 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Graph Modeling of Simultaneous EEG and Eye-tracking Data for Reading Task Identification
Feb 21, 2021
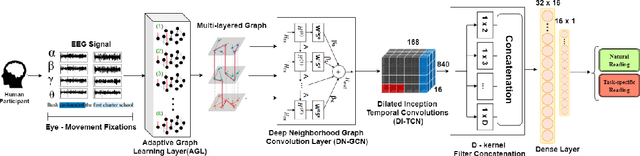
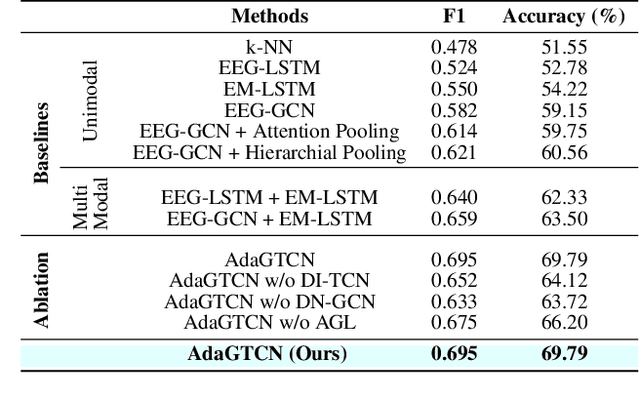
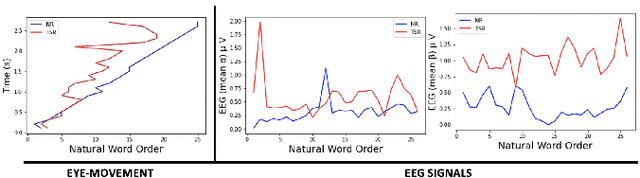
We present a new approach, that we call AdaGTCN, for identifying human reader intent from Electroencephalogram~(EEG) and Eye movement~(EM) data in order to help differentiate between normal reading and task-oriented reading. Understanding the physiological aspects of the reading process~(the cognitive load and the reading intent) can help improve the quality of crowd-sourced annotated data. Our method, Adaptive Graph Temporal Convolution Network (AdaGTCN), uses an Adaptive Graph Learning Layer and Deep Neighborhood Graph Convolution Layer for identifying the reading activities using time-locked EEG sequences recorded during word-level eye-movement fixations. Adaptive Graph Learning Layer dynamically learns the spatial correlations between the EEG electrode signals while the Deep Neighborhood Graph Convolution Layer exploits temporal features from a dense graph neighborhood to establish the state of the art in reading task identification over other contemporary approaches. We compare our approach with several baselines to report an improvement of 6.29% on the ZuCo 2.0 dataset, along with extensive ablation experiments
Provably Approximated ICP
Jan 10, 2021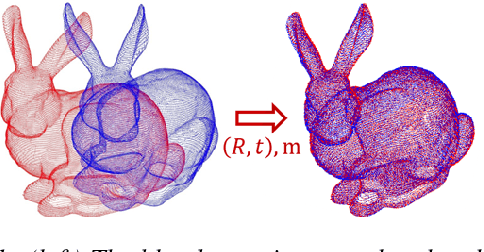
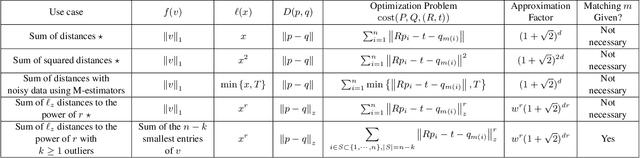
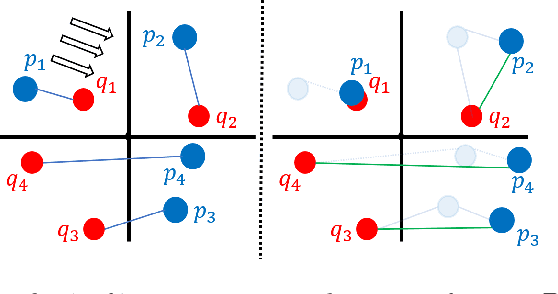
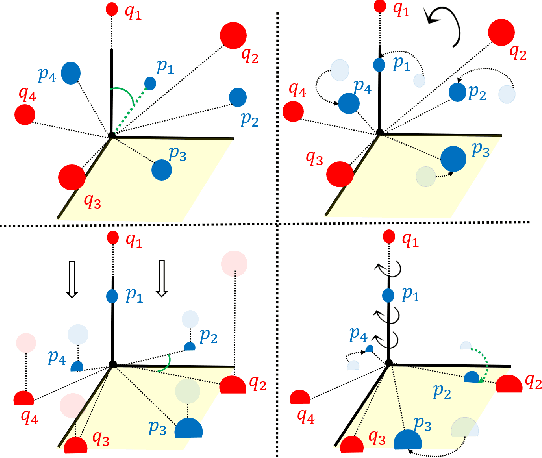
The goal of the \emph{alignment problem} is to align a (given) point cloud $P = \{p_1,\cdots,p_n\}$ to another (observed) point cloud $Q = \{q_1,\cdots,q_n\}$. That is, to compute a rotation matrix $R \in \mathbb{R}^{3 \times 3}$ and a translation vector $t \in \mathbb{R}^{3}$ that minimize the sum of paired distances $\sum_{i=1}^n D(Rp_i-t,q_i)$ for some distance function $D$. A harder version is the \emph{registration problem}, where the correspondence is unknown, and the minimum is also over all possible correspondence functions from $P$ to $Q$. Heuristics such as the Iterative Closest Point (ICP) algorithm and its variants were suggested for these problems, but none yield a provable non-trivial approximation for the global optimum. We prove that there \emph{always} exists a "witness" set of $3$ pairs in $P \times Q$ that, via novel alignment algorithm, defines a constant factor approximation (in the worst case) to this global optimum. We then provide algorithms that recover this witness set and yield the first provable constant factor approximation for the: (i) alignment problem in $O(n)$ expected time, and (ii) registration problem in polynomial time. Such small witness sets exist for many variants including points in $d$-dimensional space, outlier-resistant cost functions, and different correspondence types. Extensive experimental results on real and synthetic datasets show that our approximation constants are, in practice, close to $1$, and up to x$10$ times smaller than state-of-the-art algorithms.
Differentially Private Quantiles
Feb 16, 2021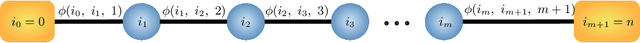

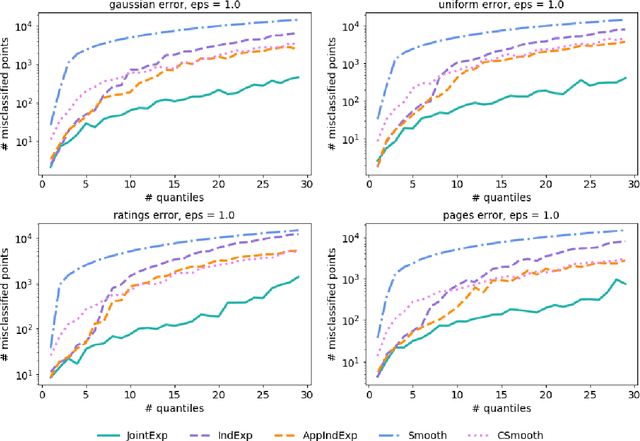
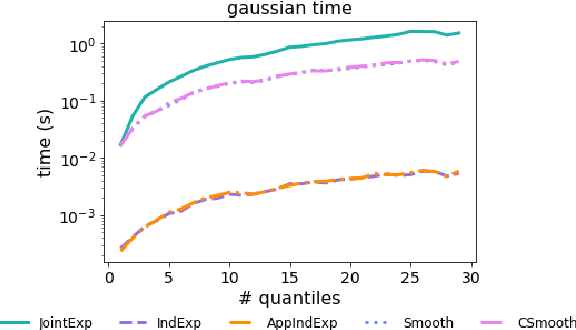
Quantiles are often used for summarizing and understanding data. If that data is sensitive, it may be necessary to compute quantiles in a way that is differentially private, providing theoretical guarantees that the result does not reveal private information. However, in the common case where multiple quantiles are needed, existing differentially private algorithms scale poorly: they compute each quantile individually, splitting their privacy budget and thus decreasing accuracy. In this work we propose an instance of the exponential mechanism that simultaneously estimates $m$ quantiles from $n$ data points while guaranteeing differential privacy. The utility function is carefully structured to allow for an efficient implementation that avoids exponential dependence on $m$ and returns estimates of all $m$ quantiles in time $O(mn^2 + m^2n)$. Experiments show that our method significantly outperforms the current state of the art on both real and synthetic data while remaining efficient enough to be practical.
Forecast with Forecasts: Diversity Matters
Dec 18, 2020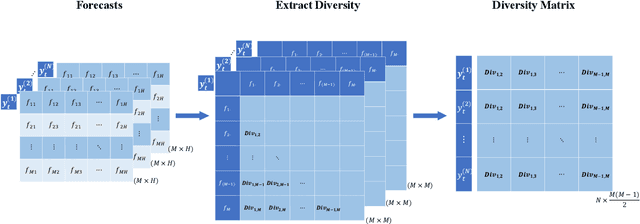

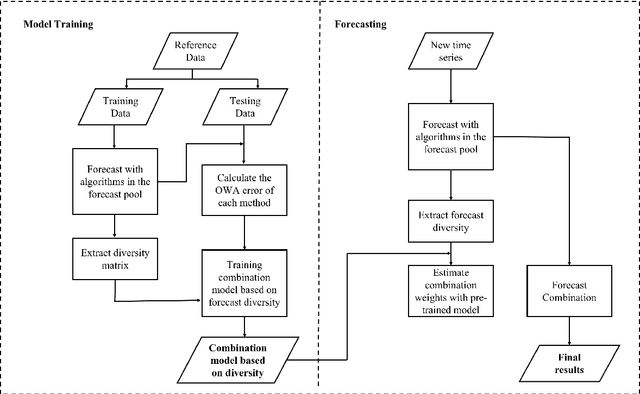
Forecast combination has been widely applied in the last few decades to improve forecast accuracy. In recent years, the idea of using time series features to construct forecast combination model has flourished in the forecasting area. Although this idea has been proved to be beneficial in several forecast competitions such as the M3 and M4 competitions, it may not be practical in many situations. For example, the task of selecting appropriate features to build forecasting models can be a big challenge for many researchers. Even if there is one acceptable way to define the features, existing features are estimated based on the historical patterns, which are doomed to change in the future, or infeasible in the case of limited historical data. In this work, we suggest a change of focus from the historical data to the produced forecasts to extract features. We calculate the diversity of a pool of models based on the corresponding forecasts as a decisive feature and use meta-learning to construct diversity-based forecast combination models. A rich set of time series are used to evaluate the performance of the proposed method. Experimental results show that our diversity-based forecast combination framework not only simplifies the modelling process but also achieves superior forecasting performance.
Shared Cross-Modal Trajectory Prediction for Autonomous Driving
Nov 15, 2020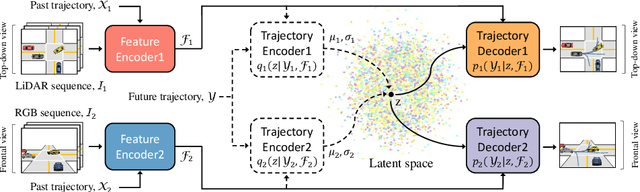
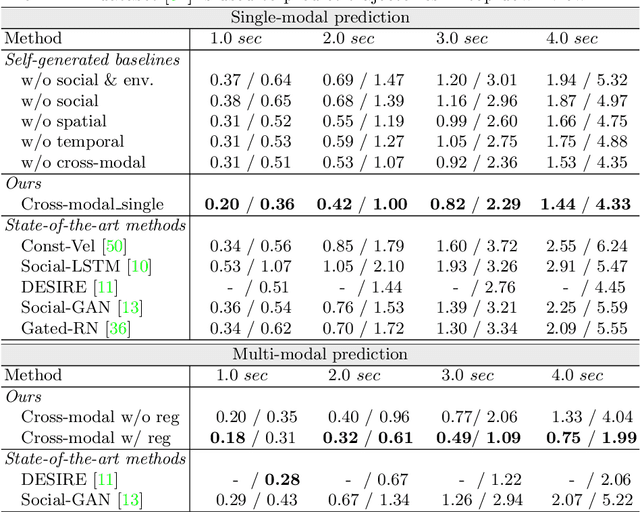
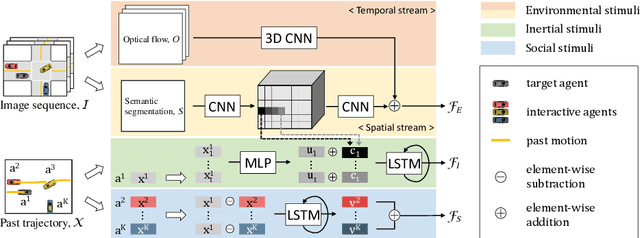
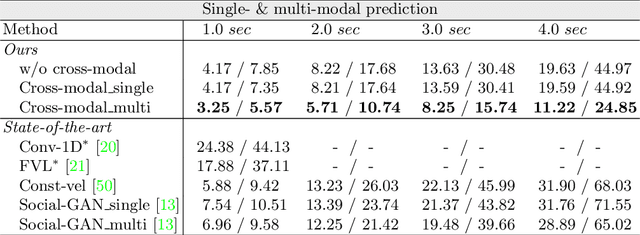
Predicting future trajectories of traffic agents in highly interactive environments is an essential and challenging problem for the safe operation of autonomous driving systems. On the basis of the fact that self-driving vehicles are equipped with various types of sensors (e.g., LiDAR scanner, RGB camera, radar, etc.), we propose a Cross-Modal Embedding framework that aims to benefit from the use of multiple input modalities. At training time, our model learns to embed a set of complementary features in a shared latent space by jointly optimizing the objective functions across different types of input data. At test time, a single input modality (e.g., LiDAR data) is required to generate predictions from the input perspective (i.e., in the LiDAR space), while taking advantages from the model trained with multiple sensor modalities. An extensive evaluation is conducted to show the efficacy of the proposed framework using two benchmark driving datasets.
Robust Place Recognition using an Imaging Lidar
Mar 03, 2021

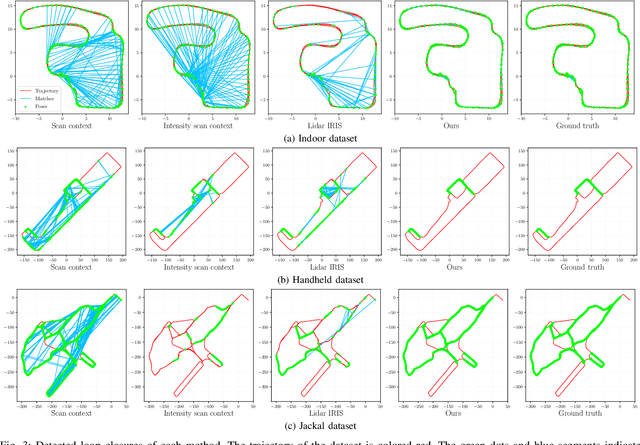

We propose a methodology for robust, real-time place recognition using an imaging lidar, which yields image-quality high-resolution 3D point clouds. Utilizing the intensity readings of an imaging lidar, we project the point cloud and obtain an intensity image. ORB feature descriptors are extracted from the image and encoded into a bag-of-words vector. The vector, used to identify the point cloud, is inserted into a database that is maintained by DBoW for fast place recognition queries. The returned candidate is further validated by matching visual feature descriptors. To reject matching outliers, we apply PnP, which minimizes the reprojection error of visual features' positions in Euclidean space with their correspondences in 2D image space, using RANSAC. Combining the advantages from both camera and lidar-based place recognition approaches, our method is truly rotation-invariant and can tackle reverse revisiting and upside-down revisiting. The proposed method is evaluated on datasets gathered from a variety of platforms over different scales and environments. Our implementation is available at https://git.io/imaging-lidar-place-recognition
Inter-Series Attention Model for COVID-19 Forecasting
Oct 25, 2020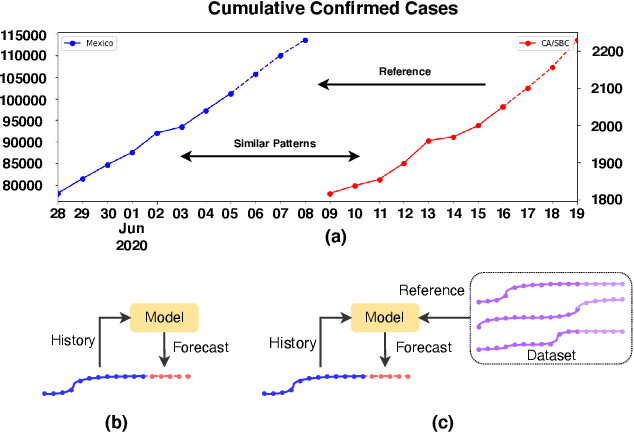

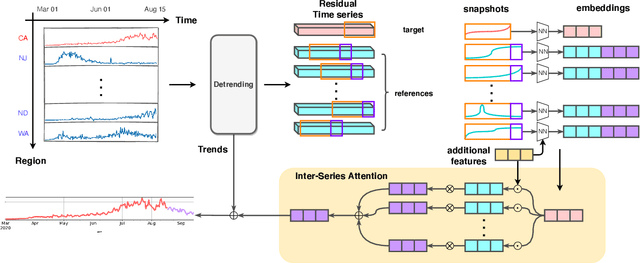
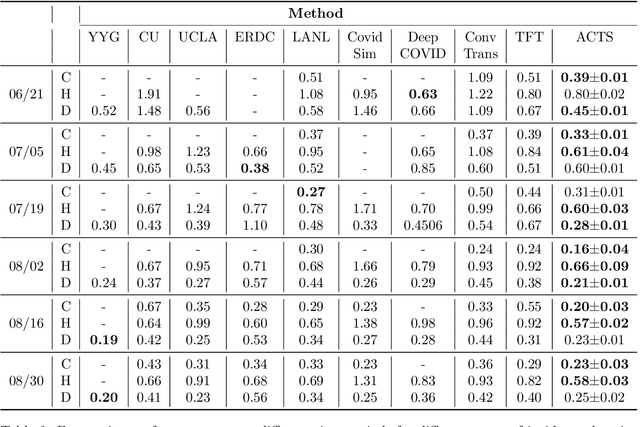
COVID-19 pandemic has an unprecedented impact all over the world since early 2020. During this public health crisis, reliable forecasting of the disease becomes critical for resource allocation and administrative planning. The results from compartmental models such as SIR and SEIR are popularly referred by CDC and news media. With more and more COVID-19 data becoming available, we examine the following question: Can a direct data-driven approach without modeling the disease spreading dynamics outperform the well referred compartmental models and their variants? In this paper, we show the possibility. It is observed that as COVID-19 spreads at different speed and scale in different geographic regions, it is highly likely that similar progression patterns are shared among these regions within different time periods. This intuition lead us to develop a new neural forecasting model, called Attention Crossing Time Series (\textbf{ACTS}), that makes forecasts via comparing patterns across time series obtained from multiple regions. The attention mechanism originally developed for natural language processing can be leveraged and generalized to materialize this idea. Among 13 out of 18 testings including forecasting newly confirmed cases, hospitalizations and deaths, \textbf{ACTS} outperforms all the leading COVID-19 forecasters highlighted by CDC.
Universal discrete-time reservoir computers with stochastic inputs and linear readouts using non-homogeneous state-affine systems
Aug 26, 2018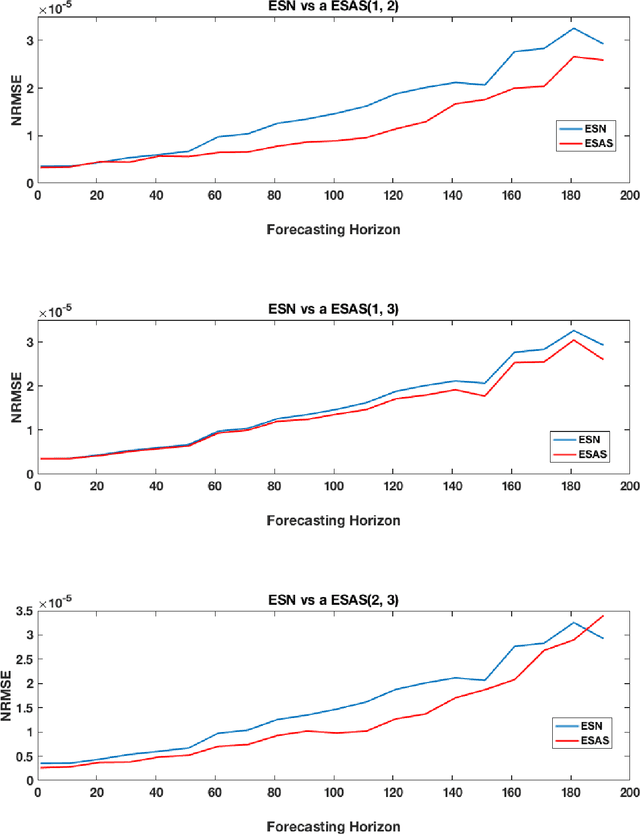
A new class of non-homogeneous state-affine systems is introduced for use in reservoir computing. Sufficient conditions are identified that guarantee first, that the associated reservoir computers with linear readouts are causal, time-invariant, and satisfy the fading memory property and second, that a subset of this class is universal in the category of fading memory filters with stochastic almost surely uniformly bounded inputs. This means that any discrete-time filter that satisfies the fading memory property with random inputs of that type can be uniformly approximated by elements in the non-homogeneous state-affine family.
Learning Student-Friendly Teacher Networks for Knowledge Distillation
Feb 16, 2021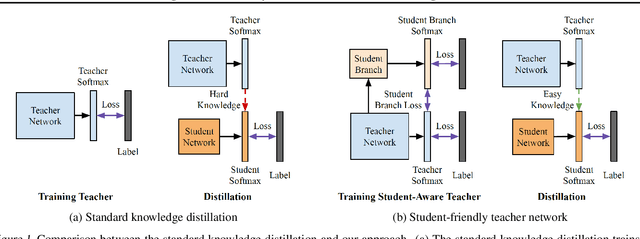
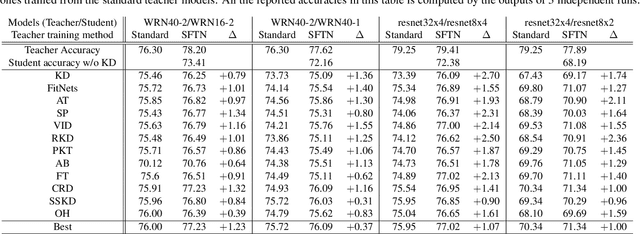
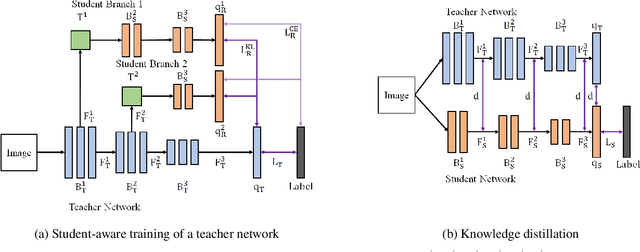
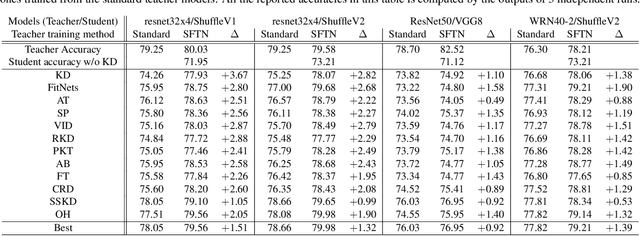
We propose a novel knowledge distillation approach to facilitate the transfer of dark knowledge from a teacher to a student. Contrary to most of the existing methods that rely on effective training of student models given pretrained teachers, we aim to learn the teacher models that are friendly to students and, consequently, more appropriate for knowledge transfer. In other words, even at the time of optimizing a teacher model, the proposed algorithm learns the student branches jointly to obtain student-friendly representations. Since the main goal of our approach lies in training teacher models and the subsequent knowledge distillation procedure is straightforward, most of the existing knowledge distillation algorithms can adopt this technique to improve the performance of the student models in terms of accuracy and convergence speed. The proposed algorithm demonstrates outstanding accuracy in several well-known knowledge distillation techniques with various combinations of teacher and student architectures.
Semantic Contextual Reasoning to Provide Human Behavior
Mar 19, 2021

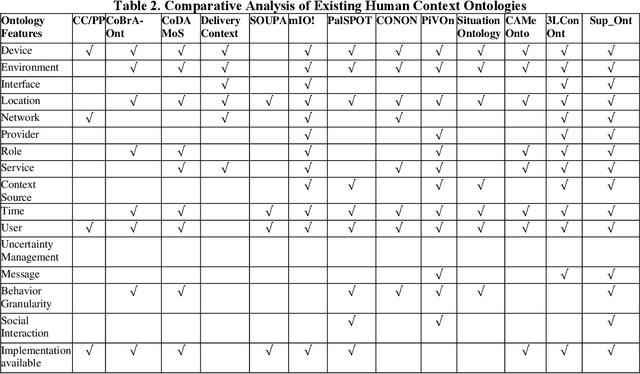
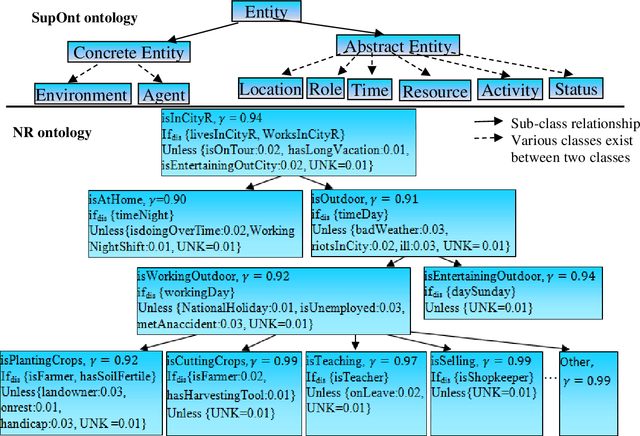
In recent years, the world has witnessed various primitives pertaining to the complexity of human behavior. Identifying an event in the presence of insufficient, incomplete, or tentative premises along with the constraints on resources such as time, data and memory is a vital aspect of an intelligent system. Data explosion presents one of the most challenging research issues for intelligent systems; to optimally represent and store this heterogeneous and voluminous data semantically to provide human behavior. There is a requirement of intelligent but personalized human behavior subject to constraints on resources and priority of the user. Knowledge, when represented in the form of an ontology, procures an intelligent response to a query posed by users; but it does not offer content in accordance with the user context. To this aim, we propose a model to quantify the user context and provide semantic contextual reasoning. A diagnostic belief algorithm (DBA) is also presented that identifies a given event and also computes the confidence of the decision as a function of available resources, premises, exceptions, and desired specificity. We conduct an empirical study in the domain of day-to-day routine queries and the experimental results show that the answer to queries and also its confidence varies with user context.