 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence and Optimality of Policy Gradient for Markov Coherent Risk
Paper and Code
Mar 05, 2021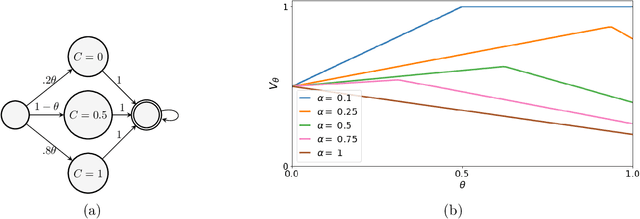

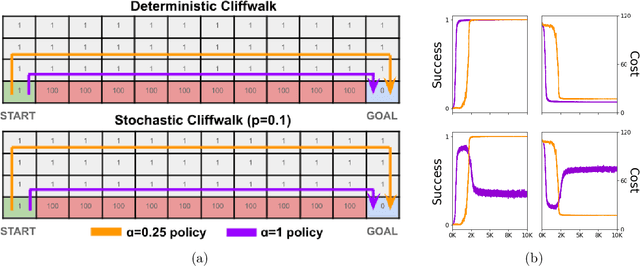
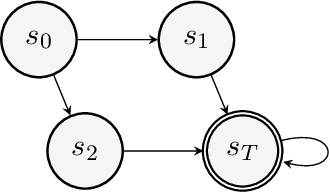
In order to model risk aversion in reinforcement learning, an emerging line of research adapts familiar algorithms to optimize coherent risk functionals, a class that includes conditional value-at-risk (CVaR). Because optimizing the coherent risk is difficult in Markov decision processes, recent work tends to focus on the Markov coherent risk (MCR), a time-consistent surrogate. While, policy gradient (PG) updates have been derived for this objective, it remains unclear (i) whether PG finds a global optimum for MCR; (ii) how to estimate the gradient in a tractable manner. In this paper, we demonstrate that, in general, MCR objectives (unlike the expected return) are not gradient dominated and that stationary points are not, in general, guaranteed to be globally optimal. Moreover, we present a tight upper bound on the suboptimality of the learned policy, characterizing its dependence on the nonlinearity of the objective and the degree of risk aversion. Addressing (ii), we propose a practical implementation of PG that uses state distribution reweighting to overcome previous limitations. Through experiments, we demonstrate that when the optimality gap is small, PG can learn risk-sensitive policies. However, we find that instances with large suboptimality gaps are abundant and easy to construct, outlining an important challenge for future research.