 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Fatigued Movements for Virtual Character Animation
Oct 12, 2023Virtual character animation and movement synthesis have advanced rapidly during recent years, especially through a combination of extensive motion capture datasets and machine learning. A remaining challenge is interactively simulating characters that fatigue when performing extended motions, which is indispensable for the realism of generated animations. However, capturing such movements is problematic, as performing movements like backflips with fatigued variations up to exhaustion raises capture cost and risk of injury. Surprisingly, little research has been done on faithful fatigue modeling. To address this, we propose a deep reinforcement learning-based approach, which -- for the first time in literature -- generates control policies for full-body physically simulated agents aware of cumulative fatigue. For this, we first leverage Generative Adversarial Imitation Learning (GAIL) to learn an expert policy for the skill; Second, we learn a fatigue policy by limiting the generated constant torque bounds based on endurance time to non-linear, state- and time-dependent limits in the joint-actuation space using a Three-Compartment Controller (3CC) model. Our results demonstrate that agents can adapt to different fatigue and rest rates interactively, and discover realistic recovery strategies without the need for any captured data of fatigued movement.
* 16 pages, 22 figures. To be published in ACM SIGGRAPH Asia Conference Papers 2023. ACM ISBN 979-8-4007-0315-7/23/12
Expanding Synthetic Real-World Degradations for Blind Video Super Resolution
May 04, 2023



Video super-resolution (VSR) techniques, especially deep-learning-based algorithms, have drastically improved over the last few years and shown impressive performance on synthetic data. However, their performance on real-world video data suffers because of the complexity of real-world degradations and misaligned video frames. Since obtaining a synthetic dataset consisting of low-resolution (LR) and high-resolution (HR) frames are easier than obtaining real-world LR and HR images, in this paper, we propose synthesizing real-world degradations on synthetic training datasets. The proposed synthetic real-world degradations (SRWD) include a combination of the blur, noise, downsampling, pixel binning, and image and video compression artifacts. We then propose using a random shuffling-based strategy to simulate these degradations on the training datasets and train a single end-to-end deep neural network (DNN) on the proposed larger variation of realistic synthesized training data. Our quantitative and qualitative comparative analysis shows that the proposed training strategy using diverse realistic degradations improves the performance by 7.1 % in terms of NRQM compared to RealBasicVSR and by 3.34 % compared to BSRGAN on the VideoLQ dataset. We also introduce a new dataset that contains high-resolution real-world videos that can serve as a common ground for bench-marking.
Edge-aware Consistent Stereo Video Depth Estimation
May 04, 2023



Video depth estimation is crucial in various applications, such as scene reconstruction and augmented reality. In contrast to the naive method of estimating depths from images, a more sophisticated approach uses temporal information, thereby eliminating flickering and geometrical inconsistencies. We propose a consistent method for dense video depth estimation; however, unlike the existing monocular methods, ours relates to stereo videos. This technique overcomes the limitations arising from the monocular input. As a benefit of using stereo inputs, a left-right consistency loss is introduced to improve the performance. Besides, we use SLAM-based camera pose estimation in the process. To address the problem of depth blurriness during test-time training (TTT), we present an edge-preserving loss function that improves the visibility of fine details while preserving geometrical consistency. We show that our edge-aware stereo video model can accurately estimate the dense depth maps.
High-Resolution Synthetic RGB-D Datasets for Monocular Depth Estimation
May 02, 2023



Accurate depth maps are essential in various applications, such as autonomous driving, scene reconstruction, point-cloud creation, etc. However, monocular-depth estimation (MDE) algorithms often fail to provide enough texture & sharpness, and also are inconsistent for homogeneous scenes. These algorithms mostly use CNN or vision transformer-based architectures requiring large datasets for supervised training. But, MDE algorithms trained on available depth datasets do not generalize well and hence fail to perform accurately in diverse real-world scenes. Moreover, the ground-truth depth maps are either lower resolution or sparse leading to relatively inconsistent depth maps. In general, acquiring a high-resolution ground truth dataset with pixel-level precision for accurate depth prediction is an expensive, and time-consuming challenge. In this paper, we generate a high-resolution synthetic depth dataset (HRSD) of dimension 1920 X 1080 from Grand Theft Auto (GTA-V), which contains 100,000 color images and corresponding dense ground truth depth maps. The generated datasets are diverse and have scenes from indoors to outdoors, from homogeneous surfaces to textures. For experiments and analysis, we train the DPT algorithm, a state-of-the-art transformer-based MDE algorithm on the proposed synthetic dataset, which significantly increases the accuracy of depth maps on different scenes by 9 %. Since the synthetic datasets are of higher resolution, we propose adding a feature extraction module in the transformer encoder and incorporating an attention-based loss, further improving the accuracy by 15 %.
Synthesis of Compositional Animations from Textual Descriptions
Mar 31, 2021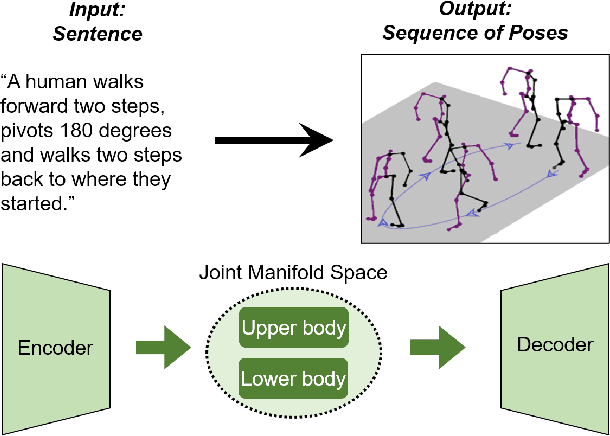
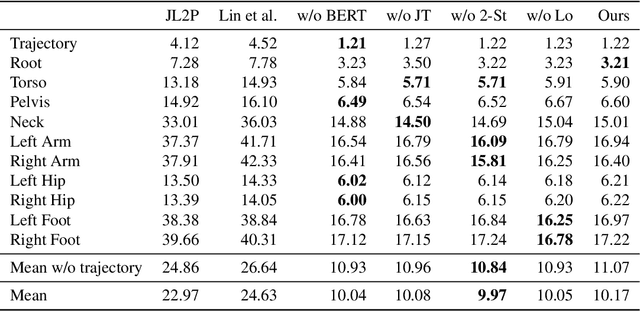
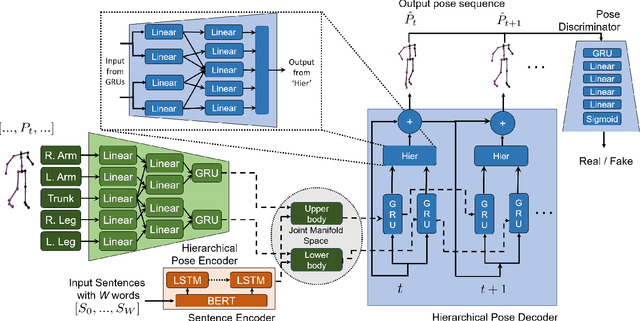
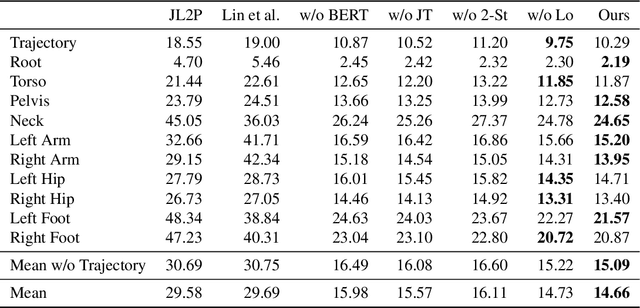
"How can we animate 3D-characters from a movie script or move robots by simply telling them what we would like them to do?" "How unstructured and complex can we make a sentence and still generate plausible movements from it?" These are questions that need to be answered in the long-run, as the field is still in its infancy. Inspired by these problems, we present a new technique for generating compositional actions, which handles complex input sentences. Our output is a 3D pose sequence depicting the actions in the input sentence. We propose a hierarchical two-stream sequential model to explore a finer joint-level mapping between natural language sentences and 3D pose sequences corresponding to the given motion. We learn two manifold representations of the motion -- one each for the upper body and the lower body movements. Our model can generate plausible pose sequences for short sentences describing single actions as well as long compositional sentences describing multiple sequential and superimposed actions. We evaluate our proposed model on the publicly available KIT Motion-Language Dataset containing 3D pose data with human-annotated sentences. Experimental results show that our model advances the state-of-the-art on text-based motion synthesis in objective evaluations by a margin of 50%. Qualitative evaluations based on a user study indicate that our synthesized motions are perceived to be the closest to the ground-truth motion captures for both short and compositional sentences.
Fine-Grained Semantic Segmentation of Motion Capture Data using Dilated Temporal Fully-Convolutional Networks
Mar 02, 2019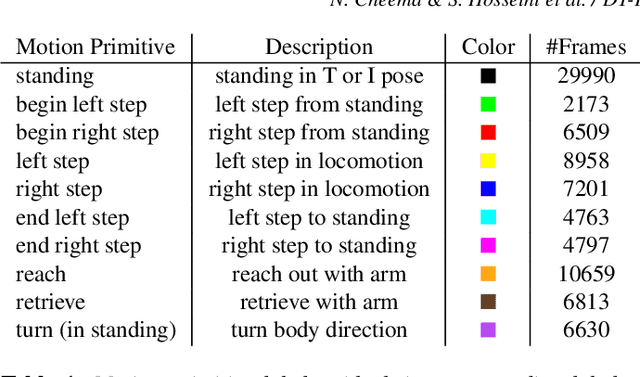

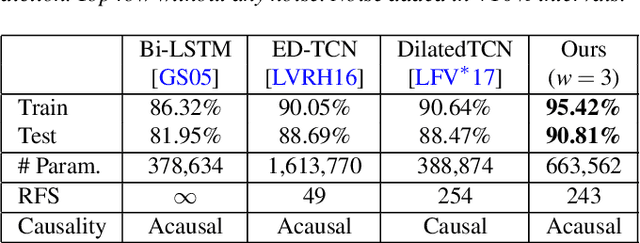
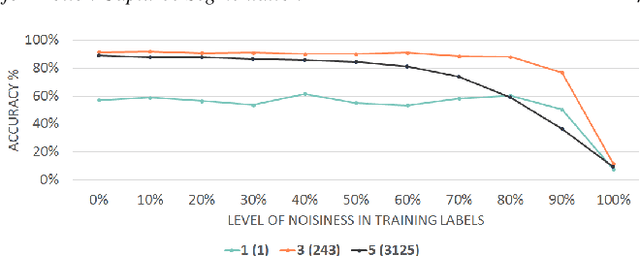
Human motion capture data has been widely used in data-driven character animation. In order to generate realistic, natural-looking motions, most data-driven approaches require considerable efforts of pre-processing, including motion segmentation and annotation. Existing (semi-) automatic solutions either require hand-crafted features for motion segmentation or do not produce the semantic annotations required for motion synthesis and building large-scale motion databases. In addition, human labeled annotation data suffers from inter- and intra-labeler inconsistencies by design. We propose a semi-automatic framework for semantic segmentation of motion capture data based on supervised machine learning techniques. It first transforms a motion capture sequence into a ``motion image'' and applies a convolutional neural network for image segmentation. Dilated temporal convolutions enable the extraction of temporal information from a large receptive field. Our model outperforms two state-of-the-art models for action segmentation, as well as a popular network for sequence modeling. Most of all, our method is very robust under noisy and inaccurate training labels and thus can handle human errors during the labeling process.
Dilated Temporal Fully-Convolutional Network for Semantic Segmentation of Motion Capture Data
Jun 24, 2018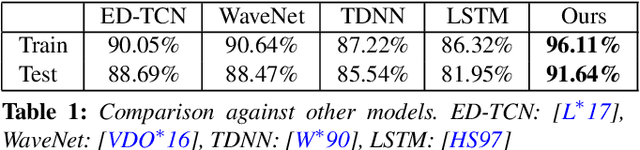
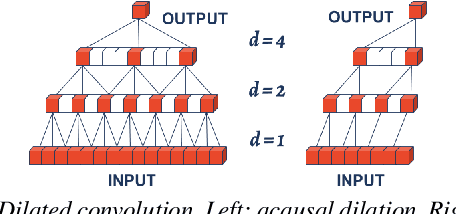
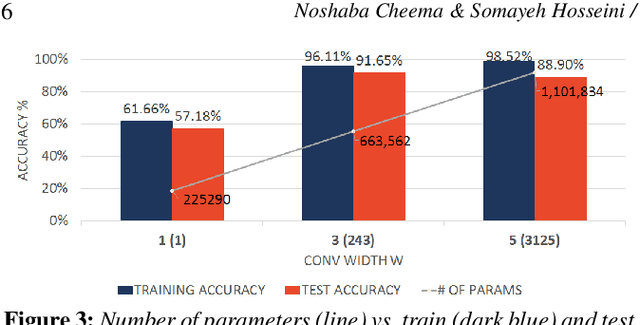
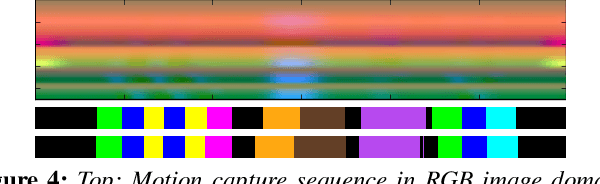
Semantic segmentation of motion capture sequences plays a key part in many data-driven motion synthesis frameworks. It is a preprocessing step in which long recordings of motion capture sequences are partitioned into smaller segments. Afterwards, additional methods like statistical modeling can be applied to each group of structurally-similar segments to learn an abstract motion manifold. The segmentation task however often remains a manual task, which increases the effort and cost of generating large-scale motion databases. We therefore propose an automatic framework for semantic segmentation of motion capture data using a dilated temporal fully-convolutional network. Our model outperforms a state-of-the-art model in action segmentation, as well as three networks for sequence modeling. We further show our model is robust against high noisy training labels.