 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Domain-invariant Similarity Activation Map Metric Learning for Retrieval-based Long-term Visual Localization
Sep 16, 2020

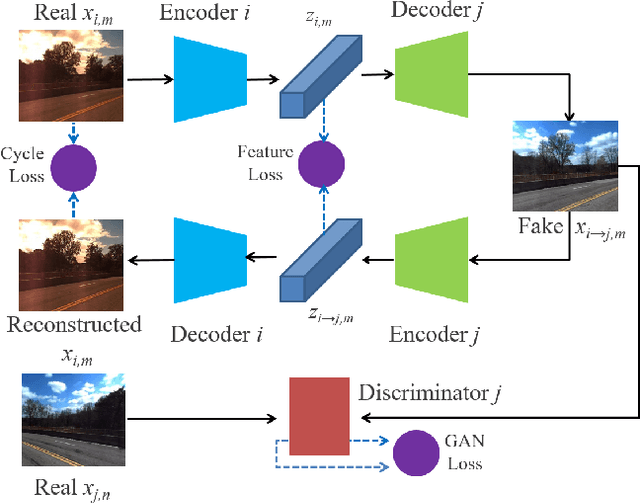
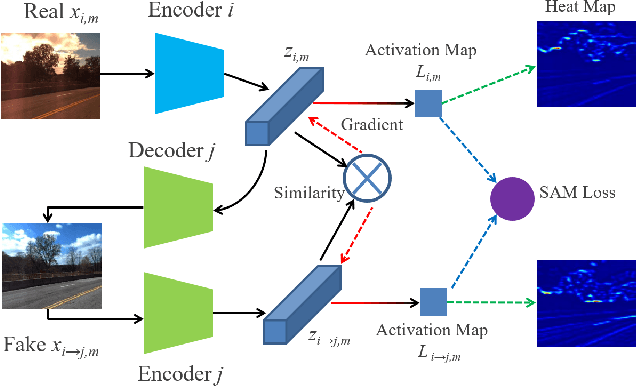
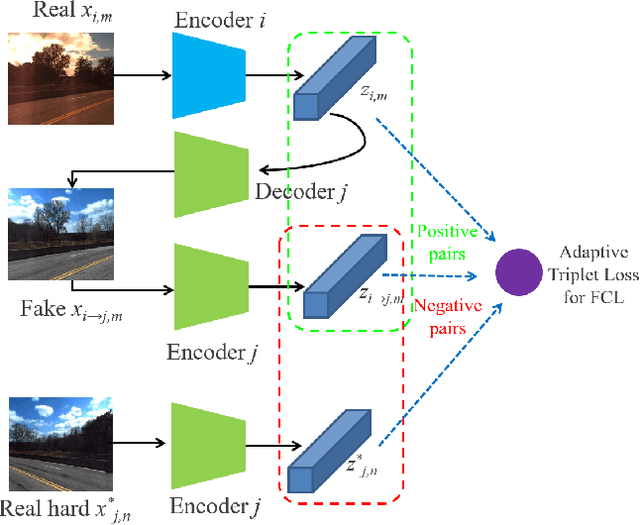
Visual localization is a crucial component in the application of mobile robot and autonomous driving. Image retrieval is an efficient and effective technique in image-based localization methods. Due to the drastic variability of environmental conditions, e.g.Su illumination, seasonal and weather changes, retrieval-based visual localization is severely affected and becomes a challenging problem. In this work, a general architecture is first formulated probabilistically to extract domain-invariant feature through multi-domain image translation. And then a novel gradient-weighted similarity activation mapping loss (Grad-SAM) is incorporated for finer localization with high accuracy. We also propose a new adaptive triplet loss to boost the metric learning of the embedding in a self-supervised manner. The final coarse-to-fine image retrieval pipeline is implemented as the sequential combination of models without and with Grad-SAM loss. Extensive experiments have been conducted to validate the effectiveness of the proposed approach on the CMU-Seasons dataset. The strong generalization ability of our approach is verified on RobotCar dataset using models pre-trained on urban part of CMU-Seasons dataset. Our performance is on par with or even outperforms the state-of-the-art image-based localization baselines in medium or high precision, especially under the challenging environments with illumination variance, vegetation and night-time images.
Grey Models for Short-Term Queue Length Predictions for Adaptive Traffic Signal Control
Dec 29, 2019

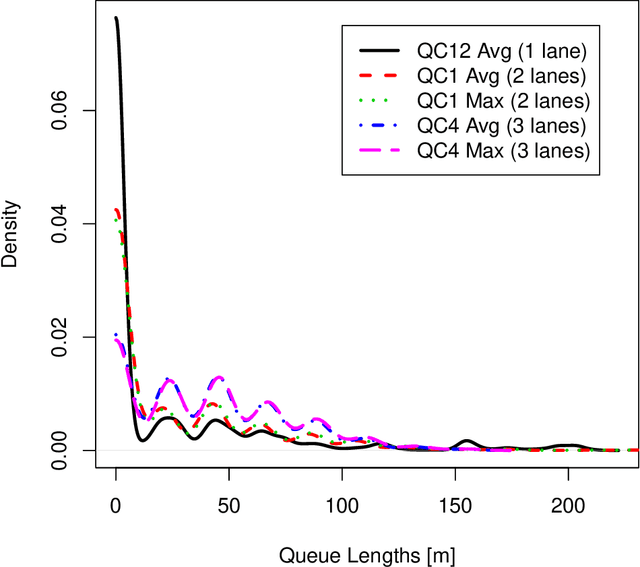

Traffic congestion at a signalized intersection greatly reduces the travel time reliability in urban areas. Adaptive signal control system (ASCS) is the most advanced traffic signal technology that regulates the signal phasing and timings considering the patterns in real-time in order to reduce congestion. Real-time prediction of queue lengths can be used to adjust the phasing and timings for different movements at an intersection with ASCS. The accuracy of the prediction varies based on the factors, such as the stochastic nature of the vehicle arrival rates, time of the day, weather and driver characteristics. In addition, accurate prediction for multilane, undersaturated and saturated traffic scenarios is challenging. Thus, the objective of this study is to develop queue length prediction models for signalized intersections that can be leveraged by ASCS using four variations of Grey systems: (i) the first order single variable Grey model (GM(1,1)); (ii) GM(1,1) with Fourier error corrections; (iii) the Grey Verhulst model (GVM), and (iv) GVM with Fourier error corrections. The efficacy of the GM is that they facilitate fast processing; as these models do not require a large amount of data; as would be needed in artificial intelligence models; and they are able to adapt to stochastic changes, unlike statistical models. We have conducted a case study using queue length data from five intersections with ASCS on a calibrated roadway network in Lexington, South Carolina. GM were compared with linear, nonlinear time series models, and long short-term memory (LSTM) neural network. Based on our analyses, we found that EGVM reduces the prediction error over closest competing models (i.e., LSTM and time series models) in predicting average and maximum queue lengths by 40% and 42%, respectively, in terms of Root Mean Squared Error, and 51% and 50%, respectively, in terms of Mean Absolute Error.
The Effect of Spectrogram Reconstruction on Automatic Music Transcription: An Alternative Approach to Improve Transcription Accuracy
Oct 20, 2020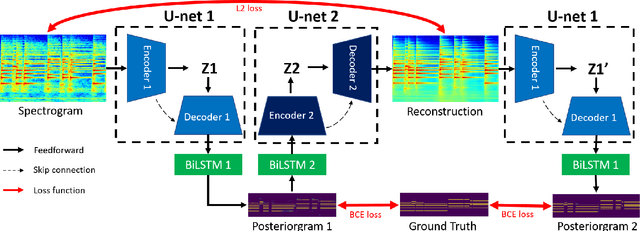

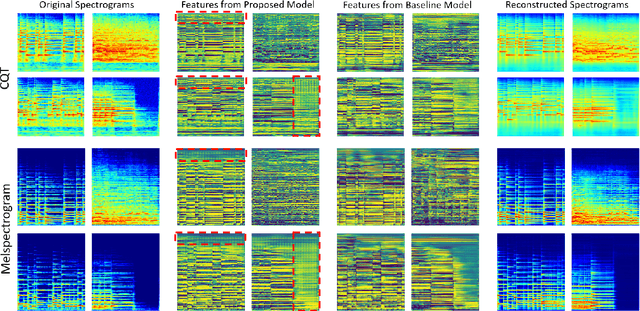

Most of the state-of-the-art automatic music transcription (AMT) models break down the main transcription task into sub-tasks such as onset prediction and offset prediction and train them with onset and offset labels. These predictions are then concatenated together and used as the input to train another model with the pitch labels to obtain the final transcription. We attempt to use only the pitch labels (together with spectrogram reconstruction loss) and explore how far this model can go without introducing supervised sub-tasks. In this paper, we do not aim at achieving state-of-the-art transcription accuracy, instead, we explore the effect that spectrogram reconstruction has on our AMT model. Our proposed model consists of two U-nets: the first U-net transcribes the spectrogram into a posteriorgram, and a second U-net transforms the posteriorgram back into a spectrogram. A reconstruction loss is applied between the original spectrogram and the reconstructed spectrogram to constrain the second U-net to focus only on reconstruction. We train our model on three different datasets: MAPS, MAESTRO, and MusicNet. Our experiments show that adding the reconstruction loss can generally improve the note-level transcription accuracy when compared to the same model without the reconstruction part. Moreover, it can also boost the frame-level precision to be higher than the state-of-the-art models. The feature maps learned by our U-net contain gridlike structures (not present in the baseline model) which implies that with the presence of the reconstruction loss, the model is probably trying to count along both the time and frequency axis, resulting in a higher note-level transcription accuracy.
Examining the causal structures of deep neural networks using information theory
Oct 26, 2020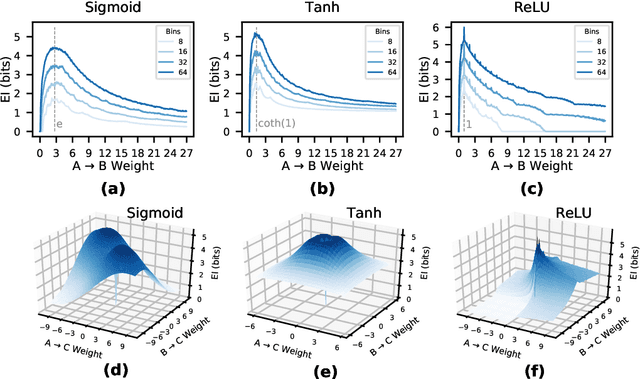
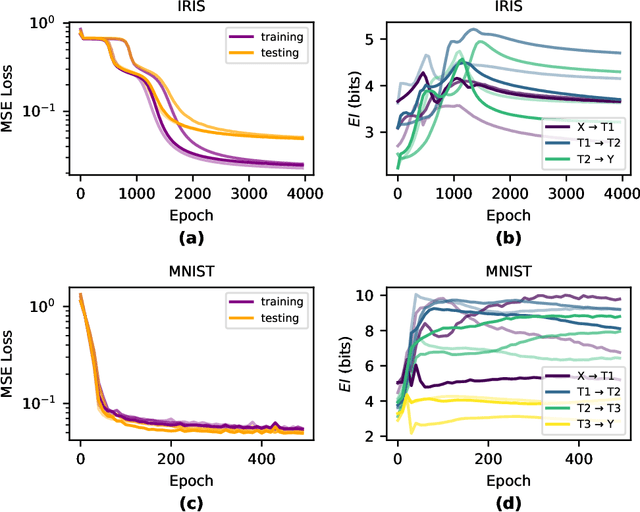
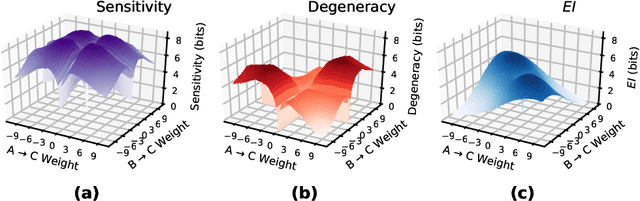
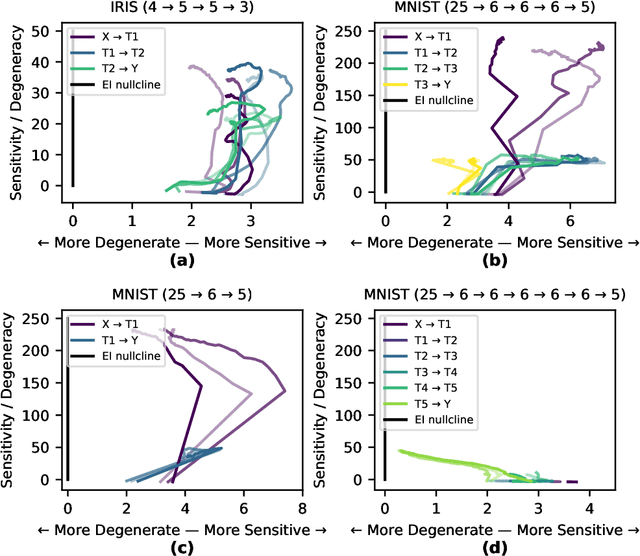
Deep Neural Networks (DNNs) are often examined at the level of their response to input, such as analyzing the mutual information between nodes and data sets. Yet DNNs can also be examined at the level of causation, exploring "what does what" within the layers of the network itself. Historically, analyzing the causal structure of DNNs has received less attention than understanding their responses to input. Yet definitionally, generalizability must be a function of a DNN's causal structure since it reflects how the DNN responds to unseen or even not-yet-defined future inputs. Here, we introduce a suite of metrics based on information theory to quantify and track changes in the causal structure of DNNs during training. Specifically, we introduce the effective information (EI) of a feedforward DNN, which is the mutual information between layer input and output following a maximum-entropy perturbation. The EI can be used to assess the degree of causal influence nodes and edges have over their downstream targets in each layer. We show that the EI can be further decomposed in order to examine the sensitivity of a layer (measured by how well edges transmit perturbations) and the degeneracy of a layer (measured by how edge overlap interferes with transmission), along with estimates of the amount of integrated information of a layer. Together, these properties define where each layer lies in the "causal plane" which can be used to visualize how layer connectivity becomes more sensitive or degenerate over time, and how integration changes during training, revealing how the layer-by-layer causal structure differentiates. These results may help in understanding the generalization capabilities of DNNs and provide foundational tools for making DNNs both more generalizable and more explainable.
Towards Cross-modality Medical Image Segmentation with Online Mutual Knowledge Distillation
Oct 04, 2020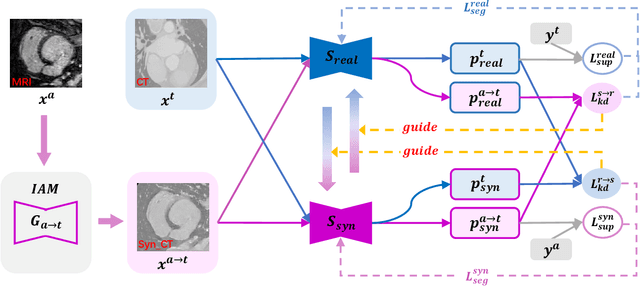
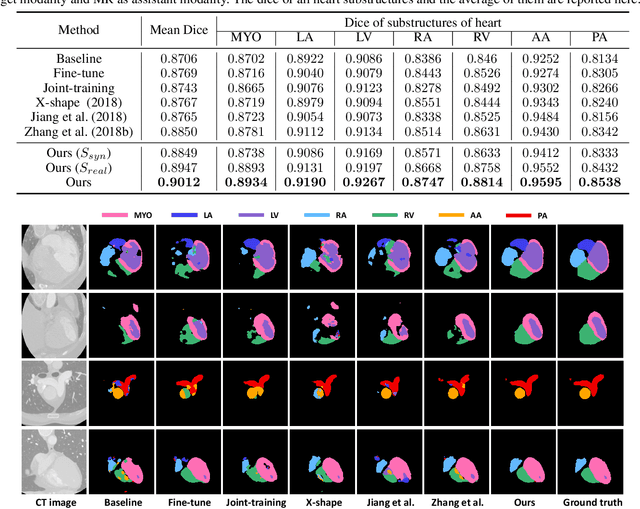
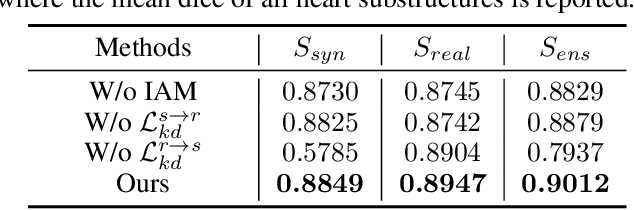
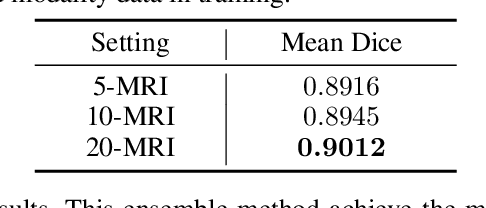
The success of deep convolutional neural networks is partially attributed to the massive amount of annotated training data. However, in practice, medical data annotations are usually expensive and time-consuming to be obtained. Considering multi-modality data with the same anatomic structures are widely available in clinic routine, in this paper, we aim to exploit the prior knowledge (e.g., shape priors) learned from one modality (aka., assistant modality) to improve the segmentation performance on another modality (aka., target modality) to make up annotation scarcity. To alleviate the learning difficulties caused by modality-specific appearance discrepancy, we first present an Image Alignment Module (IAM) to narrow the appearance gap between assistant and target modality data.We then propose a novel Mutual Knowledge Distillation (MKD) scheme to thoroughly exploit the modality-shared knowledge to facilitate the target-modality segmentation. To be specific, we formulate our framework as an integration of two individual segmentors. Each segmentor not only explicitly extracts one modality knowledge from corresponding annotations, but also implicitly explores another modality knowledge from its counterpart in mutual-guided manner. The ensemble of two segmentors would further integrate the knowledge from both modalities and generate reliable segmentation results on target modality. Experimental results on the public multi-class cardiac segmentation data, i.e., MMWHS 2017, show that our method achieves large improvements on CT segmentation by utilizing additional MRI data and outperforms other state-of-the-art multi-modality learning methods.
* Accepted by AAAI 2020
Energy-Aware Multi-Server Mobile Edge Computing: A Deep Reinforcement Learning Approach
Dec 22, 2019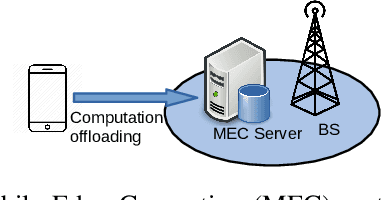
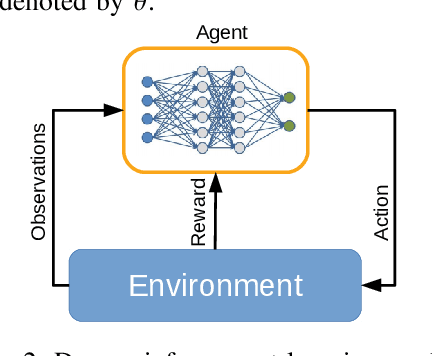
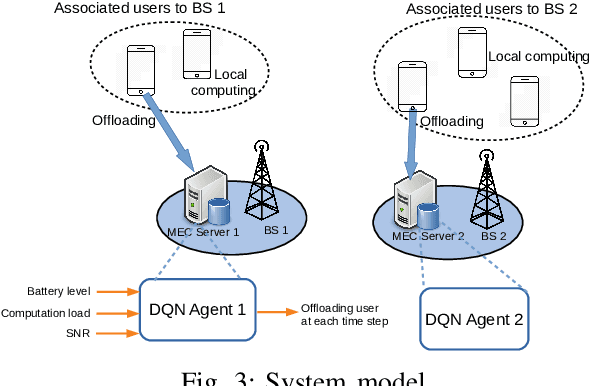
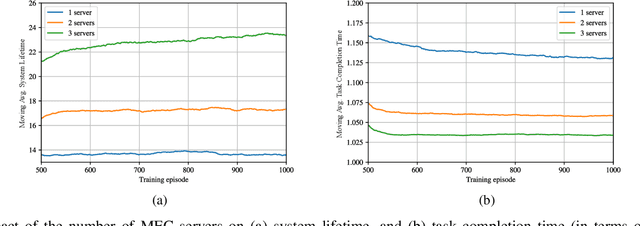
We investigate the problem of computation offloading in a mobile edge computing architecture, where multiple energy-constrained users compete to offload their computational tasks to multiple servers through a shared wireless medium. We propose a multi-agent deep reinforcement learning algorithm, where each server is equipped with an agent, observing the status of its associated users and selecting the best user for offloading at each step. We consider computation time (i.e., task completion time) and system lifetime as two key performance indicators, and we numerically demonstrate that our approach outperforms baseline algorithms in terms of the trade-off between computation time and system lifetime.
Optimization Landscape of Tucker Decomposition
Jun 29, 2020
Tucker decomposition is a popular technique for many data analysis and machine learning applications. Finding a Tucker decomposition is a nonconvex optimization problem. As the scale of the problems increases, local search algorithms such as stochastic gradient descent have become popular in practice. In this paper, we characterize the optimization landscape of the Tucker decomposition problem. In particular, we show that if the tensor has an exact Tucker decomposition, for a standard nonconvex objective of Tucker decomposition, all local minima are also globally optimal. We also give a local search algorithm that can find an approximate local (and global) optimal solution in polynomial time.
When Not to Classify: Anomaly Detection of Attacks (ADA) on DNN Classifiers at Test Time
Jun 28, 2018

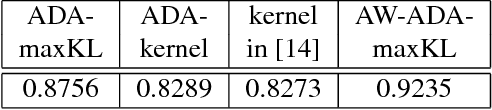

A significant threat to the recent, wide deployment of machine learning-based systems, including deep neural networks (DNNs), is adversarial learning attacks. We analyze possible test-time evasion-attack mechanisms and show that, in some important cases, when the image has been attacked, correctly classifying it has no utility: i) when the image to be attacked is (even arbitrarily) selected from the attacker's cache; ii) when the sole recipient of the classifier's decision is the attacker. Moreover, in some application domains and scenarios it is highly actionable to detect the attack irrespective of correctly classifying in the face of it (with classification still performed if no attack is detected). We hypothesize that, even if human-imperceptible, adversarial perturbations are machine-detectable. We propose a purely unsupervised anomaly detector (AD) that, unlike previous works: i) models the joint density of a deep layer using highly suitable null hypothesis density models (matched in particular to the non- negative support for RELU layers); ii) exploits multiple DNN layers; iii) leverages a "source" and "destination" class concept, source class uncertainty, the class confusion matrix, and DNN weight information in constructing a novel decision statistic grounded in the Kullback-Leibler divergence. Tested on MNIST and CIFAR-10 image databases under three prominent attack strategies, our approach outperforms previous detection methods, achieving strong ROC AUC detection accuracy on two attacks and better accuracy than recently reported for a variety of methods on the strongest (CW) attack. We also evaluate a fully white box attack on our system. Finally, we evaluate other important performance measures, such as classification accuracy, versus detection rate and attack strength.
Multi-Robot Task Allocation and Scheduling Considering Cooperative Tasks and Precedence Constraints
May 08, 2020
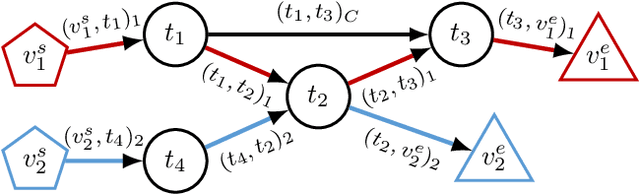
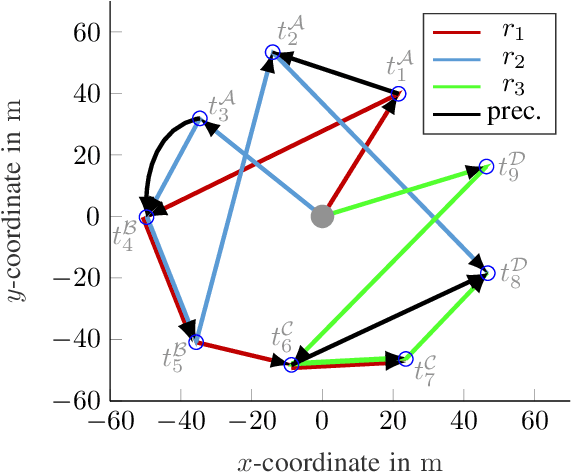
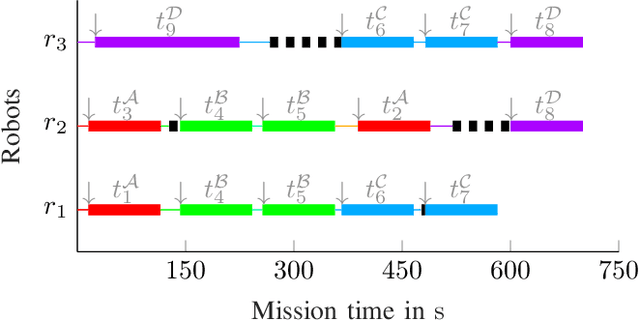
In order to fully exploit the advantages inherent to cooperating heterogeneous multi-robot teams, sophisticated coordination algorithms are essential. Time-extended multi-robot task allocation approaches assign and schedule a set of tasks to a group of robots such that certain objectives are optimized and operational constraints are met. This is particularly challenging if cooperative tasks, i.e. tasks that require two or more robots to work directly together, are considered. In this paper, we present an easy-to-implement criterion to validate the feasibility, i.e. executability, of solutions to time-extended multi-robot task allocation problems with cross schedule dependencies arising from the consideration of cooperative tasks and precedence constraints. Using the introduced feasibility criterion, we propose a local improvement heuristic based on a neighborhood operator for the problem class under consideration. The initial solution is obtained by a greedy constructive heuristic. Both methods use a generalized cost structure and are therefore able to handle various objective function instances. We evaluate the proposed approach using test scenarios of different problem sizes, all comprising the complexity aspects of the regarded problem. The simulation results illustrate the improvement potential arising from the application of the local improvement heuristic.
Stepwise Model Selection for Sequence Prediction via Deep Kernel Learning
Feb 14, 2020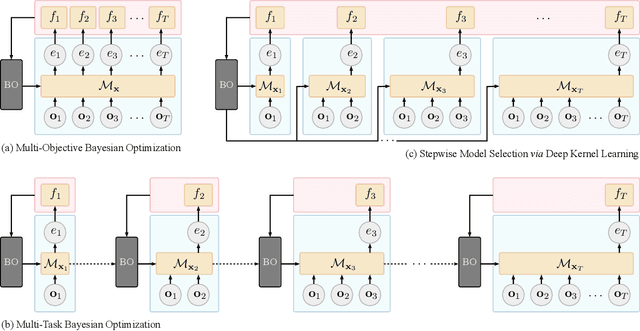

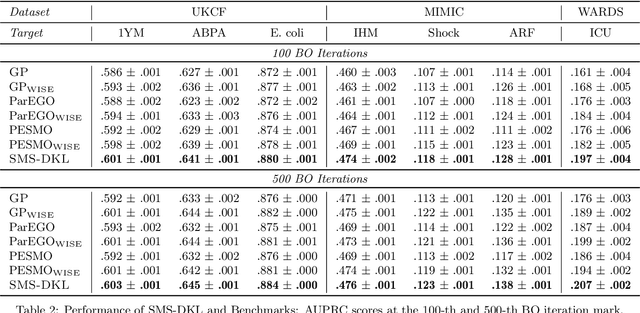
An essential problem in automated machine learning (AutoML) is that of model selection. A unique challenge in the sequential setting is the fact that the optimal model itself may vary over time, depending on the distribution of features and labels available up to each point in time. In this paper, we propose a novel Bayesian optimization (BO) algorithm to tackle the challenge of model selection in this setting. This is accomplished by treating the performance at each time step as its own black-box function. In order to solve the resulting multiple black-box function optimization problem jointly and efficiently, we exploit potential correlations among black-box functions using deep kernel learning (DKL). To the best of our knowledge, we are the first to formulate the problem of stepwise model selection (SMS) for sequence prediction, and to design and demonstrate an efficient joint-learning algorithm for this purpose. Using multiple real-world datasets, we verify that our proposed method outperforms both standard BO and multi-objective BO algorithms on a variety of sequence prediction tasks.