 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLineRides: Line-Guided Reinforcement Learning for Bicycle Robot Stunts
May 06, 2026Designing reward functions for agile robotic maneuvers in reinforcement learning remains difficult, and demonstration-based approaches often require reference motions that are unavailable for novel platforms or extreme stunts. We present LineRides, a line-guided learning framework that enables a custom bicycle robot to acquire diverse, commandable stunt behaviors from a user-provided spatial guideline and sparse key-orientations, without demonstrations or explicit timing. LineRides handles physically infeasible guidelines using a tracking margin that permits controlled deviation, resolves temporal ambiguity by measuring progress via traveled distance along the guideline, and disambiguates motion details through position- and sequence-based key-orientations. We evaluate LineRides on the Ultra Mobility Vehicle (UMV) and show that the policy trained with our methods supports seamless transitions between normal driving and stunt execution, enabling five distinct stunts on command: MiniHop, LargeHop, ThreePointTurn, Backflip, and DriftTurn.
Flip Stunts on Bicycle Robots using Iterative Motion Imitation
Mar 30, 2026This work demonstrates a front-flip on bicycle robots via reinforcement learning, particularly by imitating reference motions that are infeasible and imperfect. To address this, we propose Iterative Motion Imitation(IMI), a method that iteratively imitates trajectories generated by prior policy rollouts. Starting from an initial reference that is kinematically or dynamically infeasible, IMI helps train policies that lead to feasible and agile behaviors. We demonstrate our method on Ultra-Mobility Vehicle (UMV), a bicycle robot that is designed to enable agile behaviors. From a self-colliding table-to-ground flip reference generated by a model-based controller, we are able to train policies that enable ground-to-ground and ground-to-table front-flips. We show that compared to a single-shot motion imitation, IMI results in policies with higher success rates and can transfer robustly to the real world. To our knowledge, this is the first unassisted acrobatic flip behavior on such a platform.
Unsupervised Skill Discovery as Exploration for Learning Agile Locomotion
Aug 12, 2025Exploration is crucial for enabling legged robots to learn agile locomotion behaviors that can overcome diverse obstacles. However, such exploration is inherently challenging, and we often rely on extensive reward engineering, expert demonstrations, or curriculum learning - all of which limit generalizability. In this work, we propose Skill Discovery as Exploration (SDAX), a novel learning framework that significantly reduces human engineering effort. SDAX leverages unsupervised skill discovery to autonomously acquire a diverse repertoire of skills for overcoming obstacles. To dynamically regulate the level of exploration during training, SDAX employs a bi-level optimization process that autonomously adjusts the degree of exploration. We demonstrate that SDAX enables quadrupedal robots to acquire highly agile behaviors including crawling, climbing, leaping, and executing complex maneuvers such as jumping off vertical walls. Finally, we deploy the learned policy on real hardware, validating its successful transfer to the real world.
Language Guided Skill Discovery
Jun 07, 2024



Skill discovery methods enable agents to learn diverse emergent behaviors without explicit rewards. To make learned skills useful for unknown downstream tasks, obtaining a semantically diverse repertoire of skills is essential. While some approaches introduce a discriminator to distinguish skills and others aim to increase state coverage, no existing work directly addresses the "semantic diversity" of skills. We hypothesize that leveraging the semantic knowledge of large language models (LLMs) can lead us to improve semantic diversity of resulting behaviors. In this sense, we introduce Language Guided Skill Discovery (LGSD), a skill discovery framework that aims to directly maximize the semantic diversity between skills. LGSD takes user prompts as input and outputs a set of semantically distinctive skills. The prompts serve as a means to constrain the search space into a semantically desired subspace, and the generated LLM outputs guide the agent to visit semantically diverse states within the subspace. We demonstrate that LGSD enables legged robots to visit different user-intended areas on a plane by simply changing the prompt. Furthermore, we show that language guidance aids in discovering more diverse skills compared to five existing skill discovery methods in robot-arm manipulation environments. Lastly, LGSD provides a simple way of utilizing learned skills via natural language.
Hexa: Self-Improving for Knowledge-Grounded Dialogue System
Oct 22, 2023



A common practice in knowledge-grounded dialogue generation is to explicitly utilize intermediate steps (e.g., web-search, memory retrieval) with modular approaches. However, data for such steps are often inaccessible compared to those of dialogue responses as they are unobservable in an ordinary dialogue. To fill in the absence of these data, we develop a self-improving method to improve the generative performances of intermediate steps without the ground truth data. In particular, we propose a novel bootstrapping scheme with a guided prompt and a modified loss function to enhance the diversity of appropriate self-generated responses. Through experiments on various benchmark datasets, we empirically demonstrate that our method successfully leverages a self-improving mechanism in generating intermediate and final responses and improves the performances on the task of knowledge-grounded dialogue generation.
LECO: Learnable Episodic Count for Task-Specific Intrinsic Reward
Oct 11, 2022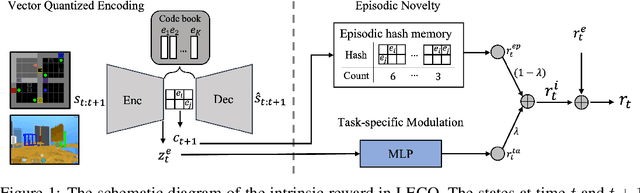
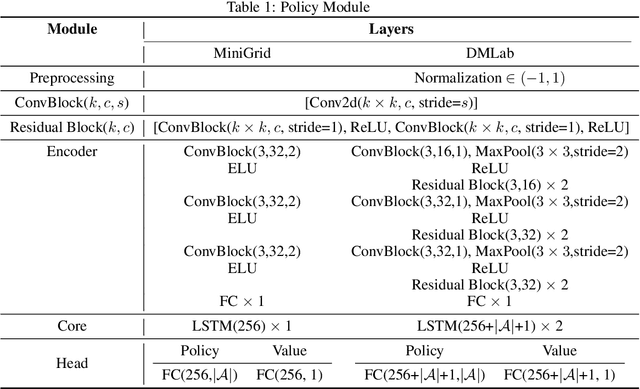
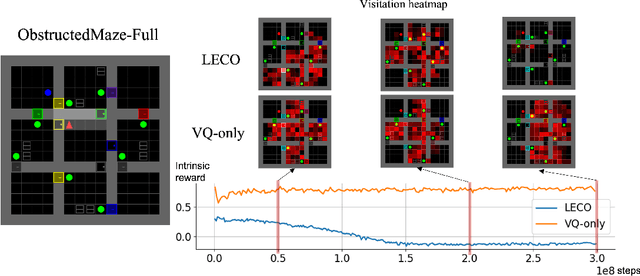
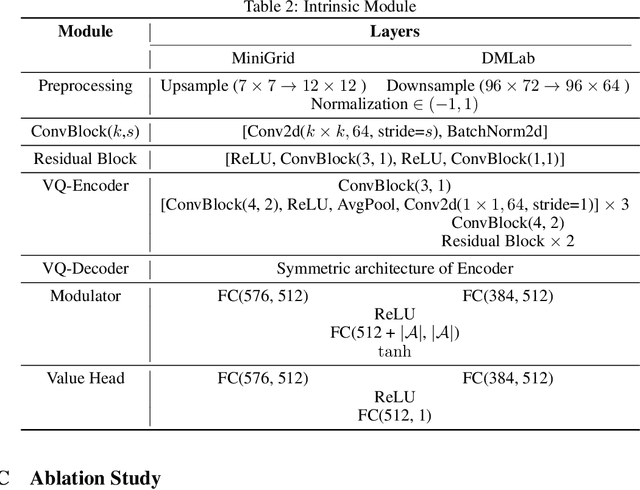
Episodic count has been widely used to design a simple yet effective intrinsic motivation for reinforcement learning with a sparse reward. However, the use of episodic count in a high-dimensional state space as well as over a long episode time requires a thorough state compression and fast hashing, which hinders rigorous exploitation of it in such hard and complex exploration environments. Moreover, the interference from task-irrelevant observations in the episodic count may cause its intrinsic motivation to overlook task-related important changes of states, and the novelty in an episodic manner can lead to repeatedly revisit the familiar states across episodes. In order to resolve these issues, in this paper, we propose a learnable hash-based episodic count, which we name LECO, that efficiently performs as a task-specific intrinsic reward in hard exploration problems. In particular, the proposed intrinsic reward consists of the episodic novelty and the task-specific modulation where the former employs a vector quantized variational autoencoder to automatically obtain the discrete state codes for fast counting while the latter regulates the episodic novelty by learning a modulator to optimize the task-specific extrinsic reward. The proposed LECO specifically enables the automatic transition from exploration to exploitation during reinforcement learning. We experimentally show that in contrast to the previous exploration methods LECO successfully solves hard exploration problems and also scales to large state spaces through the most difficult tasks in MiniGrid and DMLab environments.
Creating Pro-Level AI for Real-Time Fighting Game with Deep Reinforcement Learning
Apr 08, 2019
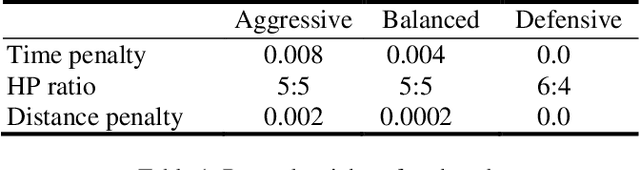
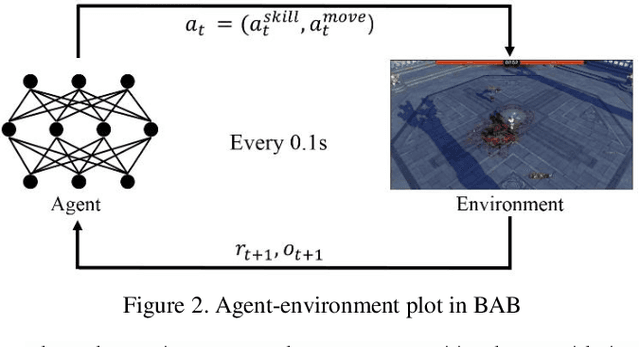

Reinforcement learning combined with deep neural networks has performed remarkably well in many genres of game recently. It surpassed human-level performance in fixed game environments and turn-based two player board games. However, no research has ever shown a result that surpassed human level in modern complex fighting games, to the best of our knowledge. This is due to the inherent difficulties of modern fighting games, including vast action spaces, real-time constraints, and performance generalizations required for various opponents. We overcame these challenges and made 1v1 battle AI agents for the commercial game, "Blade & Soul". The trained agents competed against five professional gamers and achieved 62% of win rate.This paper presents a practical reinforcement learning method including a novel self-play curriculum and data skipping techniques. Through the curriculum, three different styles of agents are created by reward shaping, and are trained against each other for robust performance. Additionally, this paper suggests data skipping techniques which increased data efficiency and facilitated explorations in vast spaces.