 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HyperMorph: Amortized Hyperparameter Learning for Image Registration
Jan 04, 2021
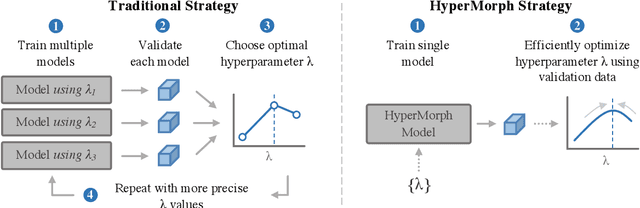

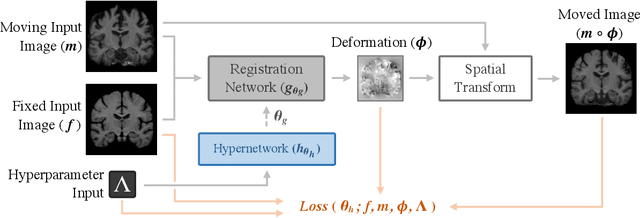
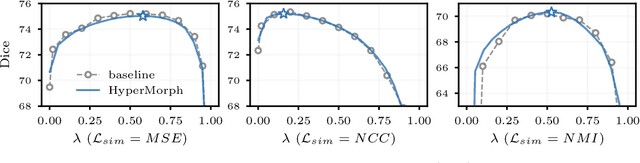
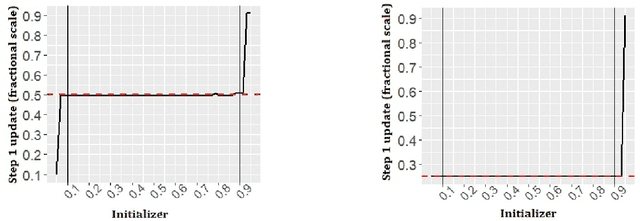
We present HyperMorph, a learning-based strategy for deformable image registration that removes the need to tune important registration hyperparameters during training. Classical registration methods solve an optimization problem to find a set of spatial correspondences between two images, while learning-based methods leverage a training dataset to learn a function that generates these correspondences. The quality of the results for both types of techniques depends greatly on the choice of hyperparameters. Unfortunately, hyperparameter tuning is time-consuming and typically involves training many separate models with various hyperparameter values, potentially leading to suboptimal results. To address this inefficiency, we introduce amortized hyperparameter learning for image registration, a novel strategy to learn the effects of hyperparameters on deformation fields. The proposed framework learns a hypernetwork that takes in an input hyperparameter and modulates a registration network to produce the optimal deformation field for that hyperparameter value. In effect, this strategy trains a single, rich model that enables rapid, fine-grained discovery of hyperparameter values from a continuous interval at test-time. We demonstrate that this approach can be used to optimize multiple hyperparameters considerably faster than existing search strategies, leading to a reduced computational and human burden and increased flexibility. We also show that this has several important benefits, including increased robustness to initialization and the ability to rapidly identify optimal hyperparameter values specific to a registration task, dataset, or even a single anatomical region - all without retraining the HyperMorph model. Our code is publicly available at http://voxelmorph.mit.edu.
Dynamically Switching Human Prediction Models for Efficient Planning
Mar 13, 2021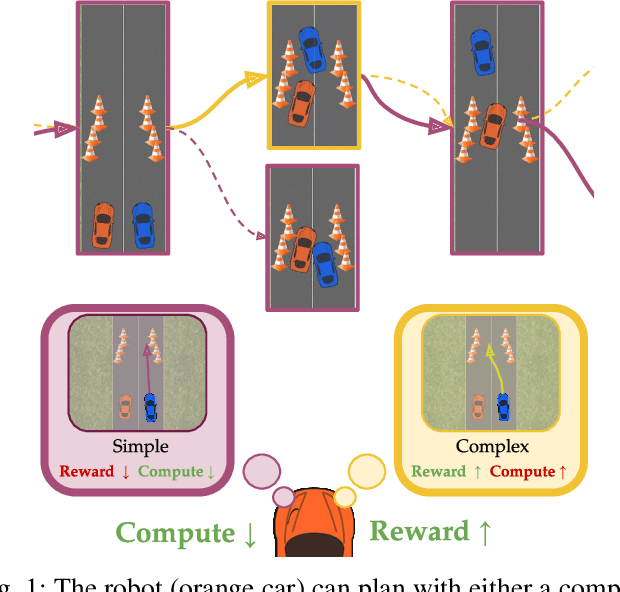
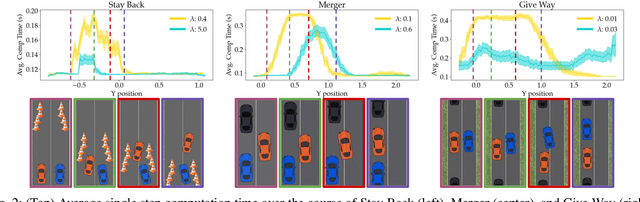
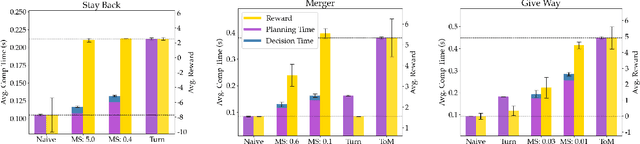
As environments involving both robots and humans become increasingly common, so does the need to account for people during planning. To plan effectively, robots must be able to respond to and sometimes influence what humans do. This requires a human model which predicts future human actions. A simple model may assume the human will continue what they did previously; a more complex one might predict that the human will act optimally, disregarding the robot; whereas an even more complex one might capture the robot's ability to influence the human. These models make different trade-offs between computational time and performance of the resulting robot plan. Using only one model of the human either wastes computational resources or is unable to handle critical situations. In this work, we give the robot access to a suite of human models and enable it to assess the performance-computation trade-off online. By estimating how an alternate model could improve human prediction and how that may translate to performance gain, the robot can dynamically switch human models whenever the additional computation is justified. Our experiments in a driving simulator showcase how the robot can achieve performance comparable to always using the best human model, but with greatly reduced computation.
A Topological Approach for Motion Track Discrimination
Feb 10, 2021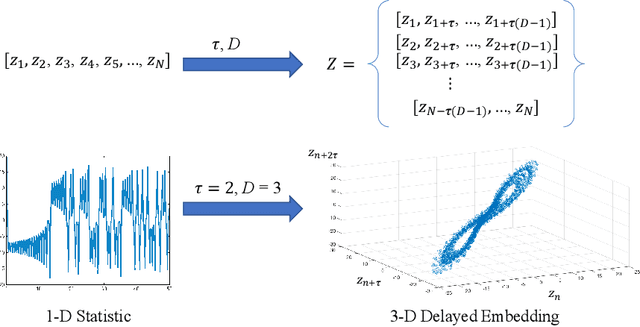
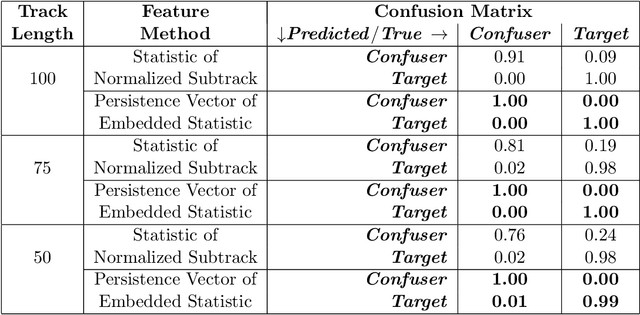
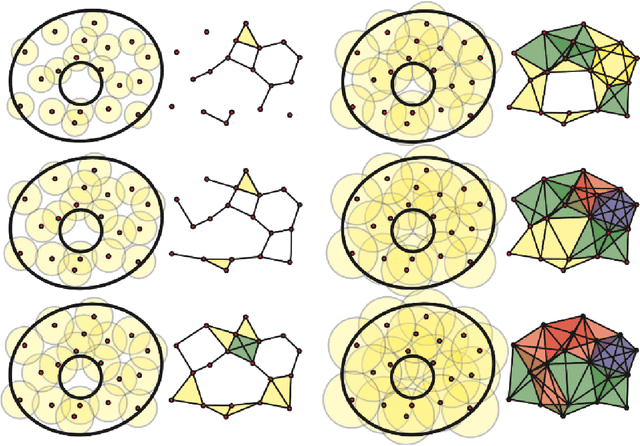
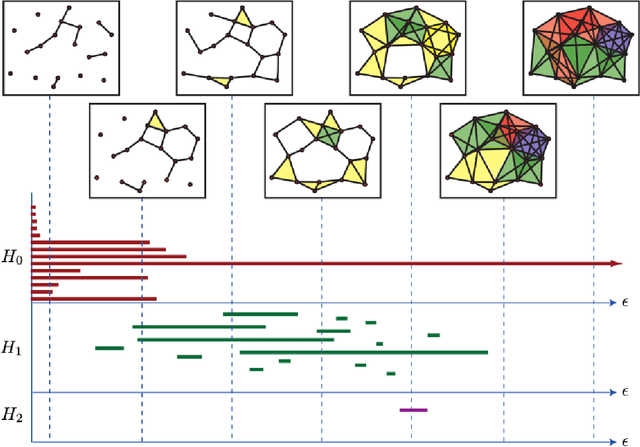
Detecting small targets at range is difficult because there is not enough spatial information present in an image sub-region containing the target to use correlation-based methods to differentiate it from dynamic confusers present in the scene. Moreover, this lack of spatial information also disqualifies the use of most state-of-the-art deep learning image-based classifiers. Here, we use characteristics of target tracks extracted from video sequences as data from which to derive distinguishing topological features that help robustly differentiate targets of interest from confusers. In particular, we calculate persistent homology from time-delayed embeddings of dynamic statistics calculated from motion tracks extracted from a wide field-of-view video stream. In short, we use topological methods to extract features related to target motion dynamics that are useful for classification and disambiguation and show that small targets can be detected at range with high probability.
Combinatorial Bandits under Strategic Manipulations
Feb 25, 2021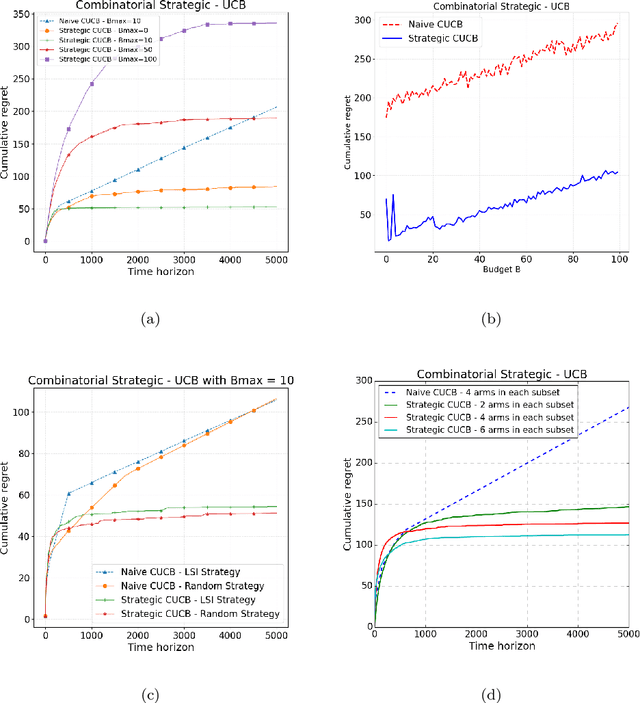
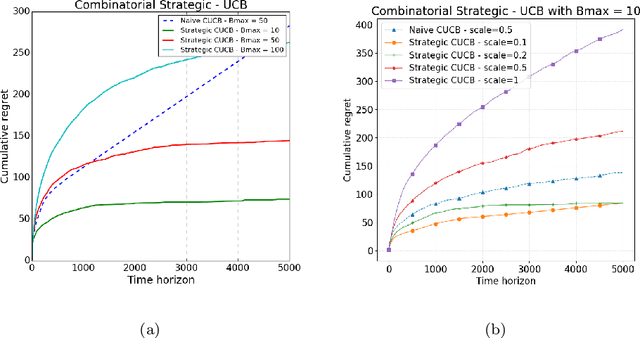
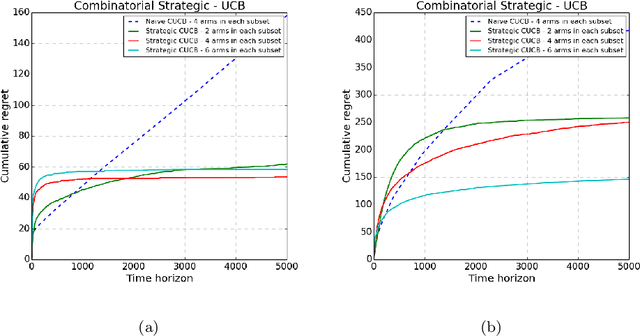
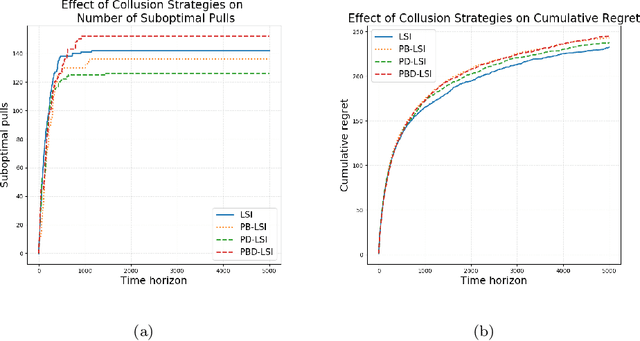
We study the problem of combinatorial multi-armed bandits (CMAB) under strategic manipulations of rewards, where each arm can modify the emitted reward signals for its own interest. Our setting elaborates a more realistic model of adaptive arms that imposes relaxed assumptions compared to adversarial corruptions and adversarial attacks. Algorithms designed under strategic arms gain robustness in real applications while avoiding being overcautious and hampering the performance. We bridge the gap between strategic manipulations and adversarial attacks by investigating the optimal colluding strategy among arms under the MAB problem. We then propose a strategic variant of the combinatorial UCB algorithm, which has a regret of at most $O(m\log T + m B_{max})$ under strategic manipulations, where $T$ is the time horizon, $m$ is the number of arms, and $B_{max}$ is the maximum budget. We further provide lower bounds on the strategic budgets for attackers to incur certain regret of the bandit algorithm. Extensive experiments corroborate our theoretical findings on robustness and regret bounds, in a variety of regimes of manipulation budgets.
Transient Information Adaptation of Artificial Intelligence: Towards Sustainable Data Processes in Complex Projects
Mar 27, 2021Large scale projects increasingly operate in complicated settings whilst drawing on an array of complex data-points, which require precise analysis for accurate control and interventions to mitigate possible project failure. Coupled with a growing tendency to rely on new information systems and processes in change projects, 90% of megaprojects globally fail to achieve their planned objectives. Renewed interest in the concept of Artificial Intelligence (AI) against a backdrop of disruptive technological innovations, seeks to enhance project managers cognitive capacity through the project lifecycle and enhance project excellence. However, despite growing interest there remains limited empirical insights on project managers ability to leverage AI for cognitive load enhancement in complex settings. As such this research adopts an exploratory sequential linear mixed methods approach to address unresolved empirical issues on transient adaptations of AI in complex projects, and the impact on cognitive load enhancement. Initial thematic findings from semi-structured interviews with domain experts, suggest that in order to leverage AI technologies and processes for sustainable cognitive load enhancement with complex data over time, project managers require improved knowledge and access to relevant technologies that mediate data processes in complex projects, but equally reflect application across different project phases. These initial findings support further hypothesis testing through a larger quantitative study incorporating structural equation modelling to examine the relationship between artificial intelligence and project managers cognitive load with project data in complex contexts.
A Context Integrated Relational Spatio-Temporal Model for Demand and Supply Forecasting
Sep 25, 2020
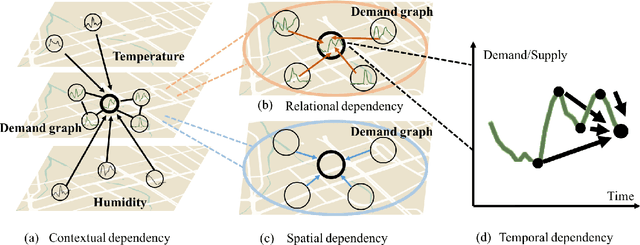

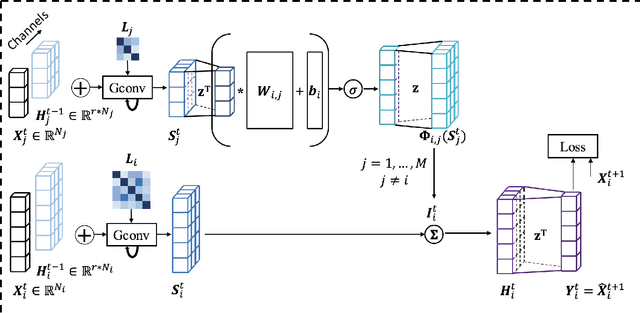
Traditional methods for demand forecasting only focus on modeling the temporal dependency. However, forecasting on spatio-temporal data requires modeling of complex nonlinear relational and spatial dependencies. In addition, dynamic contextual information can have a significant impact on the demand values, and therefore needs to be captured. For example, in a bike-sharing system, bike usage can be impacted by weather. Existing methods assume the contextual impact is fixed. However, we note that the contextual impact evolves over time. We propose a novel context integrated relational model, Context Integrated Graph Neural Network (CIGNN), which leverages the temporal, relational, spatial, and dynamic contextual dependencies for multi-step ahead demand forecasting. Our approach considers the demand network over various geographical locations and represents the network as a graph. We define a demand graph, where nodes represent demand time-series, and context graphs (one for each type of context), where nodes represent contextual time-series. Assuming that various contexts evolve and have a dynamic impact on the fluctuation of demand, our proposed CIGNN model employs a fusion mechanism that jointly learns from all available types of contextual information. To the best of our knowledge, this is the first approach that integrates dynamic contexts with graph neural networks for spatio-temporal demand forecasting, thereby increasing prediction accuracy. We present empirical results on two real-world datasets, demonstrating that CIGNN consistently outperforms state-of-the-art baselines, in both periodic and irregular time-series networks.
A Finite Time Analysis of Temporal Difference Learning With Linear Function Approximation
Nov 06, 2018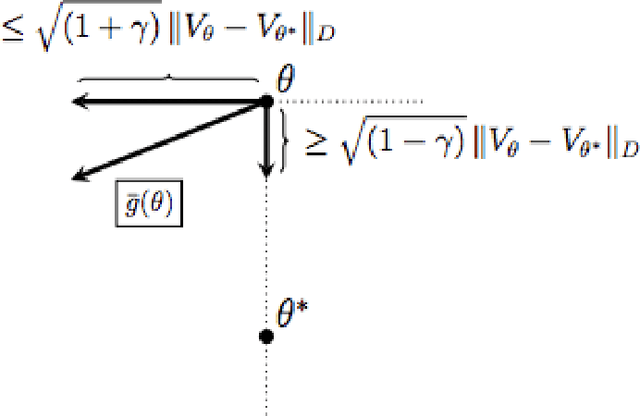
Temporal difference learning (TD) is a simple iterative algorithm used to estimate the value function corresponding to a given policy in a Markov decision process. Although TD is one of the most widely used algorithms in reinforcement learning, its theoretical analysis has proved challenging and few guarantees on its statistical efficiency are available. In this work, we provide a simple and explicit finite time analysis of temporal difference learning with linear function approximation. Except for a few key insights, our analysis mirrors standard techniques for analyzing stochastic gradient descent algorithms, and therefore inherits the simplicity and elegance of that literature. Final sections of the paper show how all of our main results extend to the study of TD learning with eligibility traces, known as TD($\lambda$), and to Q-learning applied in high-dimensional optimal stopping problems.
Inference on the change point in high dimensional time series models via plug in least squares
Jul 11, 2020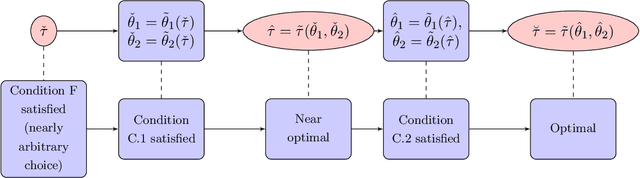
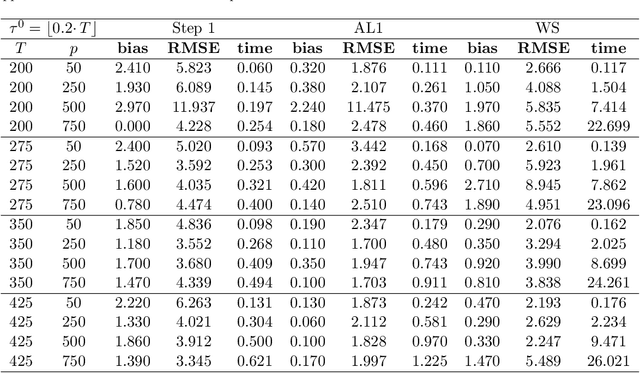
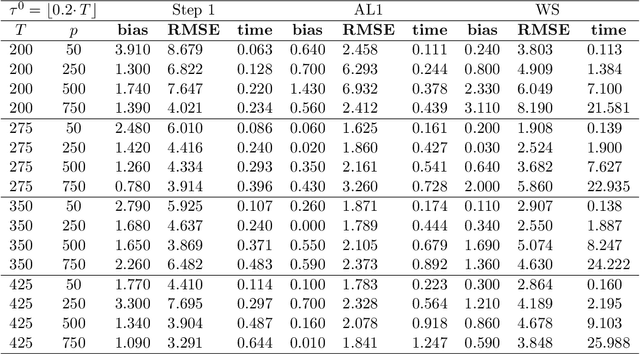
We study a plug in least squares estimator for the change point parameter where change is in the mean of a high dimensional random vector under subgaussian or subexponential distributions. We obtain sufficient conditions under which this estimator possesses sufficient adaptivity against plug in estimates of mean parameters in order to yield an optimal rate of convergence $O_p(\xi^{-2})$ in the integer scale. This rate is preserved while allowing high dimensionality as well as a potentially diminishing jump size $\xi,$ provided $s\log (p\vee T)=o(\surd(Tl_T))$ or $s\log^{3/2}(p\vee T)=o(\surd(Tl_T))$ in the subgaussian and subexponential cases, respectively. Here $s,p,T$ and $l_T$ represent a sparsity parameter, model dimension, sampling period and the separation of the change point from its parametric boundary. Moreover, since the rate of convergence is free of $s,p$ and logarithmic terms of $T,$ it allows the existence of limiting distributions. These distributions are then derived as the {\it argmax} of a two sided negative drift Brownian motion or a two sided negative drift random walk under vanishing and non-vanishing jump size regimes, respectively. Thereby allowing inference of the change point parameter in the high dimensional setting. Feasible algorithms for implementation of the proposed methodology are provided. Theoretical results are supported with monte-carlo simulations.
A Hybrid Pricing and Cutting Approach for the Multi-Shift Full Truckload Vehicle Routing Problem
Dec 03, 2020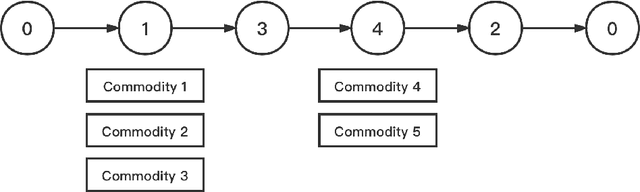

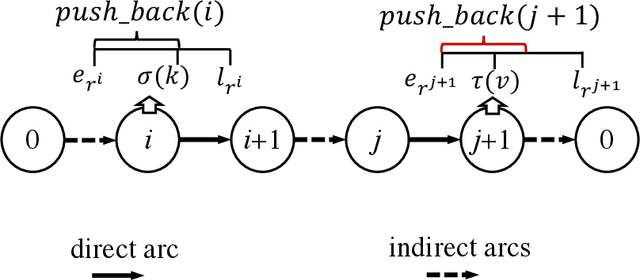
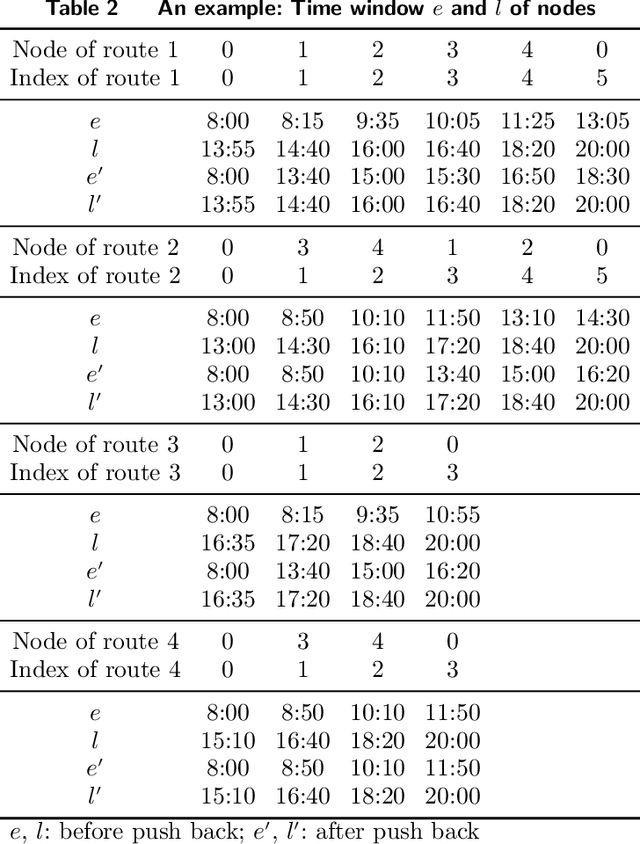
Full truckload transportation (FTL) in the form of freight containers represents one of the most important transportation modes in international trade. Due to large volume and scale, in FTL, delivery time is often less critical but cost and service quality are crucial. Therefore, efficiently solving large scale multiple shift FTL problems is becoming more and more important and requires further research. In one of our earlier studies, a set covering model and a three-stage solution method were developed for a multi-shift FTL problem. This paper extends the previous work and presents a significantly more efficient approach by hybridising pricing and cutting strategies with metaheuristics (a variable neighbourhood search and a genetic algorithm). The metaheuristics were adopted to find promising columns (vehicle routes) guided by pricing and cuts are dynamically generated to eliminate infeasible flow assignments caused by incompatible commodities. Computational experiments on real-life and artificial benchmark FTL problems showed superior performance both in terms of computational time and solution quality, when compared with previous MIP based three-stage methods and two existing metaheuristics. The proposed cutting and heuristic pricing approach can efficiently solve large scale real-life FTL problems.
Learning Optimal Fronthauling and Decentralized Edge Computation in Fog Radio Access Networks
Mar 21, 2021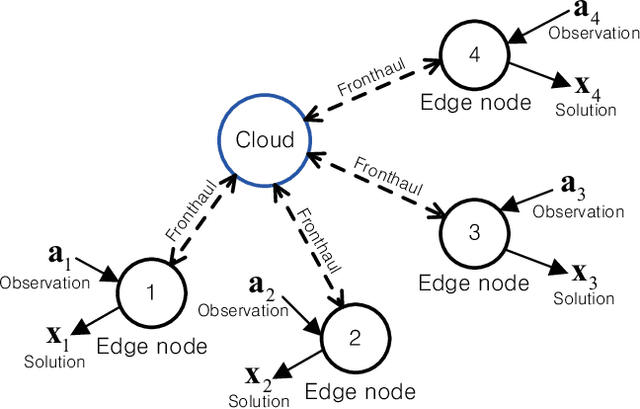
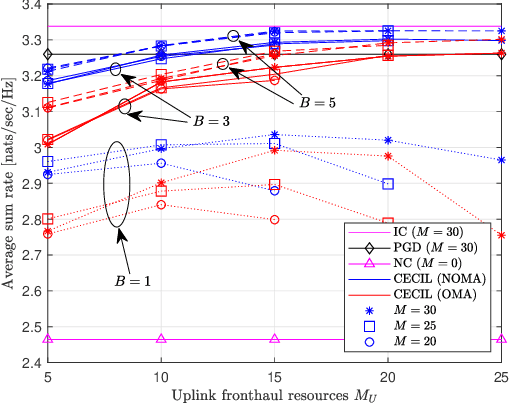
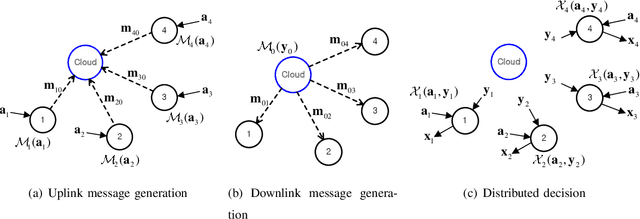
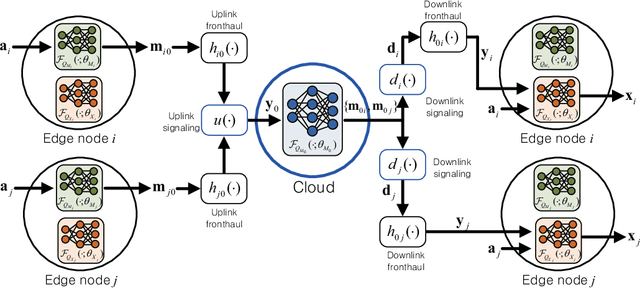
Fog radio access networks (F-RANs), which consist of a cloud and multiple edge nodes (ENs) connected via fronthaul links, have been regarded as promising network architectures. The F-RAN entails a joint optimization of cloud and edge computing as well as fronthaul interactions, which is challenging for traditional optimization techniques. This paper proposes a Cloud-Enabled Cooperation-Inspired Learning (CECIL) framework, a structural deep learning mechanism for handling a generic F-RAN optimization problem. The proposed solution mimics cloud-aided cooperative optimization policies by including centralized computing at the cloud, distributed decision at the ENs, and their uplink-downlink fronthaul interactions. A group of deep neural networks (DNNs) are employed for characterizing computations of the cloud and ENs. The forwardpass of the DNNs is carefully designed such that the impacts of the practical fronthaul links, such as channel noise and signling overheads, can be included in a training step. As a result, operations of the cloud and ENs can be jointly trained in an end-to-end manner, whereas their real-time inferences are carried out in a decentralized manner by means of the fronthaul coordination. To facilitate fronthaul cooperation among multiple ENs, the optimal fronthaul multiple access schemes are designed. Training algorithms robust to practical fronthaul impairments are also presented. Numerical results validate the effectiveness of the proposed approaches.