 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Simulate: Generative Metamodeling via Quantile Regression
Nov 29, 2023
Stochastic simulation models, while effective in capturing the dynamics of complex systems, are often too slow to run for real-time decision-making. Metamodeling techniques are widely used to learn the relationship between a summary statistic of the outputs (e.g., the mean or quantile) and the inputs of the simulator, so that it can be used in real time. However, this methodology requires the knowledge of an appropriate summary statistic in advance, making it inflexible for many practical situations. In this paper, we propose a new metamodeling concept, called generative metamodeling, which aims to construct a "fast simulator of the simulator". This technique can generate random outputs substantially faster than the original simulation model, while retaining an approximately equal conditional distribution given the same inputs. Once constructed, a generative metamodel can instantaneously generate a large amount of random outputs as soon as the inputs are specified, thereby facilitating the immediate computation of any summary statistic for real-time decision-making. Furthermore, we propose a new algorithm -- quantile-regression-based generative metamodeling (QRGMM) -- and study its convergence and rate of convergence. Extensive numerical experiments are conducted to investigate the empirical performance of QRGMM, compare it with other state-of-the-art generative algorithms, and demonstrate its usefulness in practical real-time decision-making.
A Structural-Clustering Based Active Learning for Graph Neural Networks
Dec 07, 2023In active learning for graph-structured data, Graph Neural Networks (GNNs) have shown effectiveness. However, a common challenge in these applications is the underutilization of crucial structural information. To address this problem, we propose the Structural-Clustering PageRank method for improved Active learning (SPA) specifically designed for graph-structured data. SPA integrates community detection using the SCAN algorithm with the PageRank scoring method for efficient and informative sample selection. SPA prioritizes nodes that are not only informative but also central in structure. Through extensive experiments, SPA demonstrates higher accuracy and macro-F1 score over existing methods across different annotation budgets and achieves significant reductions in query time. In addition, the proposed method only adds two hyperparameters, $\epsilon$ and $\mu$ in the algorithm to finely tune the balance between structural learning and node selection. This simplicity is a key advantage in active learning scenarios, where extensive hyperparameter tuning is often impractical.
Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
Oct 26, 2023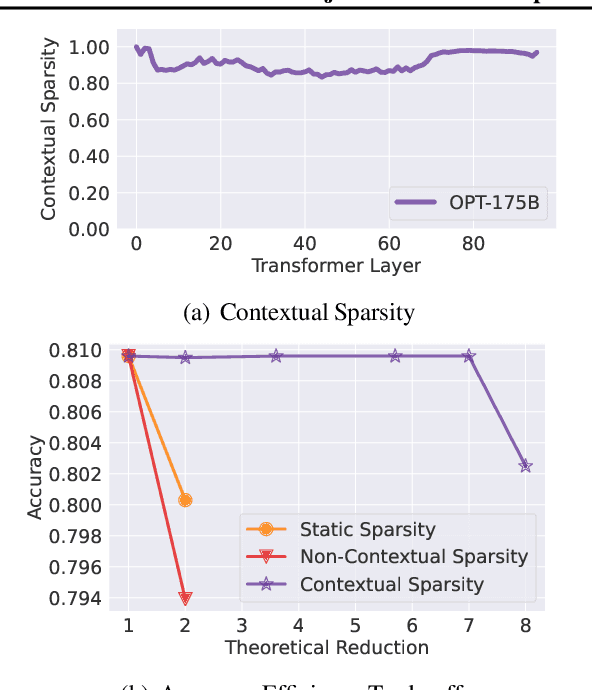
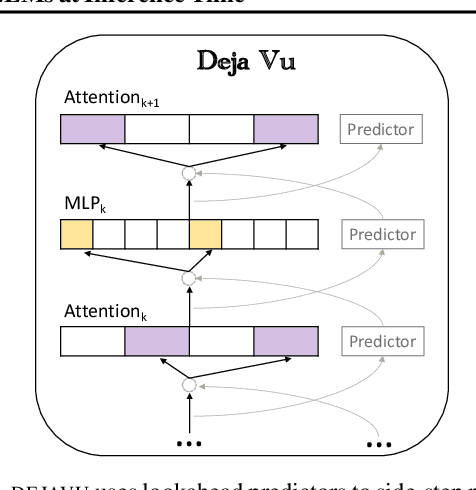
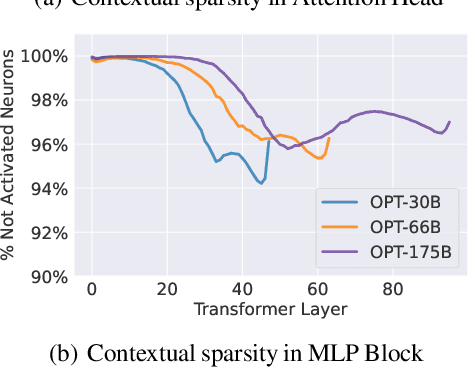
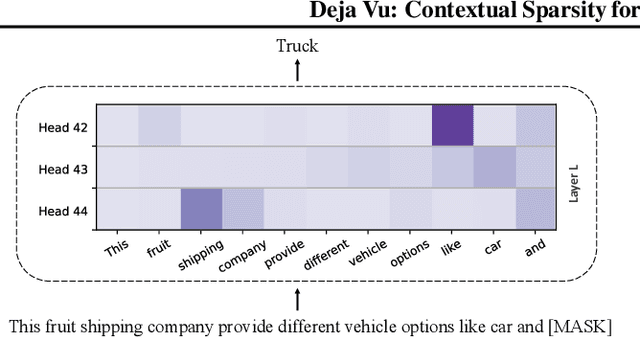
Large language models (LLMs) with hundreds of billions of parameters have sparked a new wave of exciting AI applications. However, they are computationally expensive at inference time. Sparsity is a natural approach to reduce this cost, but existing methods either require costly retraining, have to forgo LLM's in-context learning ability, or do not yield wall-clock time speedup on modern hardware. We hypothesize that contextual sparsity, which are small, input-dependent sets of attention heads and MLP parameters that yield approximately the same output as the dense model for a given input, can address these issues. We show that contextual sparsity exists, that it can be accurately predicted, and that we can exploit it to speed up LLM inference in wall-clock time without compromising LLM's quality or in-context learning ability. Based on these insights, we propose DejaVu, a system that uses a low-cost algorithm to predict contextual sparsity on the fly given inputs to each layer, along with an asynchronous and hardware-aware implementation that speeds up LLM inference. We validate that DejaVu can reduce the inference latency of OPT-175B by over 2X compared to the state-of-the-art FasterTransformer, and over 6X compared to the widely used Hugging Face implementation, without compromising model quality. The code is available at https://github.com/FMInference/DejaVu.
Predicting the Position Uncertainty at the Time of Closest Approach with Diffusion Models
Nov 09, 2023The risk of collision between resident space objects has significantly increased in recent years. As a result, spacecraft collision avoidance procedures have become an essential part of satellite operations. To ensure safe and effective space activities, satellite owners and operators rely on constantly updated estimates of encounters. These estimates include the uncertainty associated with the position of each object at the expected TCA. These estimates are crucial in planning risk mitigation measures, such as collision avoidance manoeuvres. As the TCA approaches, the accuracy of these estimates improves, as both objects' orbit determination and propagation procedures are made for increasingly shorter time intervals. However, this improvement comes at the cost of taking place close to the critical decision moment. This means that safe avoidance manoeuvres might not be possible or could incur significant costs. Therefore, knowing the evolution of this variable in advance can be crucial for operators. This work proposes a machine learning model based on diffusion models to forecast the position uncertainty of objects involved in a close encounter, particularly for the secondary object (usually debris), which tends to be more unpredictable. We compare the performance of our model with other state-of-the-art solutions and a na\"ive baseline approach, showing that the proposed solution has the potential to significantly improve the safety and effectiveness of spacecraft operations.
Talking Head(?) Anime from a Single Image 4: Improved Model and Its Distillation
Nov 30, 2023We study the problem of creating a character model that can be controlled in real time from a single image of an anime character. A solution to this problem would greatly reduce the cost of creating avatars, computer games, and other interactive applications. Talking Head Anime 3 (THA3) is an open source project that attempts to directly address the problem. It takes as input (1) an image of an anime character's upper body and (2) a 45-dimensional pose vector and outputs a new image of the same character taking the specified pose. The range of possible movements is expressive enough for personal avatars and certain types of game characters. However, the system is too slow to generate animations in real time on common PCs, and its image quality can be improved. In this paper, we improve THA3 in two ways. First, we propose new architectures for constituent networks that rotate the character's head and body based on U-Nets with attention that are widely used in modern generative models. The new architectures consistently yield better image quality than the THA3 baseline. Nevertheless, they also make the whole system much slower: it takes up to 150 milliseconds to generate a frame. Second, we propose a technique to distill the system into a small network (less than 2 MB) that can generate 512x512 animation frames in real time (under 30 FPS) using consumer gaming GPUs while keeping the image quality close to that of the full system. This improvement makes the whole system practical for real-time applications.
Data is Overrated: Perceptual Metrics Can Lead Learning in the Absence of Training Data
Dec 06, 2023Perceptual metrics are traditionally used to evaluate the quality of natural signals, such as images and audio. They are designed to mimic the perceptual behaviour of human observers and usually reflect structures found in natural signals. This motivates their use as loss functions for training generative models such that models will learn to capture the structure held in the metric. We take this idea to the extreme in the audio domain by training a compressive autoencoder to reconstruct uniform noise, in lieu of natural data. We show that training with perceptual losses improves the reconstruction of spectrograms and re-synthesized audio at test time over models trained with a standard Euclidean loss. This demonstrates better generalisation to unseen natural signals when using perceptual metrics.
Run LoRA Run: Faster and Lighter LoRA Implementations
Dec 06, 2023LoRA is a technique that reduces the number of trainable parameters in a neural network by introducing low-rank adapters to linear layers. This technique is used both for fine-tuning (LoRA, QLoRA) and full train (ReLoRA). This paper presents the RunLoRA framework for efficient implementations of LoRA that significantly improves the speed of neural network training and fine-tuning using low-rank adapters. The proposed implementation optimizes the computation of LoRA operations based on dimensions of corresponding linear layer, layer input dimensions and lora rank by choosing best forward and backward computation graph based on FLOPs and time estimations, resulting in faster training without sacrificing accuracy. The experimental results show up to 17% speedup on Llama family of models.
Identifiability of total effects from abstractions of time series causal graphs
Nov 02, 2023We study the problem of identifiability of the total effect of an intervention from observational time series only given an abstraction of the causal graph of the system. Specifically, we consider two types of abstractions: the extended summary causal graph which conflates all lagged causal relations but distinguishes between lagged and instantaneous relations; and the summary causal graph which does not give any indication about the lag between causal relations. We show that the total effect is always identifiable in extended summary causal graphs and we provide necessary and sufficient graphical conditions for identifiability in summary causal graphs. Furthermore, we provide adjustment sets allowing to estimate the total effect whenever it is identifiable.
GVFs in the Real World: Making Predictions Online for Water Treatment
Dec 04, 2023In this paper we investigate the use of reinforcement-learning based prediction approaches for a real drinking-water treatment plant. Developing such a prediction system is a critical step on the path to optimizing and automating water treatment. Before that, there are many questions to answer about the predictability of the data, suitable neural network architectures, how to overcome partial observability and more. We first describe this dataset, and highlight challenges with seasonality, nonstationarity, partial observability, and heterogeneity across sensors and operation modes of the plant. We then describe General Value Function (GVF) predictions -- discounted cumulative sums of observations -- and highlight why they might be preferable to classical n-step predictions common in time series prediction. We discuss how to use offline data to appropriately pre-train our temporal difference learning (TD) agents that learn these GVF predictions, including how to select hyperparameters for online fine-tuning in deployment. We find that the TD-prediction agent obtains an overall lower normalized mean-squared error than the n-step prediction agent. Finally, we show the importance of learning in deployment, by comparing a TD agent trained purely offline with no online updating to a TD agent that learns online. This final result is one of the first to motivate the importance of adapting predictions in real-time, for non-stationary high-volume systems in the real world.
* Published in Machine Learning (2023)
Cooperative vs. Teleoperation Control of the Steady Hand Eye Robot with Adaptive Sclera Force Control: A Comparative Study
Dec 04, 2023A surgeon's physiological hand tremor can significantly impact the outcome of delicate and precise retinal surgery, such as retinal vein cannulation (RVC) and epiretinal membrane peeling. Robot-assisted eye surgery technology provides ophthalmologists with advanced capabilities such as hand tremor cancellation, hand motion scaling, and safety constraints that enable them to perform these otherwise challenging and high-risk surgeries with high precision and safety. Steady-Hand Eye Robot (SHER) with cooperative control mode can filter out surgeon's hand tremor, yet another important safety feature, that is, minimizing the contact force between the surgical instrument and sclera surface for avoiding tissue damage cannot be met in this control mode. Also, other capabilities, such as hand motion scaling and haptic feedback, require a teleoperation control framework. In this work, for the first time, we implemented a teleoperation control mode incorporated with an adaptive sclera force control algorithm using a PHANTOM Omni haptic device and a force-sensing surgical instrument equipped with Fiber Bragg Grating (FBG) sensors attached to the SHER 2.1 end-effector. This adaptive sclera force control algorithm allows the robot to dynamically minimize the tool-sclera contact force. Moreover, for the first time, we compared the performance of the proposed adaptive teleoperation mode with the cooperative mode by conducting a vessel-following experiment inside an eye phantom under a microscope.