 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
Nov 28, 2023
Contrastive pretraining of image-text foundation models, such as CLIP, demonstrated excellent zero-shot performance and improved robustness on a wide range of downstream tasks. However, these models utilize large transformer-based encoders with significant memory and latency overhead which pose challenges for deployment on mobile devices. In this work, we introduce MobileCLIP -- a new family of efficient image-text models optimized for runtime performance along with a novel and efficient training approach, namely multi-modal reinforced training. The proposed training approach leverages knowledge transfer from an image captioning model and an ensemble of strong CLIP encoders to improve the accuracy of efficient models. Our approach avoids train-time compute overhead by storing the additional knowledge in a reinforced dataset. MobileCLIP sets a new state-of-the-art latency-accuracy tradeoff for zero-shot classification and retrieval tasks on several datasets. Our MobileCLIP-S2 variant is 2.3$\times$ faster while more accurate compared to previous best CLIP model based on ViT-B/16. We further demonstrate the effectiveness of our multi-modal reinforced training by training a CLIP model based on ViT-B/16 image backbone and achieving +2.9% average performance improvement on 38 evaluation benchmarks compared to the previous best. Moreover, we show that the proposed approach achieves 10$\times$-1000$\times$ improved learning efficiency when compared with non-reinforced CLIP training.
GSP-KalmanNet: Tracking Graph Signals via Neural-Aided Kalman Filtering
Nov 28, 2023Dynamic systems of graph signals are encountered in various applications, including social networks, power grids, and transportation. While such systems can often be described as state space (SS) models, tracking graph signals via conventional tools based on the Kalman filter (KF) and its variants is typically challenging. This is due to the nonlinearity, high dimensionality, irregularity of the domain, and complex modeling associated with real-world dynamic systems of graph signals. In this work, we study the tracking of graph signals using a hybrid model-based/data-driven approach. We develop the GSP-KalmanNet, which tracks the hidden graphical states from the graphical measurements by jointly leveraging graph signal processing (GSP) tools and deep learning (DL) techniques. The derivations of the GSP-KalmanNet are based on extending the KF to exploit the inherent graph structure via graph frequency domain filtering, which considerably simplifies the computational complexity entailed in processing high-dimensional signals and increases the robustness to small topology changes. Then, we use data to learn the Kalman gain following the recently proposed KalmanNet framework, which copes with partial and approximated modeling, without forcing a specific model over the noise statistics. Our empirical results demonstrate that the proposed GSP-KalmanNet achieves enhanced accuracy and run time performance as well as improved robustness to model misspecifications compared with both model-based and data-driven benchmarks.
StreamFlow: Streamlined Multi-Frame Optical Flow Estimation for Video Sequences
Nov 28, 2023Occlusions between consecutive frames have long posed a significant challenge in optical flow estimation. The inherent ambiguity introduced by occlusions directly violates the brightness constancy constraint and considerably hinders pixel-to-pixel matching. To address this issue, multi-frame optical flow methods leverage adjacent frames to mitigate the local ambiguity. Nevertheless, prior multi-frame methods predominantly adopt recursive flow estimation, resulting in a considerable computational overlap. In contrast, we propose a streamlined in-batch framework that eliminates the need for extensive redundant recursive computations while concurrently developing effective spatio-temporal modeling approaches under in-batch estimation constraints. Specifically, we present a Streamlined In-batch Multi-frame (SIM) pipeline tailored to video input, attaining a similar level of time efficiency to two-frame networks. Furthermore, we introduce an efficient Integrative Spatio-temporal Coherence (ISC) modeling method for effective spatio-temporal modeling during the encoding phase, which introduces no additional parameter overhead. Additionally, we devise a Global Temporal Regressor (GTR) that effectively explores temporal relations during decoding. Benefiting from the efficient SIM pipeline and effective modules, StreamFlow not only excels in terms of performance on the challenging KITTI and Sintel datasets, with particular improvement in occluded areas but also attains a remarkable $63.82\%$ enhancement in speed compared with previous multi-frame methods. The code will be available soon at https://github.com/littlespray/StreamFlow.
SCStory: Self-supervised and Continual Online Story Discovery
Nov 27, 2023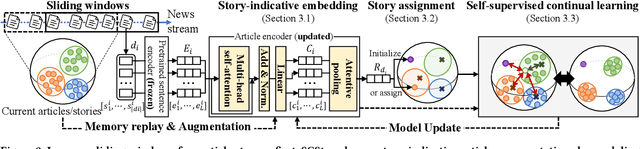
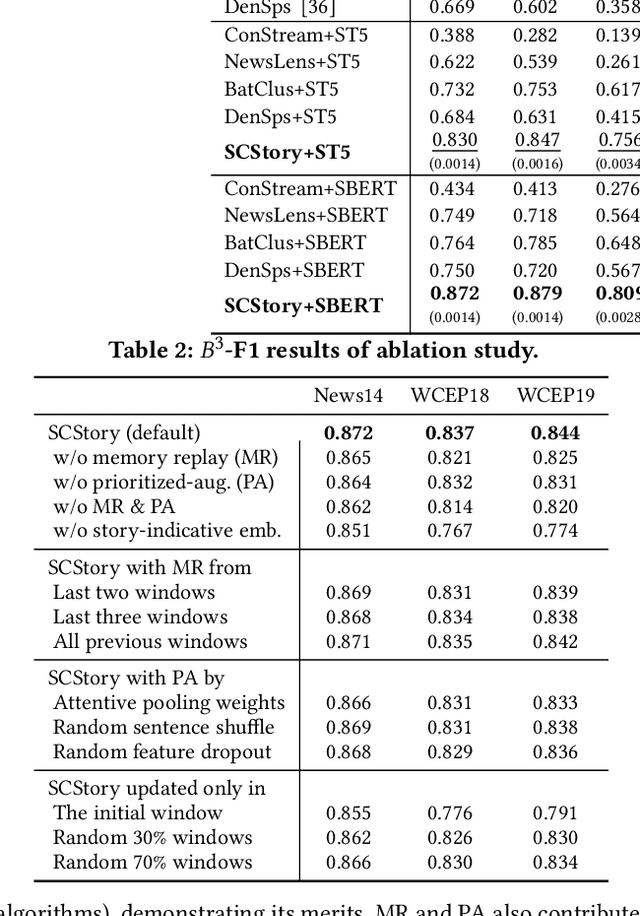
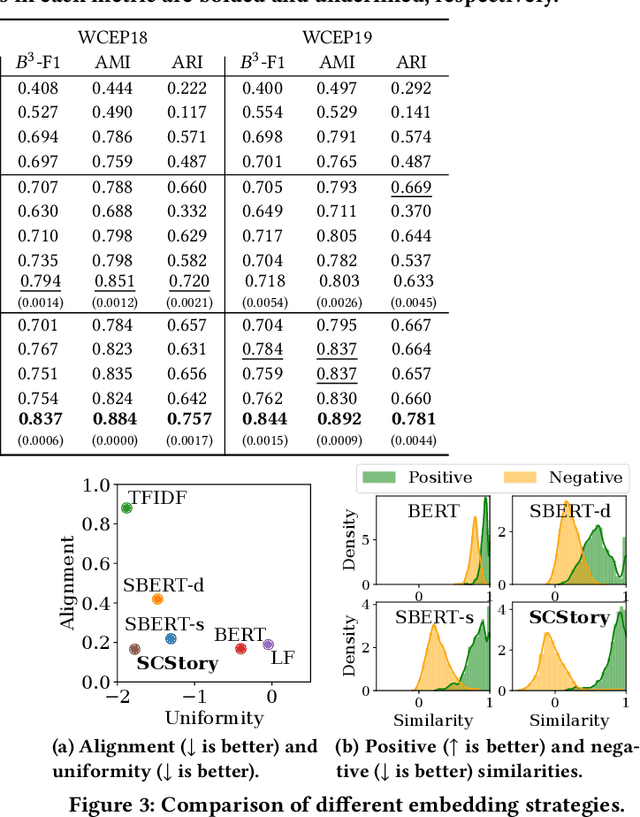
We present a framework SCStory for online story discovery, that helps people digest rapidly published news article streams in real-time without human annotations. To organize news article streams into stories, existing approaches directly encode the articles and cluster them based on representation similarity. However, these methods yield noisy and inaccurate story discovery results because the generic article embeddings do not effectively reflect the story-indicative semantics in an article and cannot adapt to the rapidly evolving news article streams. SCStory employs self-supervised and continual learning with a novel idea of story-indicative adaptive modeling of news article streams. With a lightweight hierarchical embedding module that first learns sentence representations and then article representations, SCStory identifies story-relevant information of news articles and uses them to discover stories. The embedding module is continuously updated to adapt to evolving news streams with a contrastive learning objective, backed up by two unique techniques, confidence-aware memory replay and prioritized-augmentation, employed for label absence and data scarcity problems. Thorough experiments on real and the latest news data sets demonstrate that SCStory outperforms existing state-of-the-art algorithms for unsupervised online story discovery.
Robust Self-calibration of Focal Lengths from the Fundamental Matrix
Nov 27, 2023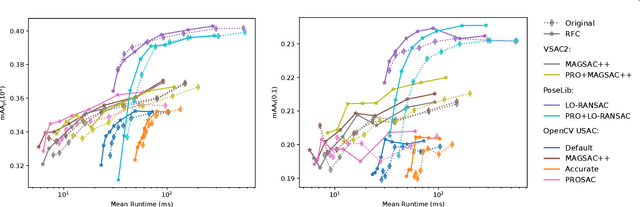
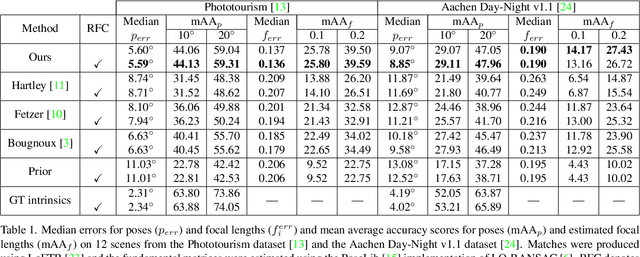
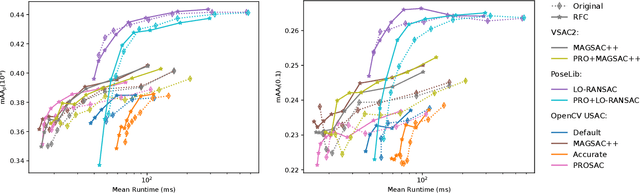
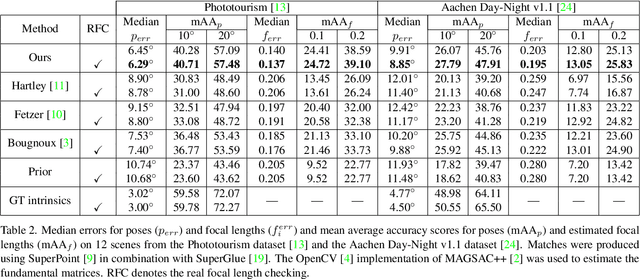
The problem of self-calibration of two cameras from a given fundamental matrix is one of the basic problems in geometric computer vision. Under the assumption of known principal points and square pixels, the well-known Bougnoux formula offers a means to compute the two unknown focal lengths. However, in many practical situations, the formula yields inaccurate results due to commonly occurring singularities. Moreover, the estimates are sensitive to noise in the computed fundamental matrix and to the assumed positions of the principal points. In this paper, we therefore propose an efficient and robust iterative method to estimate the focal lengths along with the principal points of the cameras given a fundamental matrix and priors for the estimated camera parameters. In addition, we study a computationally efficient check of models generated within RANSAC that improves the accuracy of the estimated models while reducing the total computational time. Extensive experiments on real and synthetic data show that our iterative method brings significant improvements in terms of the accuracy of the estimated focal lengths over the Bougnoux formula and other state-of-the-art methods, even when relying on inaccurate priors.
Auto-CsiNet: Scenario-customized Automatic Neural Network Architecture Generation for Massive MIMO CSI Feedback
Nov 27, 2023Deep learning has revolutionized the design of the channel state information (CSI) feedback module in wireless communications. However, designing the optimal neural network (NN) architecture for CSI feedback can be a laborious and time-consuming process. Manual design can be prohibitively expensive for customizing NNs to different scenarios. This paper proposes using neural architecture search (NAS) to automate the generation of scenario-customized CSI feedback NN architectures, thereby maximizing the potential of deep learning in exclusive environments. By employing automated machine learning and gradient-descent-based NAS, an efficient and cost-effective architecture design process is achieved. The proposed approach leverages implicit scene knowledge, integrating it into the scenario customization process in a data-driven manner, and fully exploits the potential of deep learning for each specific scenario. To address the issue of excessive search, early stopping and elastic selection mechanisms are employed, enhancing the efficiency of the proposed scheme. The experimental results demonstrate that the automatically generated architecture, known as Auto-CsiNet, outperforms manually-designed models in both reconstruction performance (achieving approximately a 14% improvement) and complexity (reducing it by approximately 50%). Furthermore, the paper analyzes the impact of the scenario on the NN architecture and its capacity.
InterControl: Generate Human Motion Interactions by Controlling Every Joint
Nov 27, 2023Text-conditioned human motion generation model has achieved great progress by introducing diffusion models and corresponding control signals. However, the interaction between humans are still under explored. To model interactions of arbitrary number of humans, we define interactions as human joint pairs that are either in contact or separated, and leverage {\em Large Language Model (LLM) Planner} to translate interaction descriptions into contact plans. Based on the contact plans, interaction generation could be achieved by spatially controllable motion generation methods by taking joint contacts as spatial conditions. We present a novel approach named InterControl for flexible spatial control of every joint in every person at any time by leveraging motion diffusion model only trained on single-person data. We incorporate a motion controlnet to generate coherent and realistic motions given sparse spatial control signals and a loss guidance module to precisely align any joint to the desired position in a classifier guidance manner via Inverse Kinematics (IK). Extensive experiments on HumanML3D and KIT-ML dataset demonstrate its effectiveness in versatile joint control. We also collect data of joint contact pairs by LLMs to show InterControl's ability in human interaction generation.
Spatial Diarization for Meeting Transcription with Ad-Hoc Acoustic Sensor Networks
Nov 27, 2023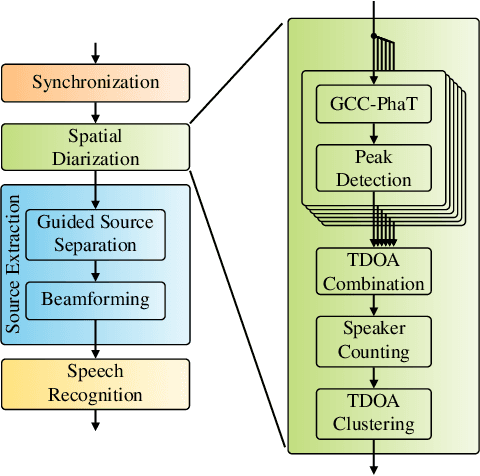
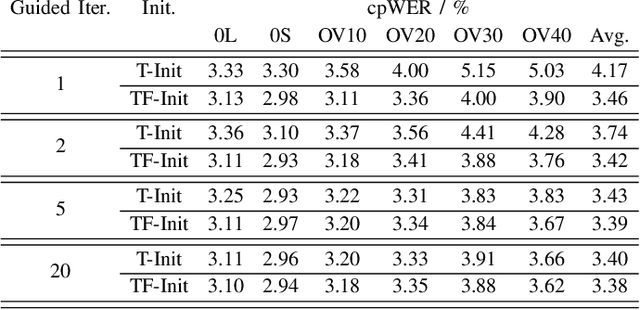
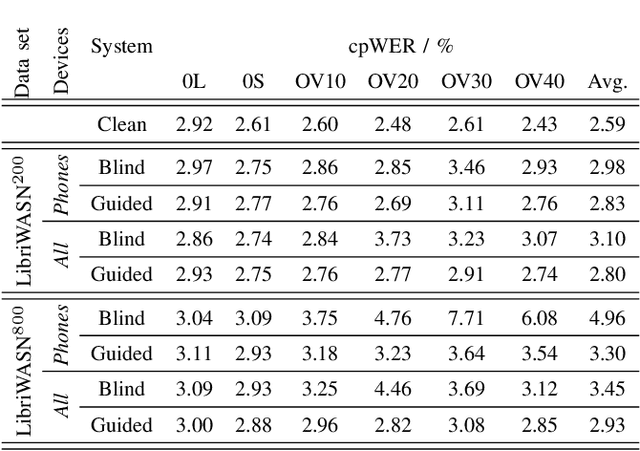
We propose a diarization system, that estimates "who spoke when" based on spatial information, to be used as a front-end of a meeting transcription system running on the signals gathered from an acoustic sensor network (ASN). Although the spatial distribution of the microphones is advantageous, exploiting the spatial diversity for diarization and signal enhancement is challenging, because the microphones' positions are typically unknown, and the recorded signals are initially unsynchronized in general. Here, we approach these issues by first blindly synchronizing the signals and then estimating time differences of arrival (TDOAs). The TDOA information is exploited to estimate the speakers' activity, even in the presence of multiple speakers being simultaneously active. This speaker activity information serves as a guide for a spatial mixture model, on which basis the individual speaker's signals are extracted via beamforming. Finally, the extracted signals are forwarded to a speech recognizer. Additionally, a novel initialization scheme for spatial mixture models based on the TDOA estimates is proposed. Experiments conducted on real recordings from the LibriWASN data set have shown that our proposed system is advantageous compared to a system using a spatial mixture model, which does not make use of external diarization information.
A Simple Geometric-Aware Indoor Positioning Interpolation Algorithm Based on Manifold Learning
Nov 27, 2023Interpolation methodologies have been widely used within the domain of indoor positioning systems. However, existing indoor positioning interpolation algorithms exhibit several inherent limitations, including reliance on complex mathematical models, limited flexibility, and relatively low precision. To enhance the accuracy and efficiency of indoor positioning interpolation techniques, this paper proposes a simple yet powerful geometric-aware interpolation algorithm for indoor positioning tasks. The key to our algorithm is to exploit the geometric attributes of the local topological manifold using manifold learning principles. Therefore, instead of constructing complicated mathematical models, the proposed algorithm facilitates the more precise and efficient estimation of points grounded in the local topological manifold. Moreover, our proposed method can be effortlessly integrated into any indoor positioning system, thereby bolstering its adaptability. Through a systematic array of experiments and comprehensive performance analyses conducted on both simulated and real-world datasets, we demonstrate that the proposed algorithm consistently outperforms the most commonly used and representative interpolation approaches regarding interpolation accuracy and efficiency. Furthermore, the experimental results also underscore the substantial practical utility of our method and its potential applicability in real-time indoor positioning scenarios.
Generalized Mixture Model for Extreme Events Forecasting in Time Series Data
Oct 11, 2023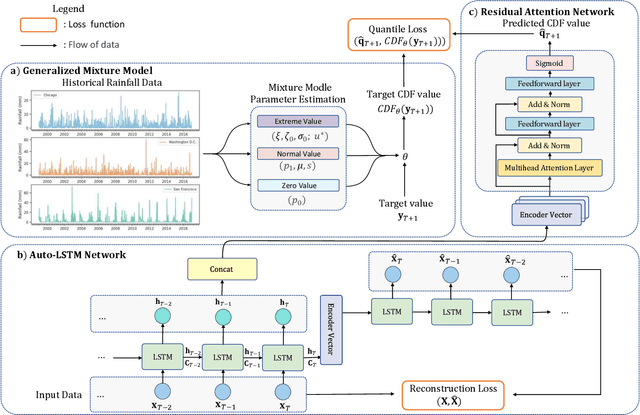
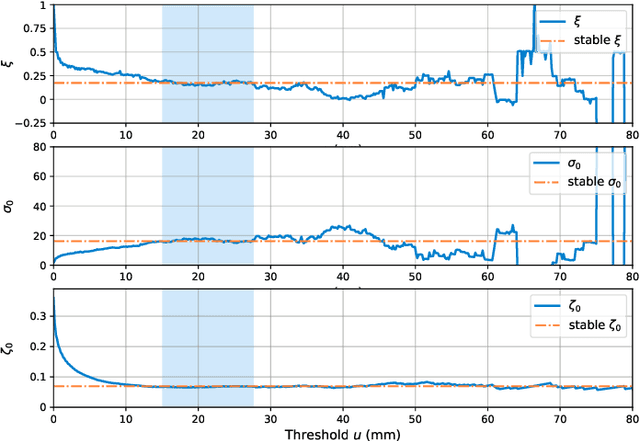
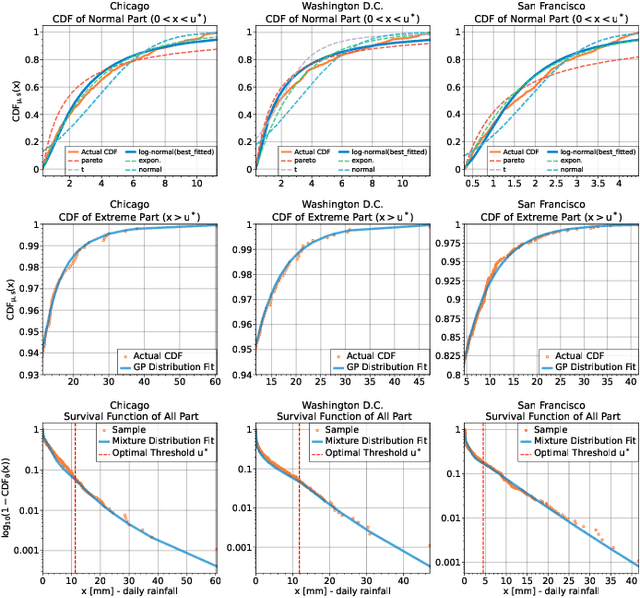
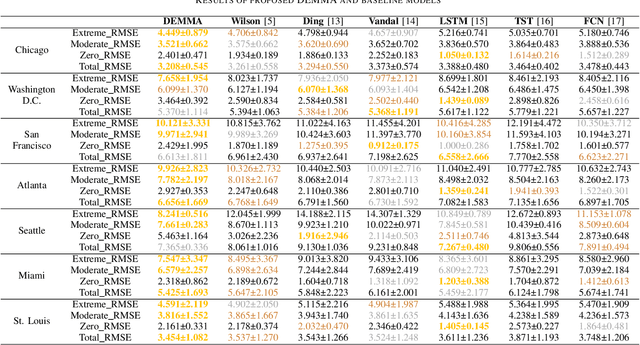
Time Series Forecasting (TSF) is a widely researched topic with broad applications in weather forecasting, traffic control, and stock price prediction. Extreme values in time series often significantly impact human and natural systems, but predicting them is challenging due to their rare occurrence. Statistical methods based on Extreme Value Theory (EVT) provide a systematic approach to modeling the distribution of extremes, particularly the Generalized Pareto (GP) distribution for modeling the distribution of exceedances beyond a threshold. To overcome the subpar performance of deep learning in dealing with heavy-tailed data, we propose a novel framework to enhance the focus on extreme events. Specifically, we propose a Deep Extreme Mixture Model with Autoencoder (DEMMA) for time series prediction. The model comprises two main modules: 1) a generalized mixture distribution based on the Hurdle model and a reparameterized GP distribution form independent of the extreme threshold, 2) an Autoencoder-based LSTM feature extractor and a quantile prediction module with a temporal attention mechanism. We demonstrate the effectiveness of our approach on multiple real-world rainfall datasets.