 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Annotation of Chinese Predicate Heads and Relevant Elements
Apr 01, 2021
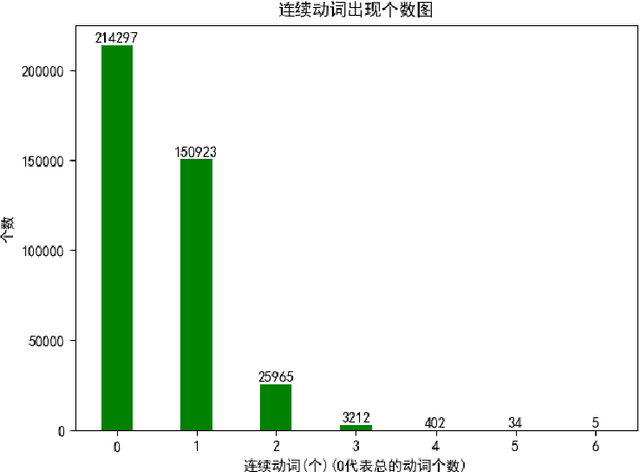
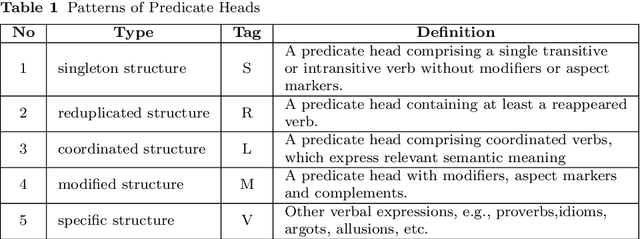
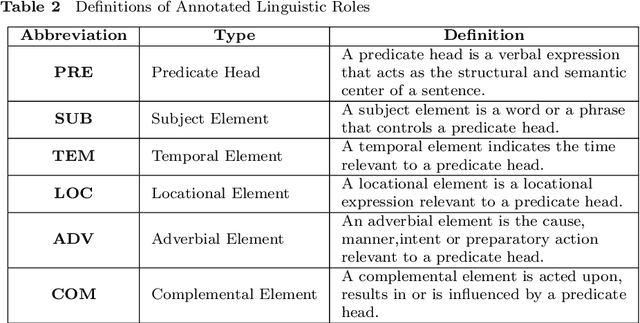
A predicate head is a verbal expression that plays a role as the structural center of a sentence. Identifying predicate heads is critical to understanding a sentence. It plays the leading role in organizing the relevant syntactic elements in a sentence, including subject elements, adverbial elements, etc. For some languages, such as English, word morphologies are valuable for identifying predicate heads. However, Chinese offers no morphological information to indicate words` grammatical roles. A Chinese sentence often contains several verbal expressions; identifying the expression that plays the role of the predicate head is not an easy task. Furthermore, Chinese sentences are inattentive to structure and provide no delimitation between words. Therefore, identifying Chinese predicate heads involves significant challenges. In Chinese information extraction, little work has been performed in predicate head recognition. No generally accepted evaluation dataset supports work in this important area. This paper presents the first attempt to develop an annotation guideline for Chinese predicate heads and their relevant syntactic elements. This annotation guideline emphasizes the role of the predicate as the structural center of a sentence. The design of relevant syntactic element annotation also follows this principle. Many considerations are proposed to achieve this goal, e.g., patterns of predicate heads, a flattened annotation structure, and a simpler syntactic unit type. Based on the proposed annotation guideline, more than 1,500 documents were manually annotated. The corpus will be available online for public access. With this guideline and annotated corpus, our goal is to broadly impact and advance the research in the area of Chinese information extraction and to provide the research community with a critical resource that has been lacking for a long time.
On the Convergence and Optimality of Policy Gradient for Markov Coherent Risk
Mar 05, 2021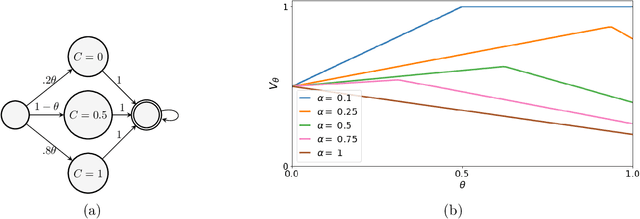

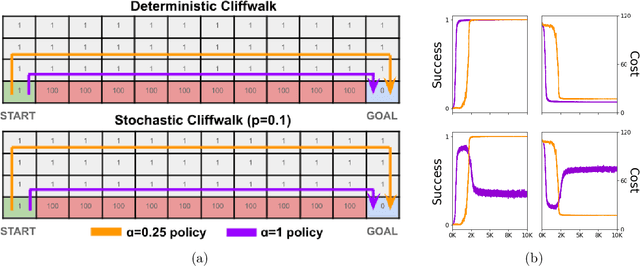
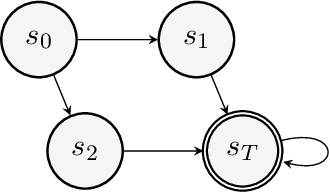
In order to model risk aversion in reinforcement learning, an emerging line of research adapts familiar algorithms to optimize coherent risk functionals, a class that includes conditional value-at-risk (CVaR). Because optimizing the coherent risk is difficult in Markov decision processes, recent work tends to focus on the Markov coherent risk (MCR), a time-consistent surrogate. While, policy gradient (PG) updates have been derived for this objective, it remains unclear (i) whether PG finds a global optimum for MCR; (ii) how to estimate the gradient in a tractable manner. In this paper, we demonstrate that, in general, MCR objectives (unlike the expected return) are not gradient dominated and that stationary points are not, in general, guaranteed to be globally optimal. Moreover, we present a tight upper bound on the suboptimality of the learned policy, characterizing its dependence on the nonlinearity of the objective and the degree of risk aversion. Addressing (ii), we propose a practical implementation of PG that uses state distribution reweighting to overcome previous limitations. Through experiments, we demonstrate that when the optimality gap is small, PG can learn risk-sensitive policies. However, we find that instances with large suboptimality gaps are abundant and easy to construct, outlining an important challenge for future research.
Efficient Near-Field Imaging Using Cylindrical MIMO Arrays
Jan 22, 2021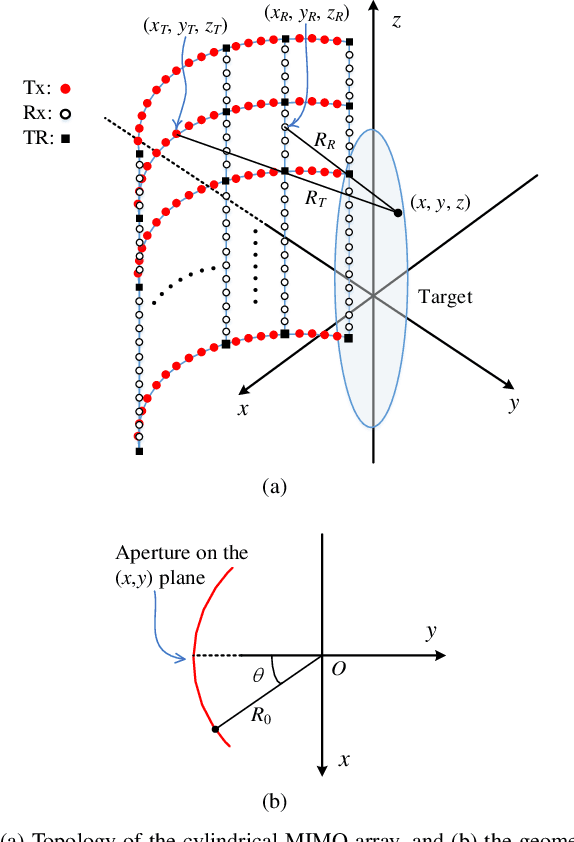
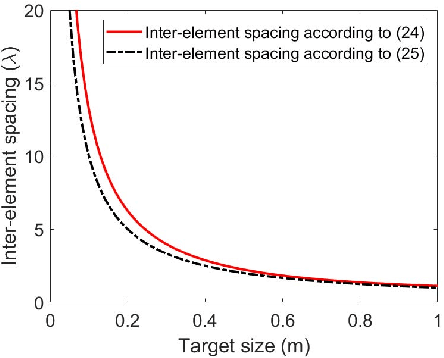
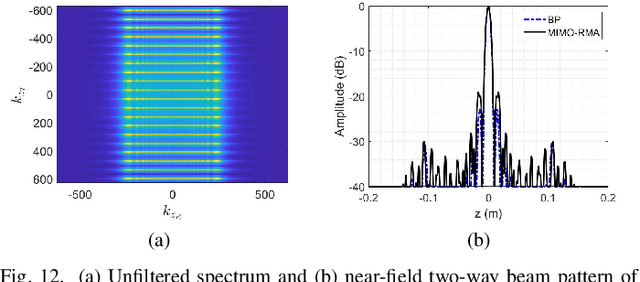
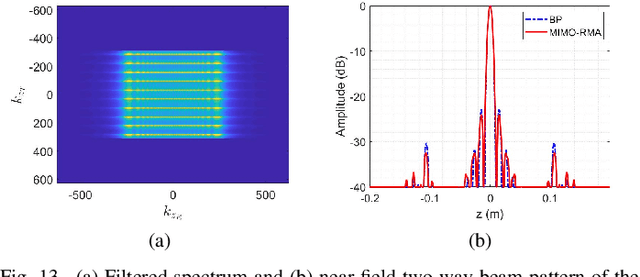
Multiple-input multiple-output (MIMO) array based millimeter-wave (MMW) imaging has a tangible prospect in applications of concealed weapons detection. A near-field imaging algorithm based on wavenumber domain processing is proposed for a cylindrical MIMO array scheme with uniformly spaced transmit and receive antennas over both the vertical and horizontal-arc directions. The spectrum aliasing associated with the proposed MIMO array is analyzed through a zero-filling discrete-time Fourier transform. The analysis shows that an undersampled array can be used in recovering the MMW image by a wavenumber domain algorithm. The requirements for the antenna inter-element spacing of the MIMO array are delineated. Numerical simulations as well as comparisons with the backprojection (BP) algorithm are provided to demonstrate the effectiveness of the proposed method.
AutoFreeze: Automatically Freezing Model Blocks to Accelerate Fine-tuning
Feb 02, 2021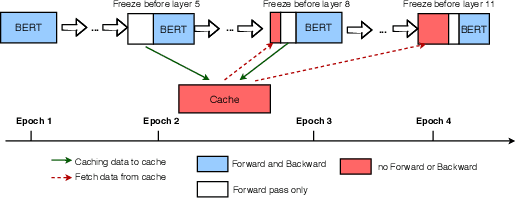
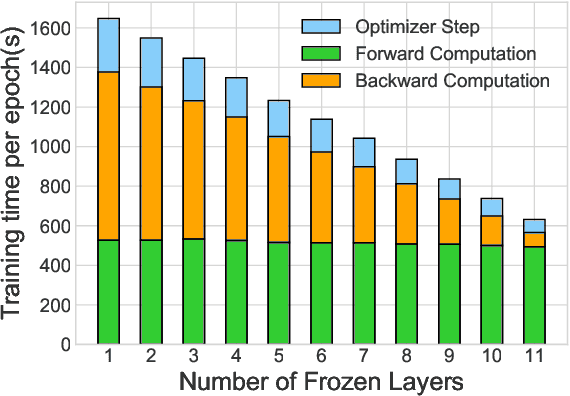
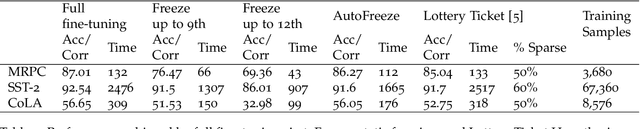
With the rapid adoption of machine learning (ML), a number of domains now use the approach of fine-tuning models pre-trained on a large corpus of data. However, our experiments show that even fine-tuning on models like BERT can take many hours when using GPUs. While prior work proposes limiting the number of layers that are fine-tuned, e.g., freezing all layers but the last layer, we find that such static approaches lead to reduced accuracy. We propose, AutoFreeze, a system that uses an adaptive approach to choose which layers are trained and show how this can accelerate model fine-tuning while preserving accuracy. We also develop mechanisms to enable efficient caching of intermediate activations which can reduce the forward computation time when performing fine-tuning. Our evaluation on fourNLP tasks shows that AutoFreeze, with caching enabled, can improve fine-tuning performance by up to 2.55x.
Fair Robust Assignment using Redundancy
Mar 05, 2021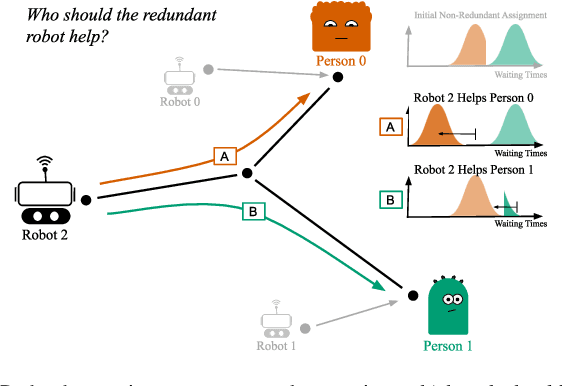
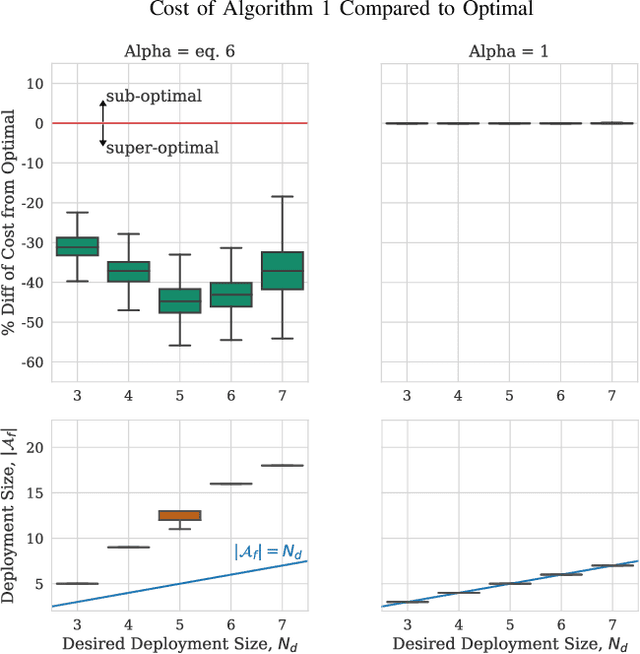
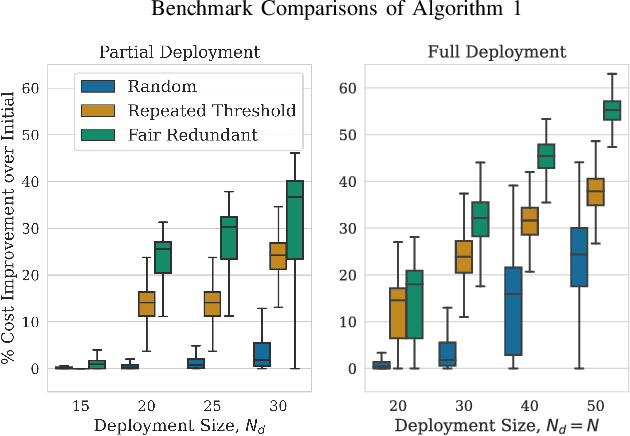
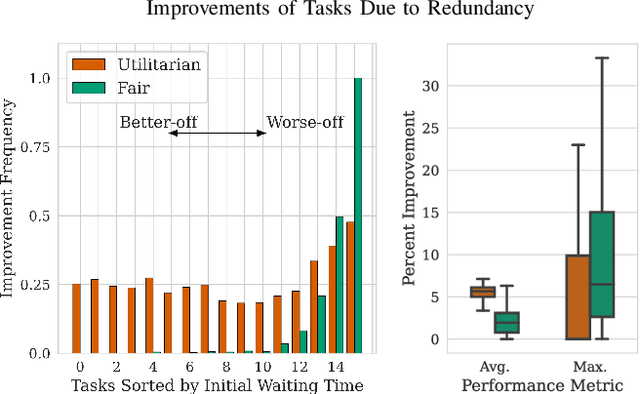
We study the consideration of fairness in redundant assignment for multi-agent task allocation. It has recently been shown that redundant assignment of agents to tasks provides robustness to uncertainty in task performance. However, the question of how to fairly assign these redundant resources across tasks remains unaddressed. In this paper, we present a novel problem formulation for fair redundant task allocation, which we cast as the optimization of worst-case task costs under a cardinality constraint. Solving this problem optimally is NP-hard. We exploit properties of supermodularity to propose a polynomial-time, near-optimal solution. In supermodular redundant assignment, the use of additional agents always improves task costs. Therefore, we provide a solution set that is $\alpha$ times larger than the cardinality constraint. This constraint relaxation enables our approach to achieve a super-optimal cost by using a sub-optimal assignment size. We derive the sub-optimality bound on this cardinality relaxation, $\alpha$. Additionally, we demonstrate that our algorithm performs near-optimally without the cardinality relaxation. We show simulations of redundant assignments of robots to goal nodes on transport networks with uncertain travel times. Empirically, our algorithm outperforms benchmarks, scales to large problems, and provides improvements in both fairness and average utility.
RL-Controller: a reinforcement learning framework for active structural control
Mar 13, 2021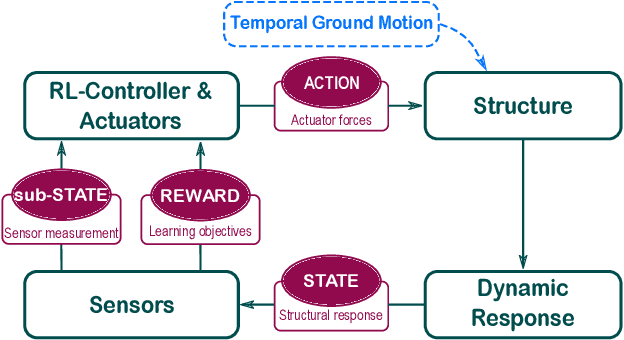
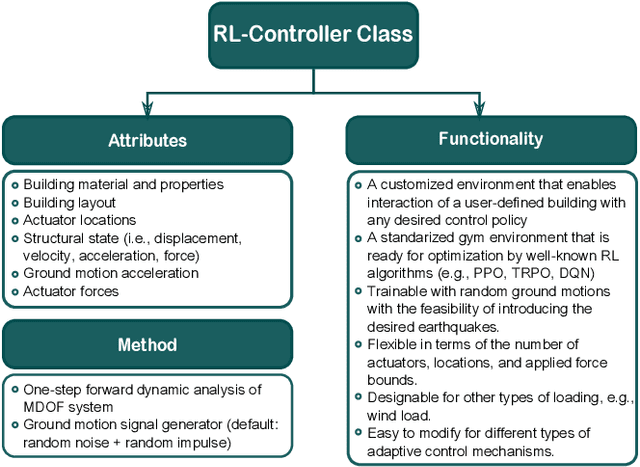
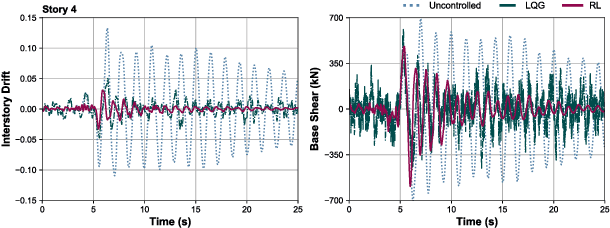
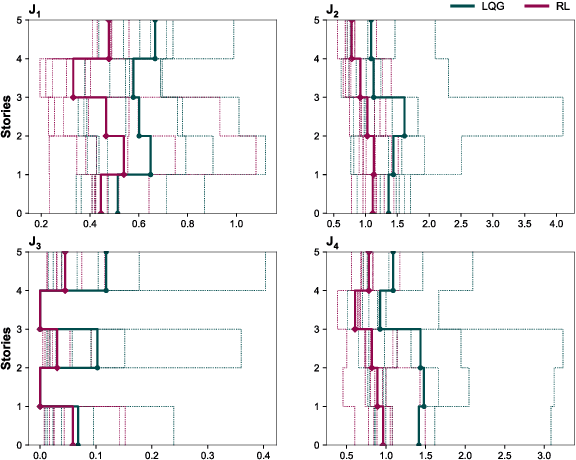
To maintain structural integrity and functionality during the designed life cycle of a structure, engineers are expected to accommodate for natural hazards as well as operational load levels. Active control systems are an efficient solution for structural response control when a structure is subjected to unexpected extreme loads. However, development of these systems through traditional means is limited by their model dependent nature. Recent advancements in adaptive learning methods, in particular, reinforcement learning (RL), for real-time decision making problems, along with rapid growth in high-performance computational resources, help structural engineers to transform the classic model-based active control problem to a purely data-driven one. In this paper, we present a novel RL-based approach for designing active controllers by introducing RL-Controller, a flexible and scalable simulation environment. The RL-Controller includes attributes and functionalities that are defined to model active structural control mechanisms in detail. We show that the proposed framework is easily trainable for a five story benchmark building with 65% reductions on average in inter story drifts (ISD) when subjected to strong ground motions. In a comparative study with LQG active control method, we demonstrate that the proposed model-free algorithm learns more optimal actuator forcing strategies that yield higher performance, e.g., 25% more ISD reductions on average with respect to LQG, without using prior information about the mechanical properties of the system.
Exploratory LQG Mean Field Games with Entropy Regularization
Dec 20, 2020We study a general class of entropy-regularized multi-variate LQG mean field games (MFGs) in continuous time with $K$ distinct sub-population of agents. We extend the notion of actions to action distributions (exploratory actions), and explicitly derive the optimal action distributions for individual agents in the limiting MFG. We demonstrate that the optimal set of action distributions yields an $\epsilon$-Nash equilibrium for the finite-population entropy-regularized MFG. Furthermore, we compare the resulting solutions with those of classical LQG MFGs and establish the equivalence of their existence.
Multimodal dynamics modeling for off-road autonomous vehicles
Nov 23, 2020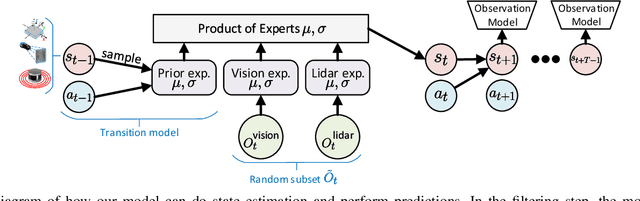

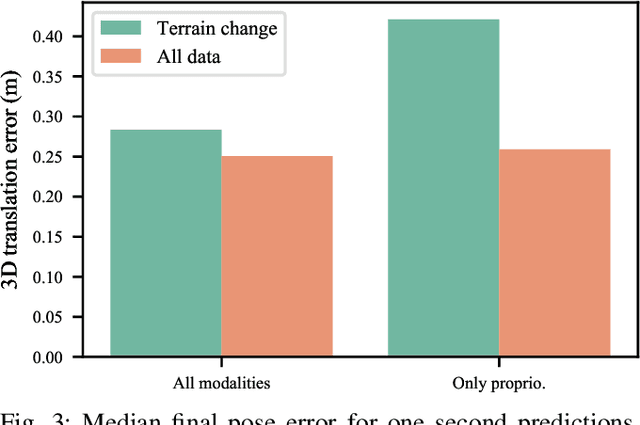

Dynamics modeling in outdoor and unstructured environments is difficult because different elements in the environment interact with the robot in ways that can be hard to predict. Leveraging multiple sensors to perceive maximal information about the robot's environment is thus crucial when building a model to perform predictions about the robot's dynamics with the goal of doing motion planning. We design a model capable of long-horizon motion predictions, leveraging vision, lidar and proprioception, which is robust to arbitrarily missing modalities at test time. We demonstrate in simulation that our model is able to leverage vision to predict traction changes. We then test our model using a real-world challenging dataset of a robot navigating through a forest, performing predictions in trajectories unseen during training. We try different modality combinations at test time and show that, while our model performs best when all modalities are present, it is still able to perform better than the baseline even when receiving only raw vision input and no proprioception, as well as when only receiving proprioception. Overall, our study demonstrates the importance of leveraging multiple sensors when doing dynamics modeling in outdoor conditions.
Anticipating synchronization with machine learning
Mar 13, 2021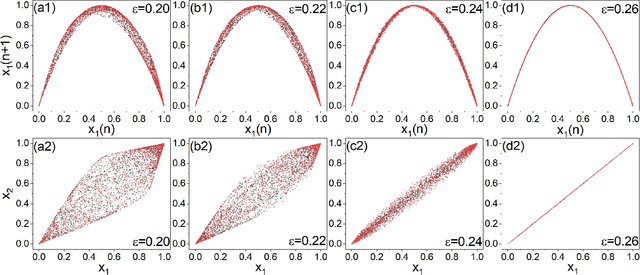
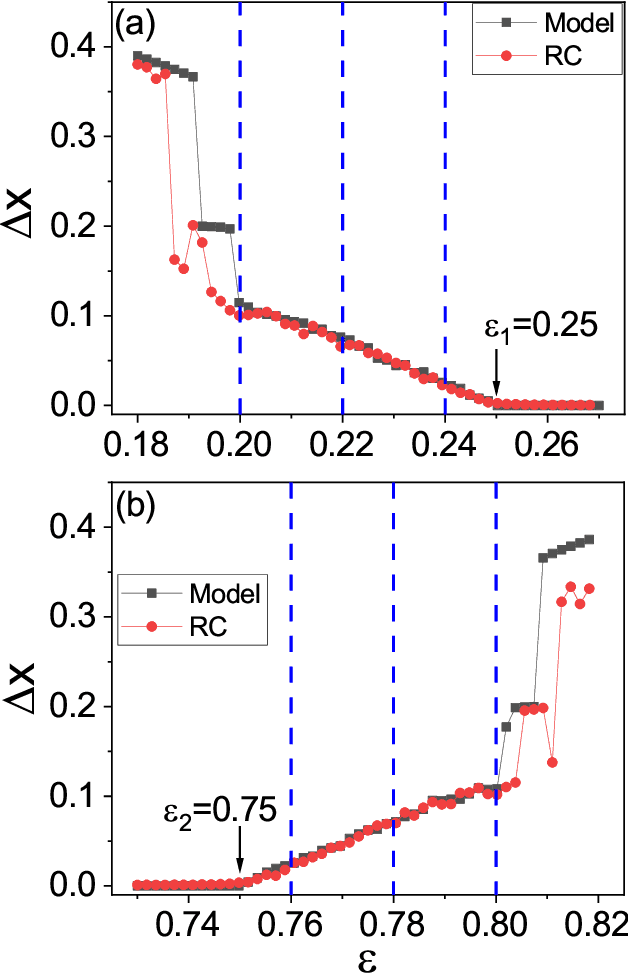
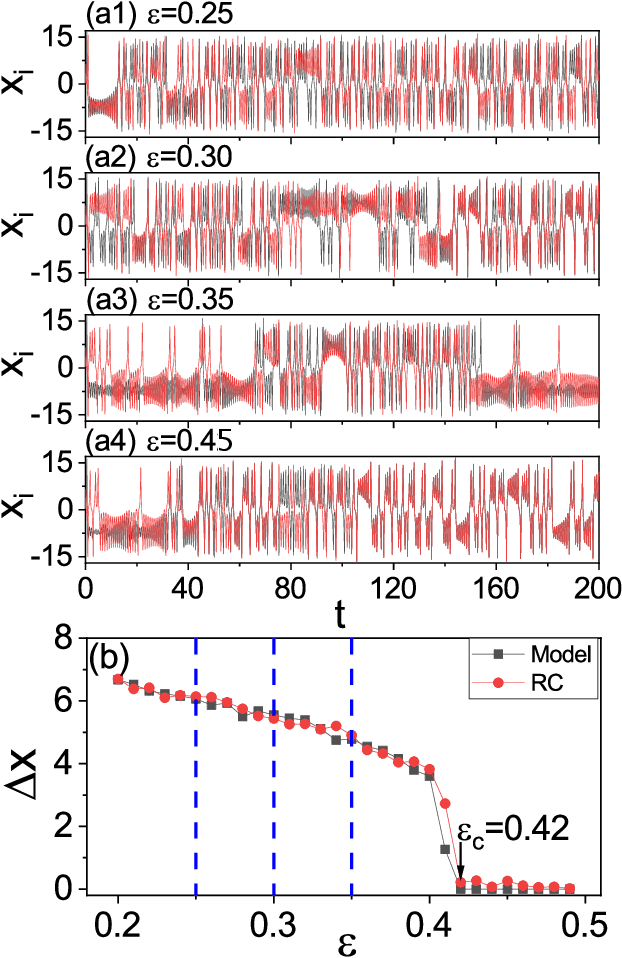
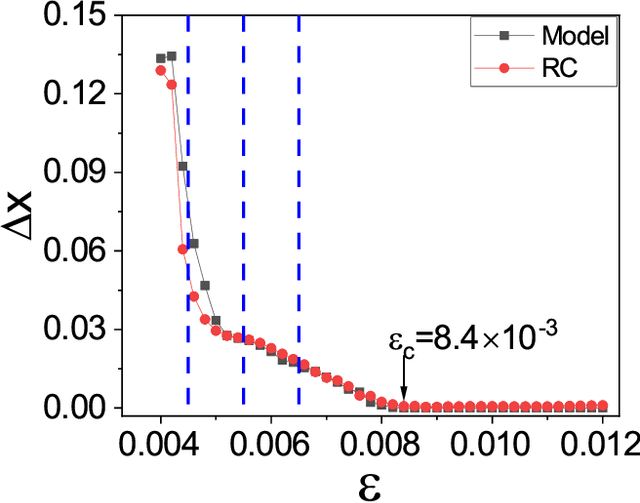
In applications of dynamical systems, situations can arise where it is desired to predict the onset of synchronization as it can lead to characteristic and significant changes in the system performance and behaviors, for better or worse. In experimental and real settings, the system equations are often unknown, raising the need to develop a prediction framework that is model free and fully data driven. We contemplate that this challenging problem can be addressed with machine learning. In particular, exploiting reservoir computing or echo state networks, we devise a "parameter-aware" scheme to train the neural machine using asynchronous time series, i.e., in the parameter regime prior to the onset of synchronization. A properly trained machine will possess the power to predict the synchronization transition in that, with a given amount of parameter drift, whether the system would remain asynchronous or exhibit synchronous dynamics can be accurately anticipated. We demonstrate the machine-learning based framework using representative chaotic models and small network systems that exhibit continuous (second-order) or abrupt (first-order) transitions. A remarkable feature is that, for a network system exhibiting an explosive (first-order) transition and a hysteresis loop in synchronization, the machine learning scheme is capable of accurately predicting these features, including the precise locations of the transition points associated with the forward and backward transition paths.
Automatic Metaphor Interpretation Using Word Embeddings
Oct 06, 2020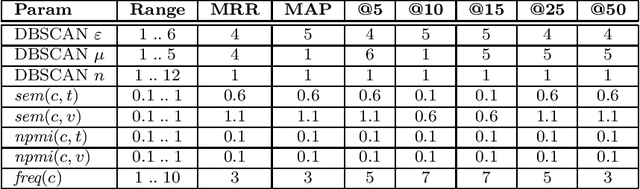
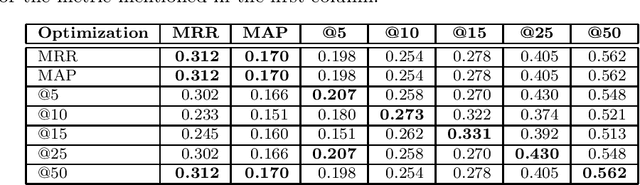


We suggest a model for metaphor interpretation using word embeddings trained over a relatively large corpus. Our system handles nominal metaphors, like "time is money". It generates a ranked list of potential interpretations of given metaphors. Candidate meanings are drawn from collocations of the topic ("time") and vehicle ("money") components, automatically extracted from a dependency-parsed corpus. We explore adding candidates derived from word association norms (common human responses to cues). Our ranking procedure considers similarity between candidate interpretations and metaphor components, measured in a semantic vector space. Lastly, a clustering algorithm removes semantically related duplicates, thereby allowing other candidate interpretations to attain higher rank. We evaluate using a set of annotated metaphors.