 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Locally Differentially Private Embedding Models in Distributed Fraud Prevention Systems
Jan 03, 2024
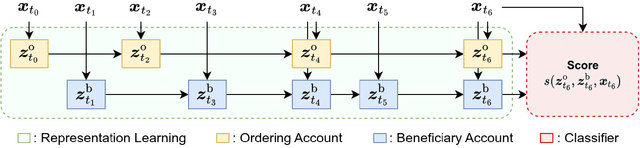
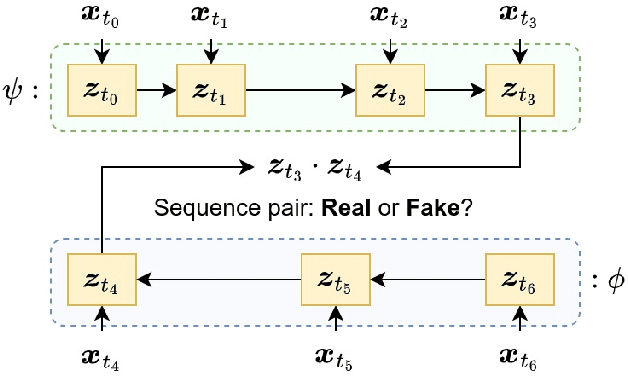
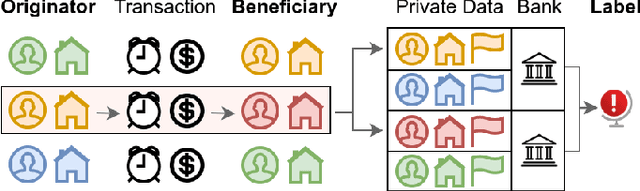
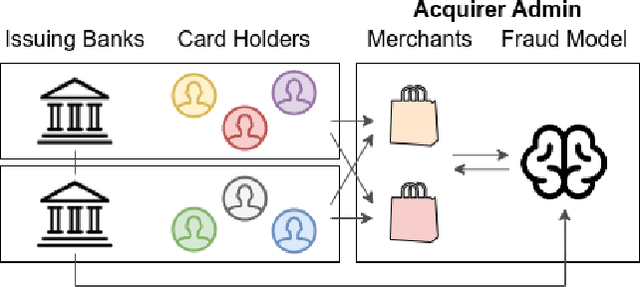
Global financial crime activity is driving demand for machine learning solutions in fraud prevention. However, prevention systems are commonly serviced to financial institutions in isolation, and few provisions exist for data sharing due to fears of unintentional leaks and adversarial attacks. Collaborative learning advances in finance are rare, and it is hard to find real-world insights derived from privacy-preserving data processing systems. In this paper, we present a collaborative deep learning framework for fraud prevention, designed from a privacy standpoint, and awarded at the recent PETs Prize Challenges. We leverage latent embedded representations of varied-length transaction sequences, along with local differential privacy, in order to construct a data release mechanism which can securely inform externally hosted fraud and anomaly detection models. We assess our contribution on two distributed data sets donated by large payment networks, and demonstrate robustness to popular inference-time attacks, along with utility-privacy trade-offs analogous to published work in alternative application domains.
Analytically-Driven Resource Management for Cloud-Native Microservices
Jan 05, 2024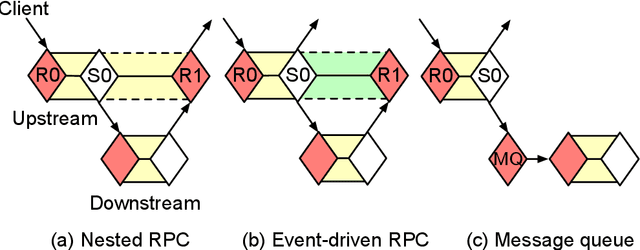
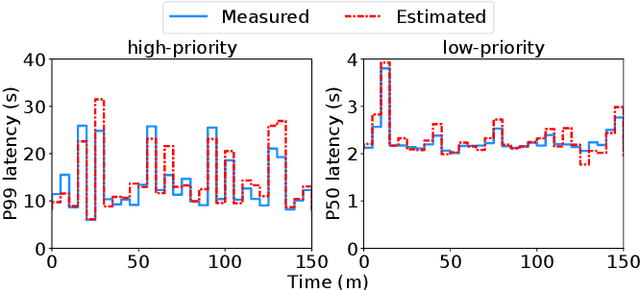
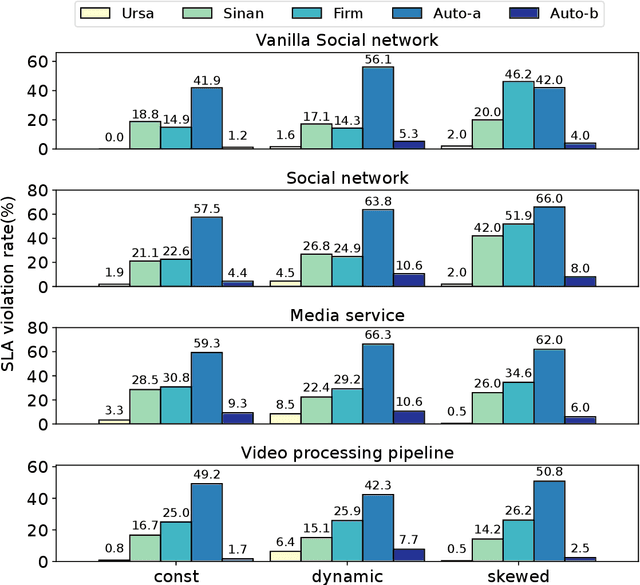
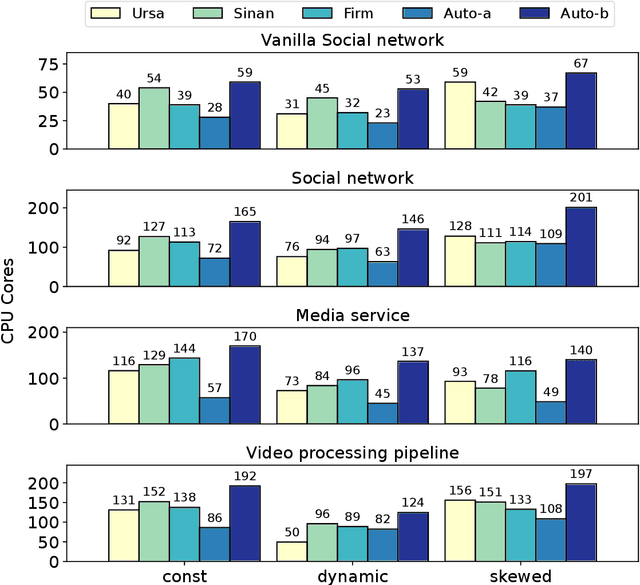
Resource management for cloud-native microservices has attracted a lot of recent attention. Previous work has shown that machine learning (ML)-driven approaches outperform traditional techniques, such as autoscaling, in terms of both SLA maintenance and resource efficiency. However, ML-driven approaches also face challenges including lengthy data collection processes and limited scalability. We present Ursa, a lightweight resource management system for cloud-native microservices that addresses these challenges. Ursa uses an analytical model that decomposes the end-to-end SLA into per-service SLA, and maps per-service SLA to individual resource allocations per microservice tier. To speed up the exploration process and avoid prolonged SLA violations, Ursa explores each microservice individually, and swiftly stops exploration if latency exceeds its SLA. We evaluate Ursa on a set of representative and end-to-end microservice topologies, including a social network, media service and video processing pipeline, each consisting of multiple classes and priorities of requests with different SLAs, and compare it against two representative ML-driven systems, Sinan and Firm. Compared to these ML-driven approaches, Ursa provides significant advantages: It shortens the data collection process by more than 128x, and its control plane is 43x faster than ML-driven approaches. At the same time, Ursa does not sacrifice resource efficiency or SLAs. During online deployment, Ursa reduces the SLA violation rate by 9.0% up to 49.9%, and reduces CPU allocation by up to 86.2% compared to ML-driven approaches.
Joint User Association and Power Control for Cell-Free Massive MIMO
Jan 05, 2024This work proposes novel approaches that jointly design user equipment (UE) association and power control (PC) in a downlink user-centric cell-free massive multiple-input multiple-output (CFmMIMO) network, where each UE is only served by a set of access points (APs) for reducing the fronthaul signalling and computational complexity. In order to maximize the sum spectral efficiency (SE) of the UEs, we formulate a mixed-integer nonconvex optimization problem under constraints on the per-AP transmit power, quality-of-service rate requirements, maximum fronthaul signalling load, and maximum number of UEs served by each AP. In order to solve the formulated problem efficiently, we propose two different schemes according to the different sizes of the CFmMIMO systems. For small-scale CFmMIMO systems, we present a successive convex approximation (SCA) method to obtain a stationary solution and also develop a learning-based method (JointCFNet) to reduce the computational complexity. For large-scale CFmMIMO systems, we propose a low-complexity suboptimal algorithm using accelerated projected gradient (APG) techniques. Numerical results show that our JointCFNet can yield similar performance and significantly decrease the run time compared with the SCA algorithm in small-scale systems. The presented APG approach is confirmed to run much faster than the SCA algorithm in the large-scale system while obtaining an SE performance close to that of the SCA approach. Moreover, the median sum SE of the APG method is up to about 2.8 fold higher than that of the heuristic baseline scheme.
Transfer Learning-based Real-time Handgun Detection
Nov 23, 2023Traditional surveillance systems rely on human attention, limiting their effectiveness. This study employs convolutional neural networks and transfer learning to develop a real-time computer vision system for automatic handgun detection. Comprehensive analysis of online handgun detection methods is conducted, emphasizing reducing false positives and learning time. Transfer learning is demonstrated as an effective approach. Despite technical challenges, the proposed system achieves a precision rate of 84.74%, demonstrating promising performance comparable to related works, enabling faster learning and accurate automatic handgun detection for enhanced security. This research advances security measures by reducing human monitoring dependence, showcasing the potential of transfer learning-based approaches for efficient and reliable handgun detection.
Bidirectional Temporal Plan Graph: Enabling Switchable Passing Orders for More Efficient Multi-Agent Path Finding Plan Execution
Dec 30, 2023The Multi-Agent Path Finding (MAPF) problem involves planning collision-free paths for multiple agents in a shared environment. The majority of MAPF solvers rely on the assumption that an agent can arrive at a specific location at a specific timestep. However, real-world execution uncertainties can cause agents to deviate from this assumption, leading to collisions and deadlocks. Prior research solves this problem by having agents follow a Temporal Plan Graph (TPG), enforcing a consistent passing order at every location as defined in the MAPF plan. However, we show that TPGs are overly strict because, in some circumstances, satisfying the passing order requires agents to wait unnecessarily, leading to longer execution time. To overcome this issue, we introduce a new graphical representation called a Bidirectional Temporal Plan Graph (BTPG), which allows switching passing orders during execution to avoid unnecessary waiting time. We design two anytime algorithms for constructing a BTPG: BTPG-na\"ive and BTPG-optimized. Experimental results show that following BTPGs consistently outperforms following TPGs, reducing unnecessary waits by 8-20%.
Unicron: Economizing Self-Healing LLM Training at Scale
Dec 30, 2023Training large-scale language models is increasingly critical in various domains, but it is hindered by frequent failures, leading to significant time and economic costs. Current failure recovery methods in cloud-based settings inadequately address the diverse and complex scenarios that arise, focusing narrowly on erasing downtime for individual tasks without considering the overall cost impact on a cluster. We introduce Unicron, a workload manager designed for efficient self-healing in large-scale language model training. Unicron optimizes the training process by minimizing failure-related costs across multiple concurrent tasks within a cluster. Its key features include in-band error detection for real-time error identification without extra overhead, a dynamic cost-aware plan generation mechanism for optimal reconfiguration, and an efficient transition strategy to reduce downtime during state changes. Deployed on a 128-GPU distributed cluster, Unicron demonstrates up to a 1.9x improvement in training efficiency over state-of-the-art methods, significantly reducing failure recovery costs and enhancing the reliability of large-scale language model training.
Event-Based Contrastive Learning for Medical Time Series
Dec 16, 2023In clinical practice, one often needs to identify whether a patient is at high risk of adverse outcomes after some key medical event; e.g., the short-term risk of death after an admission for heart failure. This task, however, remains challenging due to the complexity, variability, and heterogeneity of longitudinal medical data, especially for individuals suffering from chronic diseases like heart failure. In this paper, we introduce Event-Based Contrastive Learning (EBCL) - a method for learning embeddings of heterogeneous patient data that preserves temporal information before and after key index events. We demonstrate that EBCL produces models that yield better fine-tuning performance on critical downstream tasks including 30-day readmission, 1-year mortality, and 1-week length of stay relative to other representation learning methods that do not exploit temporal information surrounding key medical events.
To Diverge or Not to Diverge: A Morphosyntactic Perspective on Machine Translation vs Human Translation
Jan 02, 2024We conduct a large-scale fine-grained comparative analysis of machine translations (MT) against human translations (HT) through the lens of morphosyntactic divergence. Across three language pairs and two types of divergence defined as the structural difference between the source and the target, MT is consistently more conservative than HT, with less morphosyntactic diversity, more convergent patterns, and more one-to-one alignments. Through analysis on different decoding algorithms, we attribute this discrepancy to the use of beam search that biases MT towards more convergent patterns. This bias is most amplified when the convergent pattern appears around 50% of the time in training data. Lastly, we show that for a majority of morphosyntactic divergences, their presence in HT is correlated with decreased MT performance, presenting a greater challenge for MT systems.
Near-real-time Earthquake-induced Fatality Estimation using Crowdsourced Data and Large-Language Models
Dec 04, 2023When a damaging earthquake occurs, immediate information about casualties is critical for time-sensitive decision-making by emergency response and aid agencies in the first hours and days. Systems such as Prompt Assessment of Global Earthquakes for Response (PAGER) by the U.S. Geological Survey (USGS) were developed to provide a forecast within about 30 minutes of any significant earthquake globally. Traditional systems for estimating human loss in disasters often depend on manually collected early casualty reports from global media, a process that's labor-intensive and slow with notable time delays. Recently, some systems have employed keyword matching and topic modeling to extract relevant information from social media. However, these methods struggle with the complex semantics in multilingual texts and the challenge of interpreting ever-changing, often conflicting reports of death and injury numbers from various unverified sources on social media platforms. In this work, we introduce an end-to-end framework to significantly improve the timeliness and accuracy of global earthquake-induced human loss forecasting using multi-lingual, crowdsourced social media. Our framework integrates (1) a hierarchical casualty extraction model built upon large language models, prompt design, and few-shot learning to retrieve quantitative human loss claims from social media, (2) a physical constraint-aware, dynamic-truth discovery model that discovers the truthful human loss from massive noisy and potentially conflicting human loss claims, and (3) a Bayesian updating loss projection model that dynamically updates the final loss estimation using discovered truths. We test the framework in real-time on a series of global earthquake events in 2021 and 2022 and show that our framework streamlines casualty data retrieval, achieving speed and accuracy comparable to manual methods by USGS.
Preference as Reward, Maximum Preference Optimization with Importance Sampling
Jan 04, 2024Preference learning is a key technology for aligning language models with human values. Reinforcement Learning from Human Feedback (RLHF) is a model based algorithm to optimize preference learning, which first fitting a reward model for preference score, and then optimizing generating policy with on-policy PPO algorithm to maximize the reward. The processing of RLHF is complex, time-consuming and unstable. Direct Preference Optimization (DPO) algorithm using off-policy algorithm to direct optimize generating policy and eliminating the need for reward model, which is data efficient and stable. DPO use Bradley-Terry model and log-loss which leads to over-fitting to the preference data at the expense of ignoring KL-regularization term when preference near deterministic. IPO uses a root-finding pairwise MSE loss to solve the ignoring KL-regularization problem, and learning an optimal policy. But IPO's pairwise loss still can't s make the KL-regularization to work. In this paper, we design a simple and intuitive off-policy preferences optimization algorithm from an importance sampling view, and add an off-policy KL-regularization term which makes KL-regularization truly effective. To simplify the learning process and save memory usage, we can generate regularization data in advance, which eliminate the needs for both reward model and reference policy in the stage of optimization.