 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Projecting infinite time series graphs to finite marginal graphs using number theory
Oct 09, 2023
In recent years, a growing number of method and application works have adapted and applied the causal-graphical-model framework to time series data. Many of these works employ time-resolved causal graphs that extend infinitely into the past and future and whose edges are repetitive in time, thereby reflecting the assumption of stationary causal relationships. However, most results and algorithms from the causal-graphical-model framework are not designed for infinite graphs. In this work, we develop a method for projecting infinite time series graphs with repetitive edges to marginal graphical models on a finite time window. These finite marginal graphs provide the answers to $m$-separation queries with respect to the infinite graph, a task that was previously unresolved. Moreover, we argue that these marginal graphs are useful for causal discovery and causal effect estimation in time series, effectively enabling to apply results developed for finite graphs to the infinite graphs. The projection procedure relies on finding common ancestors in the to-be-projected graph and is, by itself, not new. However, the projection procedure has not yet been algorithmically implemented for time series graphs since in these infinite graphs there can be infinite sets of paths that might give rise to common ancestors. We solve the search over these possibly infinite sets of paths by an intriguing combination of path-finding techniques for finite directed graphs and solution theory for linear Diophantine equations. By providing an algorithm that carries out the projection, our paper makes an important step towards a theoretically-grounded and method-agnostic generalization of a range of causal inference methods and results to time series.
Enhancing Summarization Performance through Transformer-Based Prompt Engineering in Automated Medical Reporting
Nov 22, 2023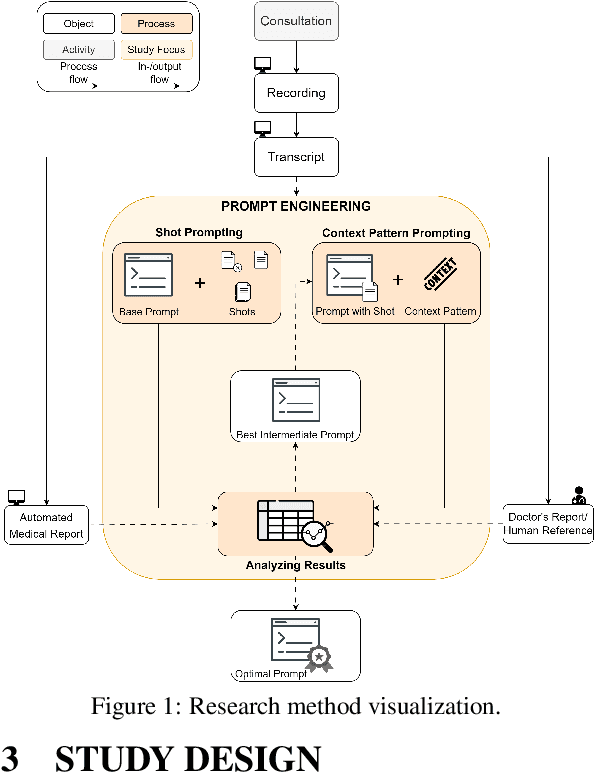
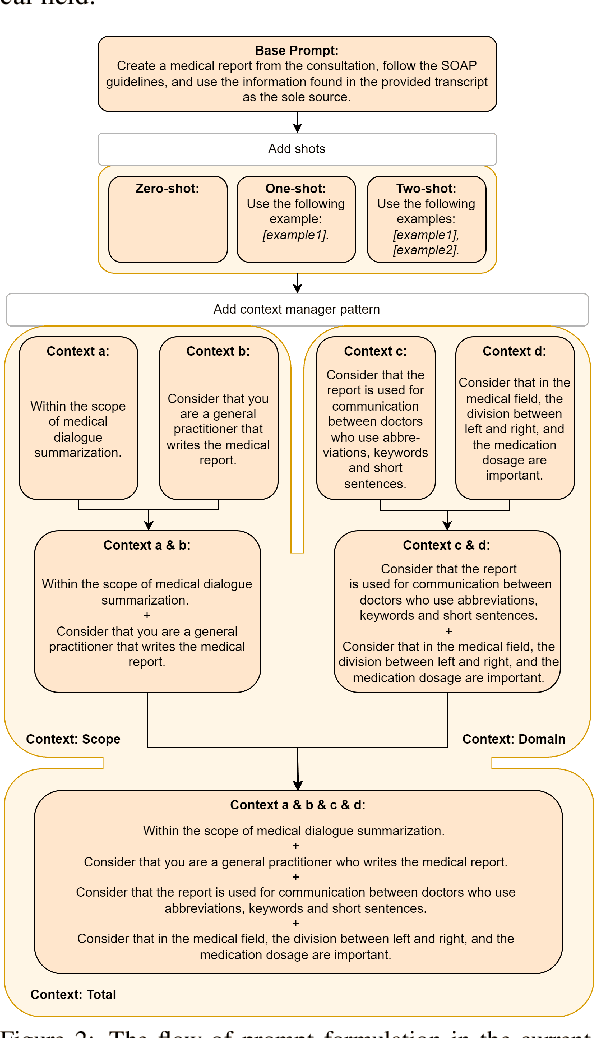
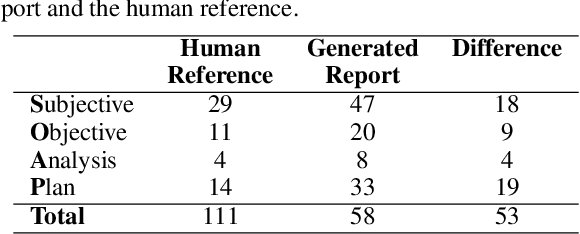

Customized medical prompts enable Large Language Models (LLM) to effectively address medical dialogue summarization. The process of medical reporting is often time-consuming for healthcare professionals. Implementing medical dialogue summarization techniques presents a viable solution to alleviate this time constraint by generating automated medical reports. The effectiveness of LLMs in this process is significantly influenced by the formulation of the prompt, which plays a crucial role in determining the quality and relevance of the generated reports. In this research, we used a combination of two distinct prompting strategies, known as shot prompting and pattern prompting to enhance the performance of automated medical reporting. The evaluation of the automated medical reports is carried out using the ROUGE score and a human evaluation with the help of an expert panel. The two-shot prompting approach in combination with scope and domain context outperforms other methods and achieves the highest score when compared to the human reference set by a general practitioner. However, the automated reports are approximately twice as long as the human references, due to the addition of both redundant and relevant statements that are added to the report.
Optimal Transport Aggregation for Visual Place Recognition
Nov 27, 2023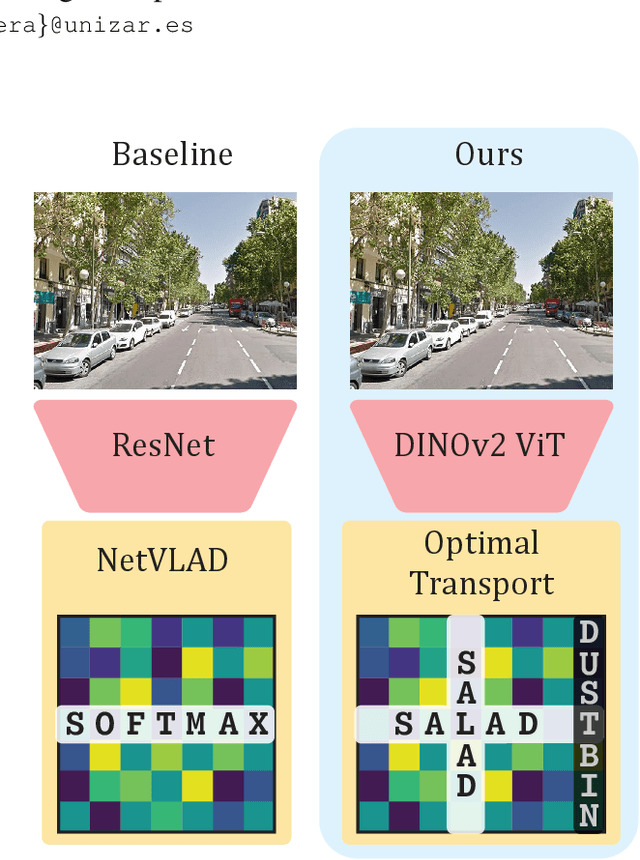

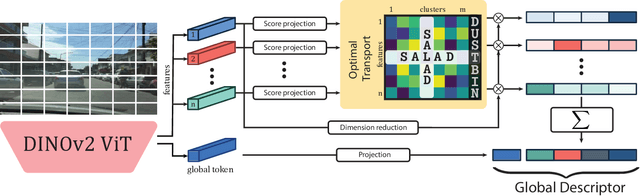

The task of Visual Place Recognition (VPR) aims to match a query image against references from an extensive database of images from different places, relying solely on visual cues. State-of-the-art pipelines focus on the aggregation of features extracted from a deep backbone, in order to form a global descriptor for each image. In this context, we introduce SALAD (Sinkhorn Algorithm for Locally Aggregated Descriptors), which reformulates NetVLAD's soft-assignment of local features to clusters as an optimal transport problem. In SALAD, we consider both feature-to-cluster and cluster-to-feature relations and we also introduce a 'dustbin' cluster, designed to selectively discard features deemed non-informative, enhancing the overall descriptor quality. Additionally, we leverage and fine-tune DINOv2 as a backbone, which provides enhanced description power for the local features, and dramatically reduces the required training time. As a result, our single-stage method not only surpasses single-stage baselines in public VPR datasets, but also surpasses two-stage methods that add a re-ranking with significantly higher cost. Code and models are available at https://github.com/serizba/salad.
FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models
Nov 27, 2023Collecting high-quality labeled data for model training is notoriously time-consuming and labor-intensive for various NLP tasks. While copious solutions, such as active learning for small language models (SLMs) and prevalent in-context learning in the era of large language models (LLMs), have been proposed and alleviate the labeling burden to some extent, their performances are still subject to human intervention. It is still underexplored how to reduce the annotation cost in the LLMs era. To bridge this, we revolutionize traditional active learning and propose an innovative collaborative learning framework FreeAL to interactively distill and filter the task-specific knowledge from LLMs. During collaborative training, an LLM serves as an active annotator inculcating its coarse-grained knowledge, while a downstream SLM is incurred as a student to filter out high-quality in-context samples to feedback LLM for the subsequent label refinery. Extensive experiments on eight benchmark datasets demonstrate that FreeAL largely enhances the zero-shot performances for both SLM and LLM without any human supervision. The code is available at https://github.com/Justherozen/FreeAL .
Where to Begin? From Random to Foundation Model Instructed Initialization in Federated Learning for Medical Image Segmentation
Nov 27, 2023In medical image analysis, Federated Learning (FL) stands out as a key technology that enables privacy-preserved, decentralized data processing, crucial for handling sensitive medical data. Currently, most FL models employ random initialization, which has been proven effective in various instances. However, given the unique challenges posed by non-IID (independently and identically distributed) data in FL, we propose a novel perspective: exploring the impact of using the foundation model with enormous pre-trained knowledge, such as the Segment Anything Model (SAM), as an instructive teacher for FL model initialization in medical image segmentation task. This work for the first time attempts to utilize the foundation model as an instructive teacher for initialization in FL, assessing its impact on the performance of FL models, especially in non-IID data scenarios. Our empirical evaluation on chest x-ray lung segmentation showcases that FL with foundation model instructed initialization not only achieves faster convergence but also improves performance in complex data contexts. These findings offer a new perspective for model initialization in FL.
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Oct 10, 2023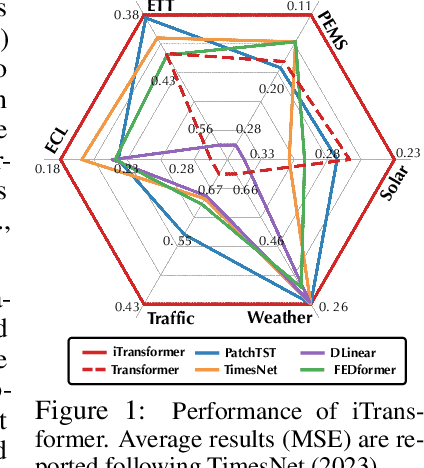
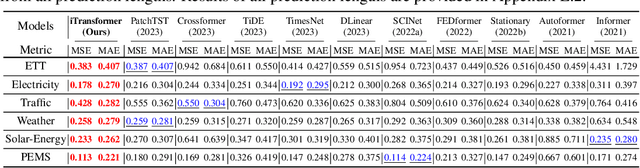
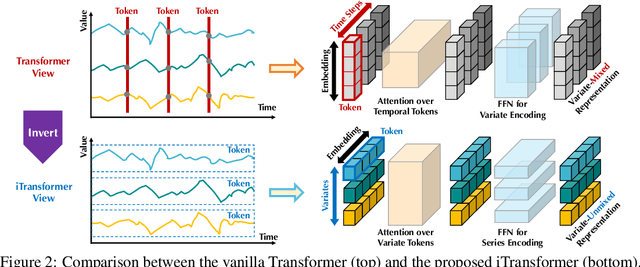
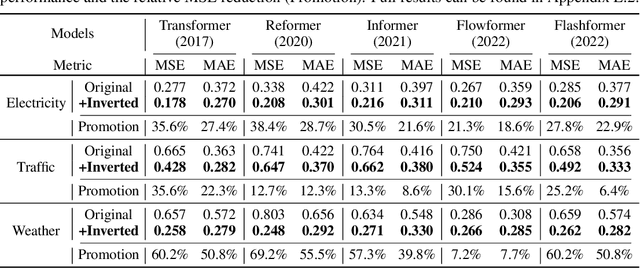
The recent boom of linear forecasting models questions the ongoing passion for architectural modifications of Transformer-based forecasters. These forecasters leverage Transformers to model the global dependencies over temporal tokens of time series, with each token formed by multiple variates of the same timestamp. However, Transformer is challenged in forecasting series with larger lookback windows due to performance degradation and computation explosion. Besides, the unified embedding for each temporal token fuses multiple variates with potentially unaligned timestamps and distinct physical measurements, which may fail in learning variate-centric representations and result in meaningless attention maps. In this work, we reflect on the competent duties of Transformer components and repurpose the Transformer architecture without any adaptation on the basic components. We propose iTransformer that simply inverts the duties of the attention mechanism and the feed-forward network. Specifically, the time points of individual series are embedded into variate tokens which are utilized by the attention mechanism to capture multivariate correlations; meanwhile, the feed-forward network is applied for each variate token to learn nonlinear representations. The iTransformer model achieves consistent state-of-the-art on several real-world datasets, which further empowers the Transformer family with promoted performance, generalization ability across different variates, and better utilization of arbitrary lookback windows, making it a nice alternative as the fundamental backbone of time series forecasting.
Beyond Sole Strength: Customized Ensembles for Generalized Vision-Language Models
Nov 28, 2023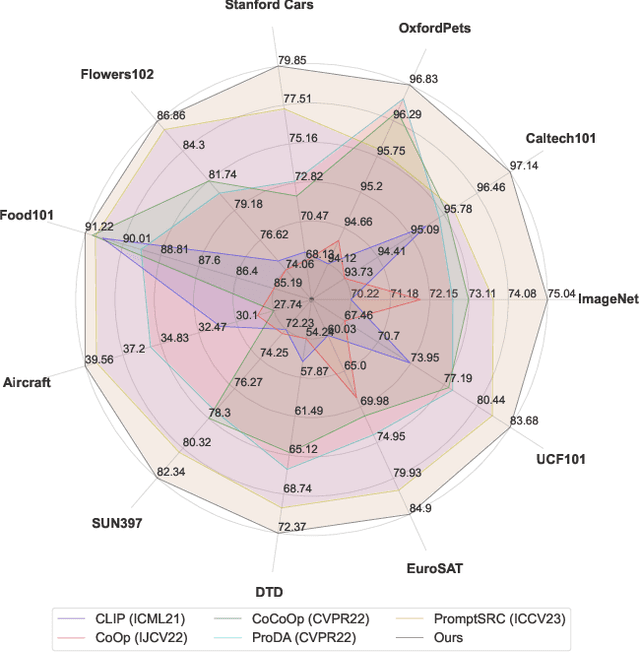
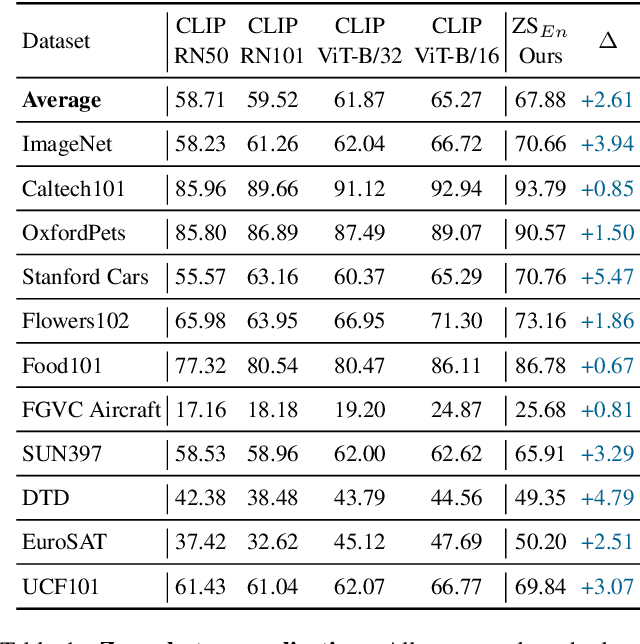
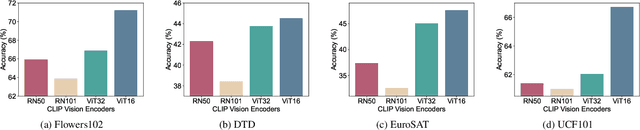
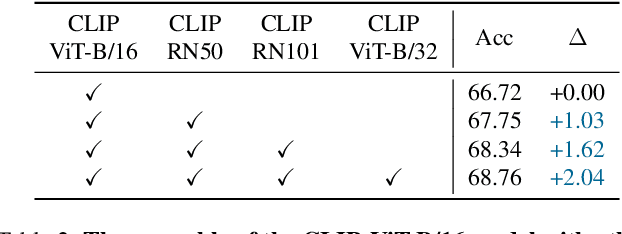
Fine-tuning pre-trained vision-language models (VLMs), e.g., CLIP, for the open-world generalization has gained increasing popularity due to its practical value. However, performance advancements are limited when relying solely on intricate algorithmic designs for a single model, even one exhibiting strong performance, e.g., CLIP-ViT-B/16. This paper, for the first time, explores the collaborative potential of leveraging much weaker VLMs to enhance the generalization of a robust single model. The affirmative findings motivate us to address the generalization problem from a novel perspective, i.e., ensemble of pre-trained VLMs. We introduce three customized ensemble strategies, each tailored to one specific scenario. Firstly, we introduce the zero-shot ensemble, automatically adjusting the logits of different models based on their confidence when only pre-trained VLMs are available. Furthermore, for scenarios with extra few-shot samples, we propose the training-free and tuning ensemble, offering flexibility based on the availability of computing resources. The proposed ensemble strategies are evaluated on zero-shot, base-to-new, and cross-dataset generalization, achieving new state-of-the-art performance. Notably, this work represents an initial stride toward enhancing the generalization performance of VLMs via ensemble. The code is available at https://github.com/zhiheLu/Ensemble_VLM.git.
Typhoon Intensity Prediction with Vision Transformer
Nov 28, 2023Predicting typhoon intensity accurately across space and time is crucial for issuing timely disaster warnings and facilitating emergency response. This has vast potential for minimizing life losses and property damages as well as reducing economic and environmental impacts. Leveraging satellite imagery for scenario analysis is effective but also introduces additional challenges due to the complex relations among clouds and the highly dynamic context. Existing deep learning methods in this domain rely on convolutional neural networks (CNNs), which suffer from limited per-layer receptive fields. This limitation hinders their ability to capture long-range dependencies and global contextual knowledge during inference. In response, we introduce a novel approach, namely "Typhoon Intensity Transformer" (Tint), which leverages self-attention mechanisms with global receptive fields per layer. Tint adopts a sequence-to-sequence feature representation learning perspective. It begins by cutting a given satellite image into a sequence of patches and recursively employs self-attention operations to extract both local and global contextual relations between all patch pairs simultaneously, thereby enhancing per-patch feature representation learning. Extensive experiments on a publicly available typhoon benchmark validate the efficacy of Tint in comparison with both state-of-the-art deep learning and conventional meteorological methods. Our code is available at https://github.com/chen-huanxin/Tint.
Multi-defender Security Games with Schedules
Nov 28, 2023Stackelberg Security Games are often used to model strategic interactions in high-stakes security settings. The majority of existing models focus on single-defender settings where a single entity assumes command of all security assets. However, many realistic scenarios feature multiple heterogeneous defenders with their own interests and priorities embedded in a more complex system. Furthermore, defenders rarely choose targets to protect. Instead, they have a multitude of defensive resources or schedules at its disposal, each with different protective capabilities. In this paper, we study security games featuring multiple defenders and schedules simultaneously. We show that unlike prior work on multi-defender security games, the introduction of schedules can cause non-existence of equilibrium even under rather restricted environments. We prove that under the mild restriction that any subset of a schedule is also a schedule, non-existence of equilibrium is not only avoided, but can be computed in polynomial time in games with two defenders. Under additional assumptions, our algorithm can be extended to games with more than two defenders and its computation scaled up in special classes of games with compactly represented schedules such as those used in patrolling applications. Experimental results suggest that our methods scale gracefully with game size, making our algorithms amongst the few that can tackle multiple heterogeneous defenders.
LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS
Nov 28, 2023Recent advancements in real-time neural rendering using point-based techniques have paved the way for the widespread adoption of 3D representations. However, foundational approaches like 3D Gaussian Splatting come with a substantial storage overhead caused by growing the SfM points to millions, often demanding gigabyte-level disk space for a single unbounded scene, posing significant scalability challenges and hindering the splatting efficiency. To address this challenge, we introduce LightGaussian, a novel method designed to transform 3D Gaussians into a more efficient and compact format. Drawing inspiration from the concept of Network Pruning, LightGaussian identifies Gaussians that are insignificant in contributing to the scene reconstruction and adopts a pruning and recovery process, effectively reducing redundancy in Gaussian counts while preserving visual effects. Additionally, LightGaussian employs distillation and pseudo-view augmentation to distill spherical harmonics to a lower degree, allowing knowledge transfer to more compact representations while maintaining reflectance. Furthermore, we propose a hybrid scheme, VecTree Quantization, to quantize all attributes, resulting in lower bitwidth representations with minimal accuracy losses. In summary, LightGaussian achieves an averaged compression rate over 15x while boosting the FPS from 139 to 215, enabling an efficient representation of complex scenes on Mip-NeRF 360, Tank and Temple datasets. Project website: https://lightgaussian.github.io/