 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Revisiting Facial Key Point Detection: An Efficient Approach Using Deep Neural Networks
May 14, 2022
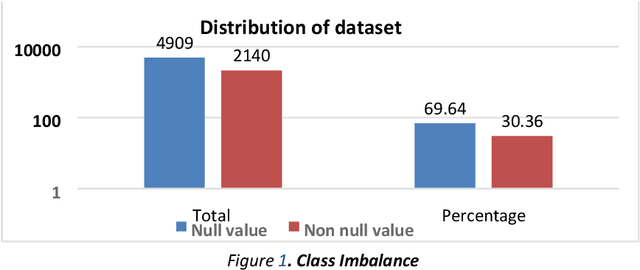
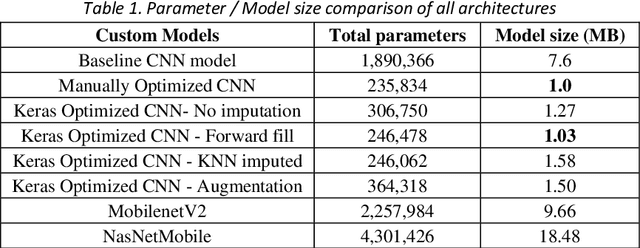

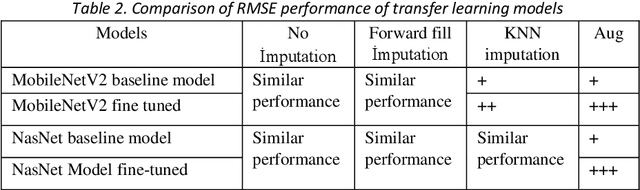
Facial landmark detection is a widely researched field of deep learning as this has a wide range of applications in many fields. These key points are distinguishing characteristic points on the face, such as the eyes center, the eye's inner and outer corners, the mouth center, and the nose tip from which human emotions and intent can be explained. The focus of our work has been evaluating transfer learning models such as MobileNetV2 and NasNetMobile, including custom CNN architectures. The objective of the research has been to develop efficient deep learning models in terms of model size, parameters, and inference time and to study the effect of augmentation imputation and fine-tuning on these models. It was found that while augmentation techniques produced lower RMSE scores than imputation techniques, they did not affect the inference time. MobileNetV2 architecture produced the lowest RMSE and inference time. Moreover, our results indicate that manually optimized CNN architectures performed similarly to Auto Keras tuned architecture. However, manually optimized architectures yielded better inference time and training curves.
Periocular Biometrics: A Modality for Unconstrained Scenarios
Dec 28, 2022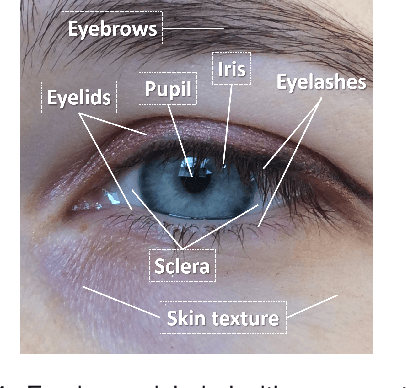
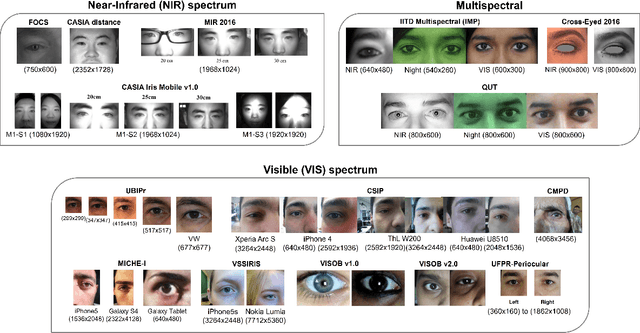
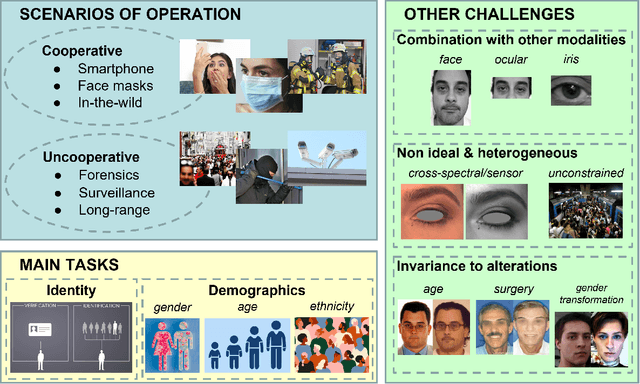
Periocular refers to the region of the face that surrounds the eye socket. This is a feature-rich area that can be used by itself to determine the identity of an individual. It is especially useful when the iris or the face cannot be reliably acquired. This can be the case of unconstrained or uncooperative scenarios, where the face may appear partially occluded, or the subject-to-camera distance may be high. However, it has received revived attention during the pandemic due to masked faces, leaving the ocular region as the only visible facial area, even in controlled scenarios. This paper discusses the state-of-the-art of periocular biometrics, giving an overall framework of its most significant research aspects.
Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
Jul 13, 2021
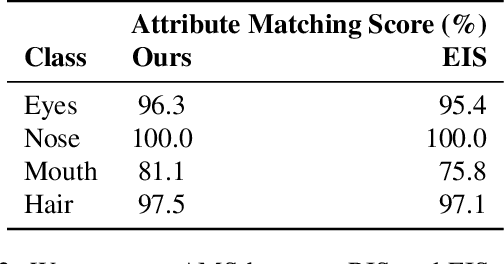

We present Retrieve in Style (RIS), an unsupervised framework for fine-grained facial feature transfer and retrieval on real images. Recent work shows that it is possible to learn a catalog that allows local semantic transfers of facial features on generated images by capitalizing on the disentanglement property of the StyleGAN latent space. RIS improves existing art on: 1) feature disentanglement and allows for challenging transfers (i.e., hair and pose) that were not shown possible in SoTA methods. 2) eliminating the need for per-image hyperparameter tuning, and for computing a catalog over a large batch of images. 3) enabling face retrieval using the proposed facial features (e.g., eyes), and to our best knowledge, is the first work to retrieve face images at the fine-grained level. 4) robustness and natural application to real images. Our qualitative and quantitative analyses show RIS achieves both high-fidelity feature transfers and accurate fine-grained retrievals on real images. We discuss the responsible application of RIS.
Detailed Facial Geometry Recovery from Multi-view Images by Learning an Implicit Function
Jan 04, 2022
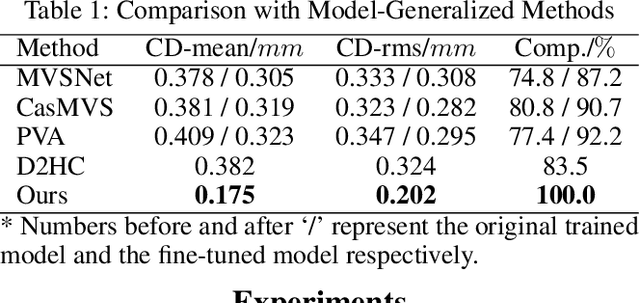
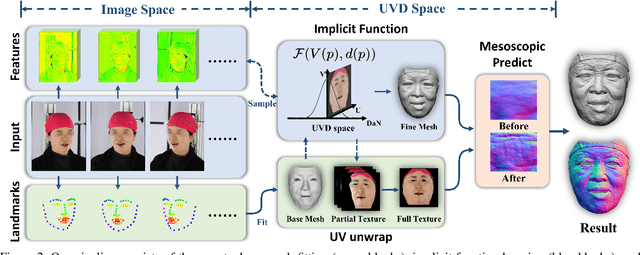
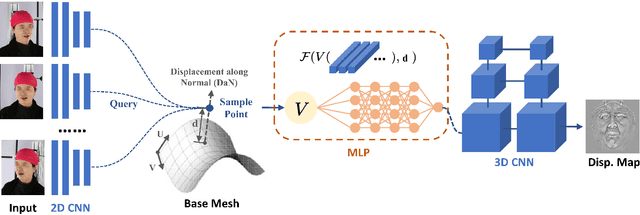
Recovering detailed facial geometry from a set of calibrated multi-view images is valuable for its wide range of applications. Traditional multi-view stereo (MVS) methods adopt optimization methods to regularize the matching cost. Recently, learning-based methods integrate all these into an end-to-end neural network and show superiority of efficiency. In this paper, we propose a novel architecture to recover extremely detailed 3D faces in roughly 10 seconds. Unlike previous learning-based methods that regularize the cost volume via 3D CNN, we propose to learn an implicit function for regressing the matching cost. By fitting a 3D morphable model from multi-view images, the features of multiple images are extracted and aggregated in the mesh-attached UV space, which makes the implicit function more effective in recovering detailed facial shape. Our method outperforms SOTA learning-based MVS in accuracy by a large margin on the FaceScape dataset. The code and data will be released soon.
3D to 4D Facial Expressions Generation Guided by Landmarks
May 16, 2021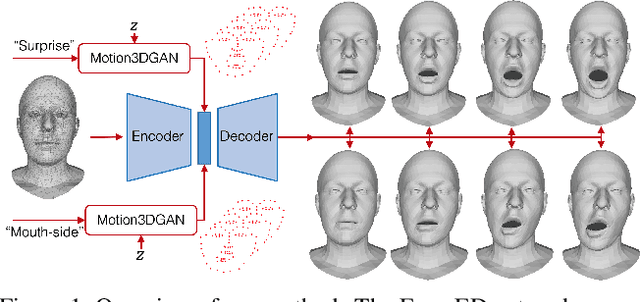
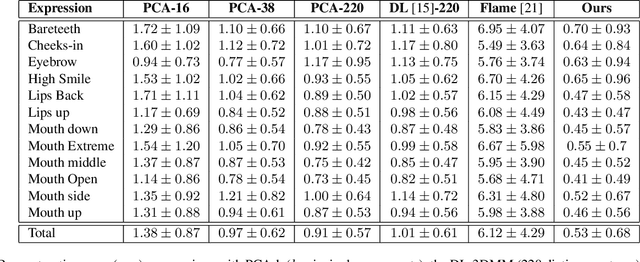
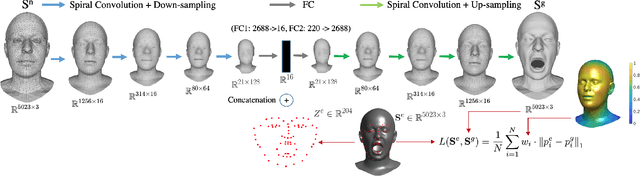
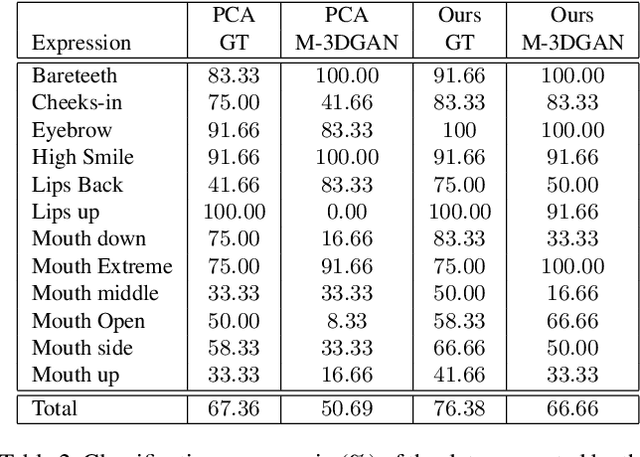
While deep learning-based 3D face generation has made a progress recently, the problem of dynamic 3D (4D) facial expression synthesis is less investigated. In this paper, we propose a novel solution to the following question: given one input 3D neutral face, can we generate dynamic 3D (4D) facial expressions from it? To tackle this problem, we first propose a mesh encoder-decoder architecture (Expr-ED) that exploits a set of 3D landmarks to generate an expressive 3D face from its neutral counterpart. Then, we extend it to 4D by modeling the temporal dynamics of facial expressions using a manifold-valued GAN capable of generating a sequence of 3D landmarks from an expression label (Motion3DGAN). The generated landmarks are fed into the mesh encoder-decoder, ultimately producing a sequence of 3D expressive faces. By decoupling the two steps, we separately address the non-linearity induced by the mesh deformation and motion dynamics. The experimental results on the CoMA dataset show that our mesh encoder-decoder guided by landmarks brings a significant improvement with respect to other landmark-based 3D fitting approaches, and that we can generate high quality dynamic facial expressions. This framework further enables the 3D expression intensity to be continuously adapted from low to high intensity. Finally, we show our framework can be applied to other tasks, such as 2D-3D facial expression transfer.
AFNet-M: Adaptive Fusion Network with Masks for 2D+3D Facial Expression Recognition
May 24, 2022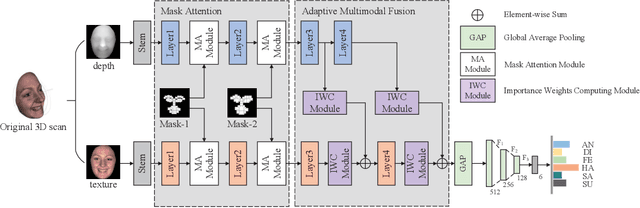
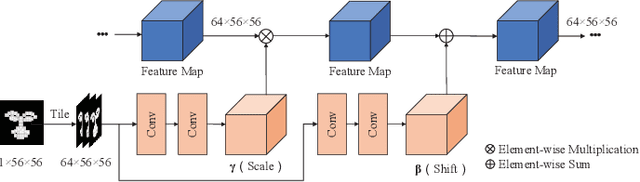
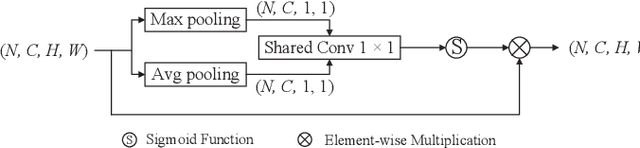
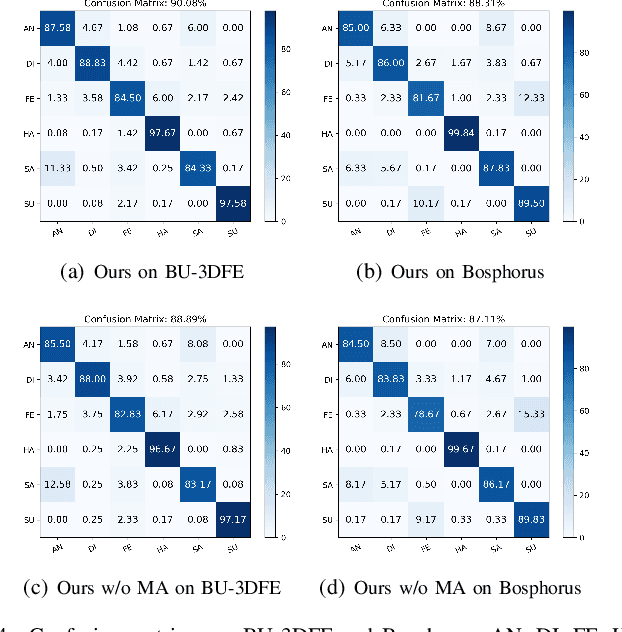
2D+3D facial expression recognition (FER) can effectively cope with illumination changes and pose variations by simultaneously merging 2D texture and more robust 3D depth information. Most deep learning-based approaches employ the simple fusion strategy that concatenates the multimodal features directly after fully-connected layers, without considering the different degrees of significance for each modality. Meanwhile, how to focus on both 2D and 3D local features in salient regions is still a great challenge. In this letter, we propose the adaptive fusion network with masks (AFNet-M) for 2D+3D FER. To enhance 2D and 3D local features, we take the masks annotating salient regions of the face as prior knowledge and design the mask attention module (MA) which can automatically learn two modulation vectors to adjust the feature maps. Moreover, we introduce a novel fusion strategy that can perform adaptive fusion at convolutional layers through the designed importance weights computing module (IWC). Experimental results demonstrate that our AFNet-M achieves the state-of-the-art performance on BU-3DFE and Bosphorus datasets and requires fewer parameters in comparison with other models.
T2V-DDPM: Thermal to Visible Face Translation using Denoising Diffusion Probabilistic Models
Sep 19, 2022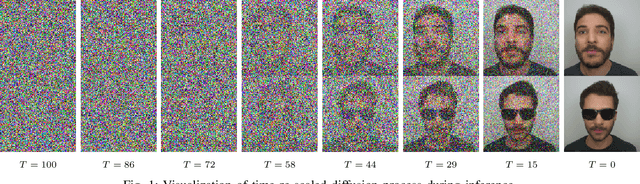
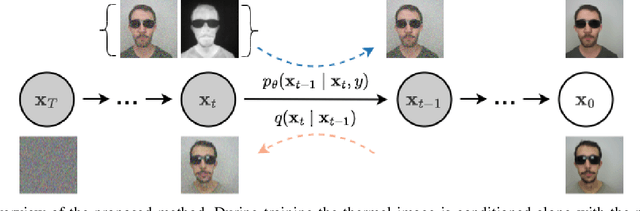
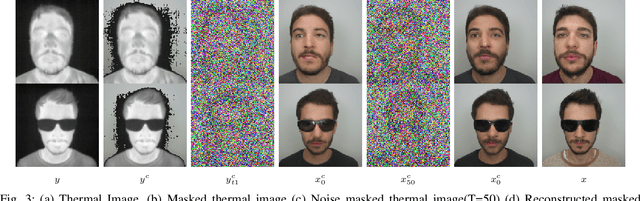

Modern-day surveillance systems perform person recognition using deep learning-based face verification networks. Most state-of-the-art facial verification systems are trained using visible spectrum images. But, acquiring images in the visible spectrum is impractical in scenarios of low-light and nighttime conditions, and often images are captured in an alternate domain such as the thermal infrared domain. Facial verification in thermal images is often performed after retrieving the corresponding visible domain images. This is a well-established problem often known as the Thermal-to-Visible (T2V) image translation. In this paper, we propose a Denoising Diffusion Probabilistic Model (DDPM) based solution for T2V translation specifically for facial images. During training, the model learns the conditional distribution of visible facial images given their corresponding thermal image through the diffusion process. During inference, the visible domain image is obtained by starting from Gaussian noise and performing denoising repeatedly. The existing inference process for DDPMs is stochastic and time-consuming. Hence, we propose a novel inference strategy for speeding up the inference time of DDPMs, specifically for the problem of T2V image translation. We achieve the state-of-the-art results on multiple datasets. The code and pretrained models are publically available at http://github.com/Nithin-GK/T2V-DDPM
Automated Detection of Equine Facial Action Units
Feb 17, 2021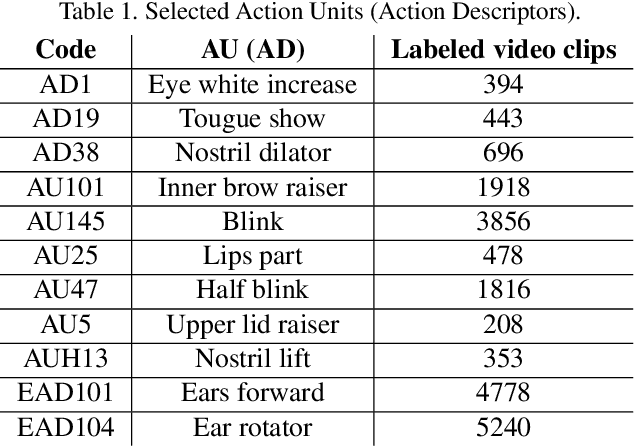
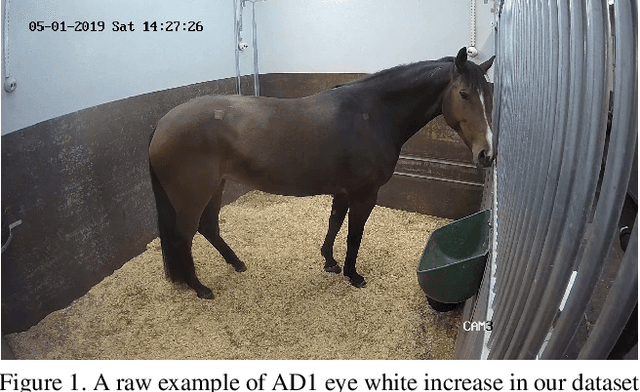
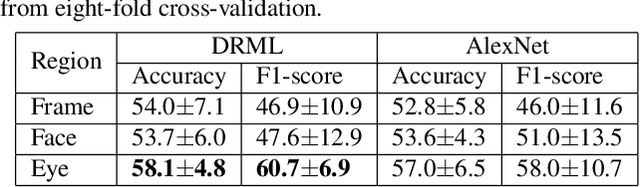
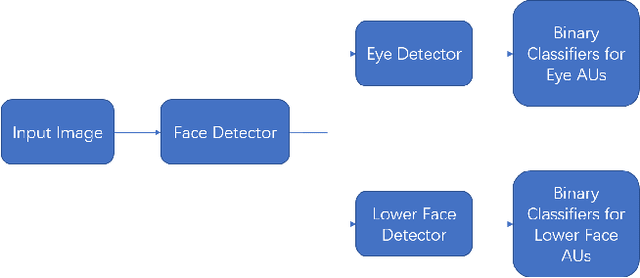
The recently developed Equine Facial Action Coding System (EquiFACS) provides a precise and exhaustive, but laborious, manual labelling method of facial action units of the horse. To automate parts of this process, we propose a Deep Learning-based method to detect EquiFACS units automatically from images. We use a cascade framework; we firstly train several object detectors to detect the predefined Region-of-Interest (ROI), and secondly apply binary classifiers for each action unit in related regions. We experiment with both regular CNNs and a more tailored model transferred from human facial action unit recognition. Promising initial results are presented for nine action units in the eye and lower face regions.
Explainable Model-Agnostic Similarity and Confidence in Face Verification
Nov 24, 2022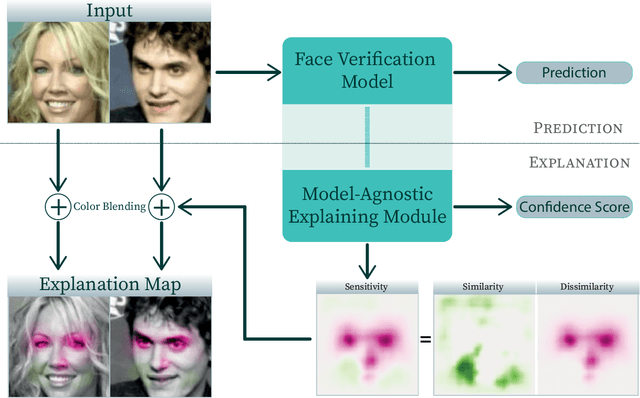
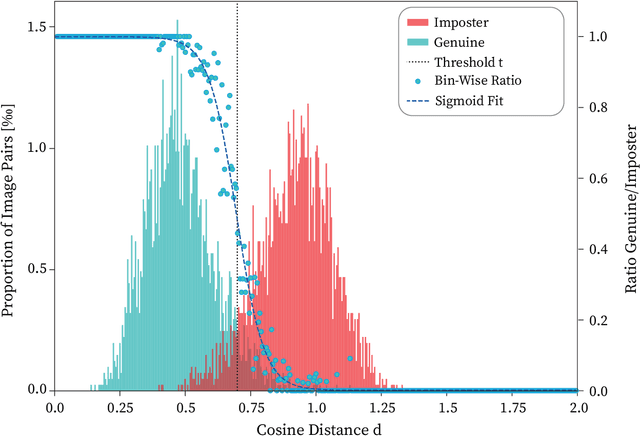


Recently, face recognition systems have demonstrated remarkable performances and thus gained a vital role in our daily life. They already surpass human face verification accountability in many scenarios. However, they lack explanations for their predictions. Compared to human operators, typical face recognition network system generate only binary decisions without further explanation and insights into those decisions. This work focuses on explanations for face recognition systems, vital for developers and operators. First, we introduce a confidence score for those systems based on facial feature distances between two input images and the distribution of distances across a dataset. Secondly, we establish a novel visualization approach to obtain more meaningful predictions from a face recognition system, which maps the distance deviation based on a systematic occlusion of images. The result is blended with the original images and highlights similar and dissimilar facial regions. Lastly, we calculate confidence scores and explanation maps for several state-of-the-art face verification datasets and release the results on a web platform. We optimize the platform for a user-friendly interaction and hope to further improve the understanding of machine learning decisions. The source code is available on GitHub, and the web platform is publicly available at http://explainable-face-verification.ey.r.appspot.com.
Facial Attribute Transformers for Precise and Robust Makeup Transfer
Apr 07, 2021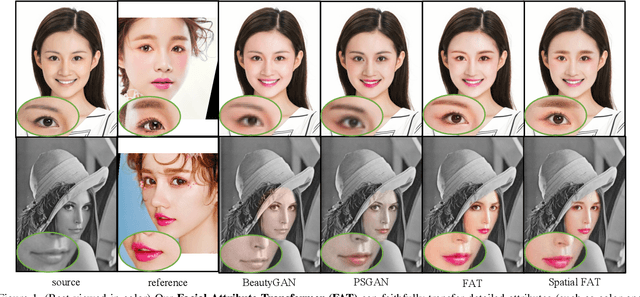

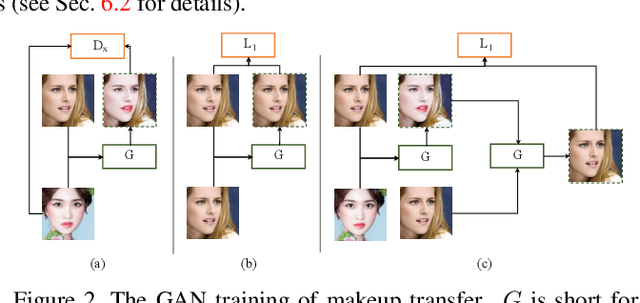
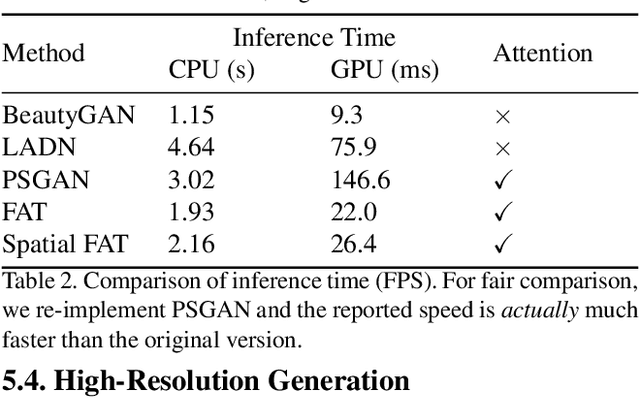
In this paper, we address the problem of makeup transfer, which aims at transplanting the makeup from the reference face to the source face while preserving the identity of the source. Existing makeup transfer methods have made notable progress in generating realistic makeup faces, but do not perform well in terms of color fidelity and spatial transformation. To tackle these issues, we propose a novel Facial Attribute Transformer (FAT) and its variant Spatial FAT for high-quality makeup transfer. Drawing inspirations from the Transformer in NLP, FAT is able to model the semantic correspondences and interactions between the source face and reference face, and then precisely estimate and transfer the facial attributes. To further facilitate shape deformation and transformation of facial parts, we also integrate thin plate splines (TPS) into FAT, thus creating Spatial FAT, which is the first method that can transfer geometric attributes in addition to color and texture. Extensive qualitative and quantitative experiments demonstrate the effectiveness and superiority of our proposed FATs in the following aspects: (1) ensuring high-fidelity color transfer; (2) allowing for geometric transformation of facial parts; (3) handling facial variations (such as poses and shadows) and (4) supporting high-resolution face generation.