 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMRA-proxy: Enhancing Multi-Class Region Semantic Segmentation in Remote Sensing Images with Attention Proxy
May 23, 2025



High-resolution remote sensing (HRRS) image segmentation is challenging due to complex spatial layouts and diverse object appearances. While CNNs excel at capturing local features, they struggle with long-range dependencies, whereas Transformers can model global context but often neglect local details and are computationally expensive.We propose a novel approach, Region-Aware Proxy Network (RAPNet), which consists of two components: Contextual Region Attention (CRA) and Global Class Refinement (GCR). Unlike traditional methods that rely on grid-based layouts, RAPNet operates at the region level for more flexible segmentation. The CRA module uses a Transformer to capture region-level contextual dependencies, generating a Semantic Region Mask (SRM). The GCR module learns a global class attention map to refine multi-class information, combining the SRM and attention map for accurate segmentation.Experiments on three public datasets show that RAPNet outperforms state-of-the-art methods, achieving superior multi-class segmentation accuracy.
Building on Huang et al. GlossBERT for Word Sense Disambiguation
Dec 14, 2021
We propose to take on the problem ofWord Sense Disambiguation (WSD). In language, words of the same form can take different meanings depending on context. While humans easily infer the meaning or gloss of such words by their context, machines stumble on this task.As such, we intend to replicated and expand upon the results of Huang et al.GlossBERT, a model which they design to disambiguate these words (Huang et al.,2019). Specifically, we propose the following augmentations: data-set tweaking(alpha hyper-parameter), ensemble methods, and replacement of BERT with BART andALBERT. The following GitHub repository contains all code used in this report, which extends on the code made available by Huang et al.
Real-time Segmentation and Facial Skin Tones Grading
Jan 09, 2020
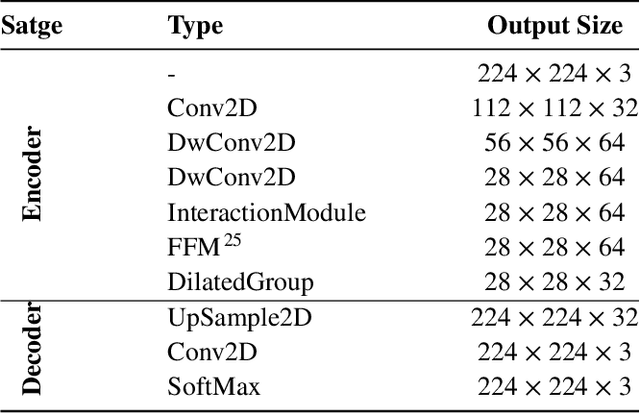
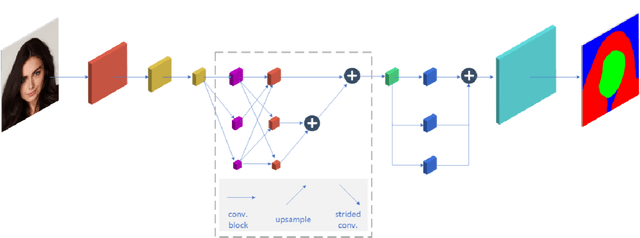
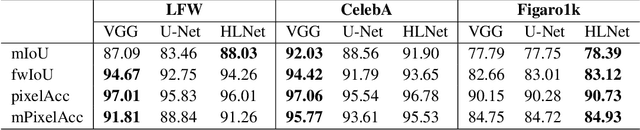
Modern approaches for semantic segmention usually pay too much attention to the accuracy of the model, and therefore it is strongly recommended to introduce cumbersome backbones, which brings heavy computation burden and memory footprint. To alleviate this problem, we propose an efficient segmentation method based on deep convolutional neural networks (DCNNs) for the task of hair and facial skin segmentation, which achieving remarkable trade-off between speed and performance on three benchmark datasets. As far as we know, the accuracy of skin tones classification is usually unsatisfactory due to the influence of external environmental factors such as illumination and background noise. Therefore, we use the segmentated face to obtain a specific face area, and further exploit the color moment algorithm to extract its color features. Specifically, for a 224 x 224 standard input, using our high-resolution spatial detail information and low-resolution contextual information fusion network (HLNet), we achieve 90.73% Pixel Accuracy on Figaro1k dataset at over 16 FPS in the case of CPU environment. Additional experiments on CamVid dataset further confirm the universality of the proposed model. We further use masked color moment for skin tones grade evaluation and approximate 80% classification accuracy demonstrate the feasibility of the proposed scheme.Code is available at https://github.com/JACKYLUO1991/Face-skin-hair-segmentaiton-and-skin-color-evaluation.