 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Semantic Disentangled Privacy-preserving Speech Representation Learning
May 19, 2025



The use of audio recordings of human speech to train LLMs poses privacy concerns due to these models' potential to generate outputs that closely resemble artifacts in the training data. In this study, we propose a speaker privacy-preserving representation learning method through the Universal Speech Codec (USC), a computationally efficient encoder-decoder model that disentangles speech into: $\textit{(i)}$ privacy-preserving semantically rich representations, capturing content and speech paralinguistics, and $\textit{(ii)}$ residual acoustic and speaker representations that enables high-fidelity reconstruction. Extensive evaluations presented show that USC's semantic representation preserves content, prosody, and sentiment, while removing potentially identifiable speaker attributes. Combining both representations, USC achieves state-of-the-art speech reconstruction. Additionally, we introduce an evaluation methodology for measuring privacy-preserving properties, aligning with perceptual tests. We compare USC against other codecs in the literature and demonstrate its effectiveness on privacy-preserving representation learning, illustrating the trade-offs of speaker anonymization, paralinguistics retention and content preservation in the learned semantic representations. Audio samples are shared in $\href{https://www.amazon.science/usc-samples}{https://www.amazon.science/usc-samples}$.
Lightweight End-to-end Text-to-speech Synthesis for low resource on-device applications
May 12, 2025



Recent works have shown that modelling raw waveform directly from text in an end-to-end (E2E) fashion produces more natural-sounding speech than traditional neural text-to-speech (TTS) systems based on a cascade or two-stage approach. However, current E2E state-of-the-art models are computationally complex and memory-consuming, making them unsuitable for real-time offline on-device applications in low-resource scenarios. To address this issue, we propose a Lightweight E2E-TTS (LE2E) model that generates high-quality speech requiring minimal computational resources. We evaluate the proposed model on the LJSpeech dataset and show that it achieves state-of-the-art performance while being up to $90\%$ smaller in terms of model parameters and $10\times$ faster in real-time-factor. Furthermore, we demonstrate that the proposed E2E training paradigm achieves better quality compared to an equivalent architecture trained in a two-stage approach. Our results suggest that LE2E is a promising approach for developing real-time, high quality, low-resource TTS applications for on-device applications.
* Published as a conference paper at SSW 2023
Low cost enhanced security face recognition with stereo cameras
Nov 04, 2020

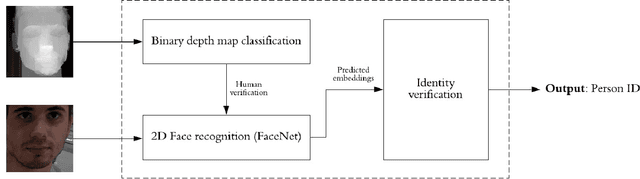
This article explores a face recognition alternative which seeks to contribute to resolve current security vulnerabilities in most recognition architectures. Current low cost facial authentication software in the market can be fooled by a printed picture of a face due to the lack of depth information. The presented software creates a depth map of the face with the help of a stereo setup, offering a higher level of security than traditional recognition programs. Analysis of the person's identity and facial depth map are processed through deep convolutional neural networks, providing a secure low cost real-time face authentication method.