 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint User Association and Power Control for Cell-Free Massive MIMO
Jan 05, 2024This work proposes novel approaches that jointly design user equipment (UE) association and power control (PC) in a downlink user-centric cell-free massive multiple-input multiple-output (CFmMIMO) network, where each UE is only served by a set of access points (APs) for reducing the fronthaul signalling and computational complexity. In order to maximize the sum spectral efficiency (SE) of the UEs, we formulate a mixed-integer nonconvex optimization problem under constraints on the per-AP transmit power, quality-of-service rate requirements, maximum fronthaul signalling load, and maximum number of UEs served by each AP. In order to solve the formulated problem efficiently, we propose two different schemes according to the different sizes of the CFmMIMO systems. For small-scale CFmMIMO systems, we present a successive convex approximation (SCA) method to obtain a stationary solution and also develop a learning-based method (JointCFNet) to reduce the computational complexity. For large-scale CFmMIMO systems, we propose a low-complexity suboptimal algorithm using accelerated projected gradient (APG) techniques. Numerical results show that our JointCFNet can yield similar performance and significantly decrease the run time compared with the SCA algorithm in small-scale systems. The presented APG approach is confirmed to run much faster than the SCA algorithm in the large-scale system while obtaining an SE performance close to that of the SCA approach. Moreover, the median sum SE of the APG method is up to about 2.8 fold higher than that of the heuristic baseline scheme.
Graph Augmentation Learning
Mar 17, 2022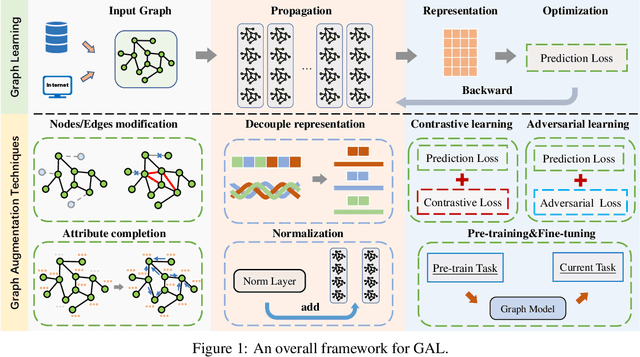

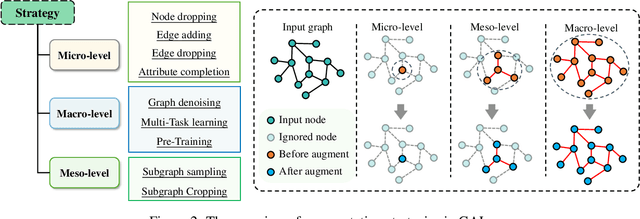

Graph Augmentation Learning (GAL) provides outstanding solutions for graph learning in handling incomplete data, noise data, etc. Numerous GAL methods have been proposed for graph-based applications such as social network analysis and traffic flow forecasting. However, the underlying reasons for the effectiveness of these GAL methods are still unclear. As a consequence, how to choose optimal graph augmentation strategy for a certain application scenario is still in black box. There is a lack of systematic, comprehensive, and experimentally validated guideline of GAL for scholars. Therefore, in this survey, we in-depth review GAL techniques from macro (graph), meso (subgraph), and micro (node/edge) levels. We further detailedly illustrate how GAL enhance the data quality and the model performance. The aggregation mechanism of augmentation strategies and graph learning models are also discussed by different application scenarios, i.e., data-specific, model-specific, and hybrid scenarios. To better show the outperformance of GAL, we experimentally validate the effectiveness and adaptability of different GAL strategies in different downstream tasks. Finally, we share our insights on several open issues of GAL, including heterogeneity, spatio-temporal dynamics, scalability, and generalization.
FedU: A Unified Framework for Federated Multi-Task Learning with Laplacian Regularization
Feb 14, 2021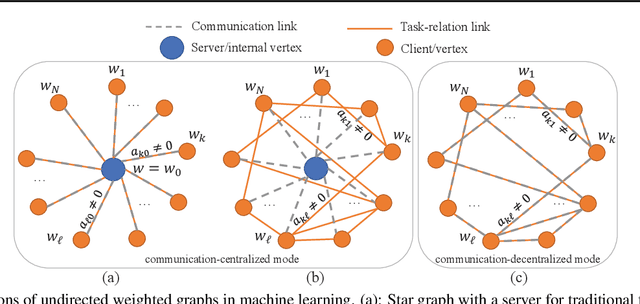
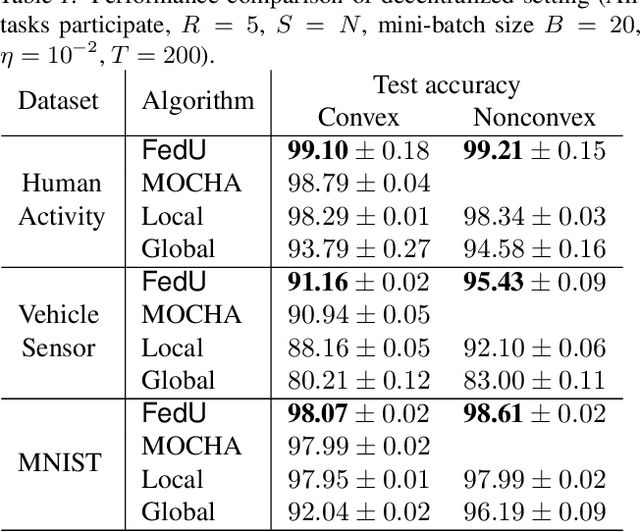
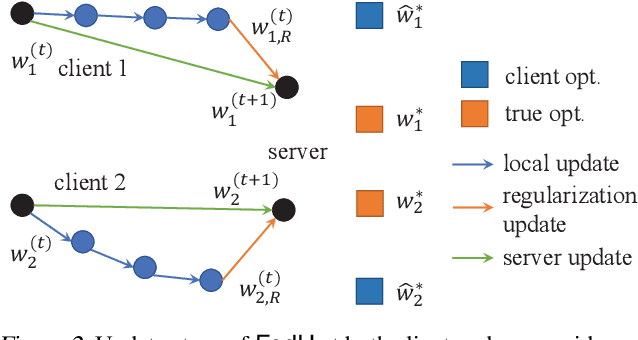
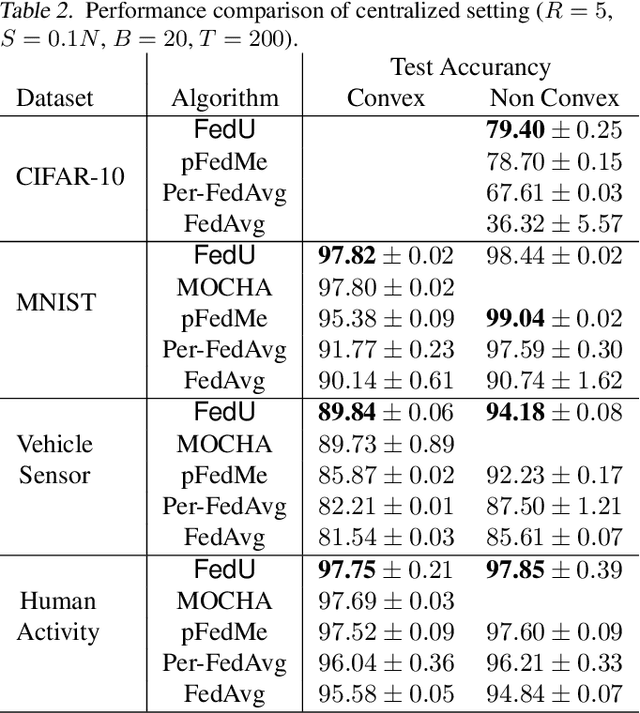
Federated multi-task learning (FMTL) has emerged as a natural choice to capture the statistical diversity among the clients in federated learning. To unleash the potential of FMTL beyond statistical diversity, we formulate a new FMTL problem FedU using Laplacian regularization, which can explicitly leverage relationships among the clients for multi-task learning. We first show that FedU provides a unified framework covering a wide range of problems such as conventional federated learning, personalized federated learning, few-shot learning, and stratified model learning. We then propose algorithms including both communication-centralized and decentralized schemes to learn optimal models of FedU. Theoretically, we show that the convergence rates of both FedU's algorithms achieve linear speedup for strongly convex and sublinear speedup of order $1/2$ for nonconvex objectives. While the analysis of FedU is applicable to both strongly convex and nonconvex loss functions, the conventional FMTL algorithm MOCHA, which is based on CoCoA framework, is only applicable to convex case. Experimentally, we verify that FedU outperforms the vanilla FedAvg, MOCHA, as well as pFedMe and Per-FedAvg in personalized federated learning.