 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Net Approaches in Metal Casting Defect Detection
Aug 08, 2022


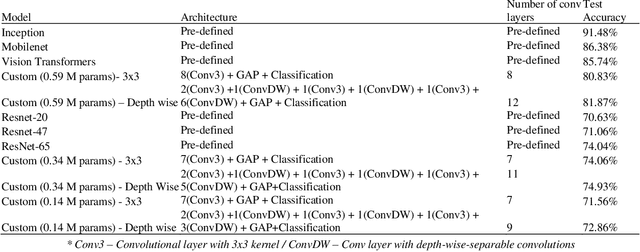
One of the most pressing challenges prevalent in the steel manufacturing industry is the identification of surface defects. Early identification of casting defects can help boost performance, including streamlining production processes. Though, deep learning models have helped bridge this gap and automate most of these processes, there is a dire need to come up with lightweight models that can be deployed easily with faster inference times. This research proposes a lightweight architecture that is efficient in terms of accuracy and inference time compared with sophisticated pre-trained CNN architectures like MobileNet, Inception, and ResNet, including vision transformers. Methodologies to minimize computational requirements such as depth-wise separable convolution and global average pooling (GAP) layer, including techniques that improve architectural efficiencies and augmentations, have been experimented. Our results indicate that a custom model of 590K parameters with depth-wise separable convolutions outperformed pretrained architectures such as Resnet and Vision transformers in terms of accuracy (81.87%) and comfortably outdid architectures such as Resnet, Inception, and Vision transformers in terms of faster inference times (12 ms). Blurpool fared outperformed other techniques, with an accuracy of 83.98%. Augmentations had a paradoxical effect on the model performance. No direct correlation between depth-wise and 3x3 convolutions on inference time, they, however, they played a direct role in improving model efficiency by enabling the networks to go deeper and by decreasing the number of trainable parameters. Our work sheds light on the fact that custom networks with efficient architectures and faster inference times can be built without the need of relying on pre-trained architectures.
Training Efficient CNNS: Tweaking the Nuts and Bolts of Neural Networks for Lighter, Faster and Robust Models
May 23, 2022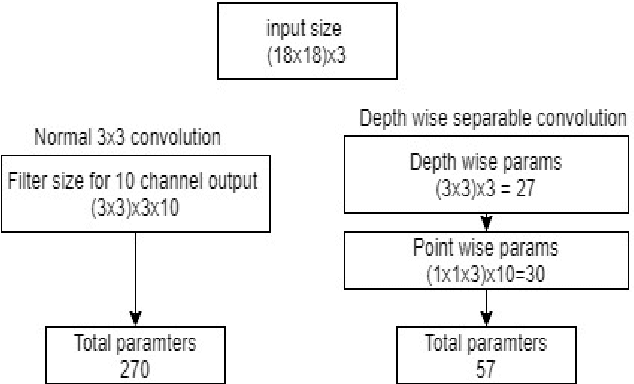
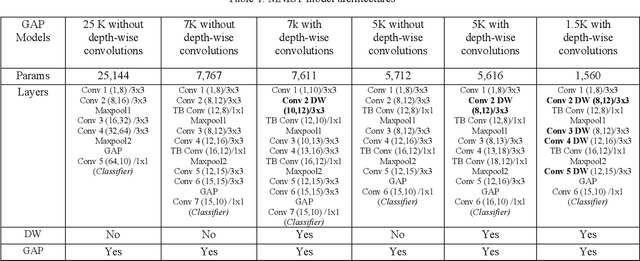
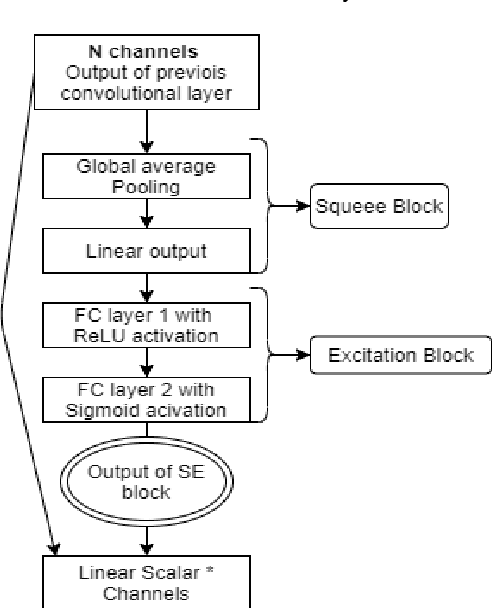
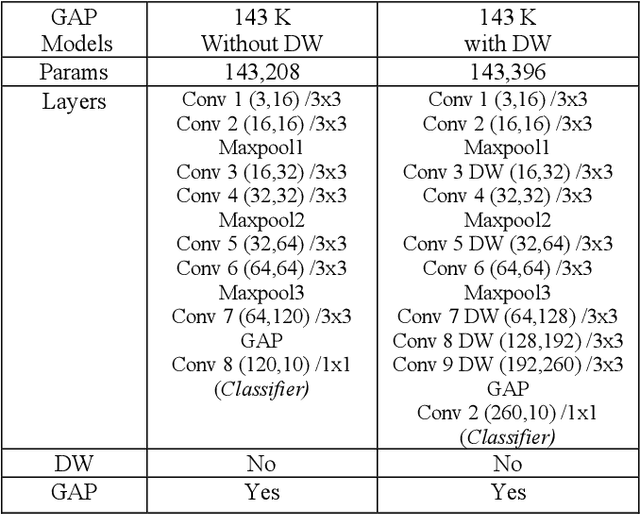
Deep Learning has revolutionized the fields of computer vision, natural language understanding, speech recognition, information retrieval and more. Many techniques have evolved over the past decade that made models lighter, faster, and robust with better generalization. However, many deep learning practitioners persist with pre-trained models and architectures trained mostly on standard datasets such as Imagenet, MS-COCO, IMDB-Wiki Dataset, and Kinetics-700 and are either hesitant or unaware of redesigning the architecture from scratch that will lead to better performance. This scenario leads to inefficient models that are not suitable on various devices such as mobile, edge, and fog. In addition, these conventional training methods are of concern as they consume a lot of computing power. In this paper, we revisit various SOTA techniques that deal with architecture efficiency (Global Average Pooling, depth-wise convolutions & squeeze and excitation, Blurpool), learning rate (Cyclical Learning Rate), data augmentation (Mixup, Cutout), label manipulation (label smoothing), weight space manipulation (stochastic weight averaging), and optimizer (sharpness aware minimization). We demonstrate how an efficient deep convolution network can be built in a phased manner by sequentially reducing the number of training parameters and using the techniques mentioned above. We achieved a SOTA accuracy of 99.2% on MNIST data with just 1500 parameters and an accuracy of 86.01% with just over 140K parameters on the CIFAR-10 dataset.
Classification of Quasars, Galaxies, and Stars in the Mapping of the Universe Multi-modal Deep Learning
May 22, 2022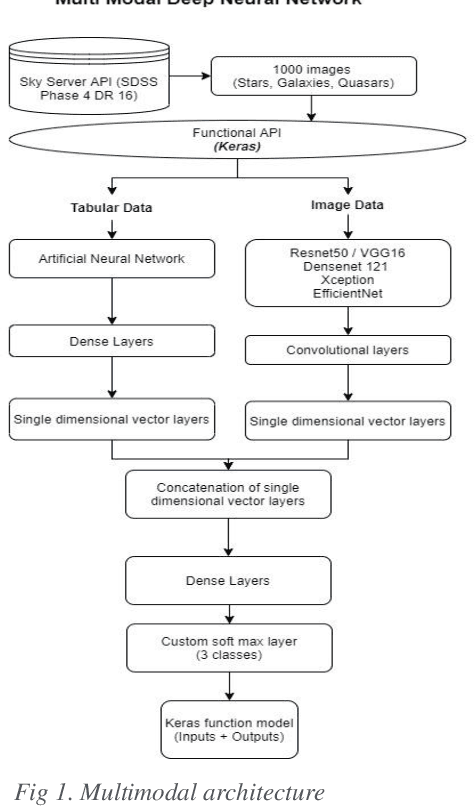
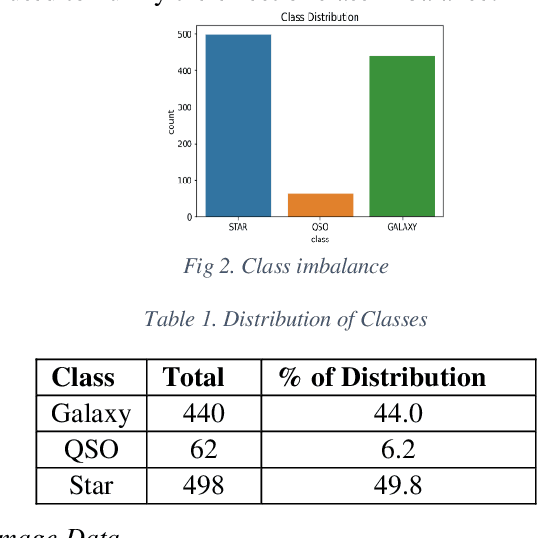
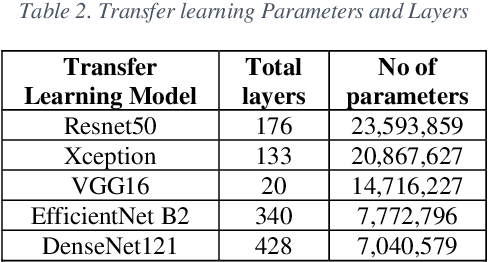

In this paper, the fourth version the Sloan Digital Sky Survey (SDSS-4), Data Release 16 dataset was used to classify the SDSS dataset into galaxies, stars, and quasars using machine learning and deep learning architectures. We efficiently utilize both image and metadata in tabular format to build a novel multi-modal architecture and achieve state-of-the-art results. In addition, our experiments on transfer learning using Imagenet weights on five different architectures (Resnet-50, DenseNet-121 VGG-16, Xception, and EfficientNet) reveal that freezing all layers and adding a final trainable layer may not be an optimal solution for transfer learning. It is hypothesized that higher the number of trainable layers, higher will be the training time and accuracy of predictions. It is also hypothesized that any subsequent increase in the number of training layers towards the base layers will not increase in accuracy as the pre trained lower layers only help in low level feature extraction which would be quite similar in all the datasets. Hence the ideal level of trainable layers needs to be identified for each model in respect to the number of parameters. For the tabular data, we compared classical machine learning algorithms (Logistic Regression, Random Forest, Decision Trees, Adaboost, LightGBM etc.,) with artificial neural networks. Our works shed new light on transfer learning and multi-modal deep learning architectures. The multi-modal architecture not only resulted in higher metrics (accuracy, precision, recall, F1 score) than models using only image data or tabular data. Furthermore, multi-modal architecture achieved the best metrics in lesser training epochs and improved the metrics on all classes.
Classification of Astronomical Bodies by Efficient Layer Fine-Tuning of Deep Neural Networks
May 14, 2022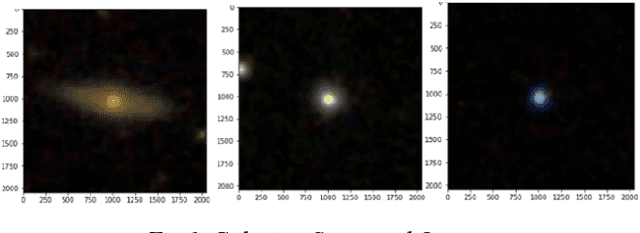
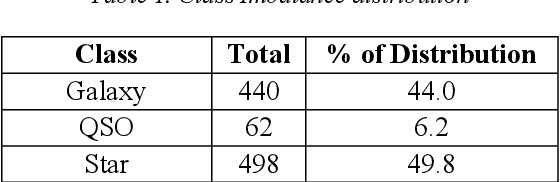
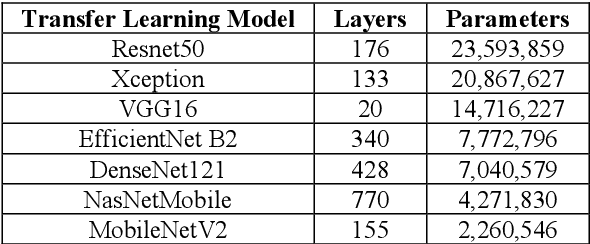
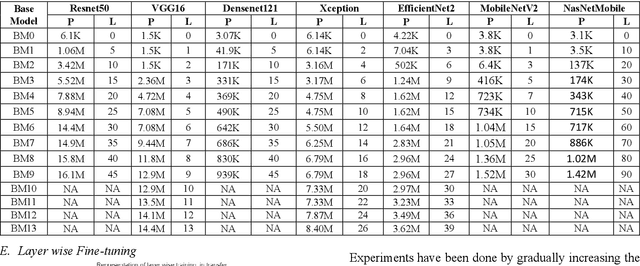
The SDSS-IV dataset contains information about various astronomical bodies such as Galaxies, Stars, and Quasars captured by observatories. Inspired by our work on deep multimodal learning, which utilized transfer learning to classify the SDSS-IV dataset, we further extended our research in the fine tuning of these architectures to study the effect in the classification scenario. Architectures such as Resnet-50, DenseNet-121 VGG-16, Xception, EfficientNetB2, MobileNetV2 and NasnetMobile have been built using layer wise fine tuning at different levels. Our findings suggest that freezing all layers with Imagenet weights and adding a final trainable layer may not be the optimal solution. Further, baseline models and models that have higher number of trainable layers performed similarly in certain architectures. Model need to be fine tuned at different levels and a specific training ratio is required for a model to be termed ideal. Different architectures had different responses to the change in the number of trainable layers w.r.t accuracies. While models such as DenseNet-121, Xception, EfficientNetB2 achieved peak accuracies that were relatively consistent with near perfect training curves, models such as Resnet-50,VGG-16, MobileNetV2 and NasnetMobile had lower, delayed peak accuracies with poorly fitting training curves. It was also found that though mobile neural networks have lesser parameters and model size, they may not always be ideal for deployment on a low computational device as they had consistently lower validation accuracies. Customized evaluation metrics such as Tuning Parameter Ratio and Tuning Layer Ratio are used for model evaluation.
Revisiting Facial Key Point Detection: An Efficient Approach Using Deep Neural Networks
May 14, 2022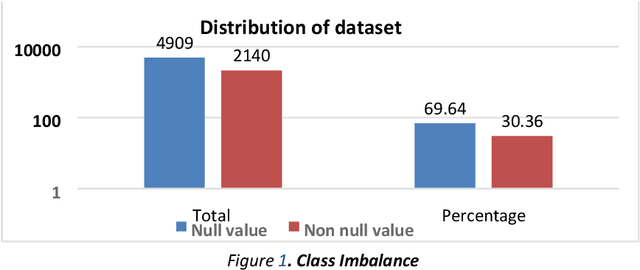
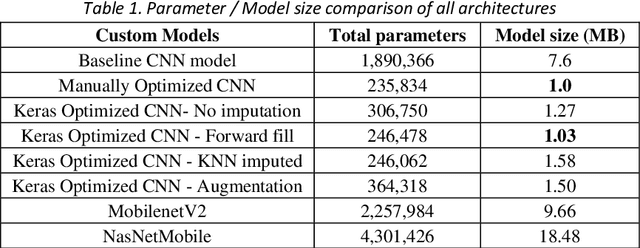

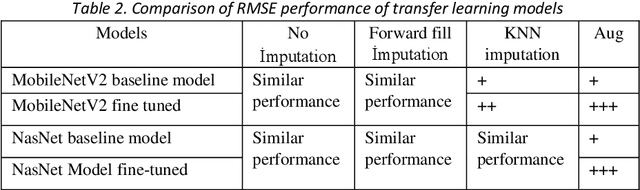
Facial landmark detection is a widely researched field of deep learning as this has a wide range of applications in many fields. These key points are distinguishing characteristic points on the face, such as the eyes center, the eye's inner and outer corners, the mouth center, and the nose tip from which human emotions and intent can be explained. The focus of our work has been evaluating transfer learning models such as MobileNetV2 and NasNetMobile, including custom CNN architectures. The objective of the research has been to develop efficient deep learning models in terms of model size, parameters, and inference time and to study the effect of augmentation imputation and fine-tuning on these models. It was found that while augmentation techniques produced lower RMSE scores than imputation techniques, they did not affect the inference time. MobileNetV2 architecture produced the lowest RMSE and inference time. Moreover, our results indicate that manually optimized CNN architectures performed similarly to Auto Keras tuned architecture. However, manually optimized architectures yielded better inference time and training curves.
Efficient Deep Learning Methods for Identification of Defective Casting Products
May 14, 2022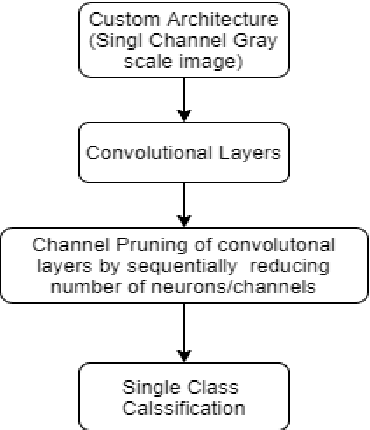
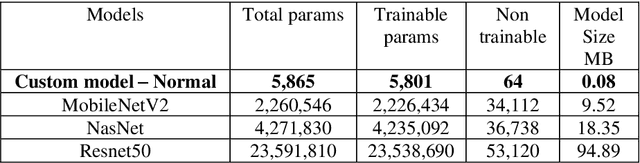
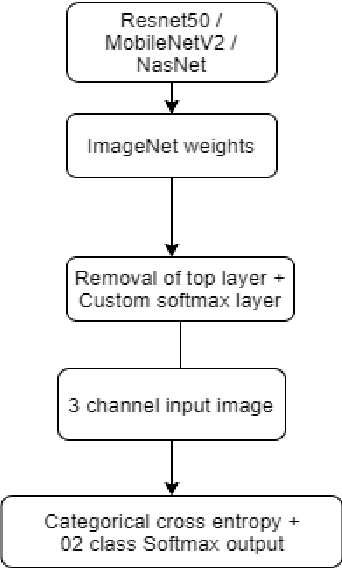
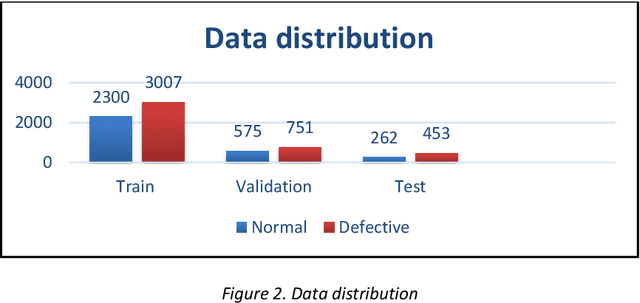
Quality inspection has become crucial in any large-scale manufacturing industry recently. In order to reduce human error, it has become imperative to use efficient and low computational AI algorithms to identify such defective products. In this paper, we have compared and contrasted various pre-trained and custom-built architectures using model size, performance and CPU latency in the detection of defective casting products. Our results show that custom architectures are efficient than pre-trained mobile architectures. Moreover, custom models perform 6 to 9 times faster than lightweight models such as MobileNetV2 and NasNet. The number of training parameters and the model size of the custom architectures is significantly lower (~386 times & ~119 times respectively) than the best performing models such as MobileNetV2 and NasNet. Augmentation experimentations have also been carried out on the custom architectures to make the models more robust and generalizable. Our work sheds light on the efficiency of these custom-built architectures for deployment on Edge and IoT devices and that transfer learning models may not always be ideal. Instead, they should be specific to the kind of dataset and the classification problem at hand.
Augmentations: An Insight into their Effectiveness on Convolution Neural Networks
May 09, 2022
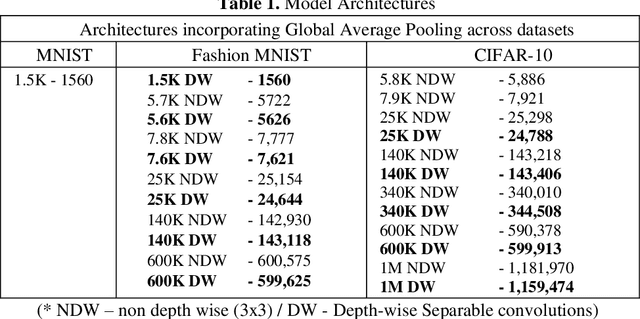
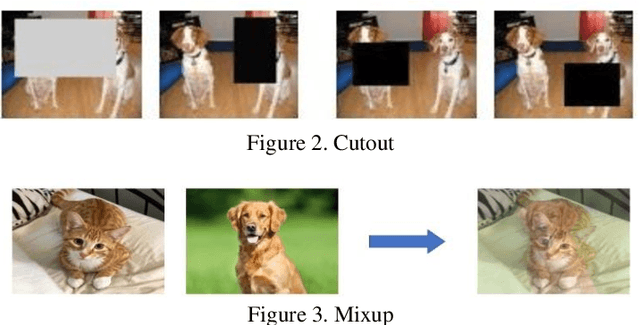
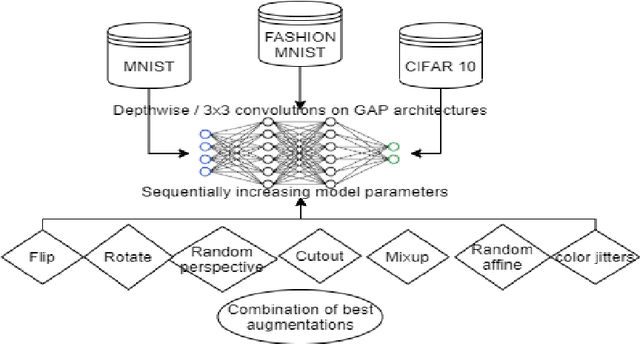
Augmentations are the key factor in determining the performance of any neural network as they provide a model with a critical edge in boosting its performance. Their ability to boost a model's robustness depends on two factors, viz-a-viz, the model architecture, and the type of augmentations. Augmentations are very specific to a dataset, and it is not imperative that all kinds of augmentation would necessarily produce a positive effect on a model's performance. Hence there is a need to identify augmentations that perform consistently well across a variety of datasets and also remain invariant to the type of architecture, convolutions, and the number of parameters used. Hence there is a need to identify augmentations that perform consistently well across a variety of datasets and also remain invariant to the type of architecture, convolutions, and the number of parameters used. This paper evaluates the effect of parameters using 3x3 and depth-wise separable convolutions on different augmentation techniques on MNIST, FMNIST, and CIFAR10 datasets. Statistical Evidence shows that techniques such as Cutouts and Random horizontal flip were consistent on both parametrically low and high architectures. Depth-wise separable convolutions outperformed 3x3 convolutions at higher parameters due to their ability to create deeper networks. Augmentations resulted in bridging the accuracy gap between the 3x3 and depth-wise separable convolutions, thus establishing their role in model generalization. At higher number augmentations did not produce a significant change in performance. The synergistic effect of multiple augmentations at higher parameters, with antagonistic effect at lower parameters, was also evaluated. The work proves that a delicate balance between architectural supremacy and augmentations needs to be achieved to enhance a model's performance in any given deep learning task.