 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Whose Emotion Matters? Speaker Detection without Prior Knowledge
Nov 23, 2022
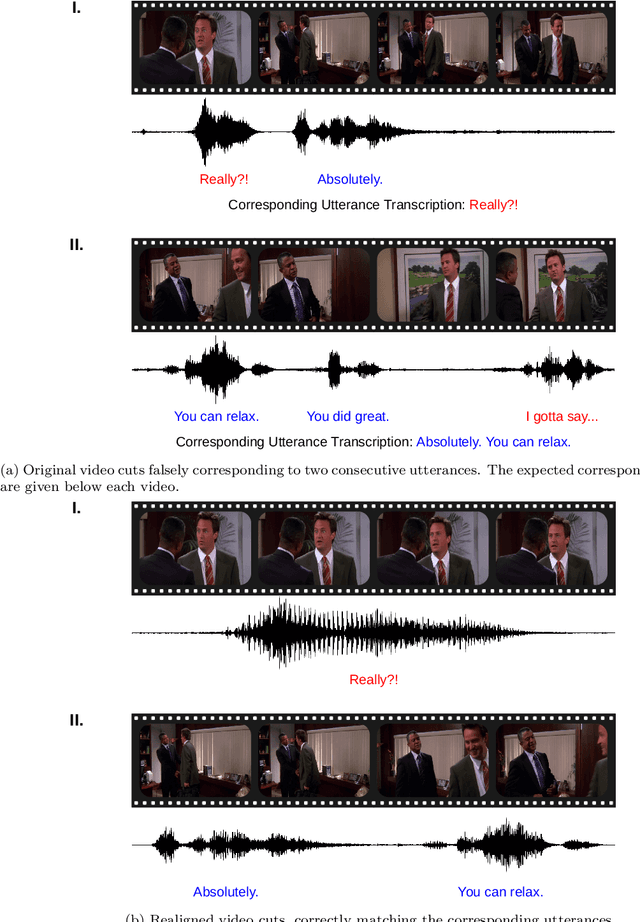

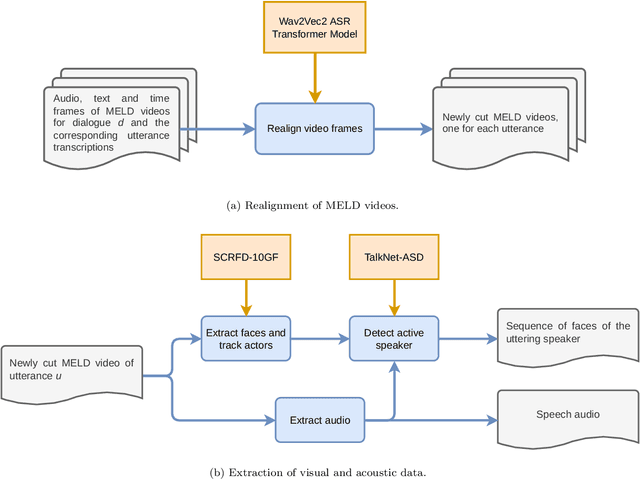
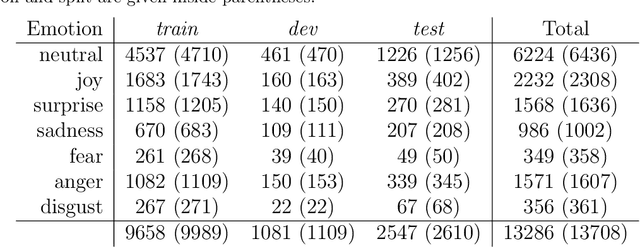
The task of emotion recognition in conversations (ERC) benefits from the availability of multiple modalities, as offered, for example, in the video-based MELD dataset. However, only a few research approaches use both acoustic and visual information from the MELD videos. There are two reasons for this: First, label-to-video alignments in MELD are noisy, making those videos an unreliable source of emotional speech data. Second, conversations can involve several people in the same scene, which requires the detection of the person speaking the utterance. In this paper we demonstrate that by using recent automatic speech recognition and active speaker detection models, we are able to realign the videos of MELD, and capture the facial expressions from uttering speakers in 96.92% of the utterances provided in MELD. Experiments with a self-supervised voice recognition model indicate that the realigned MELD videos more closely match the corresponding utterances offered in the dataset. Finally, we devise a model for emotion recognition in conversations trained on the face and audio information of the MELD realigned videos, which outperforms state-of-the-art models for ERC based on vision alone. This indicates that active speaker detection is indeed effective for extracting facial expressions from the uttering speakers, and that faces provide more informative visual cues than the visual features state-of-the-art models have been using so far.
MAFW: A Large-scale, Multi-modal, Compound Affective Database for Dynamic Facial Expression Recognition in the Wild
Aug 01, 2022
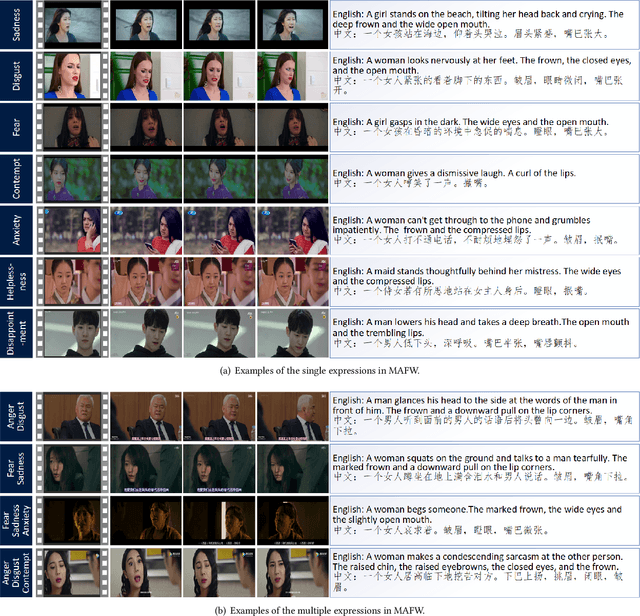
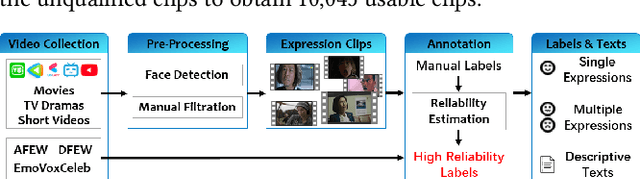
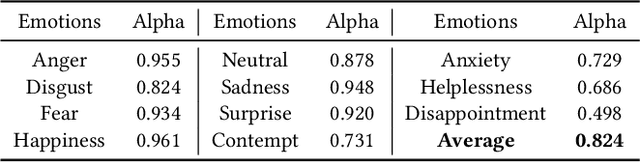
Dynamic facial expression recognition (FER) databases provide important data support for affective computing and applications. However, most FER databases are annotated with several basic mutually exclusive emotional categories and contain only one modality, e.g., videos. The monotonous labels and modality cannot accurately imitate human emotions and fulfill applications in the real world. In this paper, we propose MAFW, a large-scale multi-modal compound affective database with 10,045 video-audio clips in the wild. Each clip is annotated with a compound emotional category and a couple of sentences that describe the subjects' affective behaviors in the clip. For the compound emotion annotation, each clip is categorized into one or more of the 11 widely-used emotions, i.e., anger, disgust, fear, happiness, neutral, sadness, surprise, contempt, anxiety, helplessness, and disappointment. To ensure high quality of the labels, we filter out the unreliable annotations by an Expectation Maximization (EM) algorithm, and then obtain 11 single-label emotion categories and 32 multi-label emotion categories. To the best of our knowledge, MAFW is the first in-the-wild multi-modal database annotated with compound emotion annotations and emotion-related captions. Additionally, we also propose a novel Transformer-based expression snippet feature learning method to recognize the compound emotions leveraging the expression-change relations among different emotions and modalities. Extensive experiments on MAFW database show the advantages of the proposed method over other state-of-the-art methods for both uni- and multi-modal FER. Our MAFW database is publicly available from https://mafw-database.github.io/MAFW.
Watch Those Words: Video Falsification Detection Using Word-Conditioned Facial Motion
Dec 21, 2021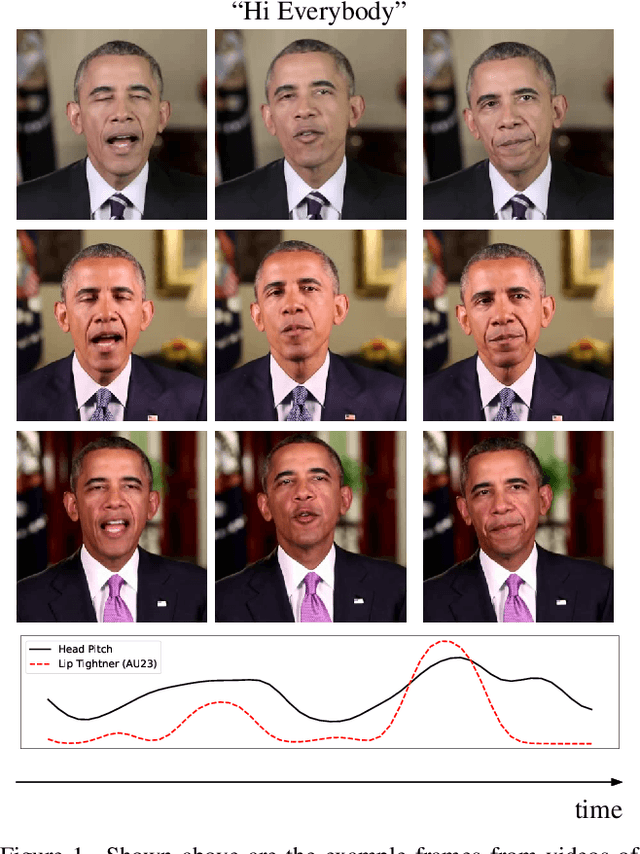
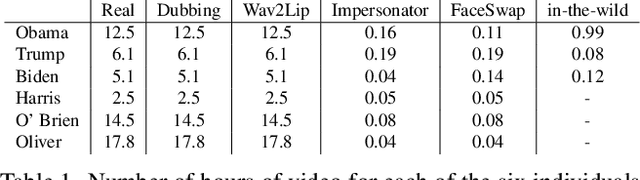
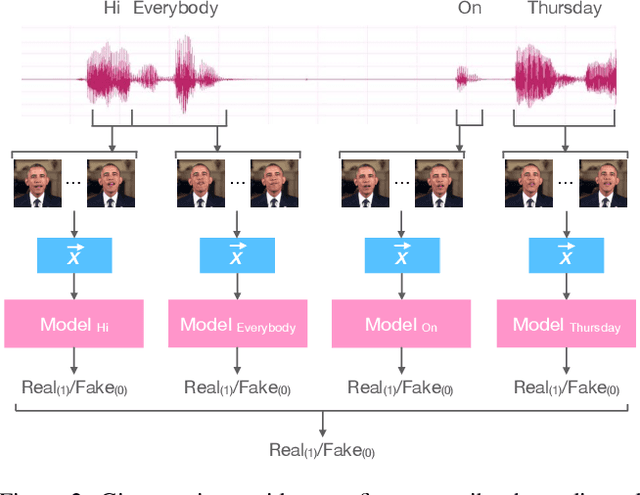
In today's era of digital misinformation, we are increasingly faced with new threats posed by video falsification techniques. Such falsifications range from cheapfakes (e.g., lookalikes or audio dubbing) to deepfakes (e.g., sophisticated AI media synthesis methods), which are becoming perceptually indistinguishable from real videos. To tackle this challenge, we propose a multi-modal semantic forensic approach to discover clues that go beyond detecting discrepancies in visual quality, thereby handling both simpler cheapfakes and visually persuasive deepfakes. In this work, our goal is to verify that the purported person seen in the video is indeed themselves by detecting anomalous correspondences between their facial movements and the words they are saying. We leverage the idea of attribution to learn person-specific biometric patterns that distinguish a given speaker from others. We use interpretable Action Units (AUs) to capture a persons' face and head movement as opposed to deep CNN visual features, and we are the first to use word-conditioned facial motion analysis. Unlike existing person-specific approaches, our method is also effective against attacks that focus on lip manipulation. We further demonstrate our method's effectiveness on a range of fakes not seen in training including those without video manipulation, that were not addressed in prior work.
PrivacyProber: Assessment and Detection of Soft-Biometric Privacy-Enhancing Techniques
Nov 16, 2022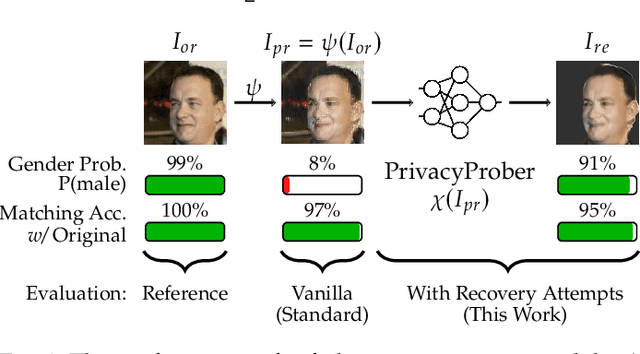

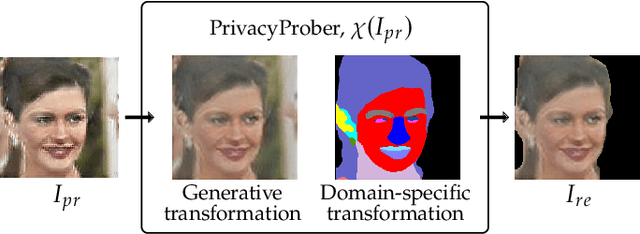
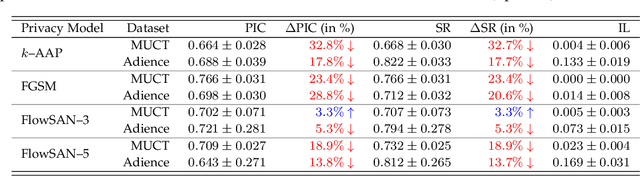
Soft-biometric privacy-enhancing techniques represent machine learning methods that aim to: (i) mitigate privacy concerns associated with face recognition technology by suppressing selected soft-biometric attributes in facial images (e.g., gender, age, ethnicity) and (ii) make unsolicited extraction of sensitive personal information infeasible. Because such techniques are increasingly used in real-world applications, it is imperative to understand to what extent the privacy enhancement can be inverted and how much attribute information can be recovered from privacy-enhanced images. While these aspects are critical, they have not been investigated in the literature. We, therefore, study the robustness of several state-of-the-art soft-biometric privacy-enhancing techniques to attribute recovery attempts. We propose PrivacyProber, a high-level framework for restoring soft-biometric information from privacy-enhanced facial images, and apply it for attribute recovery in comprehensive experiments on three public face datasets, i.e., LFW, MUCT and Adience. Our experiments show that the proposed framework is able to restore a considerable amount of suppressed information, regardless of the privacy-enhancing technique used, but also that there are significant differences between the considered privacy models. These results point to the need for novel mechanisms that can improve the robustness of existing privacy-enhancing techniques and secure them against potential adversaries trying to restore suppressed information.
A Unified Framework for Biphasic Facial Age Translation with Noisy-Semantic Guided Generative Adversarial Networks
Sep 15, 2021
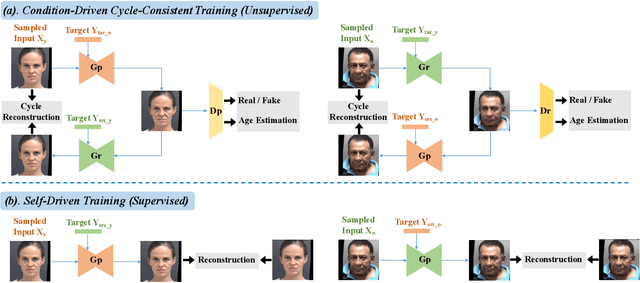
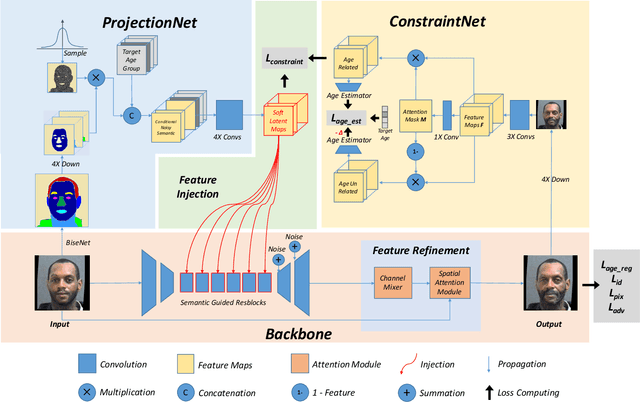

Biphasic facial age translation aims at predicting the appearance of the input face at any age. Facial age translation has received considerable research attention in the last decade due to its practical value in cross-age face recognition and various entertainment applications. However, most existing methods model age changes between holistic images, regardless of the human face structure and the age-changing patterns of individual facial components. Consequently, the lack of semantic supervision will cause infidelity of generated faces in detail. To this end, we propose a unified framework for biphasic facial age translation with noisy-semantic guided generative adversarial networks. Structurally, we project the class-aware noisy semantic layouts to soft latent maps for the following injection operation on the individual facial parts. In particular, we introduce two sub-networks, ProjectionNet and ConstraintNet. ProjectionNet introduces the low-level structural semantic information with noise map and produces soft latent maps. ConstraintNet disentangles the high-level spatial features to constrain the soft latent maps, which endows more age-related context into the soft latent maps. Specifically, attention mechanism is employed in ConstraintNet for feature disentanglement. Meanwhile, in order to mine the strongest mapping ability of the network, we embed two types of learning strategies in the training procedure, supervised self-driven generation and unsupervised condition-driven cycle-consistent generation. As a result, extensive experiments conducted on MORPH and CACD datasets demonstrate the prominent ability of our proposed method which achieves state-of-the-art performance.
Multi-spectral Facial Landmark Detection
Jun 09, 2020
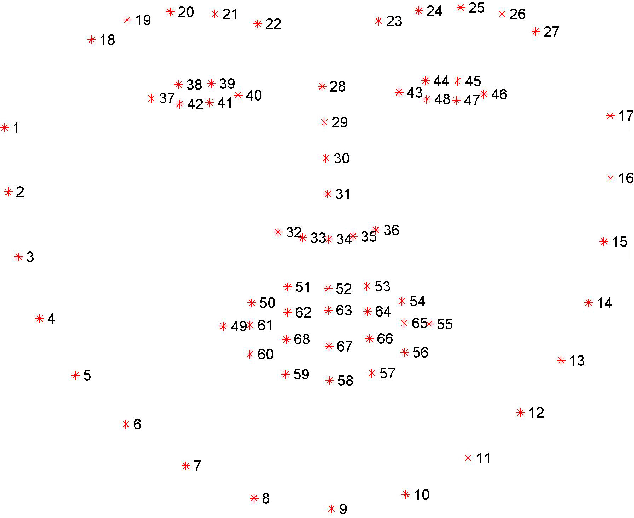
Thermal face image analysis is favorable for certain circumstances. For example, illumination-sensitive applications, like nighttime surveillance; and privacy-preserving demanded access control. However, the inadequate study on thermal face image analysis calls for attention in responding to the industry requirements. Detecting facial landmark points are important for many face analysis tasks, such as face recognition, 3D face reconstruction, and face expression recognition. In this paper, we propose a robust neural network enabled facial landmark detection, namely Deep Multi-Spectral Learning (DMSL). Briefly, DMSL consists of two sub-models, i.e. face boundary detection, and landmark coordinates detection. Such an architecture demonstrates the capability of detecting the facial landmarks on both visible and thermal images. Particularly, the proposed DMSL model is robust in facial landmark detection where the face is partially occluded, or facing different directions. The experiment conducted on Eurecom's visible and thermal paired database shows the superior performance of DMSL over the state-of-the-art for thermal facial landmark detection. In addition to that, we have annotated a thermal face dataset with their respective facial landmark for the purpose of experimentation.
The Analysis of Facial Feature Deformation using Optical Flow Algorithm
Oct 23, 2020



Facial features deformed according to the intended facial expression. Specific facial features are associated with specific facial expression, i.e. happy means the deformation of mouth. This paper presents the study of facial feature deformation for each facial expression by using an optical flow algorithm and segmented into three different regions of interest. The deformation of facial features shows the relation between facial the and facial expression. Based on the experiments, the deformations of eye and mouth are significant in all expressions except happy. For happy expression, cheeks and mouths are the significant regions. This work also suggests that different facial features' intensity varies in the way that they contribute to the recognition of the different facial expression intensity. The maximum magnitude across all expressions is shown by the mouth for surprise expression which is 9x10-4. While the minimum magnitude is shown by the mouth for angry expression which is 0.4x10-4.
* 8 pages
Comprehensive Facial Expression Synthesis using Human-Interpretable Language
Jul 16, 2020
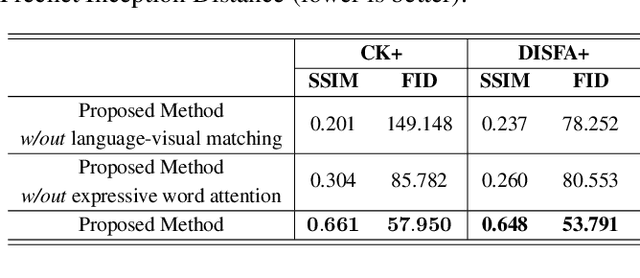
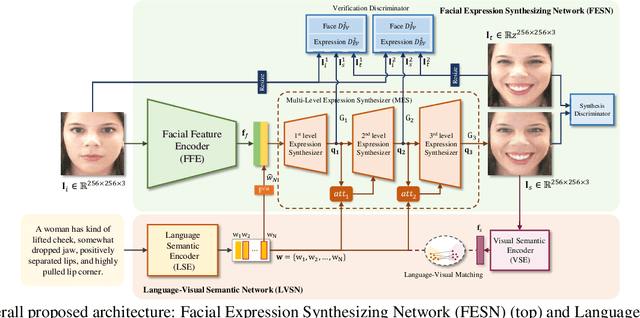

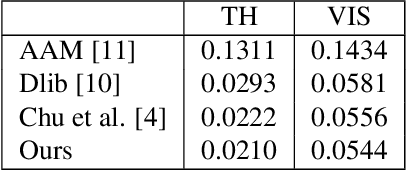
Recent advances in facial expression synthesis have shown promising results using diverse expression representations including facial action units. Facial action units for an elaborate facial expression synthesis need to be intuitively represented for human comprehension, not a numeric categorization of facial action units. To address this issue, we utilize human-friendly approach: use of natural language where language helps human grasp conceptual contexts. In this paper, therefore, we propose a new facial expression synthesis model from language-based facial expression description. Our method can synthesize the facial image with detailed expressions. In addition, effectively embedding language features on facial features, our method can control individual word to handle each part of facial movement. Extensive qualitative and quantitative evaluations were conducted to verify the effectiveness of the natural language.
Data Poisoning Won't Save You From Facial Recognition
Jun 28, 2021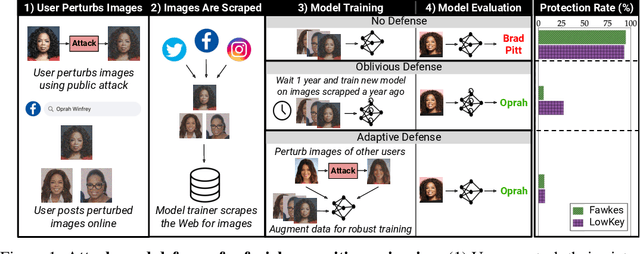
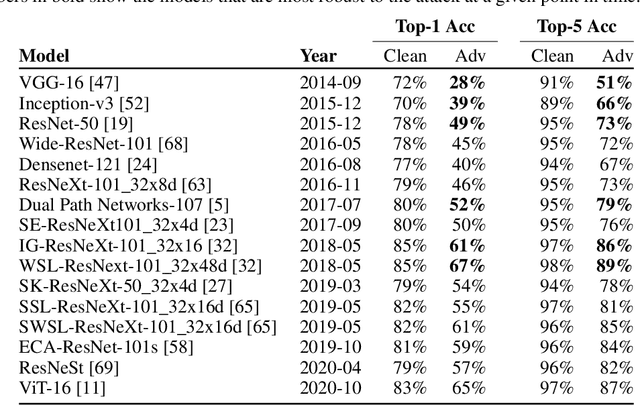


Data poisoning has been proposed as a compelling defense against facial recognition models trained on Web-scraped pictures. By perturbing the images they post online, users can fool models into misclassifying future (unperturbed) pictures. We demonstrate that this strategy provides a false sense of security, as it ignores an inherent asymmetry between the parties: users' pictures are perturbed once and for all before being published (at which point they are scraped) and must thereafter fool all future models -- including models trained adaptively against the users' past attacks, or models that use technologies discovered after the attack. We evaluate two systems for poisoning attacks against large-scale facial recognition, Fawkes (500,000+ downloads) and LowKey. We demonstrate how an "oblivious" model trainer can simply wait for future developments in computer vision to nullify the protection of pictures collected in the past. We further show that an adversary with black-box access to the attack can (i) train a robust model that resists the perturbations of collected pictures and (ii) detect poisoned pictures uploaded online. We caution that facial recognition poisoning will not admit an "arms race" between attackers and defenders. Once perturbed pictures are scraped, the attack cannot be changed so any future successful defense irrevocably undermines users' privacy.
Impact of Facial Tattoos and Paintings on Face Recognition Systems
Mar 27, 2021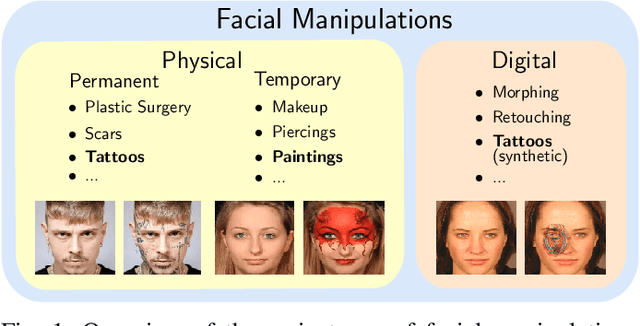
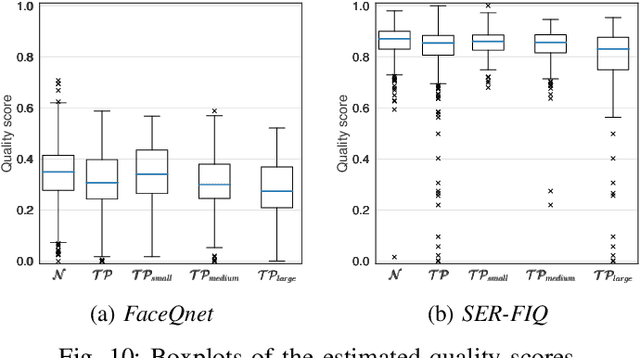
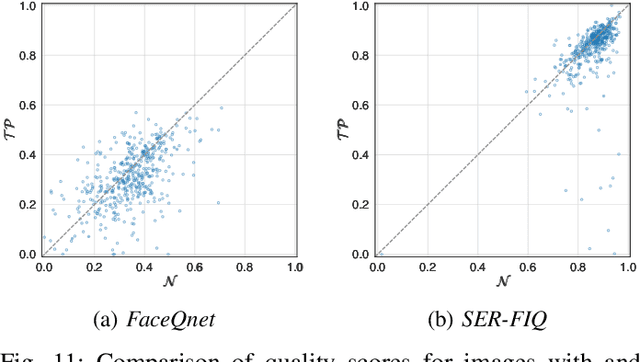

In the past years, face recognition technologies have shown impressive recognition performance, mainly due to recent developments in deep convolutional neural networks. Notwithstanding those improvements, several challenges which affect the performance of face recognition systems remain. In this work, we investigate the impact that facial tattoos and paintings have on current face recognition systems. To this end, we first collected an appropriate database containing image-pairs of individuals with and without facial tattoos or paintings. The assembled database was used to evaluate how facial tattoos and paintings affect the detection, quality estimation, as well as the feature extraction and comparison modules of a face recognition system. The impact on these modules was evaluated using state-of-the-art open-source and commercial systems. The obtained results show that facial tattoos and paintings affect all the tested modules, especially for images where a large area of the face is covered with tattoos or paintings. Our work is an initial case-study and indicates a need to design algorithms which are robust to the visual changes caused by facial tattoos and paintings.