 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Faster Diffusion: Rethinking the Role of UNet Encoder in Diffusion Models
Dec 15, 2023
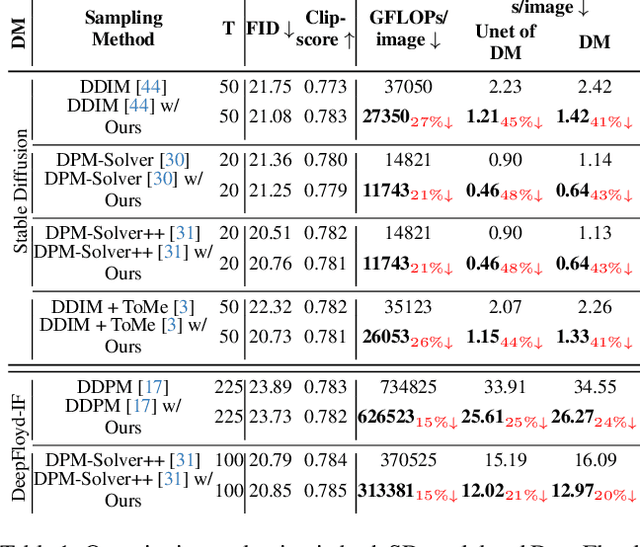
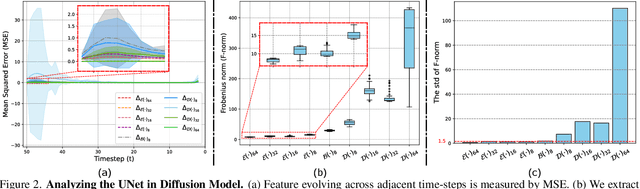
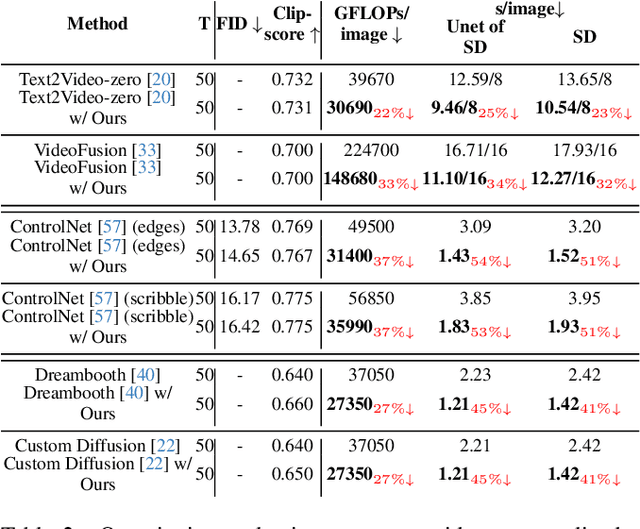
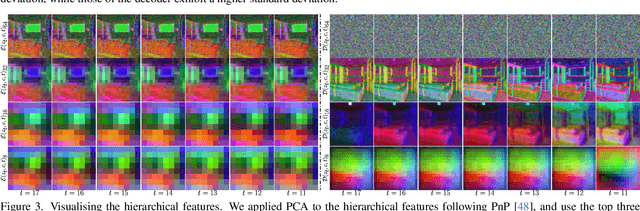
One of the key components within diffusion models is the UNet for noise prediction. While several works have explored basic properties of the UNet decoder, its encoder largely remains unexplored. In this work, we conduct the first comprehensive study of the UNet encoder. We empirically analyze the encoder features and provide insights to important questions regarding their changes at the inference process. In particular, we find that encoder features change gently, whereas the decoder features exhibit substantial variations across different time-steps. This finding inspired us to omit the encoder at certain adjacent time-steps and reuse cyclically the encoder features in the previous time-steps for the decoder. Further based on this observation, we introduce a simple yet effective encoder propagation scheme to accelerate the diffusion sampling for a diverse set of tasks. By benefiting from our propagation scheme, we are able to perform in parallel the decoder at certain adjacent time-steps. Additionally, we introduce a prior noise injection method to improve the texture details in the generated image. Besides the standard text-to-image task, we also validate our approach on other tasks: text-to-video, personalized generation and reference-guided generation. Without utilizing any knowledge distillation technique, our approach accelerates both the Stable Diffusion (SD) and the DeepFloyd-IF models sampling by 41$\%$ and 24$\%$ respectively, while maintaining high-quality generation performance. Our code is available in \href{https://github.com/hutaiHang/Faster-Diffusion}{FasterDiffusion}.
Scaling Opponent Shaping to High Dimensional Games
Dec 19, 2023In multi-agent settings with mixed incentives, methods developed for zero-sum games have been shown to lead to detrimental outcomes. To address this issue, opponent shaping (OS) methods explicitly learn to influence the learning dynamics of co-players and empirically lead to improved individual and collective outcomes. However, OS methods have only been evaluated in low-dimensional environments due to the challenges associated with estimating higher-order derivatives or scaling model-free meta-learning. Alternative methods that scale to more complex settings either converge to undesirable solutions or rely on unrealistic assumptions about the environment or co-players. In this paper, we successfully scale an OS-based approach to general-sum games with temporally-extended actions and long-time horizons for the first time. After analysing the representations of the meta-state and history used by previous algorithms, we propose a simplified version called Shaper. We show empirically that Shaper leads to improved individual and collective outcomes in a range of challenging settings from literature. We further formalize a technique previously implicit in the literature, and analyse its contribution to opponent shaping. We show empirically that this technique is helpful for the functioning of prior methods in certain environments. Lastly, we show that previous environments, such as the CoinGame, are inadequate for analysing temporally-extended general-sum interactions.
Localization and Discrete Beamforming with a Large Reconfigurable Intelligent Surface
Dec 19, 2023In millimeter-wave (mmWave) cellular systems, reconfigurable intelligent surfaces (RISs) are foreseeably deployed with a large number of reflecting elements to achieve high beamforming gains. The large-sized RIS will make radio links fall in the near-field localization regime with spatial non-stationarity issues. Moreover, the discrete phase restriction on the RIS reflection coefficient incurs exponential complexity for discrete beamforming. It remains an open problem to find the optimal RIS reflection coefficient design in polynomial time. To address these issues, we propose a scalable partitioned-far-field protocol that considers both the near-filed non-stationarity and discrete beamforming. The protocol approximates near-field signal propagation using a partitioned-far-field representation to inherit the sparsity from the sophisticated far-field and facilitate the near-field localization scheme. To improve the theoretical localization performance, we propose a fast passive beamforming (FPB) algorithm that optimally solves the discrete RIS beamforming problem, reducing the search complexity from exponential order to linear order. Furthermore, by exploiting the partitioned structure of RIS, we introduce a two-stage coarse-to-fine localization algorithm that leverages both the time delay and angle information. Numerical results demonstrate that centimeter-level localization precision is achieved under medium and high signal-to-noise ratios (SNR), revealing that RISs can provide support for low-cost and high-precision localization in future cellular systems.
A Computationally Efficient Neural Video Compression Accelerator Based on a Sparse CNN-Transformer Hybrid Network
Dec 19, 2023Video compression is widely used in digital television, surveillance systems, and virtual reality. Real-time video decoding is crucial in practical scenarios. Recently, neural video compression (NVC) combines traditional coding with deep learning, achieving impressive compression efficiency. Nevertheless, the NVC models involve high computational costs and complex memory access patterns, challenging real-time hardware implementations. To relieve this burden, we propose an algorithm and hardware co-design framework named NVCA for video decoding on resource-limited devices. Firstly, a CNN-Transformer hybrid network is developed to improve compression performance by capturing multi-scale non-local features. In addition, we propose a fast algorithm-based sparse strategy that leverages the dual advantages of pruning and fast algorithms, sufficiently reducing computational complexity while maintaining video compression efficiency. Secondly, a reconfigurable sparse computing core is designed to flexibly support sparse convolutions and deconvolutions based on the fast algorithm-based sparse strategy. Furthermore, a novel heterogeneous layer chaining dataflow is incorporated to reduce off-chip memory traffic stemming from extensive inter-frame motion and residual information. Thirdly, the overall architecture of NVCA is designed and synthesized in TSMC 28nm CMOS technology. Extensive experiments demonstrate that our design provides superior coding quality and up to 22.7x decoding speed improvements over other video compression designs. Meanwhile, our design achieves up to 2.2x improvements in energy efficiency compared to prior accelerators.
Test-time Backdoor Mitigation for Black-Box Large Language Models with Defensive Demonstrations
Nov 16, 2023Existing studies in backdoor defense have predominantly focused on the training phase, overlooking the critical aspect of testing time defense. This gap becomes particularly pronounced in the context of Large Language Models (LLMs) deployed as Web Services, which typically offer only black-box access, rendering training-time defenses impractical. To bridge this gap, our work introduces defensive demonstrations, an innovative backdoor defense strategy for blackbox large language models. Our method involves identifying the task and retrieving task-relevant demonstrations from an uncontaminated pool. These demonstrations are then combined with user queries and presented to the model during testing, without requiring any modifications/tuning to the black-box model or insights into its internal mechanisms. Defensive demonstrations are designed to counteract the adverse effects of triggers, aiming to recalibrate and correct the behavior of poisoned models during test-time evaluations. Extensive experiments show that defensive demonstrations are effective in defending both instance-level and instruction-level backdoor attacks, not only rectifying the behavior of poisoned models but also surpassing existing baselines in most scenarios.
Navigating the Structured What-If Spaces: Counterfactual Generation via Structured Diffusion
Dec 21, 2023Generating counterfactual explanations is one of the most effective approaches for uncovering the inner workings of black-box neural network models and building user trust. While remarkable strides have been made in generative modeling using diffusion models in domains like vision, their utility in generating counterfactual explanations in structured modalities remains unexplored. In this paper, we introduce Structured Counterfactual Diffuser or SCD, the first plug-and-play framework leveraging diffusion for generating counterfactual explanations in structured data. SCD learns the underlying data distribution via a diffusion model which is then guided at test time to generate counterfactuals for any arbitrary black-box model, input, and desired prediction. Our experiments show that our counterfactuals not only exhibit high plausibility compared to the existing state-of-the-art but also show significantly better proximity and diversity.
Lookahead: An Inference Acceleration Framework for Large Language Model with Lossless Generation Accuracy
Dec 20, 2023As Large Language Models (LLMs) have made significant advancements across various tasks, such as question answering, translation, text summarization, and dialogue systems, the need for accuracy in information becomes crucial, especially for serious financial products serving billions of users like Alipay. To address this, Alipay has developed a Retrieval-Augmented Generation (RAG) system that grounds LLMs on the most accurate and up-to-date information. However, for a real-world product serving millions of users, the inference speed of LLMs becomes a critical factor compared to a mere experimental model. Hence, this paper presents a generic framework for accelerating the inference process, resulting in a substantial increase in speed and cost reduction for our RAG system, with lossless generation accuracy. In the traditional inference process, each token is generated sequentially by the LLM, leading to a time consumption proportional to the number of generated tokens. To enhance this process, our framework, named \textit{lookahead}, introduces a \textit{multi-branch} strategy. Instead of generating a single token at a time, we propose a \textit{Trie-based Retrieval} (TR) process that enables the generation of multiple branches simultaneously, each of which is a sequence of tokens. Subsequently, for each branch, a \textit{Verification and Accept} (VA) process is performed to identify the longest correct sub-sequence as the final output. Our strategy offers two distinct advantages: (1) it guarantees absolute correctness of the output, avoiding any approximation algorithms, and (2) the worst-case performance of our approach is equivalent to the conventional process. We conduct extensive experiments to demonstrate the significant improvements achieved by applying our inference acceleration framework.
Photo-SLAM: Real-time Simultaneous Localization and Photorealistic Mapping for Monocular, Stereo, and RGB-D Cameras
Nov 28, 2023The integration of neural rendering and the SLAM system recently showed promising results in joint localization and photorealistic view reconstruction. However, existing methods, fully relying on implicit representations, are so resource-hungry that they cannot run on portable devices, which deviates from the original intention of SLAM. In this paper, we present Photo-SLAM, a novel SLAM framework with a hyper primitives map. Specifically, we simultaneously exploit explicit geometric features for localization and learn implicit photometric features to represent the texture information of the observed environment. In addition to actively densifying hyper primitives based on geometric features, we further introduce a Gaussian-Pyramid-based training method to progressively learn multi-level features, enhancing photorealistic mapping performance. The extensive experiments with monocular, stereo, and RGB-D datasets prove that our proposed system Photo-SLAM significantly outperforms current state-of-the-art SLAM systems for online photorealistic mapping, e.g., PSNR is 30% higher and rendering speed is hundreds of times faster in the Replica dataset. Moreover, the Photo-SLAM can run at real-time speed using an embedded platform such as Jetson AGX Orin, showing the potential of robotics applications.
Task Planning for Multiple Item Insertion using ADMM
Dec 20, 2023Mixed-integer nonlinear programmings (MINLPs) are powerful formulation tools for task planning. However, it suffers from long solving time especially for large scale problems. In this work, we first formulate the task planning problem for item stowing into a mixed-integer nonlinear programming problem, then solve it using Alternative Direction Method of Multipliers (ADMM). ADMM separates the complete formulation into a nonlinear programming problem and mixed-integer programming problem, then iterate between them to solve the original problem. We show that our ADMM converges better than non-warm-started nonlinear complementary formulation. Our proposed methods are demonstrated on hardware as a high level planner to insert books into the bookshelf.
Unconstrained Dysfluency Modeling for Dysfluent Speech Transcription and Detection
Dec 20, 2023Dysfluent speech modeling requires time-accurate and silence-aware transcription at both the word-level and phonetic-level. However, current research in dysfluency modeling primarily focuses on either transcription or detection, and the performance of each aspect remains limited. In this work, we present an unconstrained dysfluency modeling (UDM) approach that addresses both transcription and detection in an automatic and hierarchical manner. UDM eliminates the need for extensive manual annotation by providing a comprehensive solution. Furthermore, we introduce a simulated dysfluent dataset called VCTK++ to enhance the capabilities of UDM in phonetic transcription. Our experimental results demonstrate the effectiveness and robustness of our proposed methods in both transcription and detection tasks.