 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BiomedJourney: Counterfactual Biomedical Image Generation by Instruction-Learning from Multimodal Patient Journeys
Oct 18, 2023
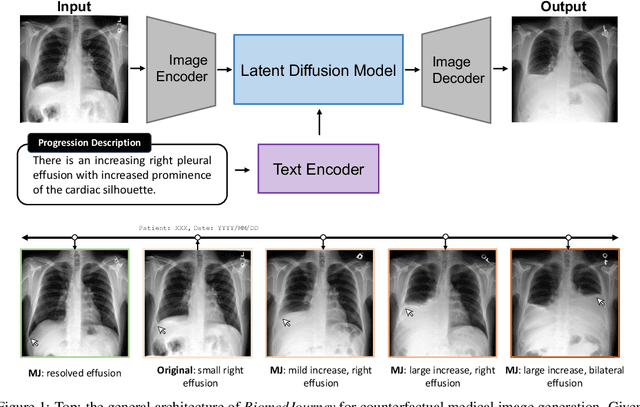
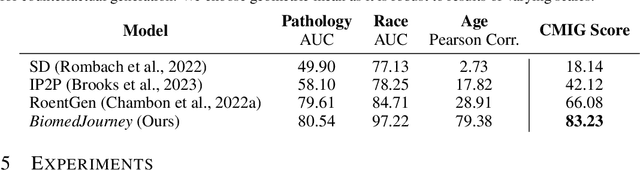
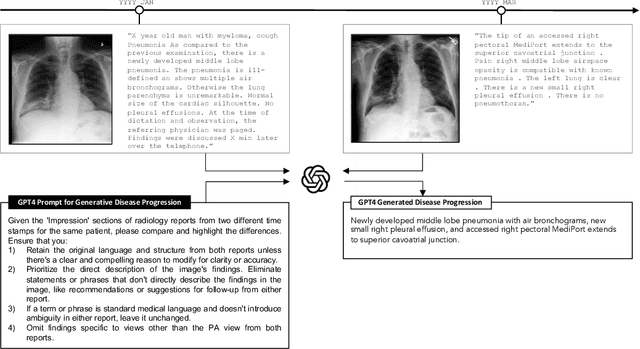
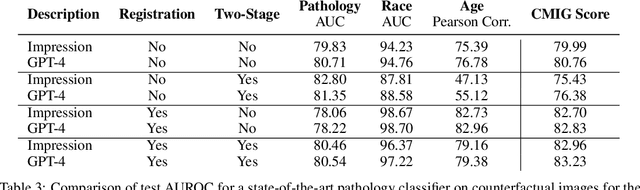
Rapid progress has been made in instruction-learning for image editing with natural-language instruction, as exemplified by InstructPix2Pix. In biomedicine, such methods can be applied to counterfactual image generation, which helps differentiate causal structure from spurious correlation and facilitate robust image interpretation for disease progression modeling. However, generic image-editing models are ill-suited for the biomedical domain, and counterfactual biomedical image generation is largely underexplored. In this paper, we present BiomedJourney, a novel method for counterfactual biomedical image generation by instruction-learning from multimodal patient journeys. Given a patient with two biomedical images taken at different time points, we use GPT-4 to process the corresponding imaging reports and generate a natural language description of disease progression. The resulting triples (prior image, progression description, new image) are then used to train a latent diffusion model for counterfactual biomedical image generation. Given the relative scarcity of image time series data, we introduce a two-stage curriculum that first pretrains the denoising network using the much more abundant single image-report pairs (with dummy prior image), and then continues training using the counterfactual triples. Experiments using the standard MIMIC-CXR dataset demonstrate the promise of our method. In a comprehensive battery of tests on counterfactual medical image generation, BiomedJourney substantially outperforms prior state-of-the-art methods in instruction image editing and medical image generation such as InstructPix2Pix and RoentGen. To facilitate future study in counterfactual medical generation, we plan to release our instruction-learning code and pretrained models.
Strategies and impact of learning curve estimation for CNN-based image classification
Oct 12, 2023Learning curves are a measure for how the performance of machine learning models improves given a certain volume of training data. Over a wide variety of applications and models it was observed that learning curves follow -- to a large extent -- a power law behavior. This makes the performance of different models for a given task somewhat predictable and opens the opportunity to reduce the training time for practitioners, who are exploring the space of possible models and hyperparameters for the problem at hand. By estimating the learning curve of a model from training on small subsets of data only the best models need to be considered for training on the full dataset. How to choose subset sizes and how often to sample models on these to obtain estimates is however not researched. Given that the goal is to reduce overall training time strategies are needed that sample the performance in a time-efficient way and yet leads to accurate learning curve estimates. In this paper we formulate the framework for these strategies and propose several strategies. Further we evaluate the strategies for simulated learning curves and in experiments with popular datasets and models for image classification tasks.
Discovering Fatigued Movements for Virtual Character Animation
Oct 12, 2023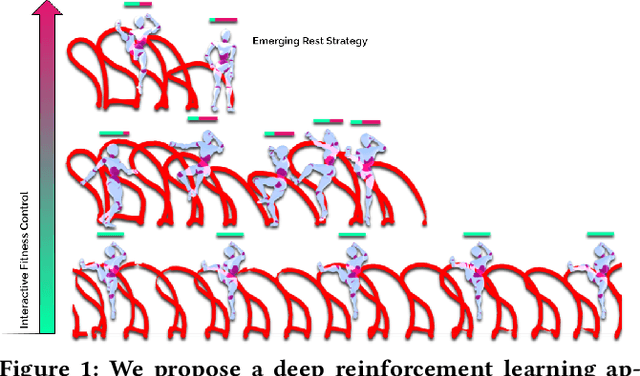
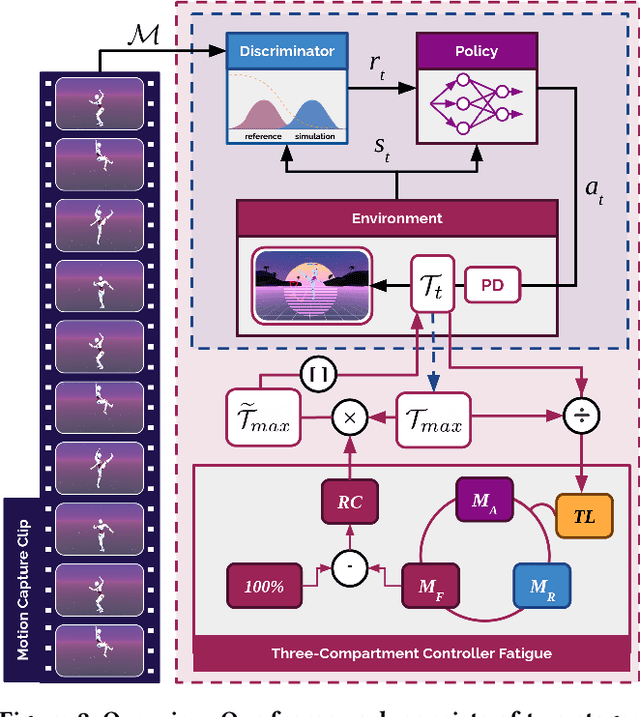

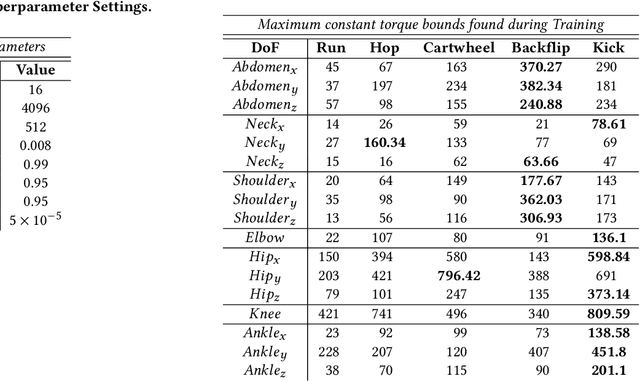
Virtual character animation and movement synthesis have advanced rapidly during recent years, especially through a combination of extensive motion capture datasets and machine learning. A remaining challenge is interactively simulating characters that fatigue when performing extended motions, which is indispensable for the realism of generated animations. However, capturing such movements is problematic, as performing movements like backflips with fatigued variations up to exhaustion raises capture cost and risk of injury. Surprisingly, little research has been done on faithful fatigue modeling. To address this, we propose a deep reinforcement learning-based approach, which -- for the first time in literature -- generates control policies for full-body physically simulated agents aware of cumulative fatigue. For this, we first leverage Generative Adversarial Imitation Learning (GAIL) to learn an expert policy for the skill; Second, we learn a fatigue policy by limiting the generated constant torque bounds based on endurance time to non-linear, state- and time-dependent limits in the joint-actuation space using a Three-Compartment Controller (3CC) model. Our results demonstrate that agents can adapt to different fatigue and rest rates interactively, and discover realistic recovery strategies without the need for any captured data of fatigued movement.
* 16 pages, 22 figures. To be published in ACM SIGGRAPH Asia Conference Papers 2023. ACM ISBN 979-8-4007-0315-7/23/12
Compression of Recurrent Neural Networks using Matrix Factorization
Oct 19, 2023
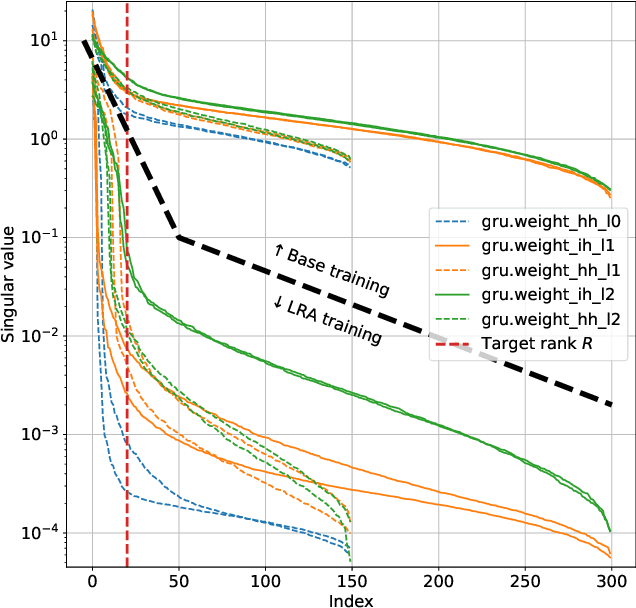
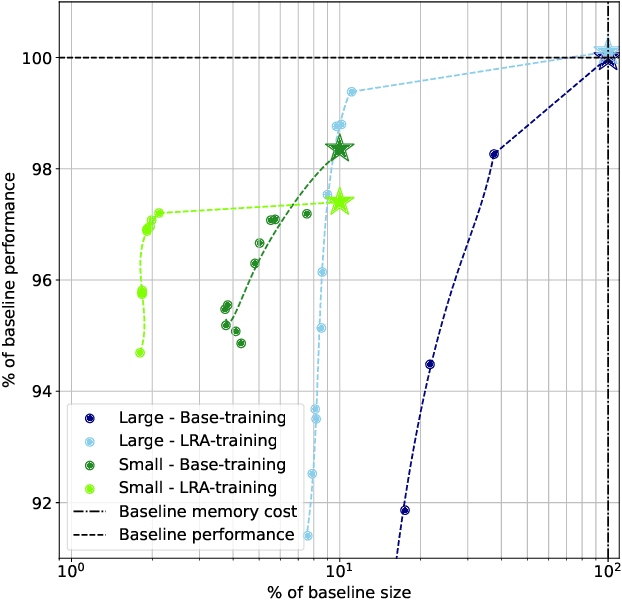
Compressing neural networks is a key step when deploying models for real-time or embedded applications. Factorizing the model's matrices using low-rank approximations is a promising method for achieving compression. While it is possible to set the rank before training, this approach is neither flexible nor optimal. In this work, we propose a post-training rank-selection method called Rank-Tuning that selects a different rank for each matrix. Used in combination with training adaptations, our method achieves high compression rates with no or little performance degradation. Our numerical experiments on signal processing tasks show that we can compress recurrent neural networks up to 14x with at most 1.4% relative performance reduction.
Enhancing Prediction and Analysis of UK Road Traffic Accident Severity Using AI: Integration of Machine Learning, Econometric Techniques, and Time Series Forecasting in Public Health Research
Sep 23, 2023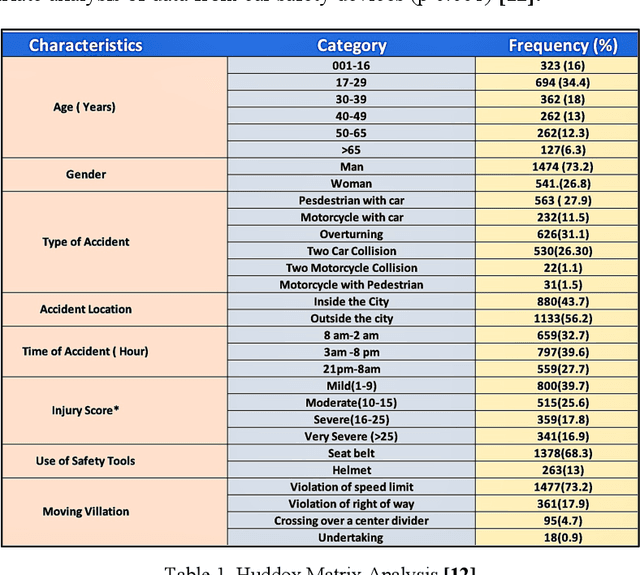
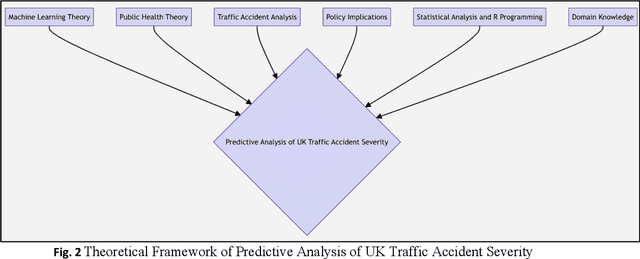
This research investigates road traffic accident severity in the UK, using a combination of machine learning, econometric, and statistical methods on historical data. We employed various techniques, including correlation analysis, regression models, GMM for error term issues, and time-series forecasting with VAR and ARIMA models. Our approach outperforms naive forecasting with an MASE of 0.800 and ME of -73.80. We also built a random forest classifier with 73% precision, 78% recall, and a 73% F1-score. Optimizing with H2O AutoML led to an XGBoost model with an RMSE of 0.176 and MAE of 0.087. Factor Analysis identified key variables, and we used SHAP for Explainable AI, highlighting influential factors like Driver_Home_Area_Type and Road_Type. Our study enhances understanding of accident severity and offers insights for evidence-based road safety policies.
On Extreme Value Asymptotics of Projected Sample Covariances in High Dimensions with Applications in Finance and Convolutional Networks
Oct 12, 2023Maximum-type statistics of certain functions of the sample covariance matrix of high-dimensional vector time series are studied to statistically confirm or reject the null hypothesis that a data set has been collected under normal conditions. The approach generalizes the case of the maximal deviation of the sample autocovariances function from its assumed values. Within a linear time series framework it is shown that Gumbel-type extreme value asymptotics holds true. As applications we discuss long-only mimimal-variance portfolio optimization and subportfolio analysis with respect to idiosyncratic risks, ETF index tracking by sparse tracking portfolios, convolutional deep learners for image analysis and the analysis of array-of-sensors data.
Estimating Uncertainty in Multimodal Foundation Models using Public Internet Data
Oct 15, 2023Foundation models are trained on vast amounts of data at scale using self-supervised learning, enabling adaptation to a wide range of downstream tasks. At test time, these models exhibit zero-shot capabilities through which they can classify previously unseen (user-specified) categories. In this paper, we address the problem of quantifying uncertainty in these zero-shot predictions. We propose a heuristic approach for uncertainty estimation in zero-shot settings using conformal prediction with web data. Given a set of classes at test time, we conduct zero-shot classification with CLIP-style models using a prompt template, e.g., "an image of a <category>", and use the same template as a search query to source calibration data from the open web. Given a web-based calibration set, we apply conformal prediction with a novel conformity score that accounts for potential errors in retrieved web data. We evaluate the utility of our proposed method in Biomedical foundation models; our preliminary results show that web-based conformal prediction sets achieve the target coverage with satisfactory efficiency on a variety of biomedical datasets.
MAD Max Beyond Single-Node: Enabling Large Machine Learning Model Acceleration on Distributed Systems
Oct 18, 2023Training and deploying large machine learning (ML) models is time-consuming and requires significant distributed computing infrastructures. Based on real-world large model training on datacenter-scale infrastructures, we show 14~32% of all GPU hours are spent on communication with no overlapping computation. To minimize the outstanding communication latency, in this work, we develop an agile performance modeling framework to guide parallelization and hardware-software co-design strategies. Using the suite of real-world large ML models on state-of-the-art GPU training hardware, we demonstrate 2.24x and 5.27x throughput improvement potential for pre-training and inference scenarios, respectively.
A Two-Stage 2D Channel Extrapolation Scheme for TDD 5G NR Systems
Oct 13, 2023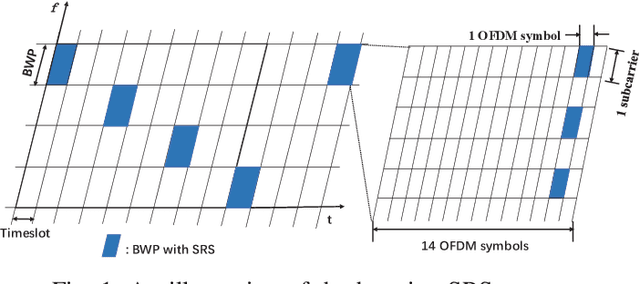
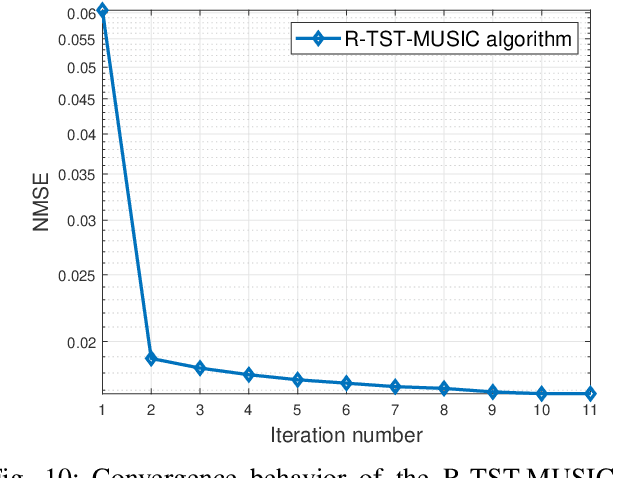
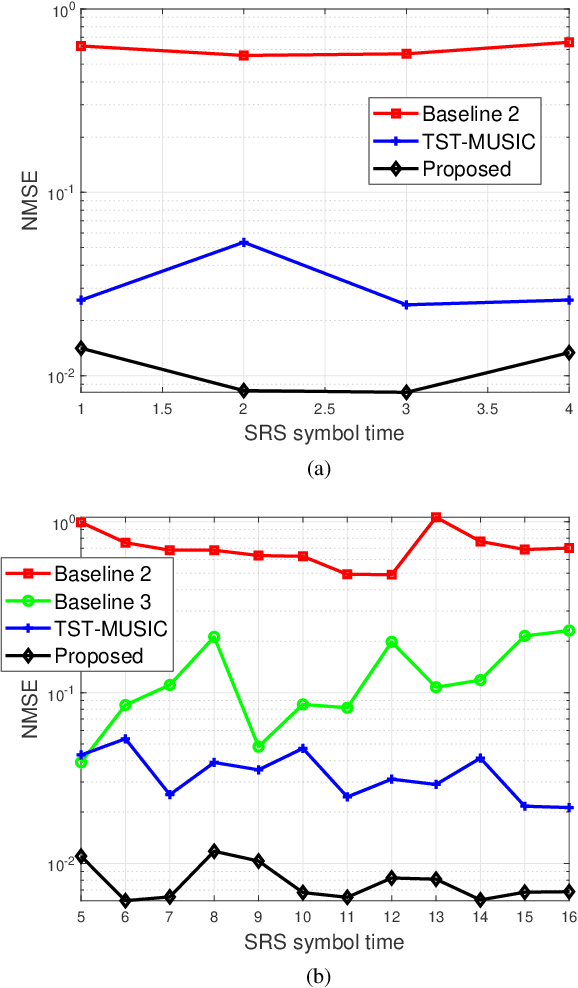

Recently, channel extrapolation has been widely investigated in frequency division duplex (FDD) massive MIMO systems. However, in time division duplex (TDD) fifth generation (5G) new radio (NR) systems, the channel extrapolation problem also arises due to the hopping uplink pilot pattern, which has not been fully researched yet. This paper addresses this gap by formulating a channel extrapolation problem in TDD massive MIMO-OFDM systems for 5G NR, incorporating imperfection factors. A novel two-stage two-dimensional (2D) channel extrapolation scheme in both frequency and time domain is proposed, designed to mitigate the negative effects of imperfection factors and ensure high-accuracy channel estimation. Specifically, in the channel estimation stage, we propose a novel multi-band and multi-timeslot based high-resolution parameter estimation algorithm to achieve 2D channel extrapolation in the presence of imperfection factors. Then, to avoid repeated multi-timeslot based channel estimation, a channel tracking stage is designed during the subsequent time instants, in which a sparse Markov channel model is formulated to capture the dynamic sparsity of massive MIMO-OFDM channels under the influence of imperfection factors. Next, an expectation-maximization (EM) based compressive channel tracking algorithm is designed to jointly estimate unknown imperfection and channel parameters by exploiting the high-resolution prior information of the delay/angle parameters from the previous timeslots. Simulation results underscore the superior performance of our proposed channel extrapolation scheme over baselines.
A Real-Time Active Speaker Detection System Integrating an Audio-Visual Signal with a Spatial Querying Mechanism
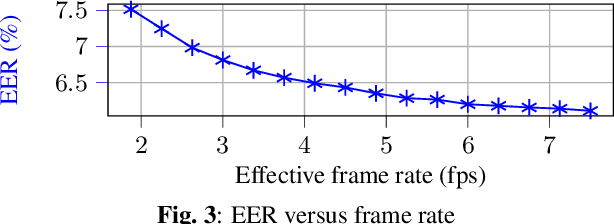
Sep 15, 2023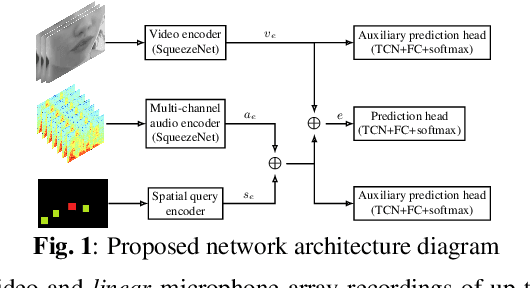


We introduce a distinctive real-time, causal, neural network-based active speaker detection system optimized for low-power edge computing. This system drives a virtual cinematography module and is deployed on a commercial device. The system uses data originating from a microphone array and a 360-degree camera. Our network requires only 127 MFLOPs per participant, for a meeting with 14 participants. Unlike previous work, we examine the error rate of our network when the computational budget is exhausted, and find that it exhibits graceful degradation, allowing the system to operate reasonably well even in this case. Departing from conventional DOA estimation approaches, our network learns to query the available acoustic data, considering the detected head locations. We train and evaluate our algorithm on a realistic meetings dataset featuring up to 14 participants in the same meeting, overlapped speech, and other challenging scenarios.