 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mobile-Seed: Joint Semantic Segmentation and Boundary Detection for Mobile Robots
Nov 23, 2023
Precise and rapid delineation of sharp boundaries and robust semantics is essential for numerous downstream robotic tasks, such as robot grasping and manipulation, real-time semantic mapping, and online sensor calibration performed on edge computing units. Although boundary detection and semantic segmentation are complementary tasks, most studies focus on lightweight models for semantic segmentation but overlook the critical role of boundary detection. In this work, we introduce Mobile-Seed, a lightweight, dual-task framework tailored for simultaneous semantic segmentation and boundary detection. Our framework features a two-stream encoder, an active fusion decoder (AFD) and a dual-task regularization approach. The encoder is divided into two pathways: one captures category-aware semantic information, while the other discerns boundaries from multi-scale features. The AFD module dynamically adapts the fusion of semantic and boundary information by learning channel-wise relationships, allowing for precise weight assignment of each channel. Furthermore, we introduce a regularization loss to mitigate the conflicts in dual-task learning and deep diversity supervision. Compared to existing methods, the proposed Mobile-Seed offers a lightweight framework to simultaneously improve semantic segmentation performance and accurately locate object boundaries. Experiments on the Cityscapes dataset have shown that Mobile-Seed achieves notable improvement over the state-of-the-art (SOTA) baseline by 2.2 percentage points (pp) in mIoU and 4.2 pp in mF-score, while maintaining an online inference speed of 23.9 frames-per-second (FPS) with 1024x2048 resolution input on an RTX 2080 Ti GPU. Additional experiments on CamVid and PASCAL Context datasets confirm our method's generalizability. Code and additional results are publicly available at https://whu-usi3dv.github.io/Mobile-Seed/.
Unraveling the Control Engineer's Craft with Neural Networks
Nov 20, 2023Many industrial processes require suitable controllers to meet their performance requirements. More often, a sophisticated digital twin is available, which is a highly complex model that is a virtual representation of a given physical process, whose parameters may not be properly tuned to capture the variations in the physical process. In this paper, we present a sim2real, direct data-driven controller tuning approach, where the digital twin is used to generate input-output data and suitable controllers for several perturbations in its parameters. State-of-the art neural-network architectures are then used to learn the controller tuning rule that maps input-output data onto the controller parameters, based on artificially generated data from perturbed versions of the digital twin. In this way, as far as we are aware, we tackle for the first time the problem of re-calibrating the controller by meta-learning the tuning rule directly from data, thus practically replacing the control engineer with a machine learning model. The benefits of this methodology are illustrated via numerical simulations for several choices of neural-network architectures.
A Multi-In-Single-Out Network for Video Frame Interpolation without Optical Flow
Nov 20, 2023In general, deep learning-based video frame interpolation (VFI) methods have predominantly focused on estimating motion vectors between two input frames and warping them to the target time. While this approach has shown impressive performance for linear motion between two input frames, it exhibits limitations when dealing with occlusions and nonlinear movements. Recently, generative models have been applied to VFI to address these issues. However, as VFI is not a task focused on generating plausible images, but rather on predicting accurate intermediate frames between two given frames, performance limitations still persist. In this paper, we propose a multi-in-single-out (MISO) based VFI method that does not rely on motion vector estimation, allowing it to effectively model occlusions and nonlinear motion. Additionally, we introduce a novel motion perceptual loss that enables MISO-VFI to better capture the spatio-temporal correlations within the video frames. Our MISO-VFI method achieves state-of-the-art results on VFI benchmarks Vimeo90K, Middlebury, and UCF101, with a significant performance gap compared to existing approaches.
Practical cross-sensor color constancy using a dual-mapping strategy
Nov 20, 2023Deep Neural Networks (DNNs) have been widely used for illumination estimation, which is time-consuming and requires sensor-specific data collection. Our proposed method uses a dual-mapping strategy and only requires a simple white point from a test sensor under a D65 condition. This allows us to derive a mapping matrix, enabling the reconstructions of image data and illuminants. In the second mapping phase, we transform the re-constructed image data into sparse features, which are then optimized with a lightweight multi-layer perceptron (MLP) model using the re-constructed illuminants as ground truths. This approach effectively reduces sensor discrepancies and delivers performance on par with leading cross-sensor methods. It only requires a small amount of memory (~0.003 MB), and takes ~1 hour training on an RTX3070Ti GPU. More importantly, the method can be implemented very fast, with ~0.3 ms and ~1 ms on a GPU or CPU respectively, and is not sensitive to the input image resolution. Therefore, it offers a practical solution to the great challenges of data recollection that is faced by the industry.
Towards Automatic Honey Bee Flower-Patch Assays with Paint Marking Re-Identification
Nov 13, 2023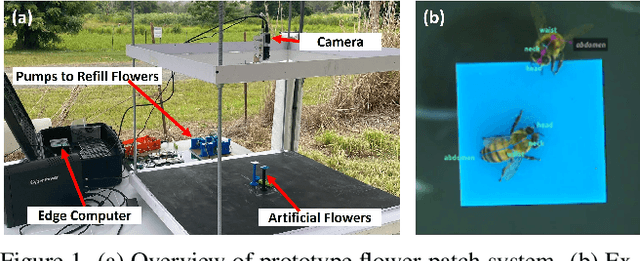
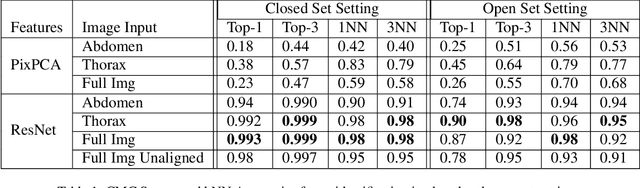

In this paper, we show that paint markings are a feasible approach to automatize the analysis of behavioral assays involving honey bees in the field where marking has to be as lightweight as possible. We contribute a novel dataset for bees re-identification with paint-markings with 4392 images and 27 identities. Contrastive learning with a ResNet backbone and triplet loss led to identity representation features with almost perfect recognition in closed setting where identities are known in advance. Diverse experiments evaluate the capability to generalize to separate IDs, and show the impact of using different body parts for identification, such as using the unmarked abdomen only. In addition, we show the potential to fully automate the visit detection and provide preliminary results of compute time for future real-time deployment in the field on an edge device.
Open-Fusion: Real-time Open-Vocabulary 3D Mapping and Queryable Scene Representation
Oct 05, 2023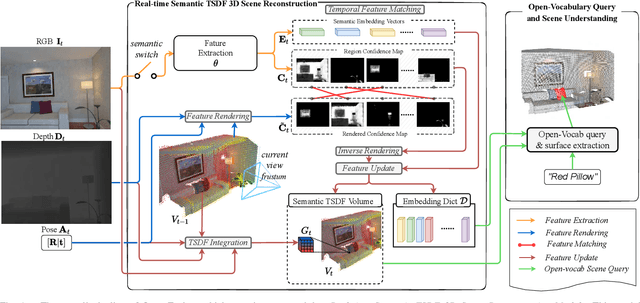

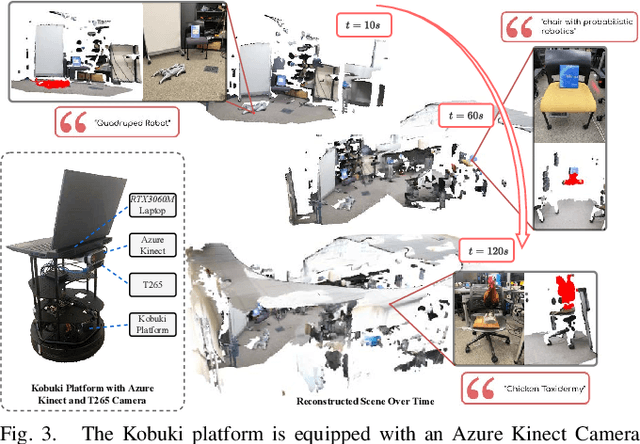

Precise 3D environmental mapping is pivotal in robotics. Existing methods often rely on predefined concepts during training or are time-intensive when generating semantic maps. This paper presents Open-Fusion, a groundbreaking approach for real-time open-vocabulary 3D mapping and queryable scene representation using RGB-D data. Open-Fusion harnesses the power of a pre-trained vision-language foundation model (VLFM) for open-set semantic comprehension and employs the Truncated Signed Distance Function (TSDF) for swift 3D scene reconstruction. By leveraging the VLFM, we extract region-based embeddings and their associated confidence maps. These are then integrated with 3D knowledge from TSDF using an enhanced Hungarian-based feature-matching mechanism. Notably, Open-Fusion delivers outstanding annotation-free 3D segmentation for open-vocabulary without necessitating additional 3D training. Benchmark tests on the ScanNet dataset against leading zero-shot methods highlight Open-Fusion's superiority. Furthermore, it seamlessly combines the strengths of region-based VLFM and TSDF, facilitating real-time 3D scene comprehension that includes object concepts and open-world semantics. We encourage the readers to view the demos on our project page: https://uark-aicv.github.io/OpenFusion
Astrocytes as a mechanism for meta-plasticity and contextually-guided network function
Nov 10, 2023Astrocytes are a ubiquitous and enigmatic type of non-neuronal cell and are found in the brain of all vertebrates. While traditionally viewed as being supportive of neurons, it is increasingly recognized that astrocytes may play a more direct and active role in brain function and neural computation. On account of their sensitivity to a host of physiological covariates and ability to modulate neuronal activity and connectivity on slower time scales, astrocytes may be particularly well poised to modulate the dynamics of neural circuits in functionally salient ways. In the current paper, we seek to capture these features via actionable abstractions within computational models of neuron-astrocyte interaction. Specifically, we engage how nested feedback loops of neuron-astrocyte interaction, acting over separated time-scales may endow astrocytes with the capability to enable learning in context-dependent settings, where fluctuations in task parameters may occur much more slowly than within-task requirements. We pose a general model of neuron-synapse-astrocyte interaction and use formal analysis to characterize how astrocytic modulation may constitute a form of meta-plasticity, altering the ways in which synapses and neurons adapt as a function of time. We then embed this model in a bandit-based reinforcement learning task environment, and show how the presence of time-scale separated astrocytic modulation enables learning over multiple fluctuating contexts. Indeed, these networks learn far more reliably versus dynamically homogeneous networks and conventional non-network-based bandit algorithms. Our results indicate how the presence of neuron-astrocyte interaction in the brain may benefit learning over different time-scales and the conveyance of task-relevant contextual information onto circuit dynamics.
Fast Heavy Inner Product Identification Between Weights and Inputs in Neural Network Training
Nov 19, 2023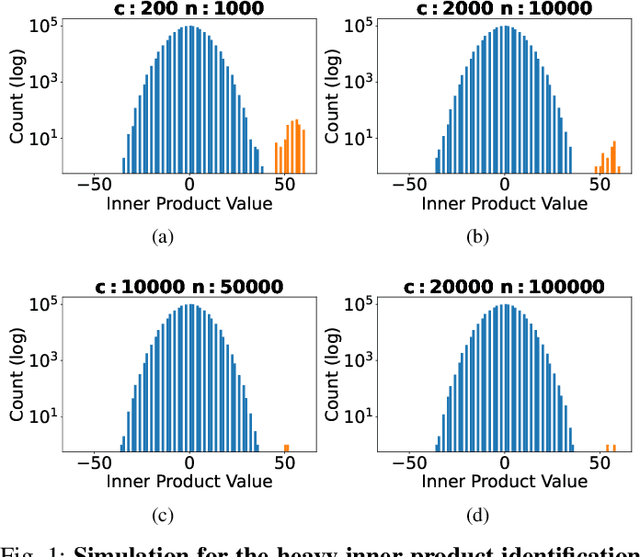
In this paper, we consider a heavy inner product identification problem, which generalizes the Light Bulb problem~(\cite{prr89}): Given two sets $A \subset \{-1,+1\}^d$ and $B \subset \{-1,+1\}^d$ with $|A|=|B| = n$, if there are exact $k$ pairs whose inner product passes a certain threshold, i.e., $\{(a_1, b_1), \cdots, (a_k, b_k)\} \subset A \times B$ such that $\forall i \in [k], \langle a_i,b_i \rangle \geq \rho \cdot d$, for a threshold $\rho \in (0,1)$, the goal is to identify those $k$ heavy inner products. We provide an algorithm that runs in $O(n^{2 \omega / 3+ o(1)})$ time to find the $k$ inner product pairs that surpass $\rho \cdot d$ threshold with high probability, where $\omega$ is the current matrix multiplication exponent. By solving this problem, our method speed up the training of neural networks with ReLU activation function.
Large-scale Mixed Traffic Control Using Dynamic Vehicle Routing and Privacy-Preserving Crowdsourcing
Nov 19, 2023Controlling and coordinating urban traffic flow through robot vehicles is emerging as a novel transportation paradigm for the future. While this approach garners growing attention from researchers and practitioners, effectively managing and coordinating large-scale mixed traffic remains a challenge. We introduce an effective framework for large-scale mixed traffic control via privacy-preserving crowdsourcing and dynamic vehicle routing. Our framework consists of three modules: a privacy-protecting crowdsensing method, a graph propagation-based traffic forecasting method, and a privacy-preserving route selection mechanism. We evaluate our framework using a real-world road network. The results show that our framework accurately forecasts traffic flow, efficiently mitigates network-wide RV shortage issue, and coordinates large-scale mixed traffic. Compared to other baseline methods, our framework not only reduces the RV shortage issue up to 69.4% but also reduces the average waiting time of all vehicles in the network up to 27%.
RT-SRTS: Angle-Agnostic Real-Time Simultaneous 3D Reconstruction and Tumor Segmentation from Single X-Ray Projection
Oct 12, 2023Radiotherapy is one of the primary treatment methods for tumors, but the organ movement caused by respiratory motion limits its accuracy. Recently, 3D imaging from single X-ray projection receives extensive attentions as a promising way to address this issue. However, current methods can only reconstruct 3D image without direct location of the tumor and are only validated for fixed-angle imaging, which fails to fully meet the requirement of motion control in radiotherapy. In this study, we propose a novel imaging method RT-SRTS which integrates 3D imaging and tumor segmentation into one network based on the multi-task learning (MTL) and achieves real-time simultaneous 3D reconstruction and tumor segmentation from single X-ray projection at any angle. Futhermore, we propose the attention enhanced calibrator (AEC) and uncertain-region elaboration (URE) modules to aid feature extraction and improve segmentation accuracy. We evaluated the proposed method on ten patient cases and compared it with two state-of-the-art methods. Our approach not only delivered superior 3D reconstruction but also demonstrated commendable tumor segmentation results. The simultaneous reconstruction and segmentation could be completed in approximately 70 ms, significantly faster than the required time threshold for real-time tumor tracking. The efficacy of both AEC and URE was also validated through ablation studies.