 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Text Analytics for Resilience-Enabled Extreme EventsReconnaissance
Nov 26, 2020
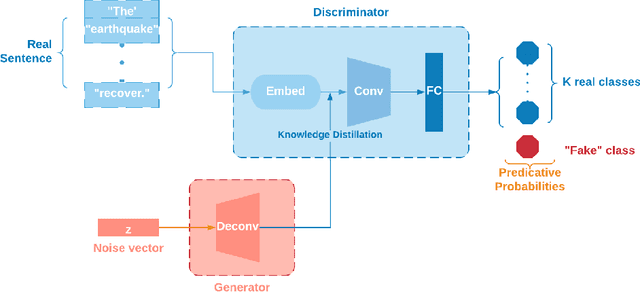
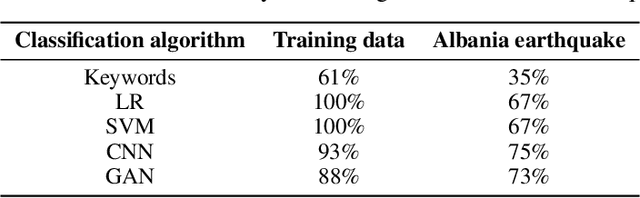
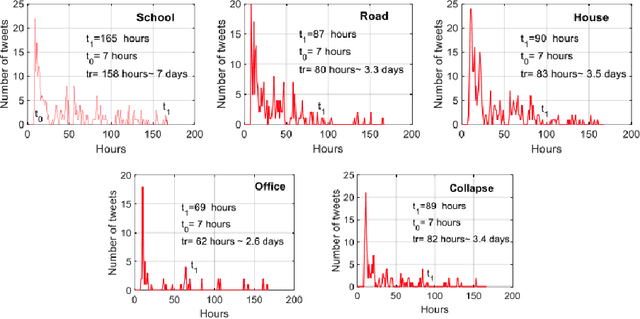

Post-hazard reconnaissance for natural disasters (e.g., earthquakes) is important for understanding the performance of the built environment, speeding up the recovery, enhancing resilience and making informed decisions related to current and future hazards. Natural language processing (NLP) is used in this study for the purposes of increasing the accuracy and efficiency of natural hazard reconnaissance through automation. The study particularly focuses on (1) automated data (news and social media) collection hosted by the Pacific Earthquake Engineering Research (PEER) Center server, (2) automatic generation of reconnaissance reports, and (3) use of social media to extract post-hazard information such as the recovery time. Obtained results are encouraging for further development and wider usage of various NLP methods in natural hazard reconnaissance.
Gaussian RAM: Lightweight Image Classification via Stochastic Retina-Inspired Glimpse and Reinforcement Learning
Nov 12, 2020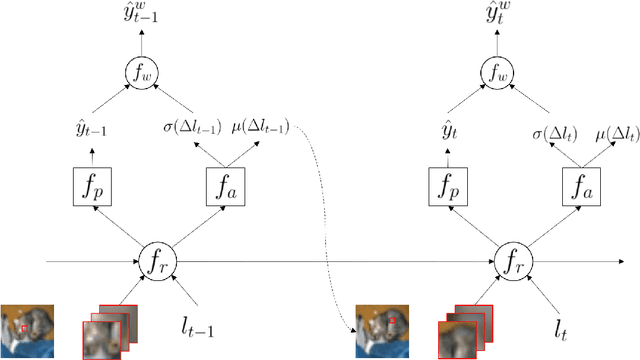


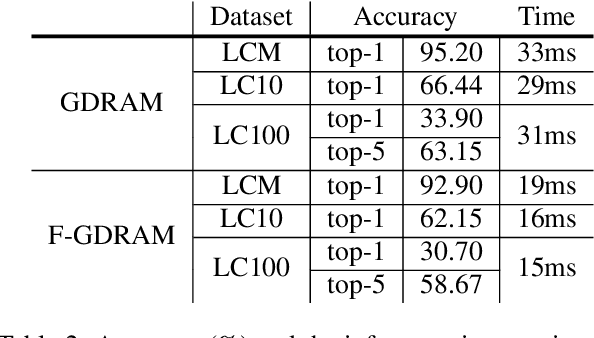
Previous studies on image classification have mainly focused on the performance of the networks, not on real-time operation or model compression. We propose a Gaussian Deep Recurrent visual Attention Model (GDRAM)- a reinforcement learning based lightweight deep neural network for large scale image classification that outperforms the conventional CNN (Convolutional Neural Network) which uses the entire image as input. Highly inspired by the biological visual recognition process, our model mimics the stochastic location of the retina with Gaussian distribution. We evaluate the model on Large cluttered MNIST, Large CIFAR-10 and Large CIFAR-100 datasets which are resized to 128 in both width and height.
Using Feature Alignment can Improve Clean Average Precision and Adversarial Robustness in Object Detection
Dec 08, 2020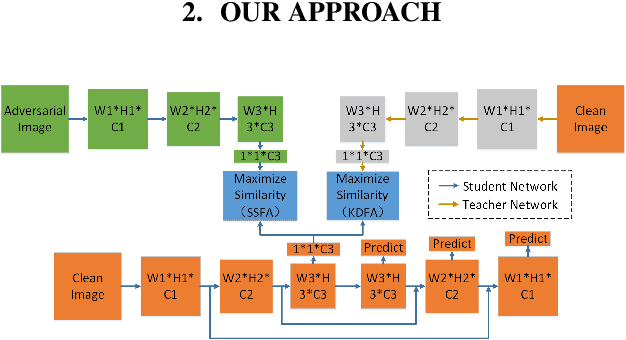
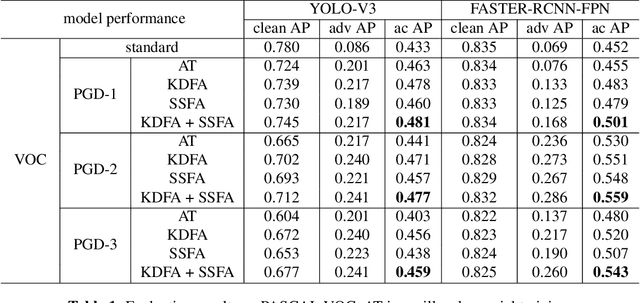
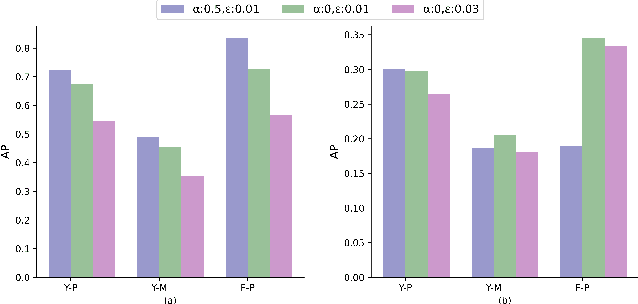
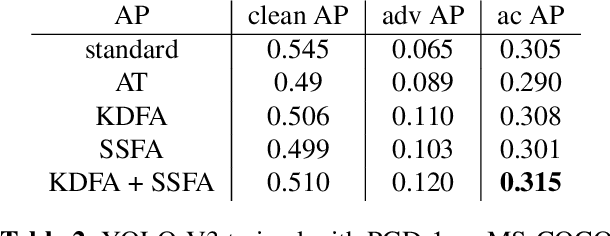
The 2D object detection in clean images has been a well studied topic, but its vulnerability against adversarial attacks is still worrying. Existing work has improved the robustness of object detector by adversarial training, but at the same time, the average precision (AP) on clean images drops significantly. In this paper, we improve object detection algorithm by guiding the output of intermediate feature layer. On the basis of adversarial training, we propose two feature alignment methods, namely Knowledge-Distilled Feature Alignment (KDFA) and Self-Supervised Feature Alignment (SSFA). The detector's clean AP and robustness can be improved by aligning the features of the middle layer of the network. We conduct extensive experiments on PASCAL VOC and MS-COCO datasets to verify the effectiveness of our proposed approach. The code of our experiments is available at https://github.com/grispeut/Feature-Alignment.git.
TrafficSim: Learning to Simulate Realistic Multi-Agent Behaviors
Jan 17, 2021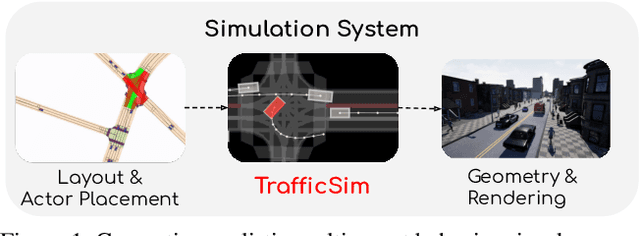
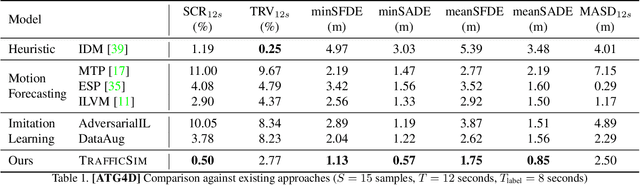

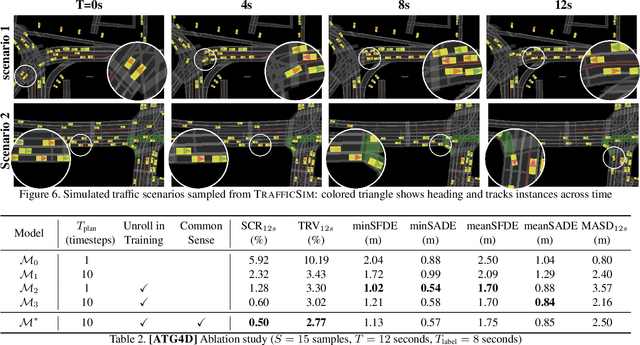
Simulation has the potential to massively scale evaluation of self-driving systems enabling rapid development as well as safe deployment. To close the gap between simulation and the real world, we need to simulate realistic multi-agent behaviors. Existing simulation environments rely on heuristic-based models that directly encode traffic rules, which cannot capture irregular maneuvers (e.g., nudging, U-turns) and complex interactions (e.g., yielding, merging). In contrast, we leverage real-world data to learn directly from human demonstration and thus capture a more diverse set of actor behaviors. To this end, we propose TrafficSim, a multi-agent behavior model for realistic traffic simulation. In particular, we leverage an implicit latent variable model to parameterize a joint actor policy that generates socially-consistent plans for all actors in the scene jointly. To learn a robust policy amenable for long horizon simulation, we unroll the policy in training and optimize through the fully differentiable simulation across time. Our learning objective incorporates both human demonstrations as well as common sense. We show TrafficSim generates significantly more realistic and diverse traffic scenarios as compared to a diverse set of baselines. Notably, we can exploit trajectories generated by TrafficSim as effective data augmentation for training better motion planner.
Control and Navigation Framework for a Hybrid Steel Bridge Inspection Robot
Feb 01, 2021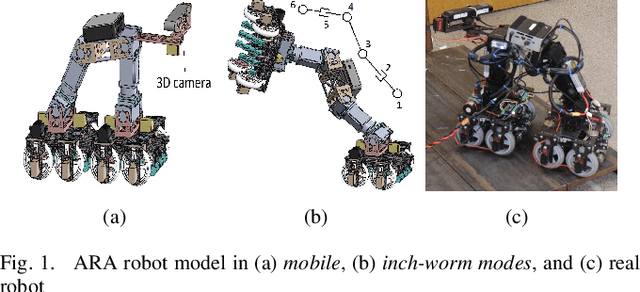

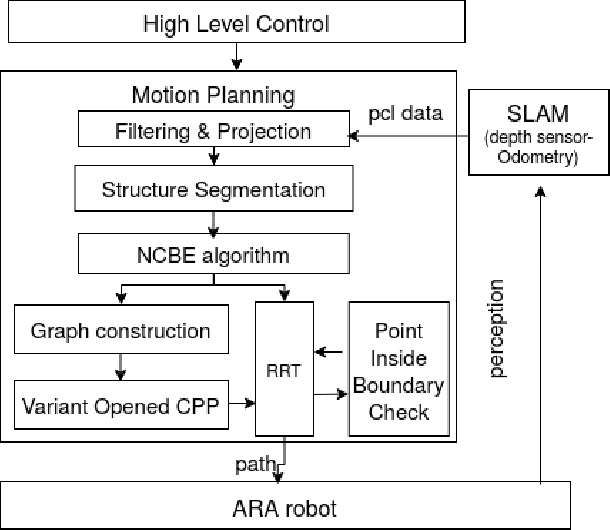
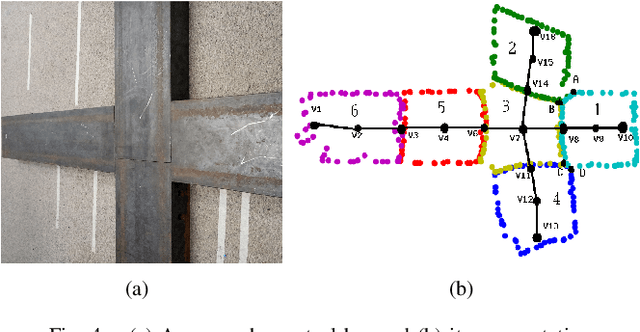
Autonomous navigation of steel bridge inspection robots is essential for proper maintenance. The majority of existing robotic solutions for steel bridge inspection requires human intervention to assist in the control and navigation. In this paper, a control and navigation framework has been proposed for the steel bridge inspection robot developed by the Advanced Robotics and Automation (ARA)to facilitate autonomous real-time navigation and minimize human intervention. The ARA robot is designed to work in two modes: mobile and inch-worm. The robot uses mobile mode when moving on a plane surface and inch-worm mode when jumping from one surface to the other. To allow the ARA robot to switch between mobile and inch-worm modes, a switching controller is developed with 3D point cloud data based. The surface detection algorithm is proposed to allow the robot to check the availability of steel surfaces (plane, area, and height) to determine the transformation from mobile mode to inch-worm one. To have the robot safely navigate and visit all steel members of the bridge, four algorithms are developed to process the data from a depth camera, segment it into clusters, estimate the boundaries, construct a graph representing the structure, generate the shortest inspection path with any starting and ending points, and determine available robot configuration for path planning. Experiments on steel bridge structures setup highlight the effective performance of the algorithms, and the potential to apply to the ARA robot to run on real bridge structures.
Political Posters Identification with Appearance-Text Fusion
Dec 19, 2020
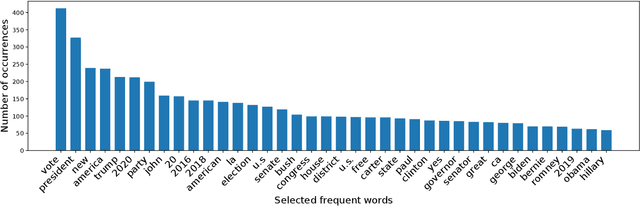

In this paper, we propose a method that efficiently utilizes appearance features and text vectors to accurately classify political posters from other similar political images. The majority of this work focuses on political posters that are designed to serve as a promotion of a certain political event, and the automated identification of which can lead to the generation of detailed statistics and meets the judgment needs in a variety of areas. Starting with a comprehensive keyword list for politicians and political events, we curate for the first time an effective and practical political poster dataset containing 13K human-labeled political images, including 3K political posters that explicitly support a movement or a campaign. Second, we make a thorough case study for this dataset and analyze common patterns and outliers of political posters. Finally, we propose a model that combines the power of both appearance and text information to classify political posters with significantly high accuracy.
Control Barriers in Bayesian Learning of System Dynamics
Dec 29, 2020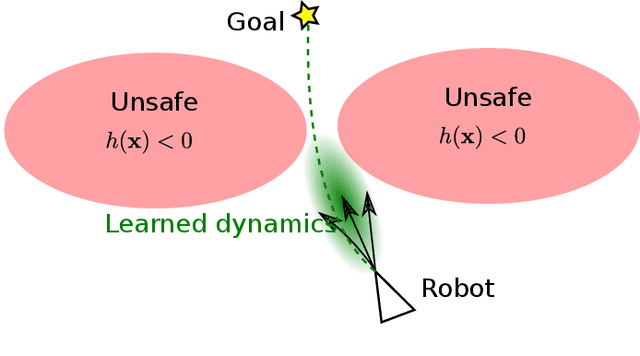
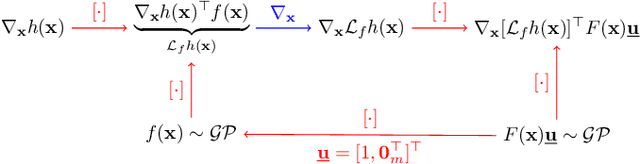
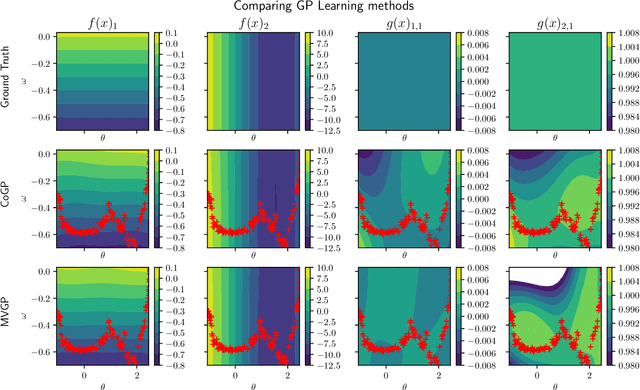
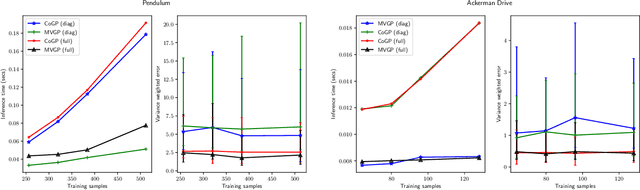
This paper focuses on learning a model of system dynamics online while satisfying safety constraints. Our objective is to avoid offline system identification or hand-specified models and allow a system to safely and autonomously estimate and adapt its own model during operation. Given streaming observations of the system state, we use Bayesian learning to obtain a distribution over the system dynamics. Specifically, we use a matrix variate Gaussian process (MVGP) regression approach with efficient covariance factorization to learn the drift and input gain terms of a nonlinear control-affine system. The MVGP distribution is then used to optimize the system behavior and ensure safety with high probability, by specifying control Lyapunov function (CLF) and control barrier function (CBF) chance constraints. We show that a safe control policy can be synthesized for systems with arbitrary relative degree and probabilistic CLF-CBF constraints by solving a second order cone program (SOCP). Finally, we extend our design to a self-triggering formulation, adaptively determining the time at which a new control input needs to be applied in order to guarantee safety.
Low cost enhanced security face recognition with stereo cameras
Nov 04, 2020

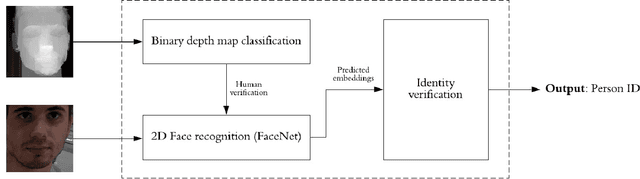
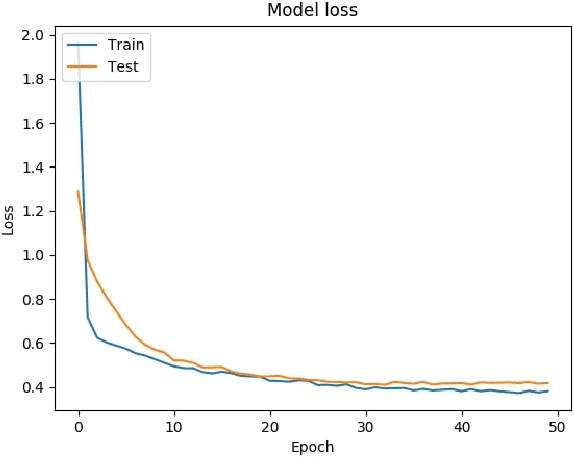
This article explores a face recognition alternative which seeks to contribute to resolve current security vulnerabilities in most recognition architectures. Current low cost facial authentication software in the market can be fooled by a printed picture of a face due to the lack of depth information. The presented software creates a depth map of the face with the help of a stereo setup, offering a higher level of security than traditional recognition programs. Analysis of the person's identity and facial depth map are processed through deep convolutional neural networks, providing a secure low cost real-time face authentication method.
Predicting conversions in display advertising based on URL embeddings
Aug 27, 2020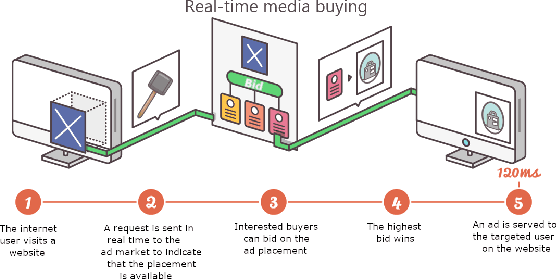
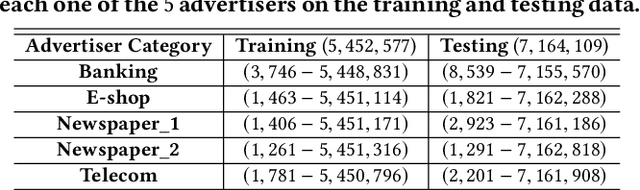
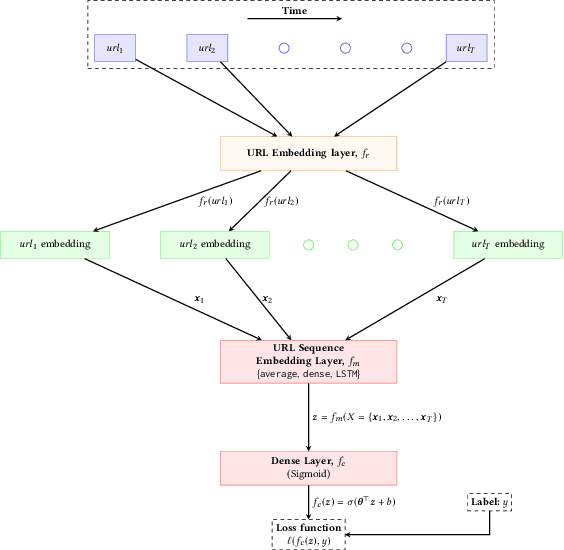
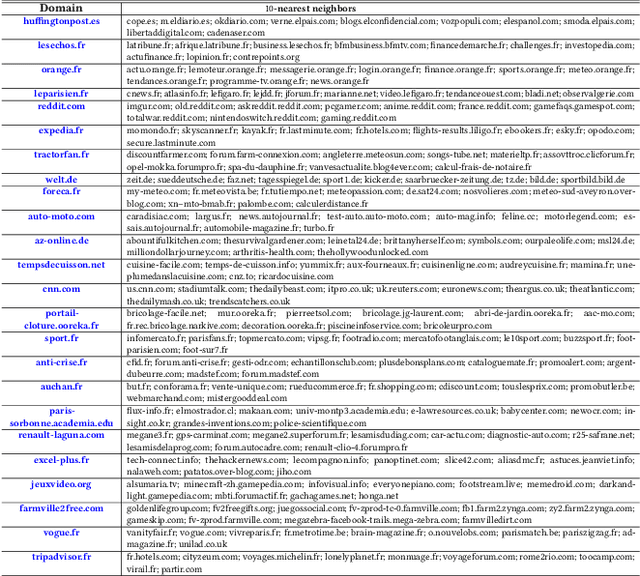
Online display advertising is growing rapidly in recent years thanks to the automation of the ad buying process. Real-time bidding (RTB) allows the automated trading of ad impressions between advertisers and publishers through real-time auctions. In order to increase the effectiveness of their campaigns, advertisers should deliver ads to the users who are highly likely to be converted (i.e., purchase, registration, website visit, etc.) in the near future. In this study, we introduce and examine different models for estimating the probability of a user converting, given their history of visited URLs. Inspired by natural language processing, we introduce three URL embedding models to compute semantically meaningful URL representations. To demonstrate the effectiveness of the different proposed representation and conversion prediction models, we have conducted experiments on real logged events collected from an advertising platform.
Bayesian HMM clustering of x-vector sequences (VBx) in speaker diarization: theory, implementation and analysis on standard tasks
Dec 29, 2020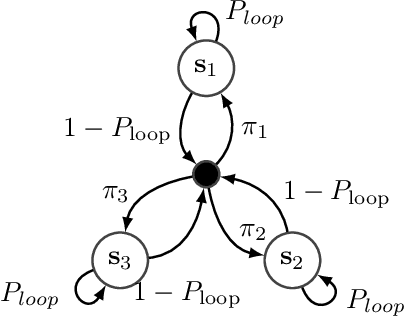
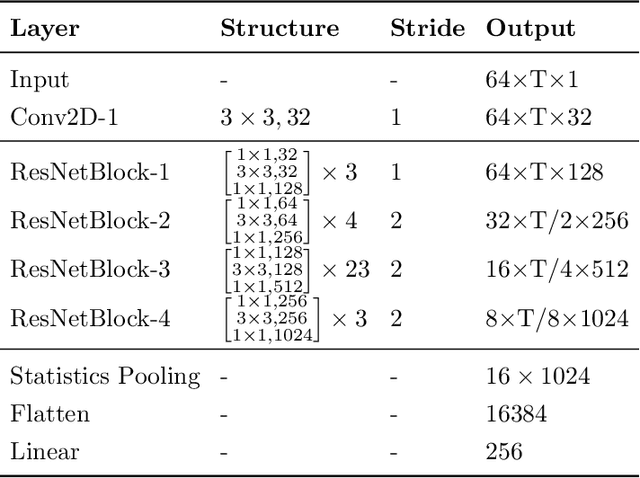
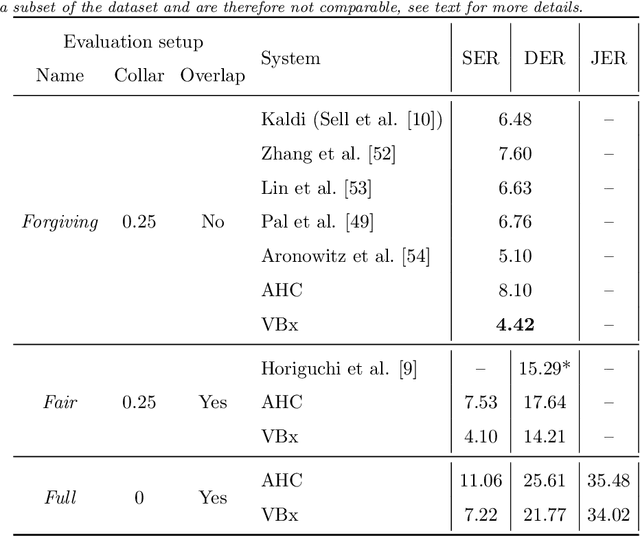
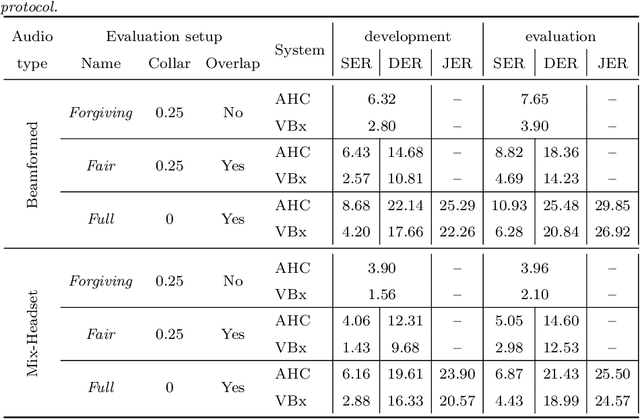
The recently proposed VBx diarization method uses a Bayesian hidden Markov model to find speaker clusters in a sequence of x-vectors. In this work we perform an extensive comparison of performance of the VBx diarization with other approaches in the literature and we show that VBx achieves superior performance on three of the most popular datasets for evaluating diarization: CALLHOME, AMI and DIHARDII datasets. Further, we present for the first time the derivation and update formulae for the VBx model, focusing on the efficiency and simplicity of this model as compared to the previous and more complex BHMM model working on frame-by-frame standard Cepstral features. Together with this publication, we release the recipe for training the x-vector extractors used in our experiments on both wide and narrowband data, and the VBx recipes that attain state-of-the-art performance on all three datasets. Besides, we point out the lack of a standardized evaluation protocol for AMI dataset and we propose a new protocol for both Beamformed and Mix-Headset audios based on the official AMI partitions and transcriptions.