 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Use of Bayesian Nonparametric methods for Estimating the Measurements in High Clutter
Nov 30, 2020
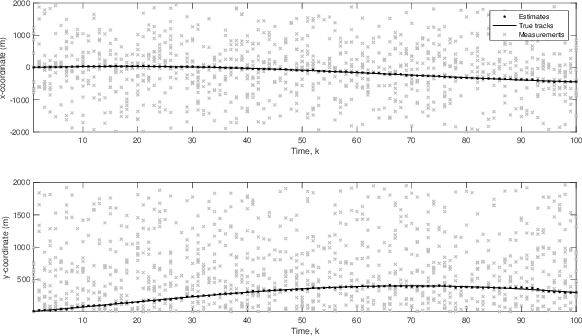
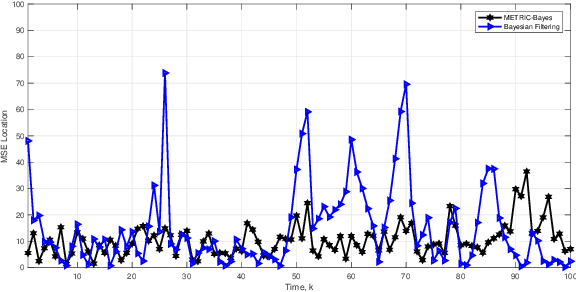
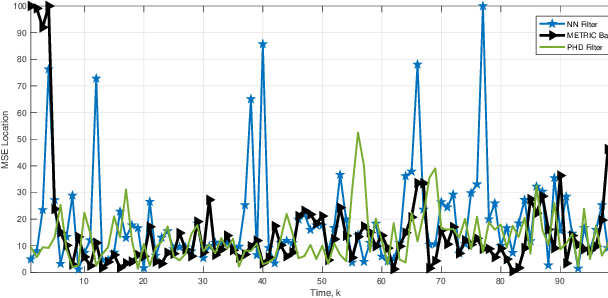
Robust tracking of a target in a clutter environment is an important and challenging task. In recent years, the nearest neighbor methods and probabilistic data association filters were proposed. However, the performance of these methods diminishes as the number of measurements increases. In this paper, we propose a robust generative approach to effectively model multiple sensor measurements for tracking a moving target in an environment with high clutter. We assume a time-dependent number of measurements that include sensor observations with unknown origin, some of which may only contain clutter with no additional information. We robustly and accurately estimate the trajectory of the moving target in a high clutter environment with an unknown number of clutters by employing Bayesian nonparametric modeling. In particular, we employ a class of joint Bayesian nonparametric models to construct the joint prior distribution of target and clutter measurements such that the conditional distributions follow a Dirichlet process. The marginalized Dirichlet process prior of the target measurements is then used in a Bayesian tracker to estimate the dynamically-varying target state. We show through experiments that the tracking performance and effectiveness of our proposed framework are increased by suppressing high clutter measurements. In addition, we show that our proposed method outperforms existing methods such as nearest neighbor and probability data association filters.
Drug-Target Interaction Prediction via an Ensemble of Weighted Nearest Neighbors with Interaction Recovery
Dec 22, 2020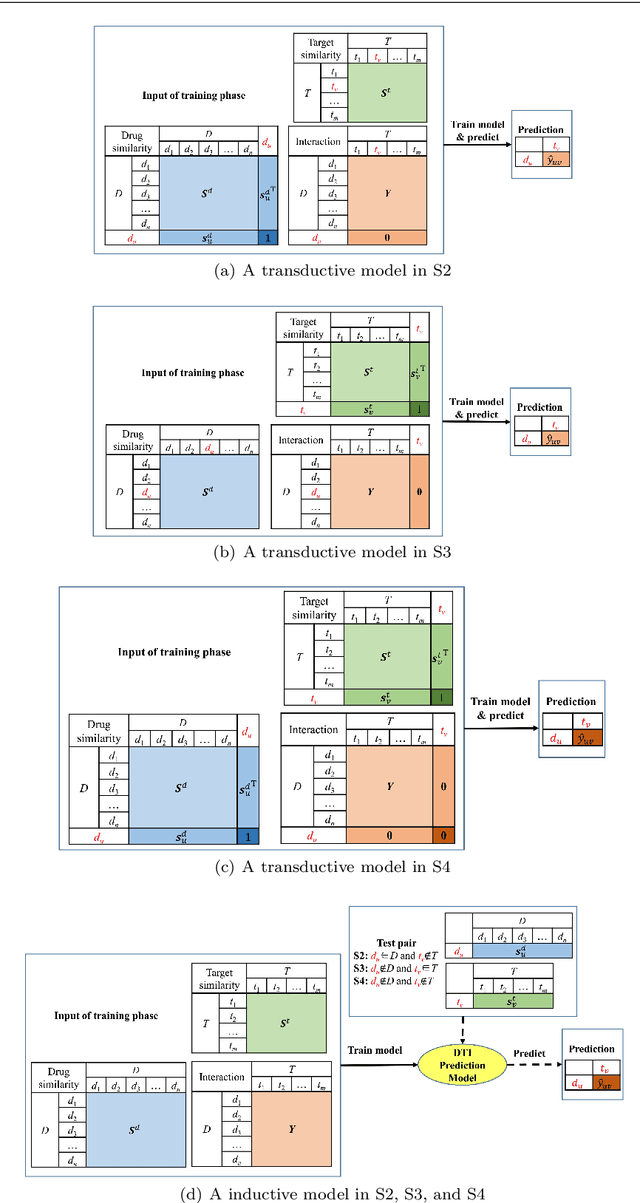


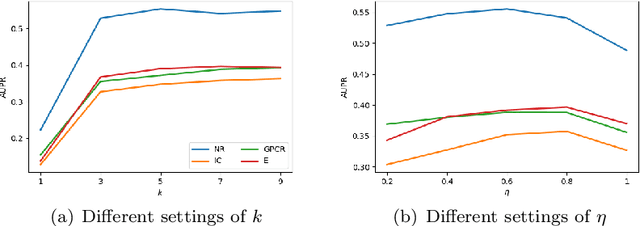
Predicting drug-target interactions (DTI) via reliable computational methods is an effective and efficient way to mitigate the enormous costs and time of the drug discovery process. Structure-based drug similarities and sequence-based target protein similarities are the commonly used information for DTI prediction. Among numerous computational methods, neighborhood-based chemogenomic approaches that leverage drug and target similarities to perform predictions directly are simple but promising ones. However, most existing similarity-based methods follow the transductive setting. These methods cannot directly generalize to unseen data because they should be re-built to predict the interactions for new arriving drugs, targets, or drug-target pairs. Besides, many similarity-based methods, especially neighborhood-based ones, cannot handle directly all three types of interaction prediction. Furthermore, a large amount of missing interactions in current DTI datasets hinders most DTI prediction methods. To address these issues, we propose a new method denoted as Weighted k Nearest Neighbor with Interaction Recovery (WkNNIR). Not only can WkNNIR estimate interactions of any new drugs and/or new targets without any need of re-training, but it can also recover missing interactions. In addition, WkNNIR exploits local imbalance to promote the influence of more reliable similarities on the DTI prediction process. We also propose a series of ensemble methods that employ diverse sampling strategies and could be coupled with WkNNIR as well as any other DTI prediction method to improve performance. Experimental results over four benchmark datasets demonstrate the effectiveness of our approaches in predicting drug-target interactions. Lastly, we confirm the practical prediction ability of proposed methods to discover reliable interactions that not reported in the original benchmark datasets.
Semantics-aware Adaptive Knowledge Distillation for Sensor-to-Vision Action Recognition
Sep 02, 2020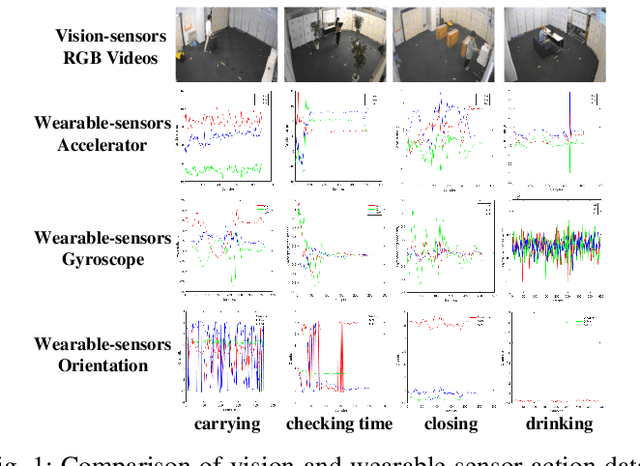
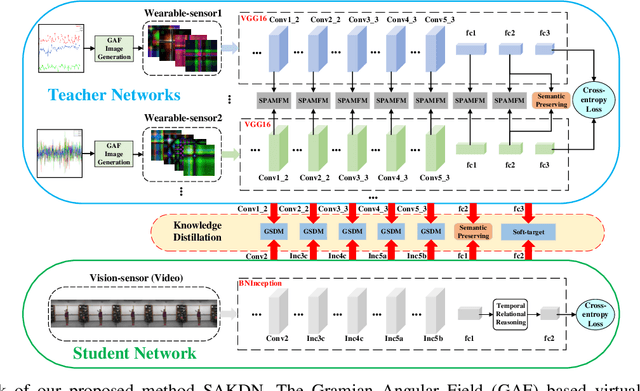
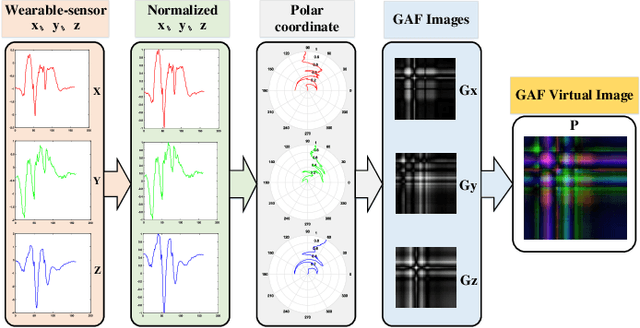
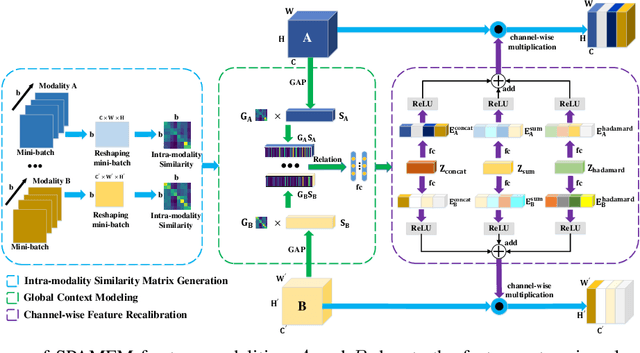
Existing vision-based action recognition is susceptible to occlusion and appearance variations, while wearable sensors can alleviate these challenges by capturing human motion with one-dimensional time-series signals (e.g. acceleration, gyroscope and orientation). For the same action, the knowledge learned from vision sensors (videos or images) and wearable sensors, may be related and complementary. However, there exists significantly large modality difference between action data captured by wearable-sensor and vision-sensor in data dimension, data distribution and inherent information content. In this paper, we propose a novel framework, named Semantics-aware Adaptive Knowledge Distillation Networks (SAKDN), to enhance action recognition in vision-sensor modality (videos) by adaptively transferring and distilling the knowledge from multiple wearable sensors. The SAKDN uses multiple wearable-sensors as teacher modalities and uses RGB videos as student modality. Specifically, we transform one-dimensional time-series signals of wearable sensors to two-dimensional images by designing a gramian angular field based virtual image generation model. Then, we build a novel Similarity-Preserving Adaptive Multi-modal Fusion Module (SPAMFM) to adaptively fuse intermediate representation knowledge from different teacher networks. To fully exploit and transfer the knowledge of multiple well-trained teacher networks to the student network, we propose a novel Graph-guided Semantically Discriminative Mapping (GSDM) loss, which utilizes graph-guided ablation analysis to produce a good visual explanation highlighting the important regions across modalities and concurrently preserving the interrelations of original data. Experimental results on Berkeley-MHAD, UTD-MHAD and MMAct datasets well demonstrate the effectiveness of our proposed SAKDN.
Dependent Matérn Processes for Multivariate Time Series
Feb 11, 2015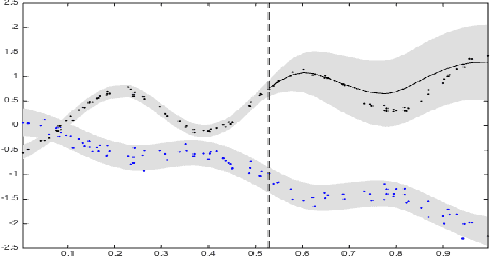
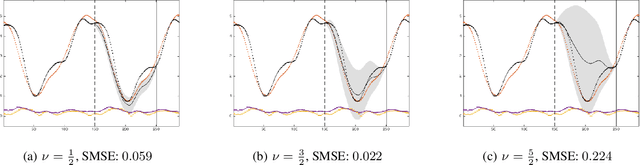
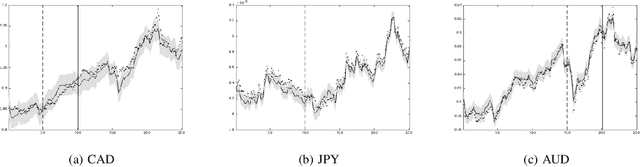
For the challenging task of modeling multivariate time series, we propose a new class of models that use dependent Mat\'ern processes to capture the underlying structure of data, explain their interdependencies, and predict their unknown values. Although similar models have been proposed in the econometric, statistics, and machine learning literature, our approach has several advantages that distinguish it from existing methods: 1) it is flexible to provide high prediction accuracy, yet its complexity is controlled to avoid overfitting; 2) its interpretability separates it from black-box methods; 3) finally, its computational efficiency makes it scalable for high-dimensional time series. In this paper, we use several simulated and real data sets to illustrate these advantages. We will also briefly discuss some extensions of our model.
DATE: Defense Against TEmperature Side-Channel Attacks in DVFS Enabled MPSoCs
Jul 02, 2020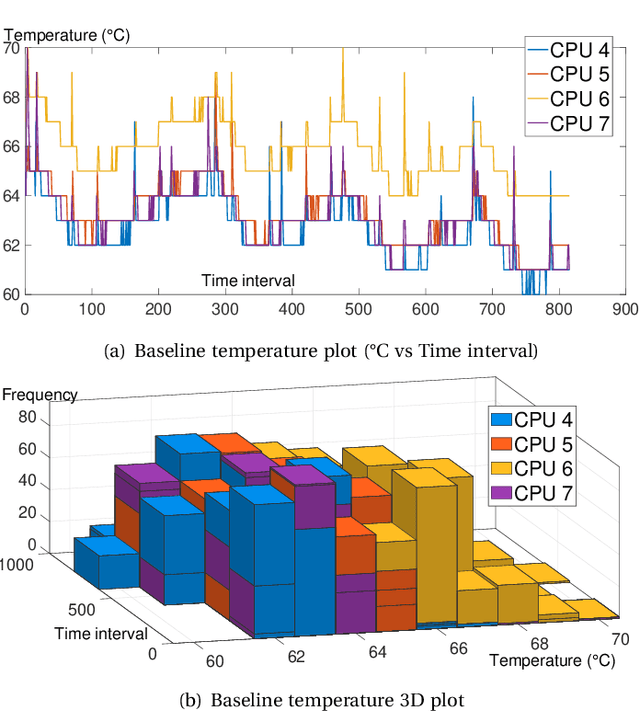
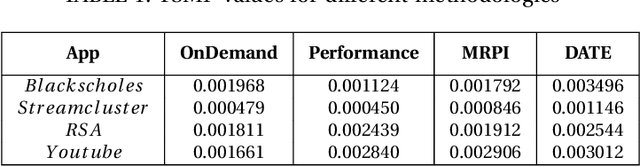
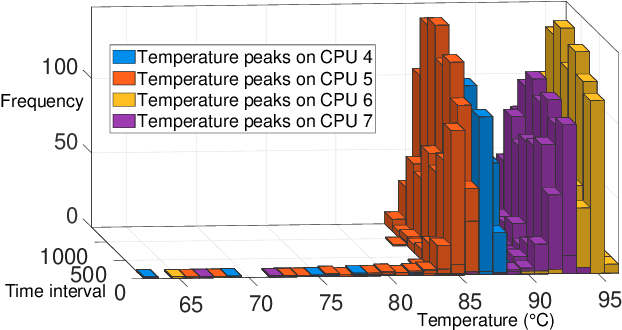
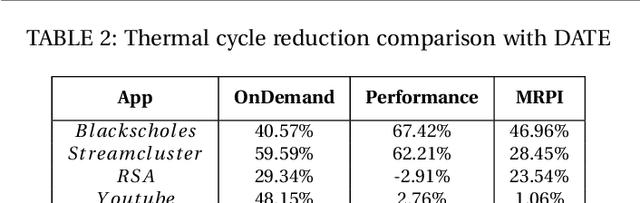
Given the constant rise in utilizing embedded devices in daily life, side channels remain a challenge to information flow control and security in such systems. One such important security flaw could be exploited through temperature side-channel attacks, where heat dissipation and propagation from the processing elements are observed over time in order to deduce security flaws. In our proposed methodology, DATE: Defense Against TEmperature side-channel attacks, we propose a novel approach of reducing spatial and temporal thermal gradient, which makes the system more secure against temperature side-channel attacks, and at the same time increases the reliability of the device in terms of lifespan. In this paper, we have also introduced a new metric, Thermal-Security-in-Multi-Processors (TSMP), which is capable of quantifying the security against temperature side-channel attacks on computing systems, and DATE is evaluated to be 139.24% more secure at the most for certain applications than the state-of-the-art, while reducing thermal cycle by 67.42% at the most.
Focal points and their implications for Möbius Transforms and Dempster-Shafer Theory
Nov 12, 2020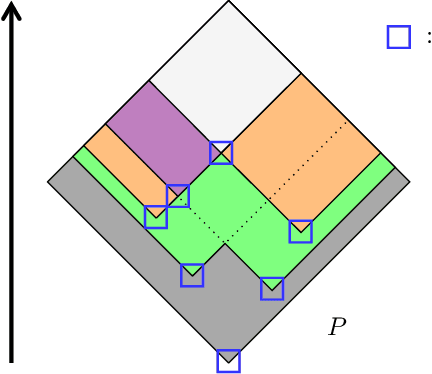
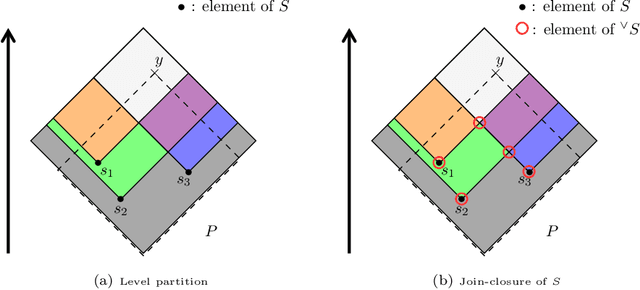
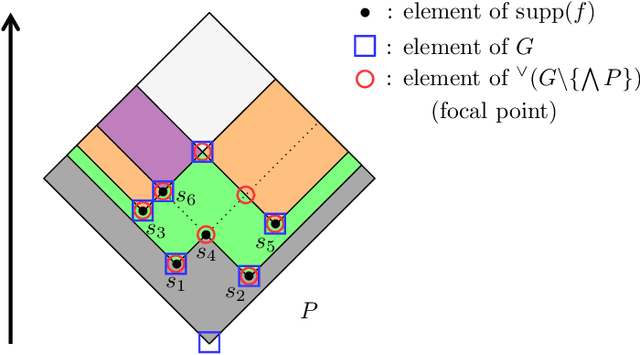
Dempster-Shafer Theory (DST) generalizes Bayesian probability theory, offering useful additional information, but suffers from a much higher computational burden. A lot of work has been done to reduce the time complexity of information fusion with Dempster's rule, which is a pointwise multiplication of two zeta transforms, and optimal general algorithms have been found to get the complete definition of these transforms. Yet, it is shown in this paper that the zeta transform and its inverse, the M\"obius transform, can be exactly simplified, fitting the quantity of information contained in belief functions. Beyond that, this simplification actually works for any function on any partially ordered set. It relies on a new notion that we call focal point and that constitutes the smallest domain on which both the zeta and M\"obius transforms can be defined. We demonstrate the interest of these general results for DST, not only for the reduction in complexity of most transformations between belief representations and their fusion, but also for theoretical purposes. Indeed, we provide a new generalization of the conjunctive decomposition of evidence and formulas uncovering how each decomposition weight is tied to the corresponding mass function.
FracBNN: Accurate and FPGA-Efficient Binary Neural Networks with Fractional Activations
Dec 22, 2020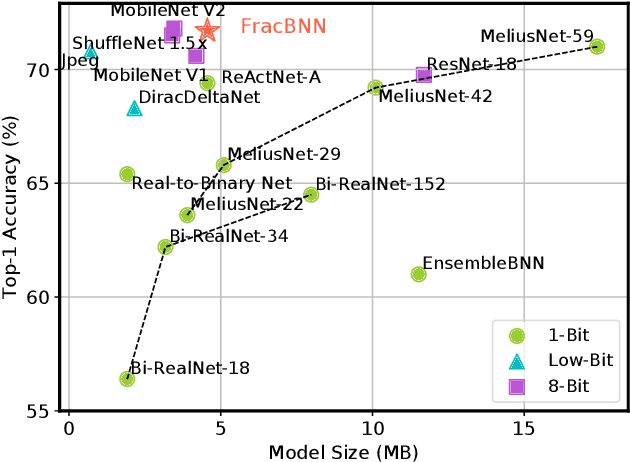

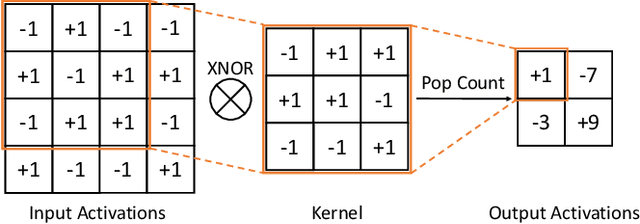
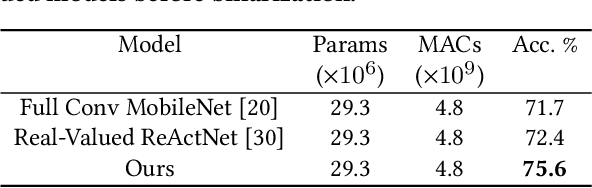
Binary neural networks (BNNs) have 1-bit weights and activations. Such networks are well suited for FPGAs, as their dominant computations are bitwise arithmetic and the memory requirement is also significantly reduced. However, compared to start-of-the-art compact convolutional neural network (CNN) models, BNNs tend to produce a much lower accuracy on realistic datasets such as ImageNet. In addition, the input layer of BNNs has gradually become a major compute bottleneck, because it is conventionally excluded from binarization to avoid a large accuracy loss. This work proposes FracBNN, which exploits fractional activations to substantially improve the accuracy of BNNs. Specifically, our approach employs a dual-precision activation scheme to compute features with up to two bits, using an additional sparse binary convolution. We further binarize the input layer using a novel thermometer encoding. Overall, FracBNN preserves the key benefits of conventional BNNs, where all convolutional layers are computed in pure binary MAC operations (BMACs). We design an efficient FPGA-based accelerator for our novel BNN model that supports the fractional activations. To evaluate the performance of FracBNN under a resource-constrained scenario, we implement the entire optimized network architecture on an embedded FPGA (Xilinx Ultra96v2). Our experiments on ImageNet show that FracBNN achieves an accuracy comparable to MobileNetV2, surpassing the best-known BNN design on FPGAs with an increase of 28.9% in top-1 accuracy and a 2.5x reduction in model size. FracBNN also outperforms a recently introduced BNN model with an increase of 2.4% in top-1 accuracy while using the same model size. On the embedded FPGA device, FracBNN demonstrates the ability of real-time image classification.
Probabilistic Surface Friction Estimation Based on Visual and Haptic Measurements
Oct 16, 2020
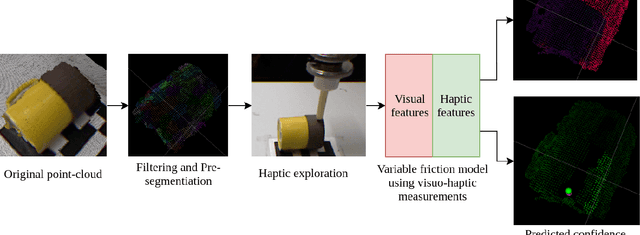

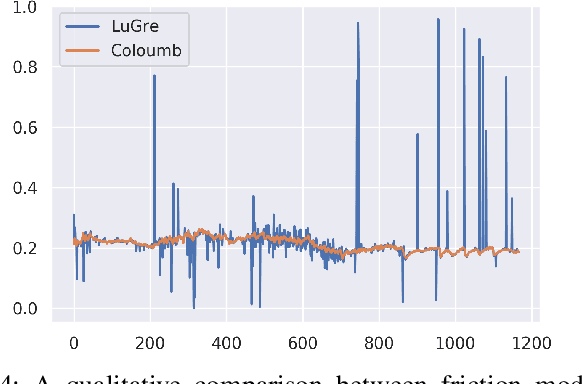
Accurately modeling local surface properties of objects is crucial to many robotic applications, from grasping to material recognition. Surface properties like friction are however difficult to estimate, as visual observation of the object does not convey enough information over these properties. In contrast, haptic exploration is time consuming as it only provides information relevant to the explored parts of the object. In this work, we propose a joint visuo-haptic object model that enables the estimation of surface friction coefficient over an entire object by exploiting the correlation of visual and haptic information, together with a limited haptic exploration by a robotic arm. We demonstrate the validity of the proposed method by showing its ability to estimate varying friction coefficients on a range of real multi-material objects. Furthermore, we illustrate how the estimated friction coefficients can improve grasping success rate by guiding a grasp planner toward high friction areas.
FUEL: Fast UAV Exploration using Incremental Frontier Structure and Hierarchical Planning
Oct 22, 2020


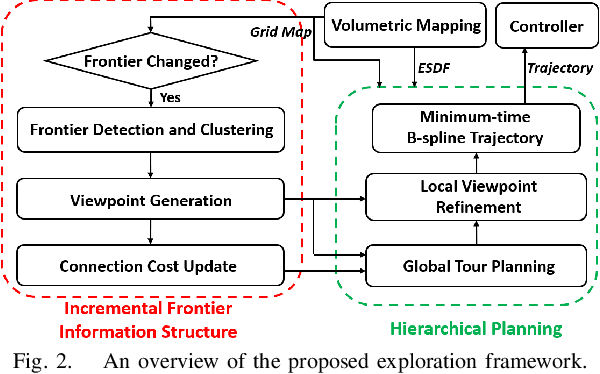
Autonomous exploration is a fundamental problem for various applications of unmanned aerial vehicles. Existing methods, however, were demonstrated to have low efficiency, due to the lack of optimality consideration, conservative motion plans and low decision frequencies. In this paper, we propose FUEL, a hierarchical framework that can support Fast UAV Exploration in complex unknown environments. We maintain crucial information in the entire space required by exploration planning by a frontier information structure (FIS), which can be updated incrementally when the space is explored. Supported by the FIS, a hierarchical planner plan exploration motions in three steps, which find efficient global coverage paths, refine a local set of viewpoints and generate minimum-time trajectories in sequence. We present extensive benchmark and real-world tests, in which our method completes the exploration tasks with unprecedented efficiency (3-8 times faster) compared to state-of-the-art approaches. Our method will be made open source to benefit the community.
Learning a Deep Reinforcement Learning Policy Over the Latent Space of a Pre-trained GAN for Semantic Age Manipulation
Nov 02, 2020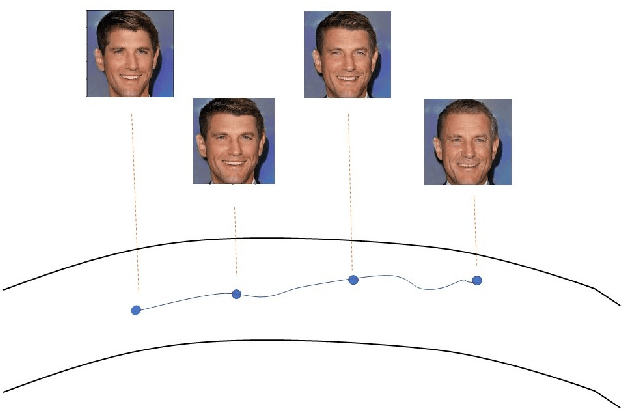


Learning a disentangled representation of the latent space has become one of the most fundamental problems studied in computer vision. Recently, many generative adversarial networks (GANs) have shown promising results in generating high fidelity images. However, studies to understand the semantic layout of the latent space of pre-trained models are still limited. Several works train conditional GANs to generate faces with required semantic attributes. Unfortunately, in these attempts often the generated output is not as photo-realistic as the state of the art models. Besides, they also require large computational resources and specific datasets to generate high fidelity images. In our work, we have formulated a Markov Decision Process (MDP) over the rich latent space of a pre-trained GAN model to learn a conditional policy for semantic manipulation along specific attributes under defined identity bounds. Further, we have defined a semantic age manipulation scheme using a locally linear approximation over the latent space. Results show that our learned policy can sample high fidelity images with required age variations, while at the same time preserve the identity of the person.