 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Layout Classification in the Wild: A Low-Resource Approach with Layout-Preserving Augmentations
Jun 15, 2026Many digitized corpora suffer from low resources because annotations may be scarce, page scans are noisy and of poor resolution, or layouts are structurally complex in ways that negatively affect the quality of automatic transcription. Developing robust classification models for low-resource languages is inhibited by the lack of large-scale annotated data and by the frequent semantic complexity of page layouts. To this end, we have curated a complex-layout dataset, manually classified into eight distinct layout types based on their separator regions. To overcome data scarcity, we propose a novel training strategy in the form of a CNN-based classifier that employs strong, domain-aware augmentations to improve generalization. We utilize narrow anisotropic Gaussian masking to suppress incidental textual details while preserving essential separations, compelling the model to learn global geometric arrangements. Additionally, we implement reflection-induced label transformations to enrich the training distribution while maintaining label consistency across asymmetric categories. The results demonstrate that layout-specific augmentations can substantially improve page-level layout classification under severe annotation scarcity.
Bag of Bags: Adaptive Visual Vocabularies for Genizah Join Image Retrieval
Apr 09, 2026A join is a set of manuscript fragments identified as originally emanating from the same manuscript. We study manuscript join retrieval: Given a query image of a fragment, retrieve other fragments originating from the same physical manuscript. We propose Bag of Bags (BoB), an image-level representation that replaces the global-level visual codebook of classical Bag of Words (BoW) with a fragment-specific vocabulary of local visual words. Our pipeline trains a sparse convolutional autoencoder on binarized fragment patches, encodes connected components from each page, clusters the resulting embeddings with per image $k$-means, and compares images using set to set distances between their local vocabularies. Evaluated on fragments from the Cairo Genizah, the best BoB variant (viz.\@ Chamfer) achieves Hit@1 of 0.78 and MRR of 0.84, compared to 0.74 and 0.80, respectively, for the strongest BoW baseline (BoW-RawPatches-$χ^2$), a 6.1\% relative improvement in top-1 accuracy. We furthermore study a mass-weighted BoB-OT variant that incorporates cluster population into prototype matching and present a formal approximation guarantee bounding its deviation from full component-level optimal transport. A two-stage pipeline using a BoW shortlist followed by BoB-OT reranking provides a practical compromise between retrieval strength and computational cost, supporting applicability to larger manuscript collections.
Building Patient Journeys in Hebrew: A Language Model for Clinical Timeline Extraction
Dec 12, 2025



We present a new Hebrew medical language model designed to extract structured clinical timelines from electronic health records, enabling the construction of patient journeys. Our model is based on DictaBERT 2.0 and continually pre-trained on over five million de-identified hospital records. To evaluate its effectiveness, we introduce two new datasets -- one from internal medicine and emergency departments, and another from oncology -- annotated for event temporal relations. Our results show that our model achieves strong performance on both datasets. We also find that vocabulary adaptation improves token efficiency and that de-identification does not compromise downstream performance, supporting privacy-conscious model development. The model is made available for research use under ethical restrictions.
Segmentation of Ink and Parchment in Dead Sea Scroll Fragments
Nov 16, 2024



The discovery of the Dead Sea Scrolls over 60 years ago is widely regarded as one of the greatest archaeological breakthroughs in modern history. Recent study of the scrolls presents ongoing computational challenges, including determining the provenance of fragments, clustering fragments based on their degree of similarity, and pairing fragments that originate from the same manuscript -- all tasks that require focusing on individual letter and fragment shapes. This paper presents a computational method for segmenting ink and parchment regions in multispectral images of Dead Sea Scroll fragments. Using the newly developed Qumran Segmentation Dataset (QSD) consisting of 20 fragments, we apply multispectral thresholding to isolate ink and parchment regions based on their unique spectral signatures. To refine segmentation accuracy, we introduce an energy minimization technique that leverages ink contours, which are more distinguishable from the background and less noisy than inner ink regions. Experimental results demonstrate that this Multispectral Thresholding and Energy Minimization (MTEM) method achieves significant improvements over traditional binarization approaches like Otsu and Sauvola in parchment segmentation and is successful at delineating ink borders, in distinction from holes and background regions.
Estimating the Influence of Sequentially Correlated Literary Properties in Textual Classification: A Data-Centric Hypothesis-Testing Approach
Nov 07, 2024



Stylometry aims to distinguish authors by analyzing literary traits assumed to reflect semi-conscious choices distinct from elements like genre or theme. However, these components often overlap, complicating text classification based solely on feature distributions. While some literary properties, such as thematic content, are likely to manifest as correlations between adjacent text units, others, like authorial style, may be independent thereof. We introduce a hypothesis-testing approach to evaluate the influence of sequentially correlated literary properties on text classification, aiming to determine when these correlations drive classification. Using a multivariate binary distribution, our method models sequential correlations between text units as a stochastic process, assessing the likelihood of clustering across varying adjacency scales. This enables us to examine whether classification is dominated by sequentially correlated properties or remains independent. In experiments on a diverse English prose corpus, our analysis integrates traditional and neural embeddings within supervised and unsupervised frameworks. Results demonstrate that our approach effectively identifies when textual classification is not primarily influenced by sequentially correlated literary properties, particularly in cases where texts differ in authorial style or genre rather than by a single author within a similar genre.
Segmenting Dead Sea Scroll Fragments for a Scientific Image Set
Jun 21, 2024



This paper presents a customized pipeline for segmenting manuscript fragments from images curated by the Israel Antiquities Authority (IAA). The images present challenges for standard segmentation methods due to the presence of the ruler, color, and plate number bars, as well as a black background that resembles the ink and varying backing substrates. The proposed pipeline, consisting of four steps, addresses these challenges by isolating and solving each difficulty using custom tailored methods. Further, the usage of a multi-step pipeline will surely be helpful from a conceptual standpoint for other image segmentation projects that encounter problems that have proven intractable when applying any of the more commonly used segmentation techniques. In addition, we create a dataset with bar detection and fragment segmentation ground truth and evaluate the pipeline steps qualitatively and quantitatively on it. This dataset is publicly available to support the development of the field. It aims to address the lack of standard sets of fragment images and evaluation metrics and enable researchers to evaluate their methods in a reliable and reproducible manner.
Domain-Independent Deception: A New Taxonomy and Linguistic Analysis
Feb 01, 2024Internet-based economies and societies are drowning in deceptive attacks. These attacks take many forms, such as fake news, phishing, and job scams, which we call ``domains of deception.'' Machine-learning and natural-language-processing researchers have been attempting to ameliorate this precarious situation by designing domain-specific detectors. Only a few recent works have considered domain-independent deception. We collect these disparate threads of research and investigate domain-independent deception. First, we provide a new computational definition of deception and break down deception into a new taxonomy. Then, we analyze the debate on linguistic cues for deception and supply guidelines for systematic reviews. Finally, we investigate common linguistic features and give evidence for knowledge transfer across different forms of deception.
A Statistical Exploration of Text Partition Into Constituents: The Case of the Priestly Source in the Books of Genesis and Exodus
May 04, 2023We present a pipeline for a statistical textual exploration, offering a stylometry-based explanation and statistical validation of a hypothesized partition of a text. Given a parameterization of the text, our pipeline: (1) detects literary features yielding the optimal overlap between the hypothesized and unsupervised partitions, (2) performs a hypothesis-testing analysis to quantify the statistical significance of the optimal overlap, while conserving implicit correlations between units of text that are more likely to be grouped, and (3) extracts and quantifies the importance of features most responsible for the classification, estimates their statistical stability and cluster-wise abundance. We apply our pipeline to the first two books in the Bible, where one stylistic component stands out in the eyes of biblical scholars, namely, the Priestly component. We identify and explore statistically significant stylistic differences between the Priestly and non-Priestly components.
Style Classification of Rabbinic Literature for Detection of Lost Midrash Tanhuma Material
Nov 17, 2022



Midrash collections are complex rabbinic works that consist of text in multiple languages, which evolved through long processes of unstable oral and written transmission. Determining the origin of a given passage in such a compilation is not always straightforward and is often a matter of dispute among scholars, yet it is essential for scholars' understanding of the passage and its relationship to other texts in the rabbinic corpus. To help solve this problem, we propose a system for classification of rabbinic literature based on its style, leveraging recently released pretrained Transformer models for Hebrew. Additionally, we demonstrate how our method can be applied to uncover lost material from Midrash Tanhuma.
Automatic Metaphor Interpretation Using Word Embeddings
Oct 06, 2020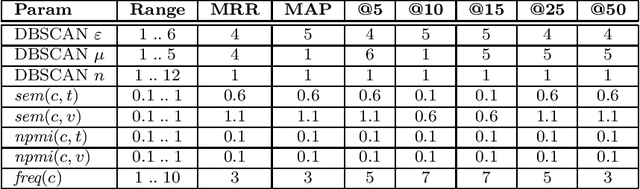
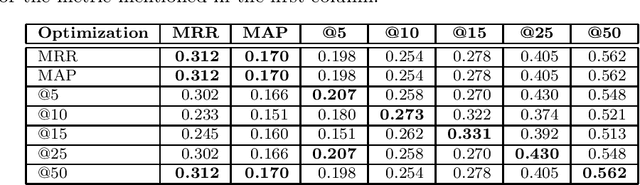


We suggest a model for metaphor interpretation using word embeddings trained over a relatively large corpus. Our system handles nominal metaphors, like "time is money". It generates a ranked list of potential interpretations of given metaphors. Candidate meanings are drawn from collocations of the topic ("time") and vehicle ("money") components, automatically extracted from a dependency-parsed corpus. We explore adding candidates derived from word association norms (common human responses to cues). Our ranking procedure considers similarity between candidate interpretations and metaphor components, measured in a semantic vector space. Lastly, a clustering algorithm removes semantically related duplicates, thereby allowing other candidate interpretations to attain higher rank. We evaluate using a set of annotated metaphors.