 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Strategic Reasoning Evaluation through Behavioral Game Theory
Feb 27, 2025Strategic decision-making involves interactive reasoning where agents adapt their choices in response to others, yet existing evaluations of large language models (LLMs) often emphasize Nash Equilibrium (NE) approximation, overlooking the mechanisms driving their strategic choices. To bridge this gap, we introduce an evaluation framework grounded in behavioral game theory, disentangling reasoning capability from contextual effects. Testing 22 state-of-the-art LLMs, we find that GPT-o3-mini, GPT-o1, and DeepSeek-R1 dominate most games yet also demonstrate that the model scale alone does not determine performance. In terms of prompting enhancement, Chain-of-Thought (CoT) prompting is not universally effective, as it increases strategic reasoning only for models at certain levels while providing limited gains elsewhere. Additionally, we investigate the impact of encoded demographic features on the models, observing that certain assignments impact the decision-making pattern. For instance, GPT-4o shows stronger strategic reasoning with female traits than males, while Gemma assigns higher reasoning levels to heterosexual identities compared to other sexual orientations, indicating inherent biases. These findings underscore the need for ethical standards and contextual alignment to balance improved reasoning with fairness.
Decision-Making Behavior Evaluation Framework for LLMs under Uncertain Context
Jun 10, 2024



When making decisions under uncertainty, individuals often deviate from rational behavior, which can be evaluated across three dimensions: risk preference, probability weighting, and loss aversion. Given the widespread use of large language models (LLMs) in decision-making processes, it is crucial to assess whether their behavior aligns with human norms and ethical expectations or exhibits potential biases. Several empirical studies have investigated the rationality and social behavior performance of LLMs, yet their internal decision-making tendencies and capabilities remain inadequately understood. This paper proposes a framework, grounded in behavioral economics, to evaluate the decision-making behaviors of LLMs. Through a multiple-choice-list experiment, we estimate the degree of risk preference, probability weighting, and loss aversion in a context-free setting for three commercial LLMs: ChatGPT-4.0-Turbo, Claude-3-Opus, and Gemini-1.0-pro. Our results reveal that LLMs generally exhibit patterns similar to humans, such as risk aversion and loss aversion, with a tendency to overweight small probabilities. However, there are significant variations in the degree to which these behaviors are expressed across different LLMs. We also explore their behavior when embedded with socio-demographic features, uncovering significant disparities. For instance, when modeled with attributes of sexual minority groups or physical disabilities, Claude-3-Opus displays increased risk aversion, leading to more conservative choices. These findings underscore the need for careful consideration of the ethical implications and potential biases in deploying LLMs in decision-making scenarios. Therefore, this study advocates for developing standards and guidelines to ensure that LLMs operate within ethical boundaries while enhancing their utility in complex decision-making environments.
HiKonv: Maximizing the Throughput of Quantized Convolution With Novel Bit-wise Management and Computation
Jul 22, 2022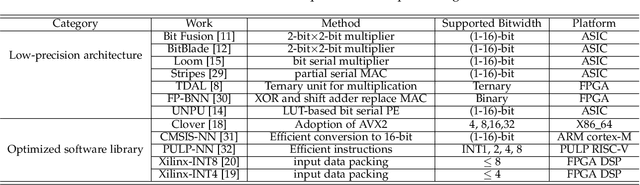
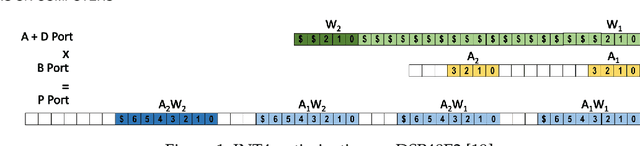
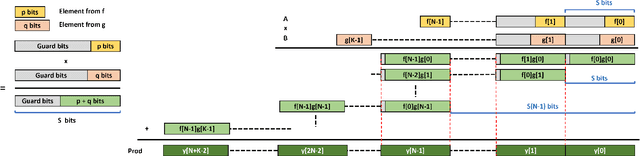
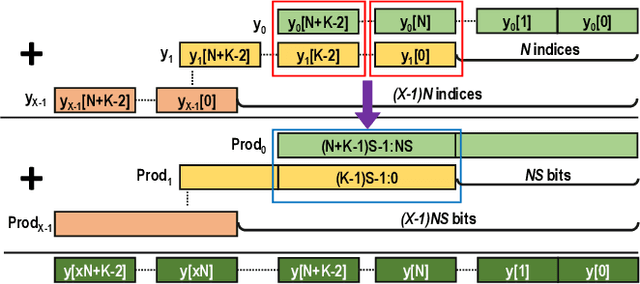
Quantization for CNN has shown significant progress with the intention of reducing the cost of computation and storage with low-bitwidth data representations. There are, however, no systematic studies on how an existing full-bitwidth processing unit, such as ALU in CPUs and DSP in FPGAs, can be better utilized to deliver significantly higher computation throughput for convolution under various quantized bitwidths. In this study, we propose HiKonv, a unified solution that maximizes the throughput of convolution on a given underlying processing unit with low-bitwidth quantized data inputs through novel bit-wise management and parallel computation. We establish theoretical framework and performance models using a full-bitwidth multiplier for highly parallelized low-bitwidth convolution, and demonstrate new breakthroughs for high-performance computing in this critical domain. For example, a single 32-bit processing unit in CPU can deliver 128 binarized convolution operations (multiplications and additions) and 13 4-bit convolution operations with a single multiplication instruction, and a single 27x18 multiplier in the FPGA DSP can deliver 60, 8 or 2 convolution operations with 1, 4 or 8-bit inputs in one clock cycle. We demonstrate the effectiveness of HiKonv on both CPU and FPGA. On CPU, HiKonv outperforms the baseline implementation with 1 to 8-bit inputs and provides up to 7.6x and 1.4x performance improvements for 1-D convolution, and performs 2.74x and 3.19x over the baseline implementation for 4-bit signed and unsigned data inputs for 2-D convolution. On FPGA, HiKonv solution enables a single DSP to process multiple convolutions with a shorter processing latency. For binarized input, each DSP with HiKonv is equivalent up to 76.6 LUTs. Compared to the DAC-SDC 2020 champion model, HiKonv achieves a 2.37x throughput improvement and 2.61x DSP efficiency improvement, respectively.
HiKonv: High Throughput Quantized Convolution With Novel Bit-wise Management and Computation
Dec 28, 2021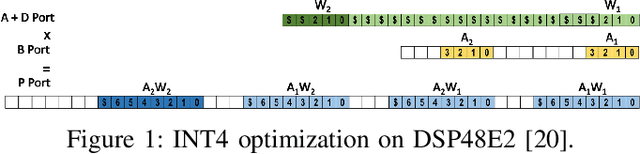
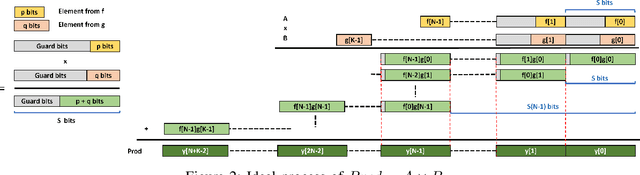

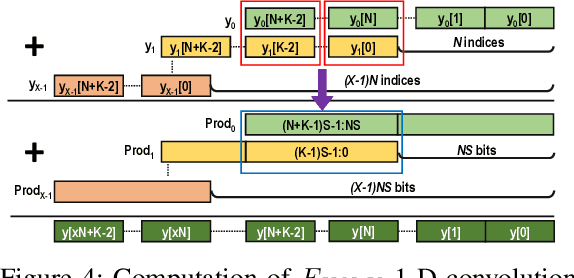
Quantization for Convolutional Neural Network (CNN) has shown significant progress with the intention of reducing the cost of computation and storage with low-bitwidth data inputs. There are, however, no systematic studies on how an existing full-bitwidth processing unit, such as CPUs and DSPs, can be better utilized to carry out significantly higher computation throughput for convolution under various quantized bitwidths. In this study, we propose HiKonv, a unified solution that maximizes the compute throughput of a given underlying processing unit to process low-bitwidth quantized data inputs through novel bit-wise parallel computation. We establish theoretical performance bounds using a full-bitwidth multiplier for highly parallelized low-bitwidth convolution, and demonstrate new breakthroughs for high-performance computing in this critical domain. For example, a single 32-bit processing unit can deliver 128 binarized convolution operations (multiplications and additions) under one CPU instruction, and a single 27x18 DSP core can deliver eight convolution operations with 4-bit inputs in one cycle. We demonstrate the effectiveness of HiKonv on CPU and FPGA for both convolutional layers or a complete DNN model. For a convolutional layer quantized to 4-bit, HiKonv achieves a 3.17x latency improvement over the baseline implementation using C++ on CPU. Compared to the DAC-SDC 2020 champion model for FPGA, HiKonv achieves a 2.37x throughput improvement and 2.61x DSP efficiency improvement, respectively.
FracBNN: Accurate and FPGA-Efficient Binary Neural Networks with Fractional Activations
Dec 22, 2020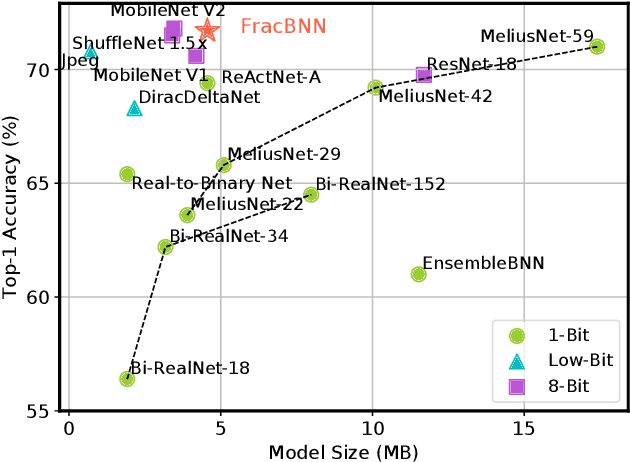

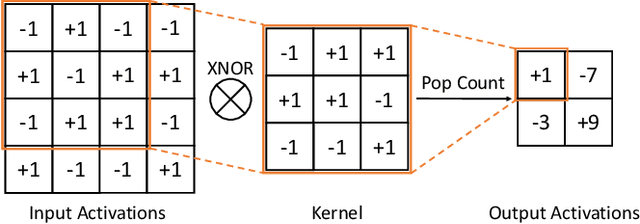
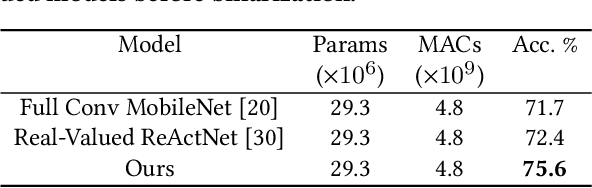
Binary neural networks (BNNs) have 1-bit weights and activations. Such networks are well suited for FPGAs, as their dominant computations are bitwise arithmetic and the memory requirement is also significantly reduced. However, compared to start-of-the-art compact convolutional neural network (CNN) models, BNNs tend to produce a much lower accuracy on realistic datasets such as ImageNet. In addition, the input layer of BNNs has gradually become a major compute bottleneck, because it is conventionally excluded from binarization to avoid a large accuracy loss. This work proposes FracBNN, which exploits fractional activations to substantially improve the accuracy of BNNs. Specifically, our approach employs a dual-precision activation scheme to compute features with up to two bits, using an additional sparse binary convolution. We further binarize the input layer using a novel thermometer encoding. Overall, FracBNN preserves the key benefits of conventional BNNs, where all convolutional layers are computed in pure binary MAC operations (BMACs). We design an efficient FPGA-based accelerator for our novel BNN model that supports the fractional activations. To evaluate the performance of FracBNN under a resource-constrained scenario, we implement the entire optimized network architecture on an embedded FPGA (Xilinx Ultra96v2). Our experiments on ImageNet show that FracBNN achieves an accuracy comparable to MobileNetV2, surpassing the best-known BNN design on FPGAs with an increase of 28.9% in top-1 accuracy and a 2.5x reduction in model size. FracBNN also outperforms a recently introduced BNN model with an increase of 2.4% in top-1 accuracy while using the same model size. On the embedded FPGA device, FracBNN demonstrates the ability of real-time image classification.