 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TSception: Capturing Temporal Dynamics and Spatial Asymmetry from EEG for Emotion Recognition
Apr 07, 2021

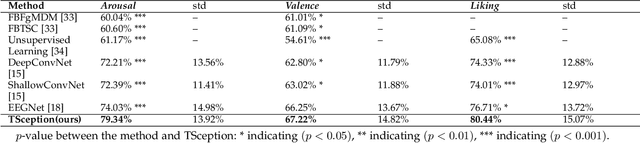
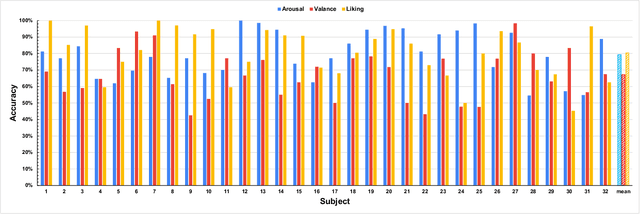
In this paper, we propose TSception, a multi-scale convolutional neural network, to learn temporal dynamics and spatial asymmetry from affective electroencephalogram (EEG). TSception consists of dynamic temporal, asymmetric spatial, and high-level fusion Layers, which learn discriminative representations in the time and channel dimensions simultaneously. The dynamic temporal layer consists of multi-scale 1D convolutional kernels whose lengths are related to the sampling rate of the EEG signal, which learns its dynamic temporal and frequency representations. The asymmetric spatial layer takes advantage of the asymmetric neural activations underlying emotional responses, learning the discriminative global and hemisphere representations. The learned spatial representations will be fused by a high-level fusion layer. With robust nested cross-validation settings, the proposed method is evaluated on two publicly available datasets DEAP and AMIGOS. And the performance is compared with prior reported methods such as FBFgMDM, FBTSC, Unsupervised learning, DeepConvNet, ShallowConvNet, and EEGNet. The results indicate that the proposed method significantly (p<0.05) outperforms others in terms of classification accuracy. The proposed methods can be utilized in emotion regulation therapy for emotion recognition in the future. The source code can be found at: https://github.com/deepBrains/TSception-New
Creating Pro-Level AI for Real-Time Fighting Game with Deep Reinforcement Learning
Apr 08, 2019
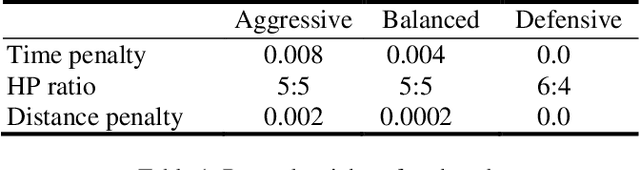
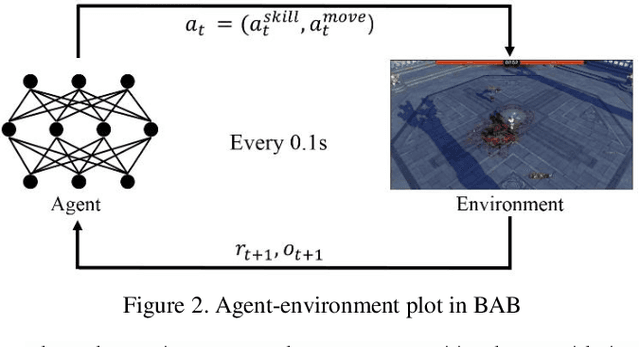

Reinforcement learning combined with deep neural networks has performed remarkably well in many genres of game recently. It surpassed human-level performance in fixed game environments and turn-based two player board games. However, no research has ever shown a result that surpassed human level in modern complex fighting games, to the best of our knowledge. This is due to the inherent difficulties of modern fighting games, including vast action spaces, real-time constraints, and performance generalizations required for various opponents. We overcame these challenges and made 1v1 battle AI agents for the commercial game, "Blade & Soul". The trained agents competed against five professional gamers and achieved 62% of win rate.This paper presents a practical reinforcement learning method including a novel self-play curriculum and data skipping techniques. Through the curriculum, three different styles of agents are created by reward shaping, and are trained against each other for robust performance. Additionally, this paper suggests data skipping techniques which increased data efficiency and facilitated explorations in vast spaces.
Learning compressed representations of blood samples time series with missing data
Oct 20, 2017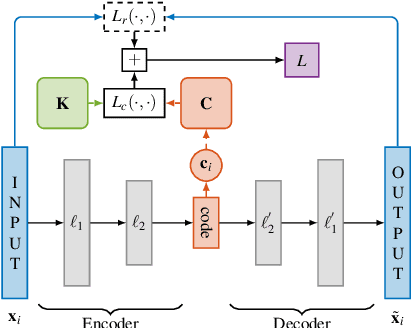

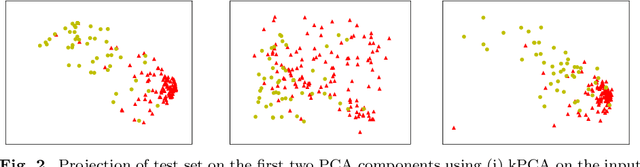
Clinical measurements collected over time are naturally represented as multivariate time series (MTS), which often contain missing data. An autoencoder can learn low dimensional vectorial representations of MTS that preserve important data characteristics, but cannot deal explicitly with missing data. In this work, we propose a new framework that combines an autoencoder with the Time series Cluster Kernel (TCK), a kernel that accounts for missingness patterns in MTS. Via kernel alignment, we incorporate TCK in the autoencoder to improve the learned representations in presence of missing data. We consider a classification problem of MTS with missing values, representing blood samples of patients with surgical site infection. With our approach, rather than with a standard autoencoder, we learn representations in low dimensions that can be classified better.
PCB-Fire: Automated Classification and Fault Detection in PCB
Feb 22, 2021
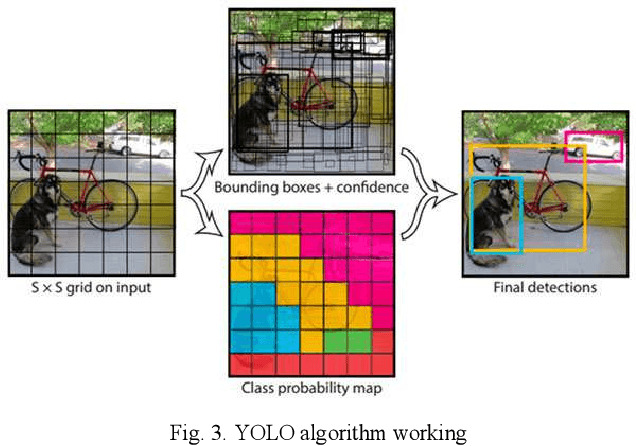

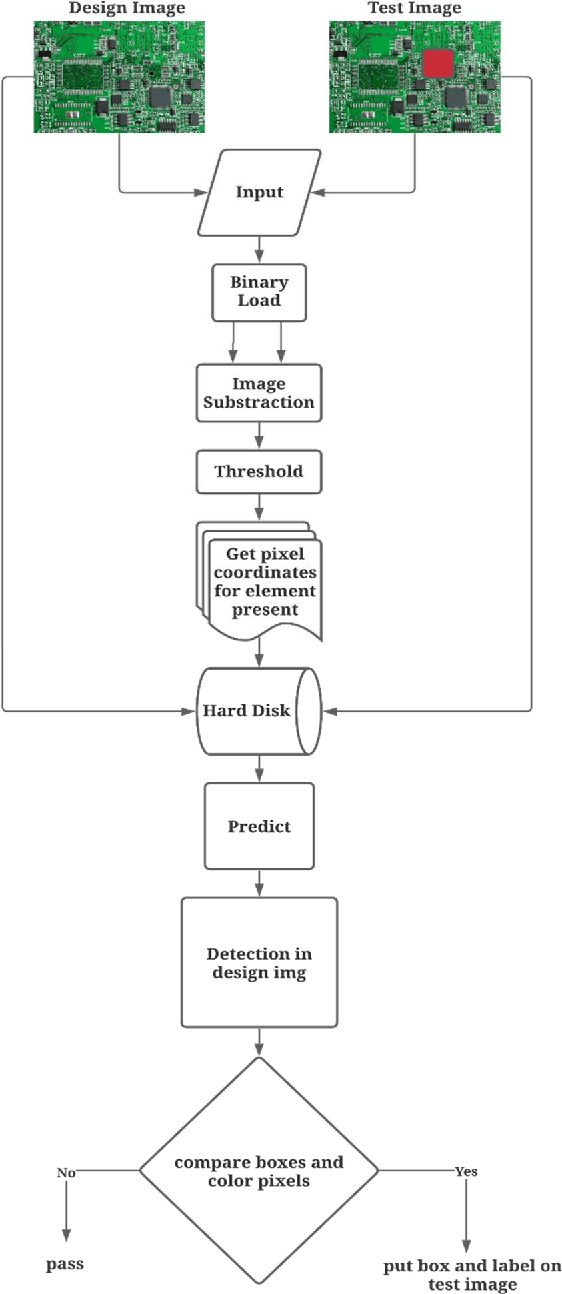
Printed Circuit Boards are the foundation for the functioning of any electronic device, and therefore are an essential component for various industries such as automobile, communication, computation, etc. However, one of the challenges faced by the PCB manufacturers in the process of manufacturing of the PCBs is the faulty placement of its components including missing components. In the present scenario the infrastructure required to ensure adequate quality of the PCB requires a lot of time and effort. The authors present a novel solution for detecting missing components and classifying them in a resourceful manner. The presented algorithm focuses on pixel theory and object detection, which has been used in combination to optimize the results from the given dataset.
* 6 Pages, 9 Figures, Conference
Modeling Graph Node Correlations with Neighbor Mixture Models
Mar 29, 2021
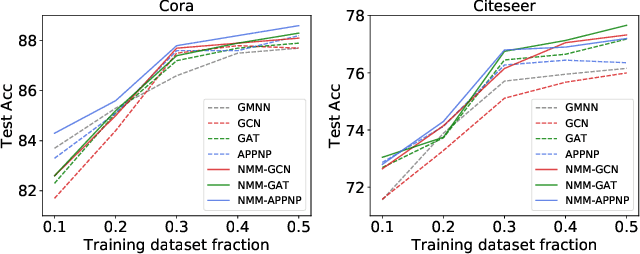
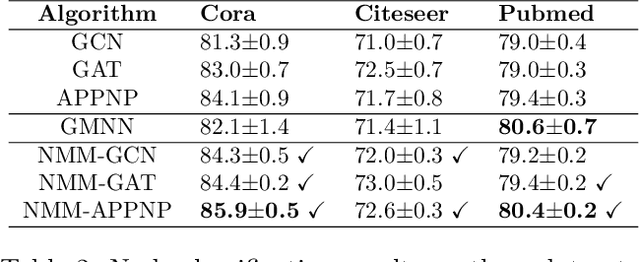
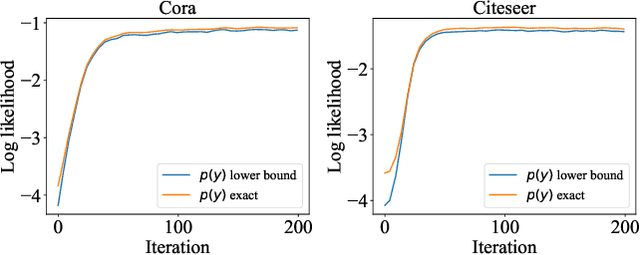
We propose a new model, the Neighbor Mixture Model (NMM), for modeling node labels in a graph. This model aims to capture correlations between the labels of nodes in a local neighborhood. We carefully design the model so it could be an alternative to a Markov Random Field but with more affordable computations. In particular, drawing samples and evaluating marginal probabilities of single labels can be done in linear time. To scale computations to large graphs, we devise a variational approximation without introducing extra parameters. We further use graph neural networks (GNNs) to parameterize the NMM, which reduces the number of learnable parameters while allowing expressive representation learning. The proposed model can be either fit directly to large observed graphs or used to enable scalable inference that preserves correlations for other distributions such as deep generative graph models. Across a diverse set of node classification, image denoising, and link prediction tasks, we show our proposed NMM advances the state-of-the-art in modeling real-world labeled graphs.
Non-Autoregressive Predictive Coding for Learning Speech Representations from Local Dependencies
Nov 01, 2020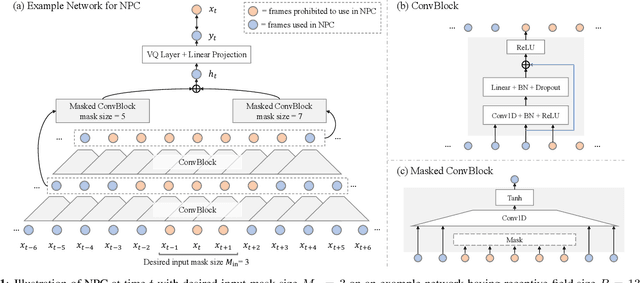
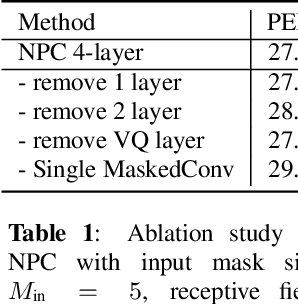
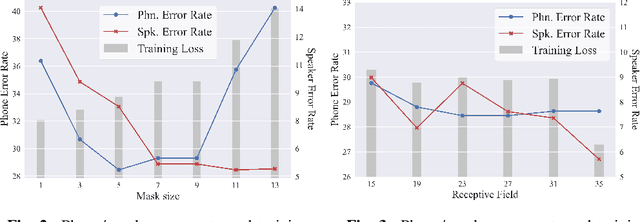
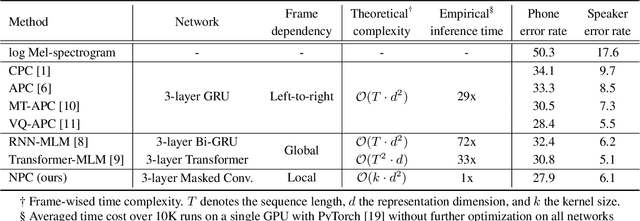
Self-supervised speech representations have been shown to be effective in a variety of speech applications. However, existing representation learning methods generally rely on the autoregressive model and/or observed global dependencies while generating the representation. In this work, we propose Non-Autoregressive Predictive Coding (NPC), a self-supervised method, to learn a speech representation in a non-autoregressive manner by relying only on local dependencies of speech. NPC has a conceptually simple objective and can be implemented easily with the introduced Masked Convolution Blocks. NPC offers a significant speedup for inference since it is parallelizable in time and has a fixed inference time for each time step regardless of the input sequence length. We discuss and verify the effectiveness of NPC by theoretically and empirically comparing it with other methods. We show that the NPC representation is comparable to other methods in speech experiments on phonetic and speaker classification while being more efficient.
A Closer Look at Self-training for Zero-Label Semantic Segmentation
Apr 21, 2021
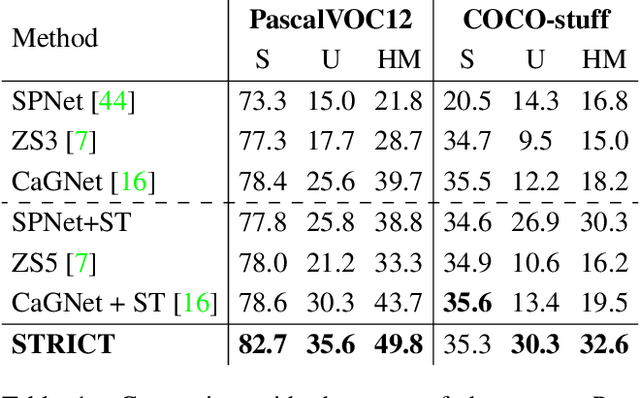
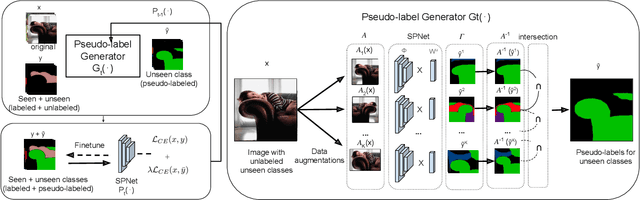
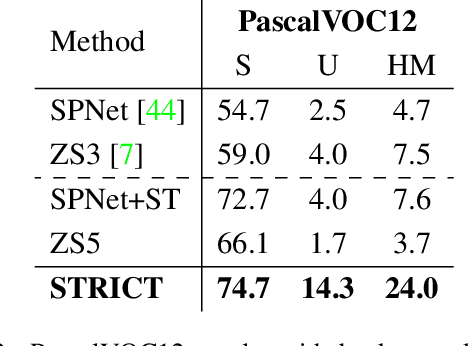
Being able to segment unseen classes not observed during training is an important technical challenge in deep learning, because of its potential to reduce the expensive annotation required for semantic segmentation. Prior zero-label semantic segmentation works approach this task by learning visual-semantic embeddings or generative models. However, they are prone to overfitting on the seen classes because there is no training signal for them. In this paper, we study the challenging generalized zero-label semantic segmentation task where the model has to segment both seen and unseen classes at test time. We assume that pixels of unseen classes could be present in the training images but without being annotated. Our idea is to capture the latent information on unseen classes by supervising the model with self-produced pseudo-labels for unlabeled pixels. We propose a consistency regularizer to filter out noisy pseudo-labels by taking the intersections of the pseudo-labels generated from different augmentations of the same image. Our framework generates pseudo-labels and then retrain the model with human-annotated and pseudo-labelled data. This procedure is repeated for several iterations. As a result, our approach achieves the new state-of-the-art on PascalVOC12 and COCO-stuff datasets in the challenging generalized zero-label semantic segmentation setting, surpassing other existing methods addressing this task with more complex strategies.
Temporally-Continuous Probabilistic Prediction using Polynomial Trajectory Parameterization
Nov 01, 2020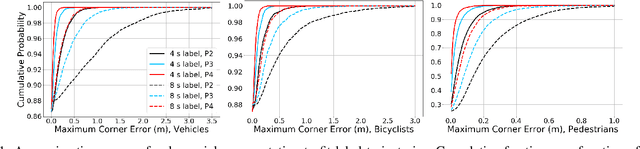
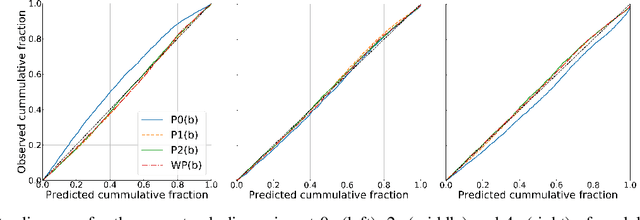
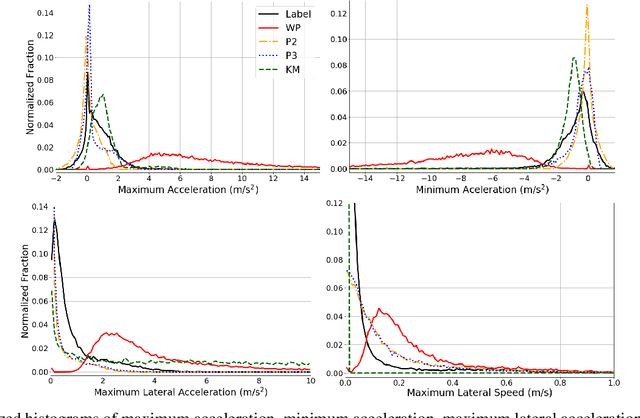
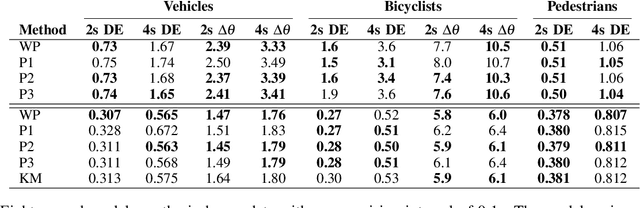
A commonly-used representation for motion prediction of actors is a sequence of waypoints (comprising positions and orientations) for each actor at discrete future time-points. While this approach is simple and flexible, it can exhibit unrealistic higher-order derivatives (such as acceleration) and approximation errors at intermediate time steps. To address this issue we propose a simple and general representation for temporally continuous probabilistic trajectory prediction that is based on polynomial trajectory parameterization. We evaluate the proposed representation on supervised trajectory prediction tasks using two large self-driving data sets. The results show realistic higher-order derivatives and better accuracy at interpolated time-points, as well as the benefits of the inferred noise distributions over the trajectories. Extensive experimental studies based on existing state-of-the-art models demonstrate the effectiveness of the proposed approach relative to other representations in predicting the future motions of vehicle, bicyclist, and pedestrian traffic actors.
Cisco at AAAI-CAD21 shared task: Predicting Emphasis in Presentation Slides using Contextualized Embeddings
Feb 09, 2021
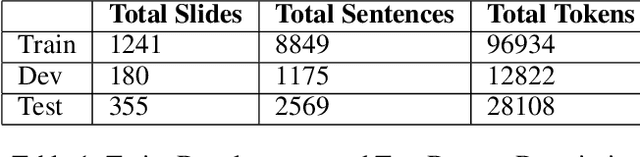
This paper describes our proposed system for the AAAI-CAD21 shared task: Predicting Emphasis in Presentation Slides. In this specific task, given the contents of a slide we are asked to predict the degree of emphasis to be laid on each word in the slide. We propose 2 approaches to this problem including a BiLSTM-ELMo approach and a transformers based approach based on RoBERTa and XLNet architectures. We achieve a score of 0.518 on the evaluation leaderboard which ranks us 3rd and 0.543 on the post-evaluation leaderboard which ranks us 1st at the time of writing the paper.
Real-time Segmentation and Facial Skin Tones Grading
Jan 09, 2020
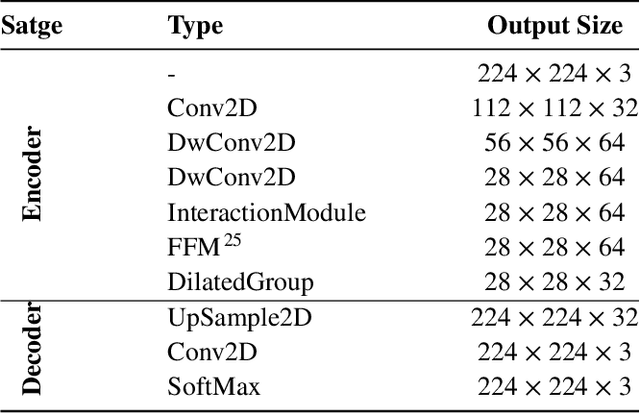
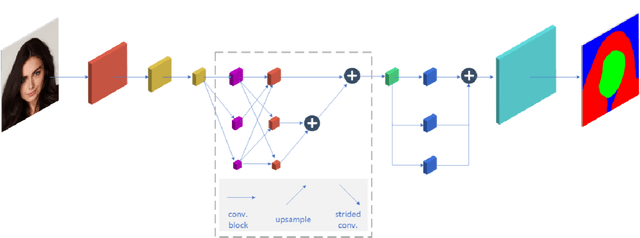
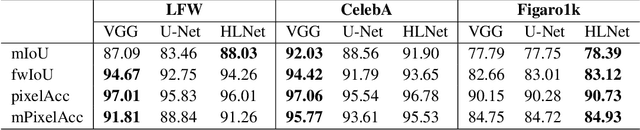
Modern approaches for semantic segmention usually pay too much attention to the accuracy of the model, and therefore it is strongly recommended to introduce cumbersome backbones, which brings heavy computation burden and memory footprint. To alleviate this problem, we propose an efficient segmentation method based on deep convolutional neural networks (DCNNs) for the task of hair and facial skin segmentation, which achieving remarkable trade-off between speed and performance on three benchmark datasets. As far as we know, the accuracy of skin tones classification is usually unsatisfactory due to the influence of external environmental factors such as illumination and background noise. Therefore, we use the segmentated face to obtain a specific face area, and further exploit the color moment algorithm to extract its color features. Specifically, for a 224 x 224 standard input, using our high-resolution spatial detail information and low-resolution contextual information fusion network (HLNet), we achieve 90.73% Pixel Accuracy on Figaro1k dataset at over 16 FPS in the case of CPU environment. Additional experiments on CamVid dataset further confirm the universality of the proposed model. We further use masked color moment for skin tones grade evaluation and approximate 80% classification accuracy demonstrate the feasibility of the proposed scheme.Code is available at https://github.com/JACKYLUO1991/Face-skin-hair-segmentaiton-and-skin-color-evaluation.