 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Not to Classify: Anomaly Detection of Attacks on DNN Classifiers at Test Time
Paper and Code
Jun 28, 2018

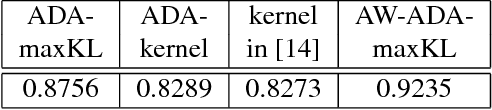

A significant threat to the recent, wide deployment of machine learning-based systems, including deep neural networks (DNNs), is adversarial learning attacks. We analyze possible test-time evasion-attack mechanisms and show that, in some important cases, when the image has been attacked, correctly classifying it has no utility: i) when the image to be attacked is (even arbitrarily) selected from the attacker's cache; ii) when the sole recipient of the classifier's decision is the attacker. Moreover, in some application domains and scenarios it is highly actionable to detect the attack irrespective of correctly classifying in the face of it (with classification still performed if no attack is detected). We hypothesize that, even if human-imperceptible, adversarial perturbations are machine-detectable. We propose a purely unsupervised anomaly detector (AD) that, unlike previous works: i) models the joint density of a deep layer using highly suitable null hypothesis density models (matched in particular to the non- negative support for RELU layers); ii) exploits multiple DNN layers; iii) leverages a "source" and "destination" class concept, source class uncertainty, the class confusion matrix, and DNN weight information in constructing a novel decision statistic grounded in the Kullback-Leibler divergence. Tested on MNIST and CIFAR-10 image databases under three prominent attack strategies, our approach outperforms previous detection methods, achieving strong ROC AUC detection accuracy on two attacks and better accuracy than recently reported for a variety of methods on the strongest (CW) attack. We also evaluate a fully white box attack on our system. Finally, we evaluate other important performance measures, such as classification accuracy, versus detection rate and attack strength.