 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Reasoning Structural Relation for Occlusion-Robust Facial Landmark Localization
Dec 19, 2021
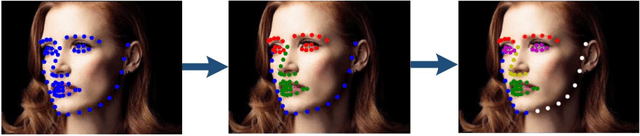
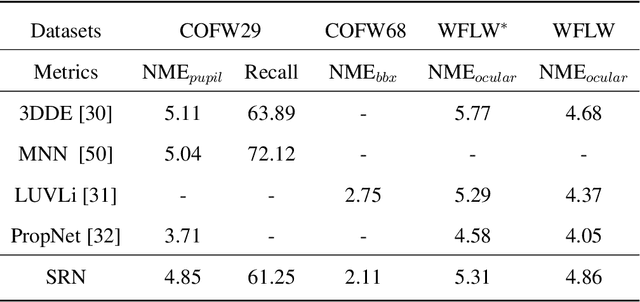
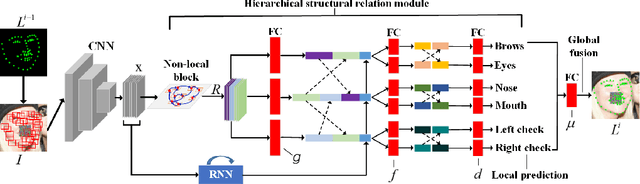
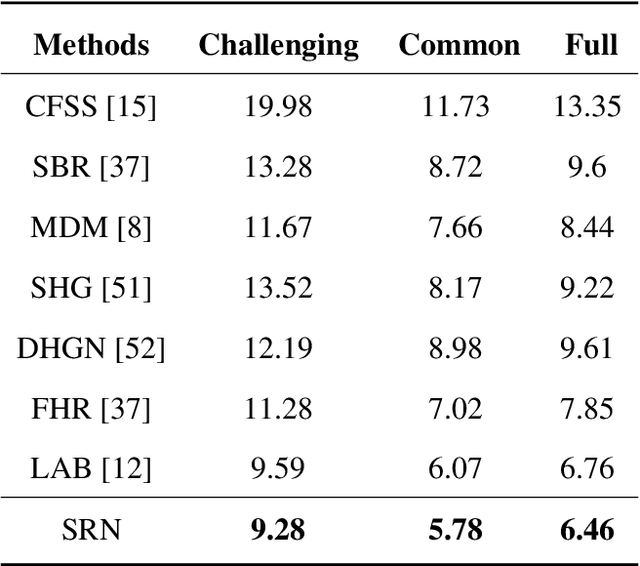
In facial landmark localization tasks, various occlusions heavily degrade the localization accuracy due to the partial observability of facial features. This paper proposes a structural relation network (SRN) for occlusion-robust landmark localization. Unlike most existing methods that simply exploit the shape constraint, the proposed SRN aims to capture the structural relations among different facial components. These relations can be considered a more powerful shape constraint against occlusion. To achieve this, a hierarchical structural relation module (HSRM) is designed to hierarchically reason the structural relations that represent both long- and short-distance spatial dependencies. Compared with existing network architectures, HSRM can efficiently model the spatial relations by leveraging its geometry-aware network architecture, which reduces the semantic ambiguity caused by occlusion. Moreover, the SRN augments the training data by synthesizing occluded faces. To further extend our SRN for occluded video data, we formulate the occluded face synthesis as a Markov decision process (MDP). Specifically, it plans the movement of the dynamic occlusion based on an accumulated reward associated with the performance degradation of the pre-trained SRN. This procedure augments hard samples for robust facial landmark tracking. Extensive experimental results indicate that the proposed method achieves outstanding performance on occluded and masked faces. Code is available at https://github.com/zhuccly/SRN.
Pose Impact Estimation on Face Recognition using 3D-Aware Synthetic Data with Application to Quality Assessment
Mar 01, 2023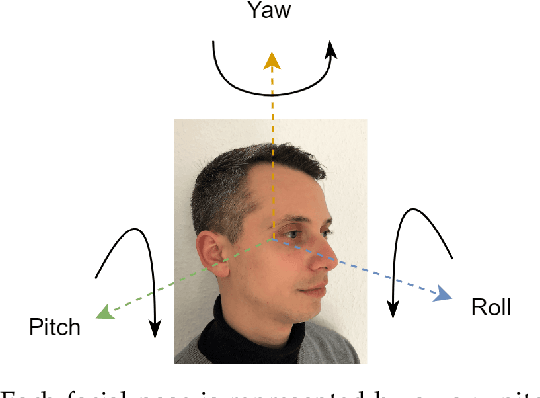



Evaluating the quality of facial images is essential for operating face recognition systems with sufficient accuracy. The recent advances in face quality standardisation (ISO/IEC WD 29794-5) recommend the usage of component quality measures for breaking down face quality into its individual factors, hence providing valuable feedback for operators to re-capture low-quality images. In light of recent advances in 3D-aware generative adversarial networks, we propose a novel dataset, "Syn-YawPitch", comprising 1,000 identities with varying yaw-pitch angle combinations. Utilizing this dataset, we demonstrate that pitch angles beyond 30 degrees have a significant impact on the biometric performance of current face recognition systems. Furthermore, we propose a lightweight and efficient pose quality predictor that adheres to the standards of ISO/IEC WD 29794-5 and is freely available for use at https://github.com/datasciencegrimmer/Syn-YawPitch/.
A comprehensive survey on semantic facial attribute editing using generative adversarial networks
May 21, 2022
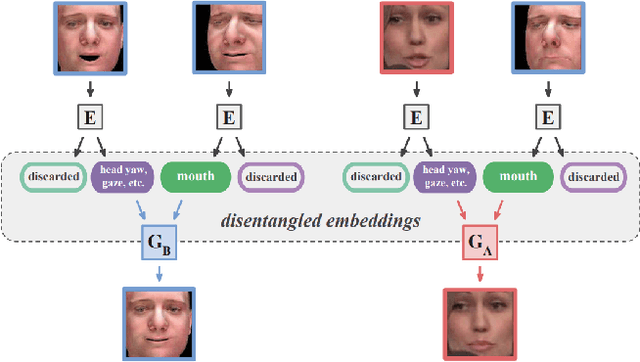
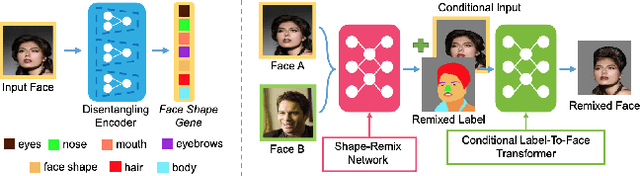
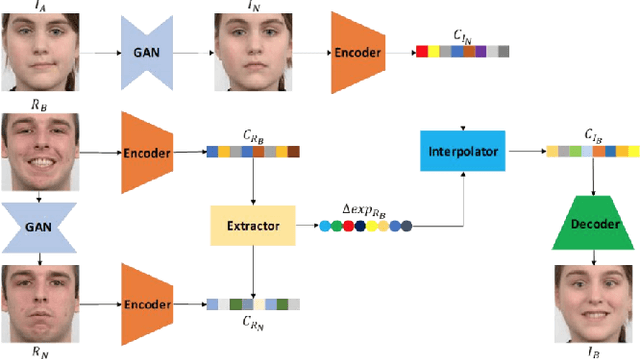
Generating random photo-realistic images has experienced tremendous growth during the past few years due to the advances of the deep convolutional neural networks and generative models. Among different domains, face photos have received a great deal of attention and a large number of face generation and manipulation models have been proposed. Semantic facial attribute editing is the process of varying the values of one or more attributes of a face image while the other attributes of the image are not affected. The requested modifications are provided as an attribute vector or in the form of driving face image and the whole process is performed by the corresponding models. In this paper, we survey the recent works and advances in semantic facial attribute editing. We cover all related aspects of these models including the related definitions and concepts, architectures, loss functions, datasets, evaluation metrics, and applications. Based on their architectures, the state-of-the-art models are categorized and studied as encoder-decoder, image-to-image, and photo-guided models. The challenges and restrictions of the current state-of-the-art methods are discussed as well.
Natural Language-Assisted Sign Language Recognition
Mar 21, 2023
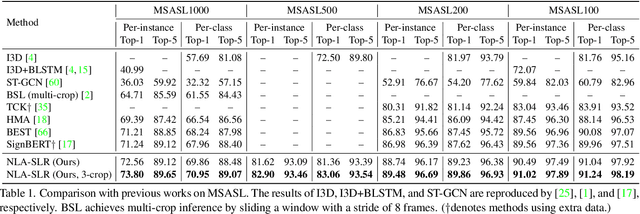
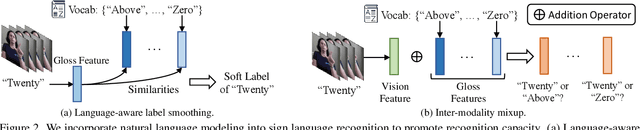
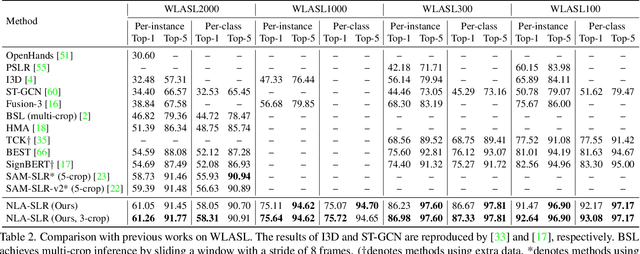
Sign languages are visual languages which convey information by signers' handshape, facial expression, body movement, and so forth. Due to the inherent restriction of combinations of these visual ingredients, there exist a significant number of visually indistinguishable signs (VISigns) in sign languages, which limits the recognition capacity of vision neural networks. To mitigate the problem, we propose the Natural Language-Assisted Sign Language Recognition (NLA-SLR) framework, which exploits semantic information contained in glosses (sign labels). First, for VISigns with similar semantic meanings, we propose language-aware label smoothing by generating soft labels for each training sign whose smoothing weights are computed from the normalized semantic similarities among the glosses to ease training. Second, for VISigns with distinct semantic meanings, we present an inter-modality mixup technique which blends vision and gloss features to further maximize the separability of different signs under the supervision of blended labels. Besides, we also introduce a novel backbone, video-keypoint network, which not only models both RGB videos and human body keypoints but also derives knowledge from sign videos of different temporal receptive fields. Empirically, our method achieves state-of-the-art performance on three widely-adopted benchmarks: MSASL, WLASL, and NMFs-CSL. Codes are available at https://github.com/FangyunWei/SLRT.
Learning Facial Representations from the Cycle-consistency of Face
Aug 07, 2021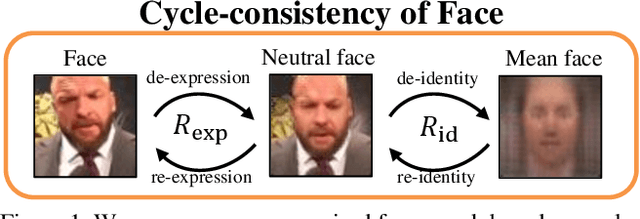
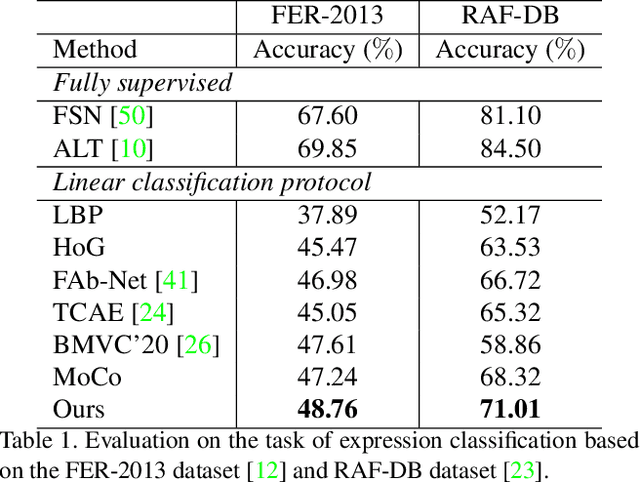
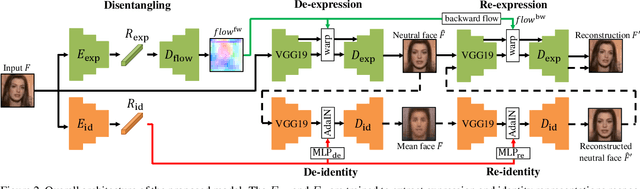
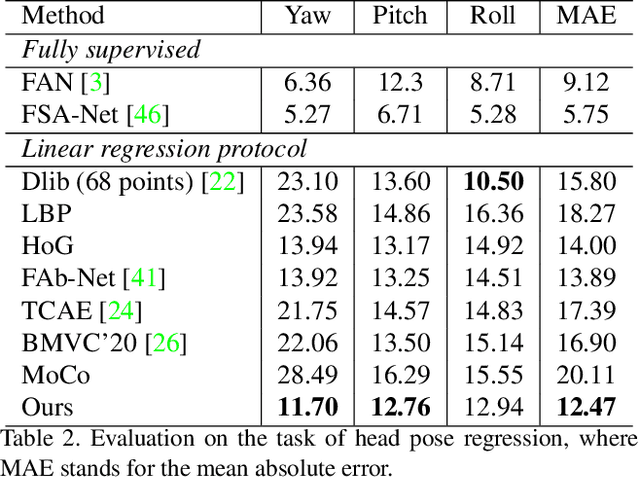
Faces manifest large variations in many aspects, such as identity, expression, pose, and face styling. Therefore, it is a great challenge to disentangle and extract these characteristics from facial images, especially in an unsupervised manner. In this work, we introduce cycle-consistency in facial characteristics as free supervisory signal to learn facial representations from unlabeled facial images. The learning is realized by superimposing the facial motion cycle-consistency and identity cycle-consistency constraints. The main idea of the facial motion cycle-consistency is that, given a face with expression, we can perform de-expression to a neutral face via the removal of facial motion and further perform re-expression to reconstruct back to the original face. The main idea of the identity cycle-consistency is to exploit both de-identity into mean face by depriving the given neutral face of its identity via feature re-normalization and re-identity into neutral face by adding the personal attributes to the mean face. At training time, our model learns to disentangle two distinct facial representations to be useful for performing cycle-consistent face reconstruction. At test time, we use the linear protocol scheme for evaluating facial representations on various tasks, including facial expression recognition and head pose regression. We also can directly apply the learnt facial representations to person recognition, frontalization and image-to-image translation. Our experiments show that the results of our approach is competitive with those of existing methods, demonstrating the rich and unique information embedded in the disentangled representations. Code is available at https://github.com/JiaRenChang/FaceCycle .
Neuron Structure Modeling for Generalizable Remote Physiological Measurement
Mar 10, 2023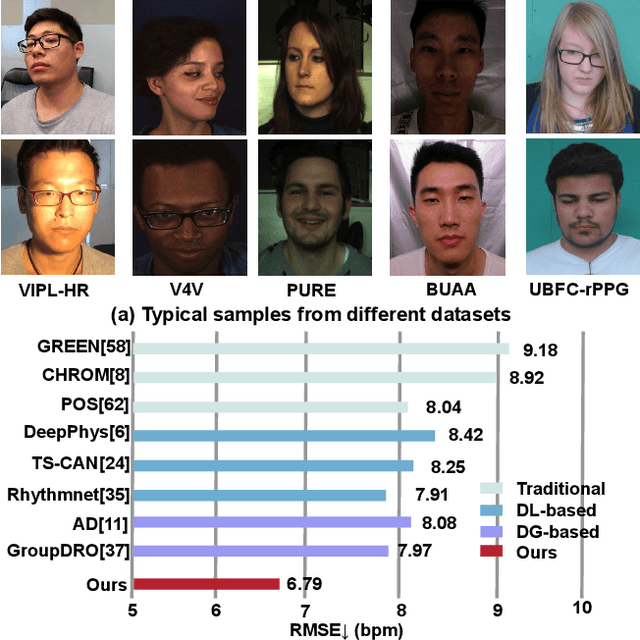
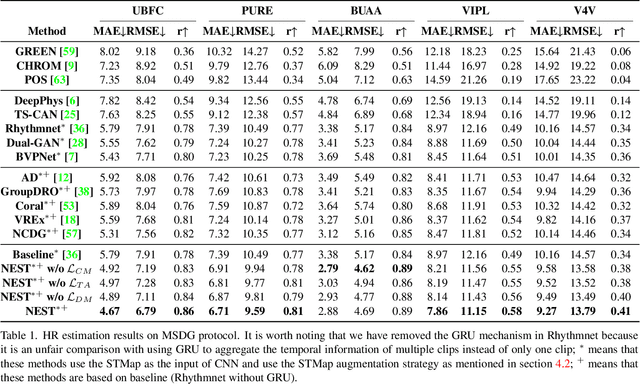
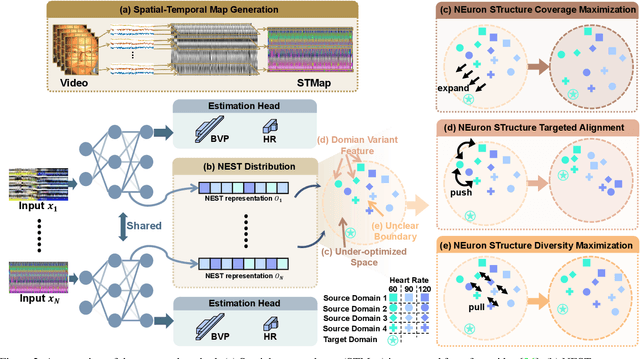
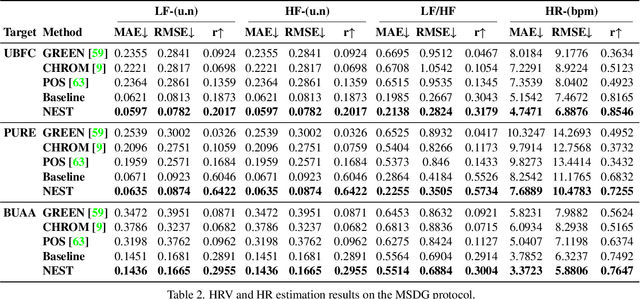
Remote photoplethysmography (rPPG) technology has drawn increasing attention in recent years. It can extract Blood Volume Pulse (BVP) from facial videos, making many applications like health monitoring and emotional analysis more accessible. However, as the BVP signal is easily affected by environmental changes, existing methods struggle to generalize well for unseen domains. In this paper, we systematically address the domain shift problem in the rPPG measurement task. We show that most domain generalization methods do not work well in this problem, as domain labels are ambiguous in complicated environmental changes. In light of this, we propose a domain-label-free approach called NEuron STructure modeling (NEST). NEST improves the generalization capacity by maximizing the coverage of feature space during training, which reduces the chance for under-optimized feature activation during inference. Besides, NEST can also enrich and enhance domain invariant features across multi-domain. We create and benchmark a large-scale domain generalization protocol for the rPPG measurement task. Extensive experiments show that our approach outperforms the state-of-the-art methods on both cross-dataset and intra-dataset settings.
Subpixel Heatmap Regression for Facial Landmark Localization
Nov 03, 2021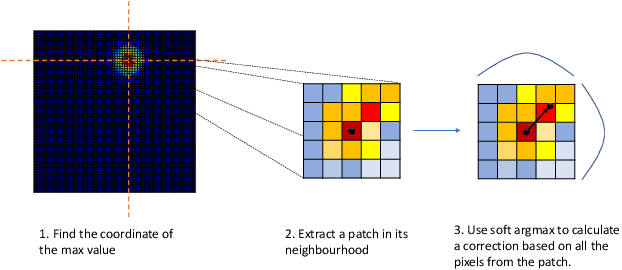
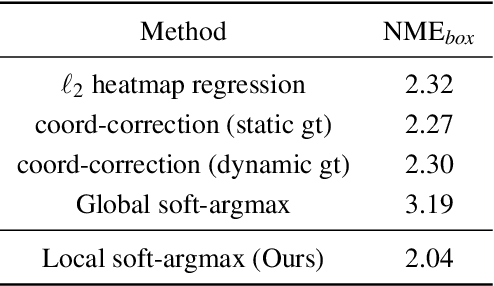
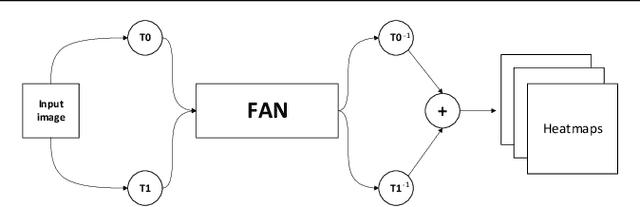

Deep Learning models based on heatmap regression have revolutionized the task of facial landmark localization with existing models working robustly under large poses, non-uniform illumination and shadows, occlusions and self-occlusions, low resolution and blur. However, despite their wide adoption, heatmap regression approaches suffer from discretization-induced errors related to both the heatmap encoding and decoding process. In this work we show that these errors have a surprisingly large negative impact on facial alignment accuracy. To alleviate this problem, we propose a new approach for the heatmap encoding and decoding process by leveraging the underlying continuous distribution. To take full advantage of the newly proposed encoding-decoding mechanism, we also introduce a Siamese-based training that enforces heatmap consistency across various geometric image transformations. Our approach offers noticeable gains across multiple datasets setting a new state-of-the-art result in facial landmark localization. Code alongside the pretrained models will be made available at https://www.adrianbulat.com/face-alignment
OmniAvatar: Geometry-Guided Controllable 3D Head Synthesis
Mar 27, 2023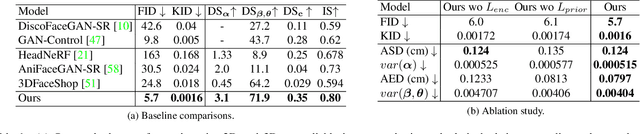
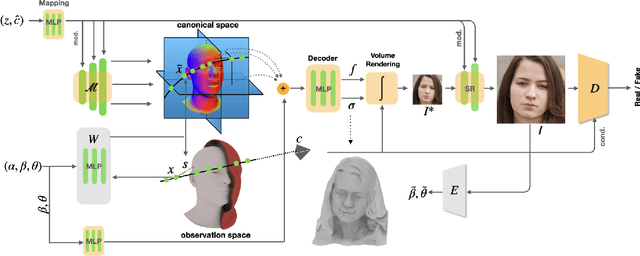

We present OmniAvatar, a novel geometry-guided 3D head synthesis model trained from in-the-wild unstructured images that is capable of synthesizing diverse identity-preserved 3D heads with compelling dynamic details under full disentangled control over camera poses, facial expressions, head shapes, articulated neck and jaw poses. To achieve such high level of disentangled control, we first explicitly define a novel semantic signed distance function (SDF) around a head geometry (FLAME) conditioned on the control parameters. This semantic SDF allows us to build a differentiable volumetric correspondence map from the observation space to a disentangled canonical space from all the control parameters. We then leverage the 3D-aware GAN framework (EG3D) to synthesize detailed shape and appearance of 3D full heads in the canonical space, followed by a volume rendering step guided by the volumetric correspondence map to output into the observation space. To ensure the control accuracy on the synthesized head shapes and expressions, we introduce a geometry prior loss to conform to head SDF and a control loss to conform to the expression code. Further, we enhance the temporal realism with dynamic details conditioned upon varying expressions and joint poses. Our model can synthesize more preferable identity-preserved 3D heads with compelling dynamic details compared to the state-of-the-art methods both qualitatively and quantitatively. We also provide an ablation study to justify many of our system design choices.
Cross-modal Face- and Voice-style Transfer
Mar 01, 2023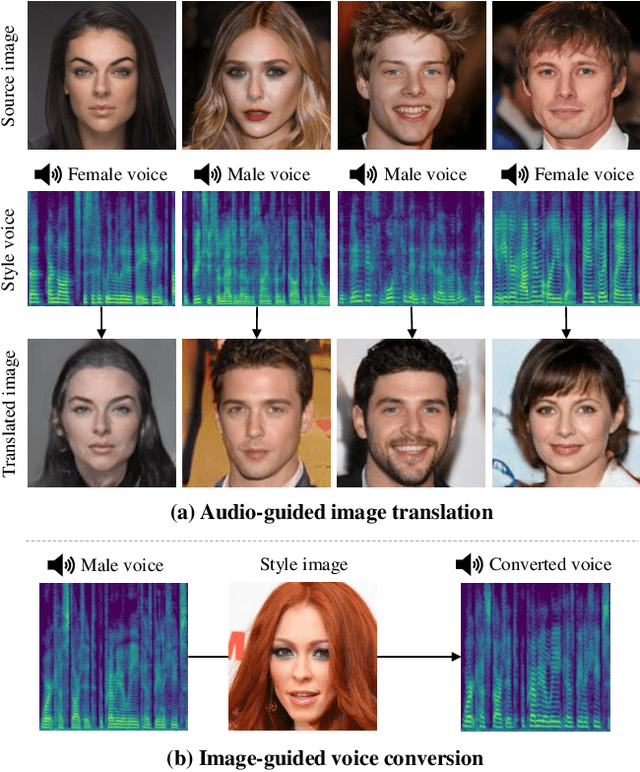

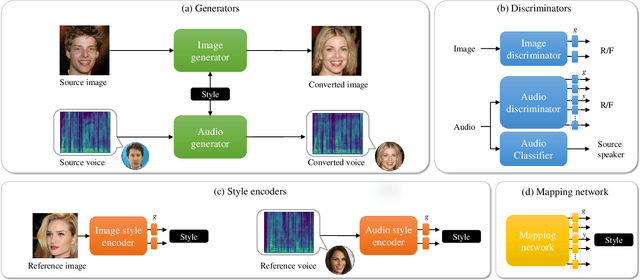
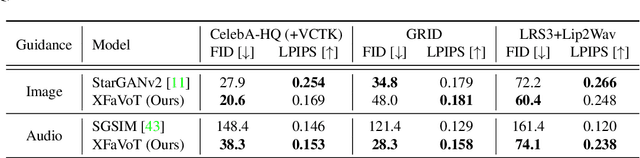
Image-to-image translation and voice conversion enable the generation of a new facial image and voice while maintaining some of the semantics such as a pose in an image and linguistic content in audio, respectively. They can aid in the content-creation process in many applications. However, as they are limited to the conversion within each modality, matching the impression of the generated face and voice remains an open question. We propose a cross-modal style transfer framework called XFaVoT that jointly learns four tasks: image translation and voice conversion tasks with audio or image guidance, which enables the generation of ``face that matches given voice" and ``voice that matches given face", and intra-modality translation tasks with a single framework. Experimental results on multiple datasets show that XFaVoT achieves cross-modal style translation of image and voice, outperforming baselines in terms of quality, diversity, and face-voice correspondence.
Robust and Precise Facial Landmark Detection by Self-Calibrated Pose Attention Network
Dec 23, 2021
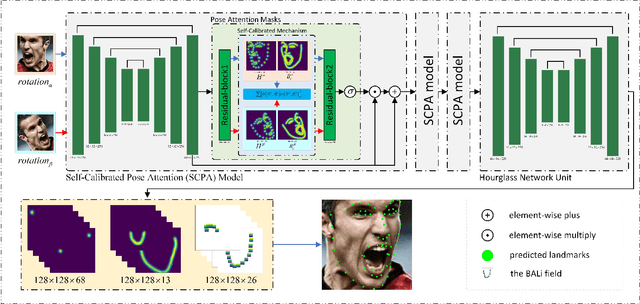


Current fully-supervised facial landmark detection methods have progressed rapidly and achieved remarkable performance. However, they still suffer when coping with faces under large poses and heavy occlusions for inaccurate facial shape constraints and insufficient labeled training samples. In this paper, we propose a semi-supervised framework, i.e., a Self-Calibrated Pose Attention Network (SCPAN) to achieve more robust and precise facial landmark detection in challenging scenarios. To be specific, a Boundary-Aware Landmark Intensity (BALI) field is proposed to model more effective facial shape constraints by fusing boundary and landmark intensity field information. Moreover, a Self-Calibrated Pose Attention (SCPA) model is designed to provide a self-learned objective function that enforces intermediate supervision without label information by introducing a self-calibrated mechanism and a pose attention mask. We show that by integrating the BALI fields and SCPA model into a novel self-calibrated pose attention network, more facial prior knowledge can be learned and the detection accuracy and robustness of our method for faces with large poses and heavy occlusions have been improved. The experimental results obtained for challenging benchmark datasets demonstrate that our approach outperforms state-of-the-art methods in the literature.