 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Monocular Vision based Crowdsourced 3D Traffic Sign Positioning with Unknown Camera Intrinsics and Distortion Coefficients
Jul 09, 2020
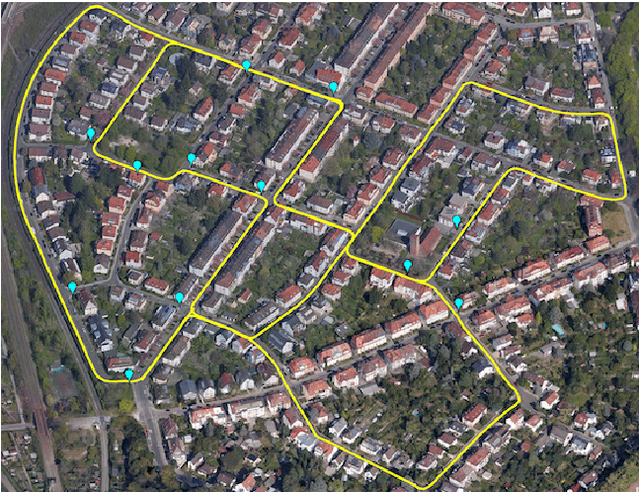
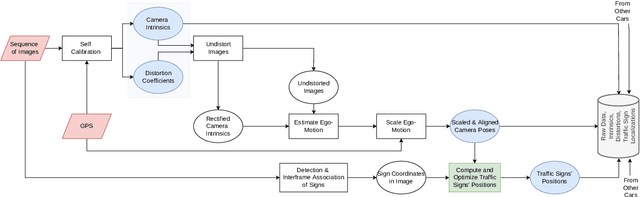
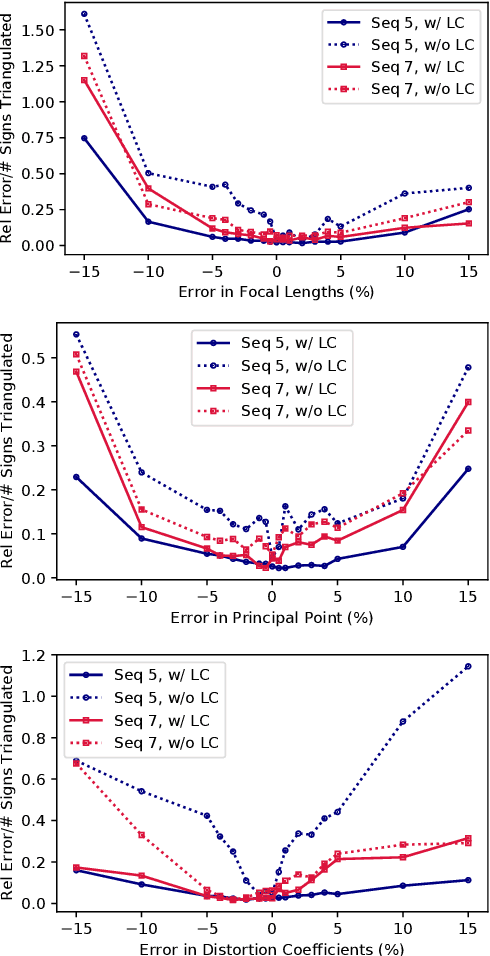
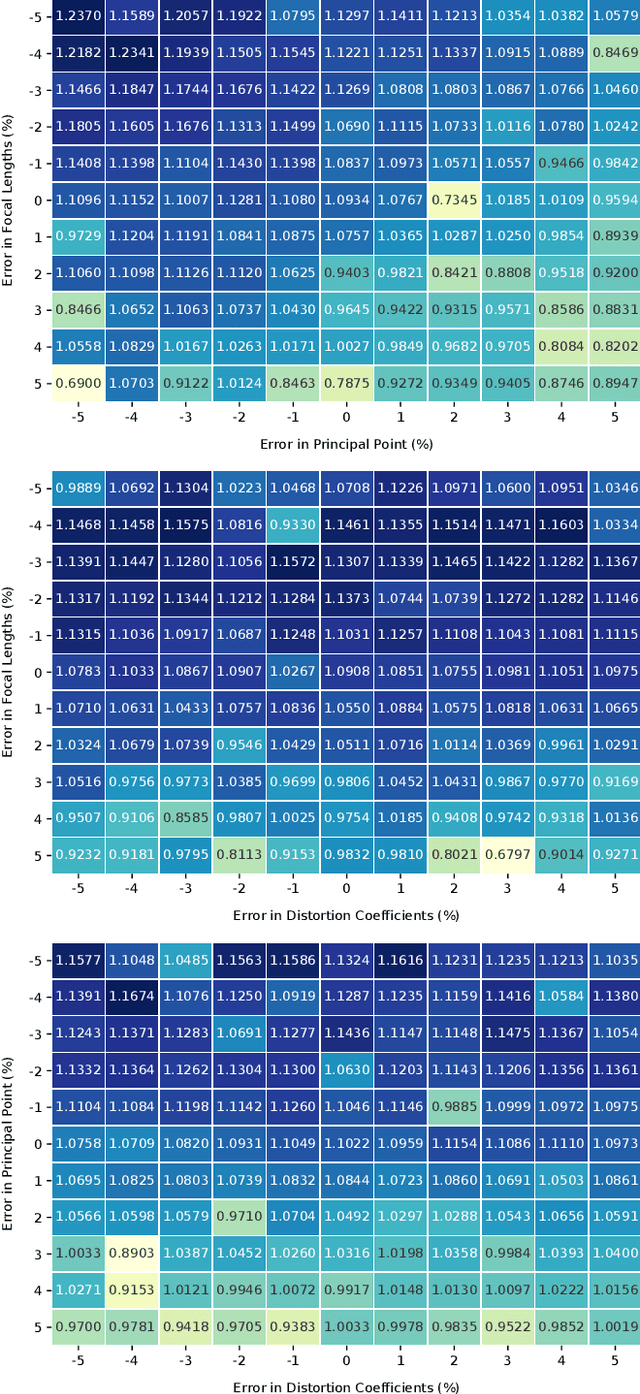
Autonomous vehicles and driver assistance systems utilize maps of 3D semantic landmarks for improved decision making. However, scaling the mapping process as well as regularly updating such maps come with a huge cost. Crowdsourced mapping of these landmarks such as traffic sign positions provides an appealing alternative. The state-of-the-art approaches to crowdsourced mapping use ground truth camera parameters, which may not always be known or may change over time. In this work, we demonstrate an approach to computing 3D traffic sign positions without knowing the camera focal lengths, principal point, and distortion coefficients a priori. We validate our proposed approach on a public dataset of traffic signs in KITTI. Using only a monocular color camera and GPS, we achieve an average single journey relative and absolute positioning accuracy of 0.26 m and 1.38 m, respectively.
Using a memory of motion to efficiently achieve visual predictive control tasks
Jan 31, 2020

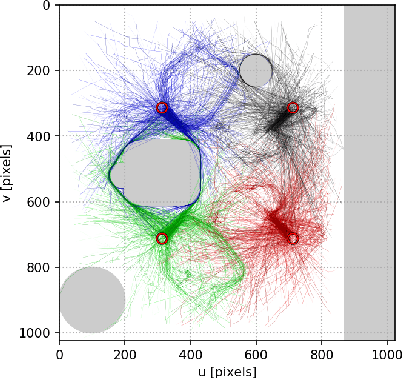
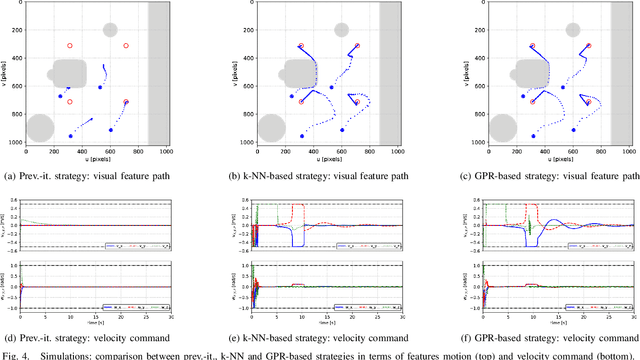
This paper addresses the problem of efficiently achieving visual predictive control tasks. To this end, a memory of motion, containing a set of trajectories built off-line, is used for leveraging precomputation and dealing with difficult visual tasks. Regression techniques, such as k-nearest neighbors and Gaussian process regression, are used to query the memory and provide on-line the control optimization process with a warm-start and way points. The proposed technique allows the robot to achieve difficult tasks and, at the same time, keep the execution time limited. Simulation and experimental results, carried out with a 7-axis manipulator, show the effectiveness of the approach.
Improving Competence for Reliable Autonomy
Jul 23, 2020
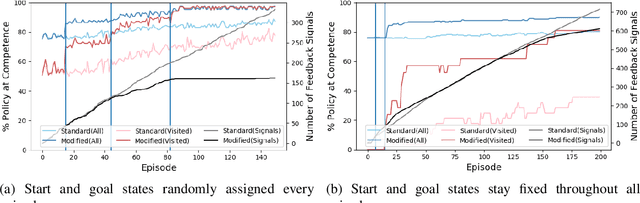
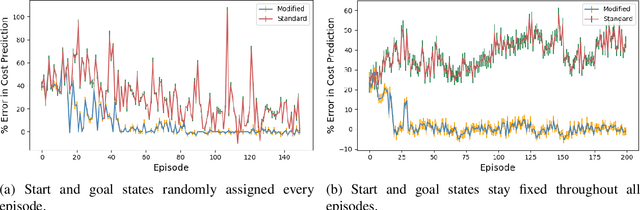
Given the complexity of real-world, unstructured domains, it is often impossible or impractical to design models that include every feature needed to handle all possible scenarios that an autonomous system may encounter. For an autonomous system to be reliable in such domains, it should have the ability to improve its competence online. In this paper, we propose a method for improving the competence of a system over the course of its deployment. We specifically focus on a class of semi-autonomous systems known as competence-aware systems that model their own competence -- the optimal extent of autonomy to use in any given situation -- and learn this competence over time from feedback received through interactions with a human authority. Our method exploits such feedback to identify important state features missing from the system's initial model, and incorporates them into its state representation. The result is an agent that better predicts human involvement, leading to improvements in its competence and reliability, and as a result, its overall performance.
* In Proceedings AREA 2020, arXiv:2007.11260
Bach or Mock? A Grading Function for Chorales in the Style of J.S. Bach
Jun 23, 2020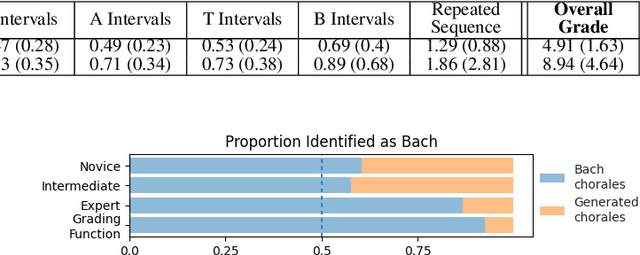

Deep generative systems that learn probabilistic models from a corpus of existing music do not explicitly encode knowledge of a musical style, compared to traditional rule-based systems. Thus, it can be difficult to determine whether deep models generate stylistically correct output without expert evaluation, but this is expensive and time-consuming. Therefore, there is a need for automatic, interpretable, and musically-motivated evaluation measures of generated music. In this paper, we introduce a grading function that evaluates four-part chorales in the style of J.S. Bach along important musical features. We use the grading function to evaluate the output of a Transformer model, and show that the function is both interpretable and outperforms human experts at discriminating Bach chorales from model-generated ones.
SIGL: Securing Software Installations Through Deep Graph Learning
Aug 26, 2020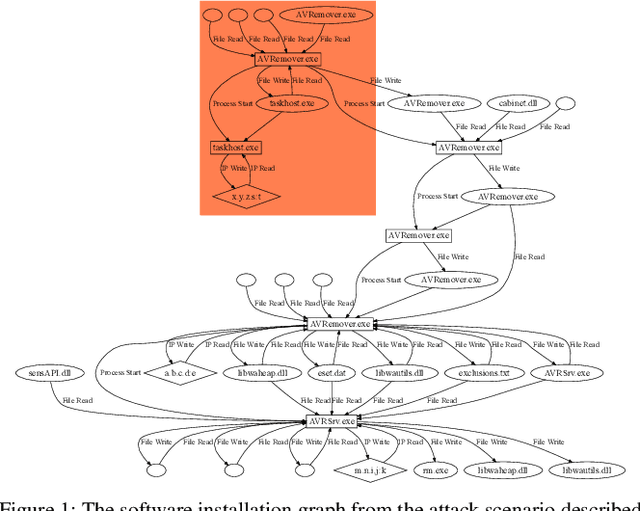

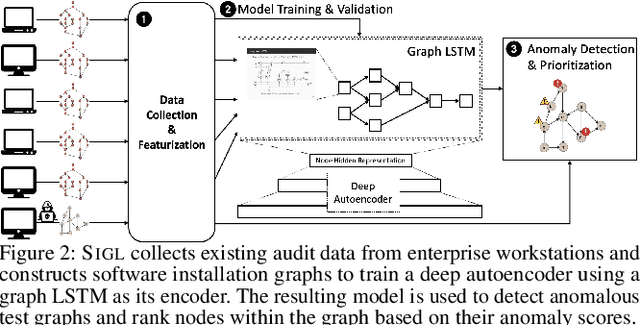

Many users implicitly assume that software can only be exploited after it is installed. However, recent supply-chain attacks demonstrate that application integrity must be ensured during installation itself. We introduce SIGL, a new tool for detecting malicious behavior during software installation. SIGL collects traces of system call activity, building a data provenance graph that it analyzes using a novel autoencoder architecture with a graph long short-term memory network (graph LSTM) for the encoder and a standard multilayer perceptron for the decoder. SIGL flags suspicious installations as well as the specific installation-time processes that are likely to be malicious. Using a test corpus of 625 malicious installers containing real-world malware, we demonstrate that SIGL has a detection accuracy of 96%, outperforming similar systems from industry and academia by up to 87% in precision and recall and 45% in accuracy. We also demonstrate that SIGL can pinpoint the processes most likely to have triggered malicious behavior, works on different audit platforms and operating systems, and is robust to training data contamination and adversarial attack. It can be used with application-specific models, even in the presence of new software versions, as well as application-agnostic meta-models that encompass a wide range of applications and installers.
Suphx: Mastering Mahjong with Deep Reinforcement Learning
Apr 01, 2020
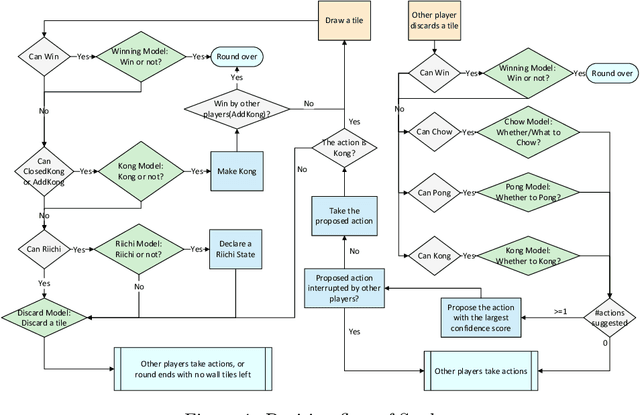
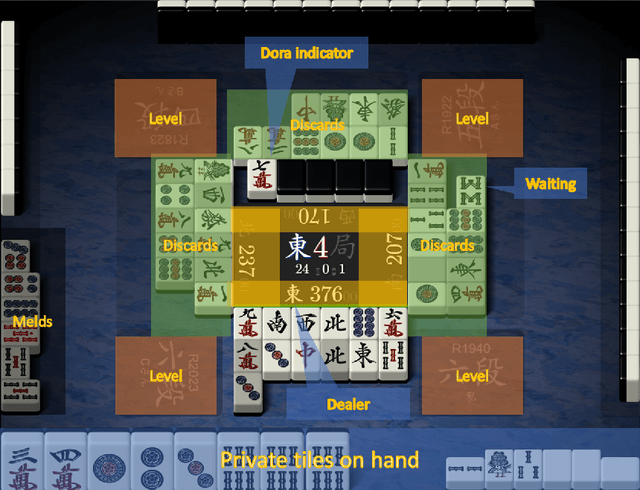

Artificial Intelligence (AI) has achieved great success in many domains, and game AI is widely regarded as its beachhead since the dawn of AI. In recent years, studies on game AI have gradually evolved from relatively simple environments (e.g., perfect-information games such as Go, chess, shogi or two-player imperfect-information games such as heads-up Texas hold'em) to more complex ones (e.g., multi-player imperfect-information games such as multi-player Texas hold'em and StartCraft II). Mahjong is a popular multi-player imperfect-information game worldwide but very challenging for AI research due to its complex playing/scoring rules and rich hidden information. We design an AI for Mahjong, named Suphx, based on deep reinforcement learning with some newly introduced techniques including global reward prediction, oracle guiding, and run-time policy adaptation. Suphx has demonstrated stronger performance than most top human players in terms of stable rank and is rated above 99.99% of all the officially ranked human players in the Tenhou platform. This is the first time that a computer program outperforms most top human players in Mahjong.
On the safety of vulnerable road users by cyclist orientation detection using Deep Learning
Apr 25, 2020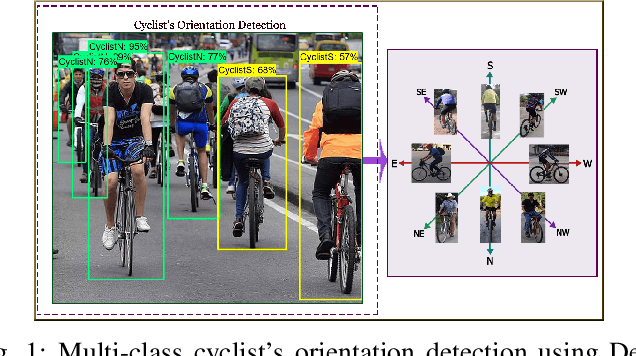
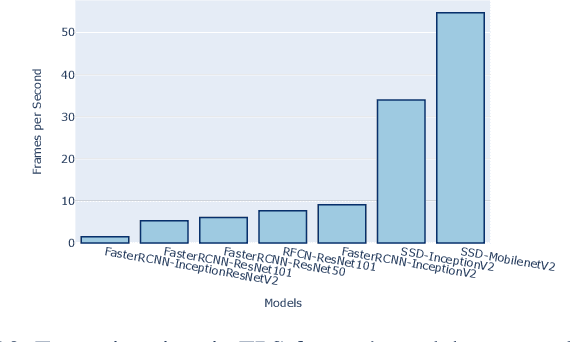
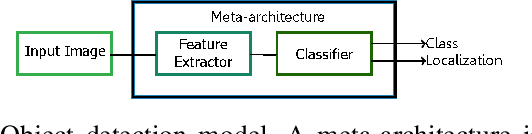
In this work, orientation detection using Deep Learning is acknowledged for a particularly vulnerable class of road users,the cyclists. Knowing the cyclists' orientation is of great relevance since it provides a good notion about their future trajectory, which is crucial to avoid accidents in the context of intelligent transportation systems. Using Transfer Learning with pre-trained models and TensorFlow, we present a performance comparison between the main algorithms reported in the literature for object detection,such as SSD, Faster R-CNN and R-FCN along with MobilenetV2, InceptionV2, ResNet50, ResNet101 feature extractors. Moreover, we propose multi-class detection with eight different classes according to orientations. To do so, we introduce a new dataset called "Detect-Bike", containing 20,229 cyclist instances over 11,103 images, which has been labeled based on cyclist's orientation. Then, the same Deep Learning methods used for detection are trained to determine the target's heading. Our experimental results and vast evaluation showed satisfactory performance of all of the studied methods for the cyclists and their orientation detection, especially using Faster R-CNN with ResNet50 proved to be precise but significantly slower. Meanwhile, SSD using InceptionV2 provided good trade-off between precision and execution time, and is to be preferred for real-time embedded applications.
An Empirical Evaluation of Similarity Measures for Time Series Classification
Jan 16, 2014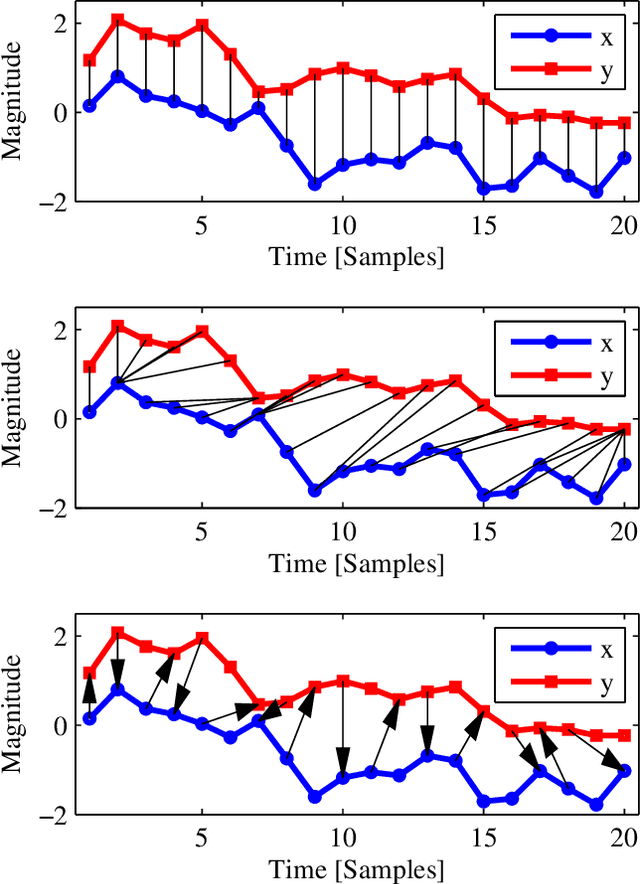
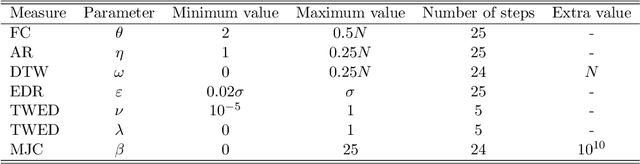
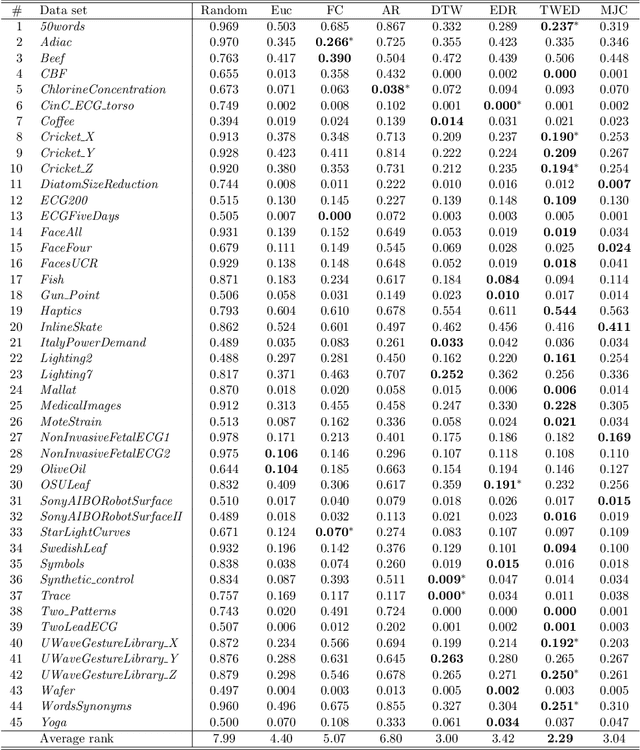
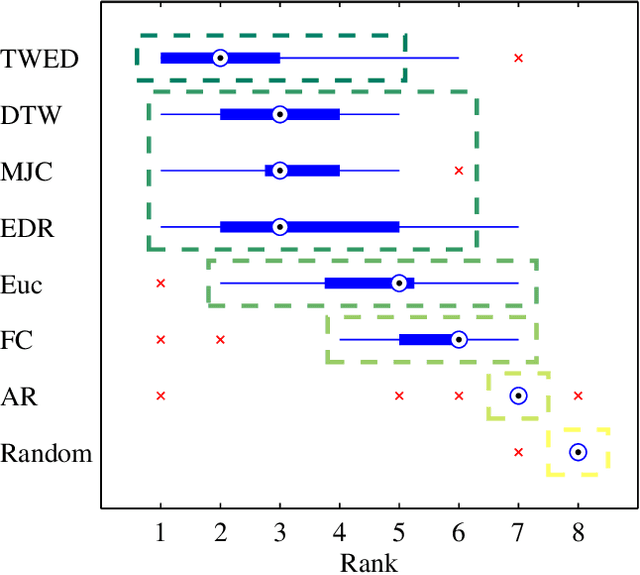
Time series are ubiquitous, and a measure to assess their similarity is a core part of many computational systems. In particular, the similarity measure is the most essential ingredient of time series clustering and classification systems. Because of this importance, countless approaches to estimate time series similarity have been proposed. However, there is a lack of comparative studies using empirical, rigorous, quantitative, and large-scale assessment strategies. In this article, we provide an extensive evaluation of similarity measures for time series classification following the aforementioned principles. We consider 7 different measures coming from alternative measure `families', and 45 publicly-available time series data sets coming from a wide variety of scientific domains. We focus on out-of-sample classification accuracy, but in-sample accuracies and parameter choices are also discussed. Our work is based on rigorous evaluation methodologies and includes the use of powerful statistical significance tests to derive meaningful conclusions. The obtained results show the equivalence, in terms of accuracy, of a number of measures, but with one single candidate outperforming the rest. Such findings, together with the followed methodology, invite researchers on the field to adopt a more consistent evaluation criteria and a more informed decision regarding the baseline measures to which new developments should be compared.
* 28 pages, 5 figures, 3 tables
Super Resolution of Arterial Spin Labeling MR Imaging Using Unsupervised Multi-Scale Generative Adversarial Network
Sep 14, 2020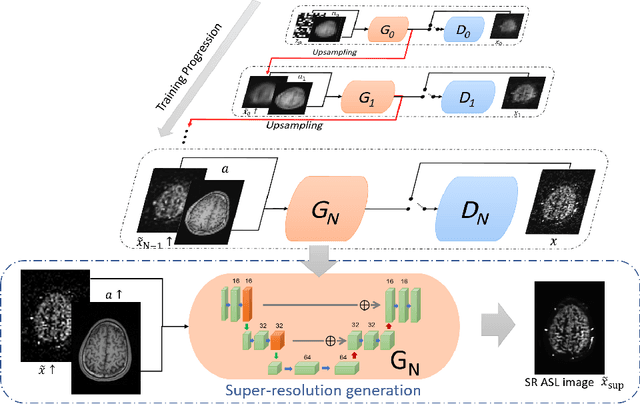
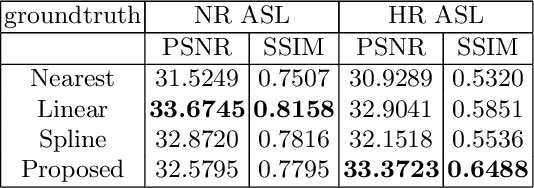
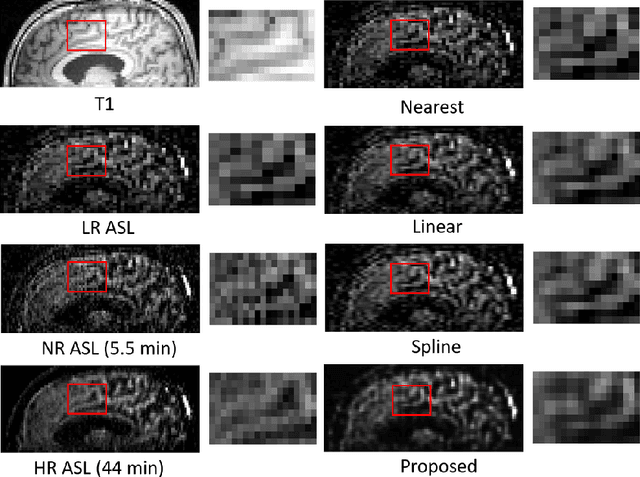
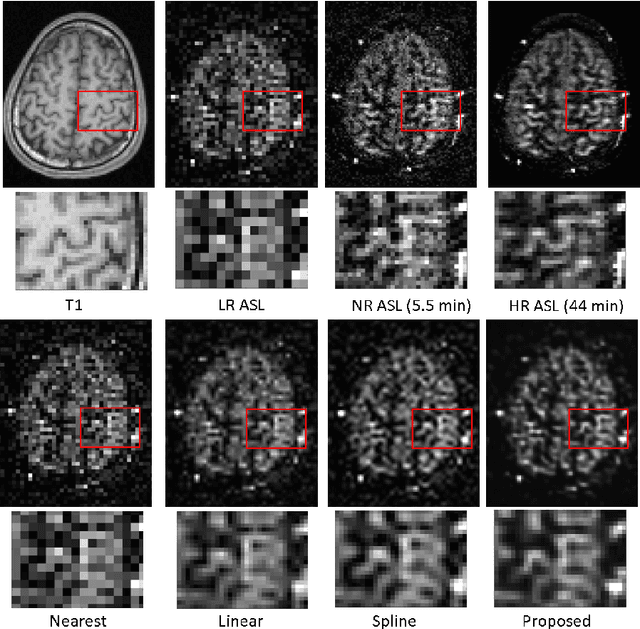
Arterial spin labeling (ASL) magnetic resonance imaging (MRI) is a powerful imaging technology that can measure cerebral blood flow (CBF) quantitatively. However, since only a small portion of blood is labeled compared to the whole tissue volume, conventional ASL suffers from low signal-to-noise ratio (SNR), poor spatial resolution, and long acquisition time. In this paper, we proposed a super-resolution method based on a multi-scale generative adversarial network (GAN) through unsupervised training. The network only needs the low-resolution (LR) ASL image itself for training and the T1-weighted image as the anatomical prior. No training pairs or pre-training are needed. A low-pass filter guided item was added as an additional loss to suppress the noise interference from the LR ASL image. After the network was trained, the super-resolution (SR) image was generated by supplying the upsampled LR ASL image and corresponding T1-weighted image to the generator of the last layer. Performance of the proposed method was evaluated by comparing the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) using normal-resolution (NR) ASL image (5.5 min acquisition) and high-resolution (HR) ASL image (44 min acquisition) as the ground truth. Compared to the nearest, linear, and spline interpolation methods, the proposed method recovers more detailed structure information, reduces the image noise visually, and achieves the highest PSNR and SSIM when using HR ASL image as the ground-truth.
Gesture Recognition from Skeleton Data for Intuitive Human-Machine Interaction
Aug 26, 2020
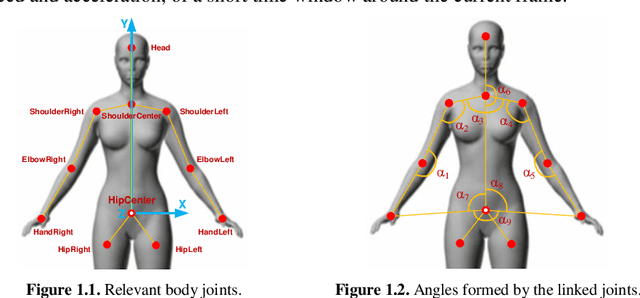
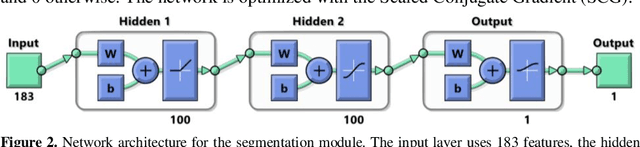
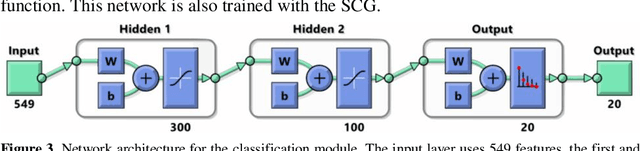
Human gesture recognition has assumed a capital role in industrial applications, such as Human-Machine Interaction. We propose an approach for segmentation and classification of dynamic gestures based on a set of handcrafted features, which are drawn from the skeleton data provided by the Kinect sensor. The module for gesture detection relies on a feedforward neural network which performs framewise binary classification. The method for gesture recognition applies a sliding window, which extracts information from both the spatial and temporal dimensions. Then we combine windows of varying durations to get a multi-temporal scale approach and an additional gain in performance. Encouraged by the recent success of Recurrent Neural Networks for time series domains, we also propose a method for simultaneous gesture segmentation and classification based on the bidirectional Long Short-Term Memory cells, which have shown ability for learning the temporal relationships on long temporal scales. We evaluate all the different approaches on the dataset published for the ChaLearn Looking at People Challenge 2014. The most effective method achieves a Jaccard index of 0.75, which suggests a performance almost on pair with that presented by the state-of-the-art techniques. At the end, the recognized gestures are used to interact with a collaborative robot.