 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
L3DAS21 Challenge: Machine Learning for 3D Audio Signal Processing
Apr 22, 2021
The L3DAS21 Challenge is aimed at encouraging and fostering collaborative research on machine learning for 3D audio signal processing, with particular focus on 3D speech enhancement (SE) and 3D sound localization and detection (SELD). Alongside with the challenge, we release the L3DAS21 dataset, a 65 hours 3D audio corpus, accompanied with a Python API that facilitates the data usage and results submission stage. Usually, machine learning approaches to 3D audio tasks are based on single-perspective Ambisonics recordings or on arrays of single-capsule microphones. We propose, instead, a novel multichannel audio configuration based multiple-source and multiple-perspective Ambisonics recordings, performed with an array of two first-order Ambisonics microphones. To the best of our knowledge, it is the first time that a dual-mic Ambisonics configuration is used for these tasks. We provide baseline models and results for both tasks, obtained with state-of-the-art architectures: FaSNet for SE and SELDNet for SELD. This report is aimed at providing all needed information to participate in the L3DAS21 Challenge, illustrating the details of the L3DAS21 dataset, the challenge tasks and the baseline models.
Distributed Word Representation in Tsetlin Machine
Apr 14, 2021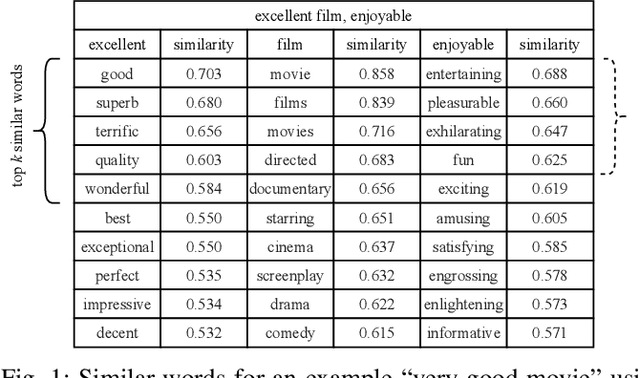
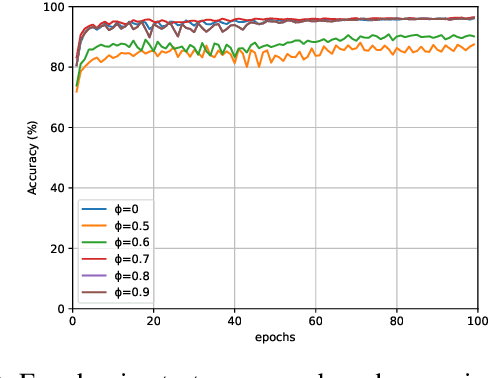
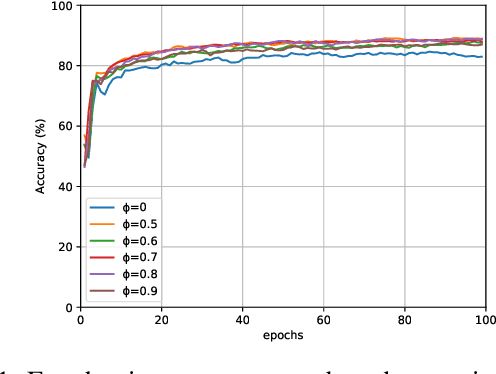
Tsetlin Machine (TM) is an interpretable pattern recognition algorithm based on propositional logic. The algorithm has demonstrated competitive performance in many Natural Language Processing (NLP) tasks, including sentiment analysis, text classification, and Word Sense Disambiguation (WSD). To obtain human-level interpretability, legacy TM employs Boolean input features such as bag-of-words (BOW). However, the BOW representation makes it difficult to use any pre-trained information, for instance, word2vec and GloVe word representations. This restriction has constrained the performance of TM compared to deep neural networks (DNNs) in NLP. To reduce the performance gap, in this paper, we propose a novel way of using pre-trained word representations for TM. The approach significantly enhances the TM performance and maintains interpretability at the same time. We achieve this by extracting semantically related words from pre-trained word representations as input features to the TM. Our experiments show that the accuracy of the proposed approach is significantly higher than the previous BOW-based TM, reaching the level of DNN-based models.
Financial Markets Prediction with Deep Learning
Apr 05, 2021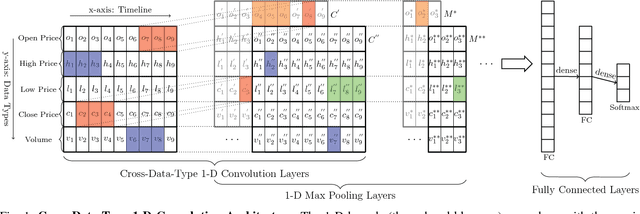
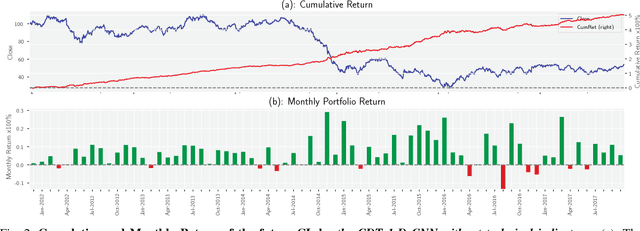
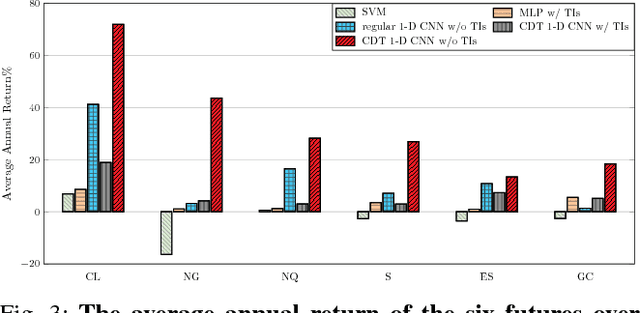
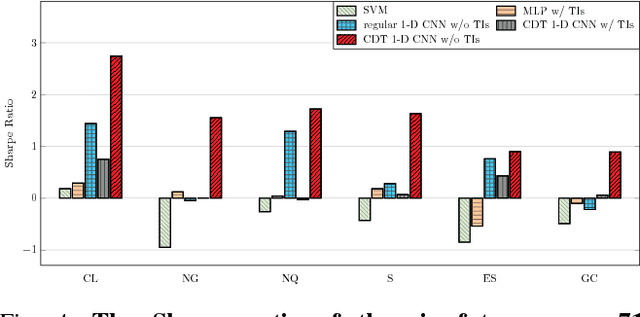
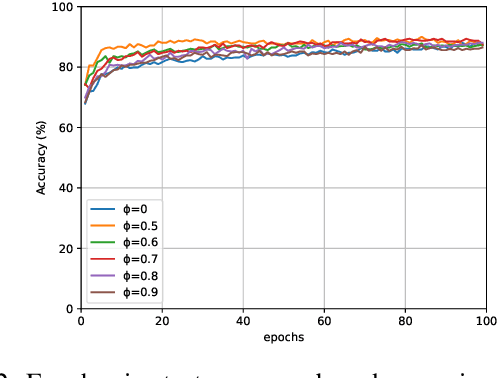
Financial markets are difficult to predict due to its complex systems dynamics. Although there have been some recent studies that use machine learning techniques for financial markets prediction, they do not offer satisfactory performance on financial returns. We propose a novel one-dimensional convolutional neural networks (CNN) model to predict financial market movement. The customized one-dimensional convolutional layers scan financial trading data through time, while different types of data, such as prices and volume, share parameters (kernels) with each other. Our model automatically extracts features instead of using traditional technical indicators and thus can avoid biases caused by selection of technical indicators and pre-defined coefficients in technical indicators. We evaluate the performance of our prediction model with strictly backtesting on historical trading data of six futures from January 2010 to October 2017. The experiment results show that our CNN model can effectively extract more generalized and informative features than traditional technical indicators, and achieves more robust and profitable financial performance than previous machine learning approaches.
A Novel Non-Invasive Estimation of Respiration Rate from Photoplethysmograph Signal Using Machine Learning Model
Feb 18, 2021

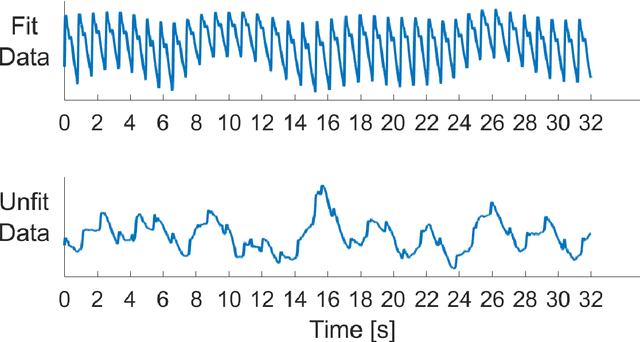
Respiratory ailments such as asthma, chronic obstructive pulmonary disease (COPD), pneumonia, and lung cancer are life-threatening. Respiration rate (RR) is a vital indicator of the wellness of a patient. Continuous monitoring of RR can provide early indication and thereby save lives. However, a real-time continuous RR monitoring facility is only available at the intensive care unit (ICU) due to the size and cost of the equipment. Recent researches have proposed Photoplethysmogram (PPG) and/ Electrocardiogram (ECG) signals for RR estimation however, the usage of ECG is limited due to the unavailability of it in wearable devices. Due to the advent of wearable smartwatches with built-in PPG sensors, it is now being considered for continuous monitoring of RR. This paper describes a novel approach to RR estimation using machine learning (ML) models with the PPG signal features. Feature selection algorithms were used to reduce computational complexity and the chance of overfitting. The best ML model and the best feature selection algorithm combination was fine-tuned to optimize its performance using hyperparameter optimization. Gaussian Process Regression (GPR) with fitrgp feature selection algorithm outperformed all other combinations and exhibits a root mean squared error (RMSE), mean absolute error (MAE), and two-standard deviation (2SD) of 2.57, 1.91, and 5.13 breaths per minute, respectively. This ML model based RR estimation can be embedded in wearable devices for real-time continuous monitoring of the patient.
ECINN: Efficient Counterfactuals from Invertible Neural Networks
Apr 05, 2021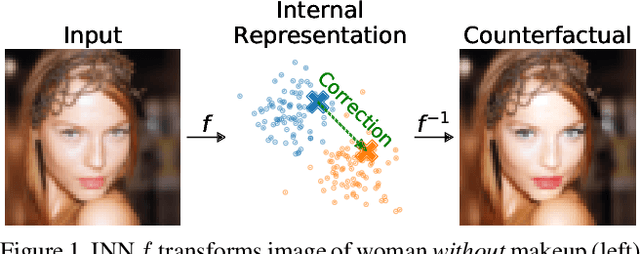
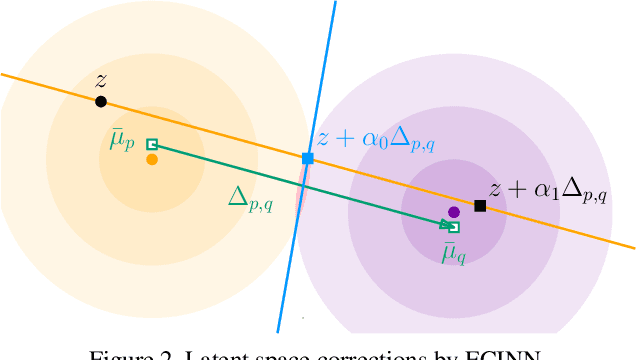

Counterfactual examples identify how inputs can be altered to change the predicted class of a classifier, thus opening up the black-box nature of, e.g., deep neural networks. We propose a method, ECINN, that utilizes the generative capacities of invertible neural networks for image classification to generate counterfactual examples efficiently. In contrast to competing methods that sometimes need a thousand evaluations or more of the classifier, ECINN has a closed-form expression and generates a counterfactual in the time of only two evaluations. Arguably, the main challenge of generating counterfactual examples is to alter only input features that affect the predicted outcome, i.e., class-dependent features. Our experiments demonstrate how ECINN alters class-dependent image regions to change the perceptual and predicted class of the counterfactuals. Additionally, we extend ECINN to also produce heatmaps (ECINNh) for easy inspection of, e.g., pairwise class-dependent changes in the generated counterfactual examples. Experimentally, we find that ECINNh outperforms established methods that generate heatmap-based explanations.
Collaborative Learning to Generate Audio-Video Jointly
Apr 01, 2021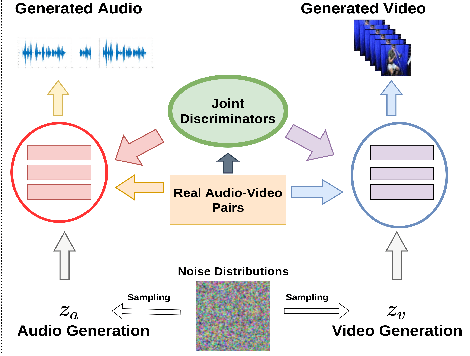

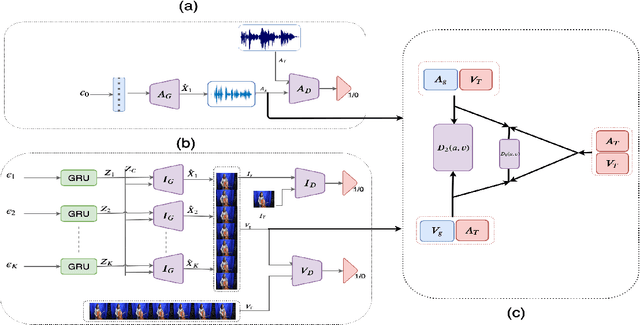

There have been a number of techniques that have demonstrated the generation of multimedia data for one modality at a time using GANs, such as the ability to generate images, videos, and audio. However, so far, the task of multi-modal generation of data, specifically for audio and videos both, has not been sufficiently well-explored. Towards this, we propose a method that demonstrates that we are able to generate naturalistic samples of video and audio data by the joint correlated generation of audio and video modalities. The proposed method uses multiple discriminators to ensure that the audio, video, and the joint output are also indistinguishable from real-world samples. We present a dataset for this task and show that we are able to generate realistic samples. This method is validated using various standard metrics such as Inception Score, Frechet Inception Distance (FID) and through human evaluation.
Modelling and Analysis of Magnetic Fields from Skeletal Muscle for Valuable Physiological Measurements
Apr 05, 2021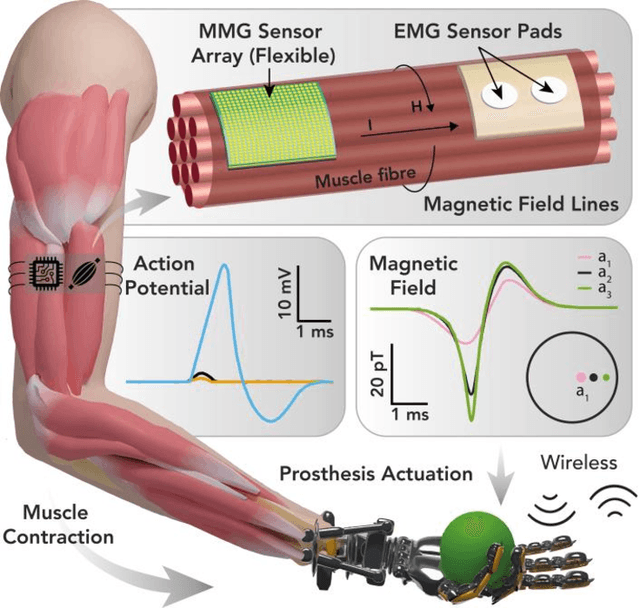

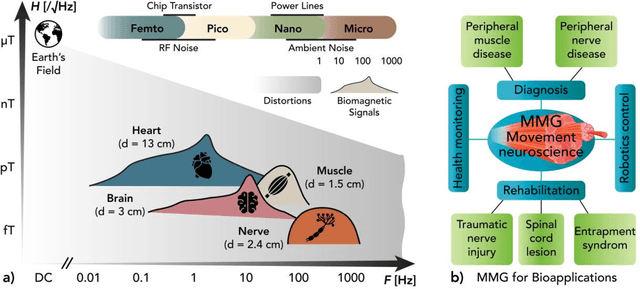

MagnetoMyoGraphy (MMG) is a method of studying muscle function via weak magnetic fields generated from human active organs and tissues. The correspondence between MMG and electromyography means directly derived from the Maxwell-Amp\`ere law. Here, upon briefly describing the principles of voltage distribution inside skeletal muscles due to the electrical stimulation, we provide a protocol to determine the effects of the magnetic field generated from a time-changing action potential propagating in a group of skeletal muscle cells. The position-dependent and the magnetic field behaviour on account of the different currents in muscle fibres are performed in temporal, spectral and spatial domains. The procedure covers identification of the fibre subpopulations inside the fascicles of a given nerve section, characterization of soleus skeletal muscle currents, check of axial intracellular currents, calculation of the generated magnetic field ultimately. We expect this protocol to take approximately 2-3 hours to complete for the whole finite-element analysis.
Modeling Users and Online Communities for Abuse Detection: A Position on Ethics and Explainability
Apr 14, 2021Abuse on the Internet is an important societal problem of our time. Millions of Internet users face harassment, racism, personal attacks, and other types of abuse across various platforms. The psychological effects of abuse on individuals can be profound and lasting. Consequently, over the past few years, there has been a substantial research effort towards automated abusive language detection in the field of NLP. In this position paper, we discuss the role that modeling of users and online communities plays in abuse detection. Specifically, we review and analyze the state of the art methods that leverage user or community information to enhance the understanding and detection of abusive language. We then explore the ethical challenges of incorporating user and community information, laying out considerations to guide future research. Finally, we address the topic of explainability in abusive language detection, proposing properties that an explainable method should aim to exhibit. We describe how user and community information can facilitate the realization of these properties and discuss the effective operationalization of explainability in view of the properties.
Multimodal Deep Learning Framework for Image Popularity Prediction on Social Media
May 18, 2021
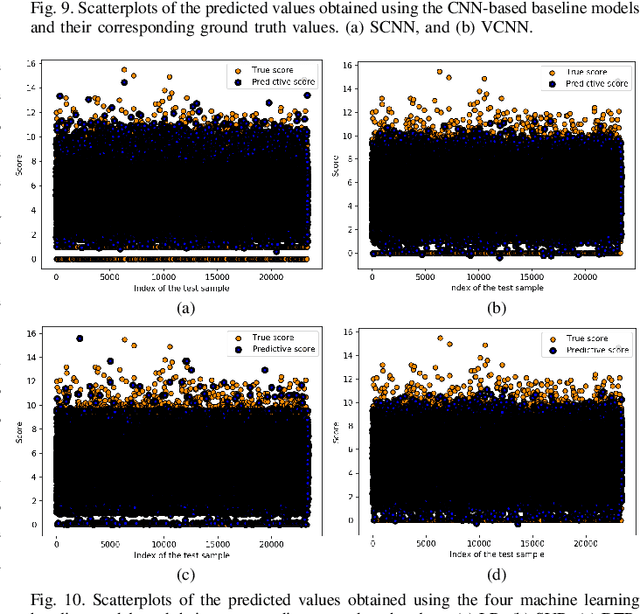
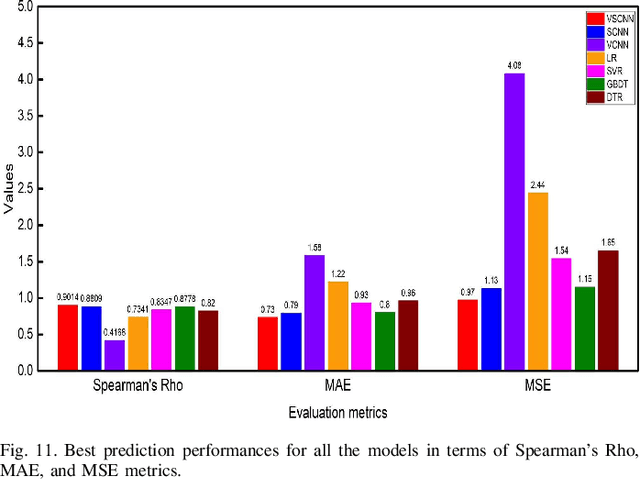
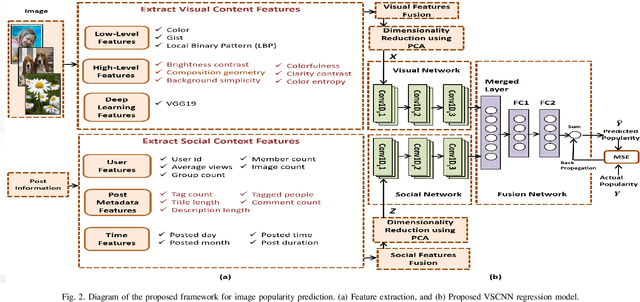
Billions of photos are uploaded to the web daily through various types of social networks. Some of these images receive millions of views and become popular, whereas others remain completely unnoticed. This raises the problem of predicting image popularity on social media. The popularity of an image can be affected by several factors, such as visual content, aesthetic quality, user, post metadata, and time. Thus, considering all these factors is essential for accurately predicting image popularity. In addition, the efficiency of the predictive model also plays a crucial role. In this study, motivated by multimodal learning, which uses information from various modalities, and the current success of convolutional neural networks (CNNs) in various fields, we propose a deep learning model, called visual-social convolutional neural network (VSCNN), which predicts the popularity of a posted image by incorporating various types of visual and social features into a unified network model. VSCNN first learns to extract high-level representations from the input visual and social features by utilizing two individual CNNs. The outputs of these two networks are then fused into a joint network to estimate the popularity score in the output layer. We assess the performance of the proposed method by conducting extensive experiments on a dataset of approximately 432K images posted on Flickr. The simulation results demonstrate that the proposed VSCNN model significantly outperforms state-of-the-art models, with a relative improvement of greater than 2.33%, 7.59%, and 14.16% in terms of Spearman's Rho, mean absolute error, and mean squared error, respectively.
* 14 pages, 11 figures, 7 tables
The Discovery of Dynamics via Linear Multistep Methods and Deep Learning: Error Estimation
Mar 21, 2021
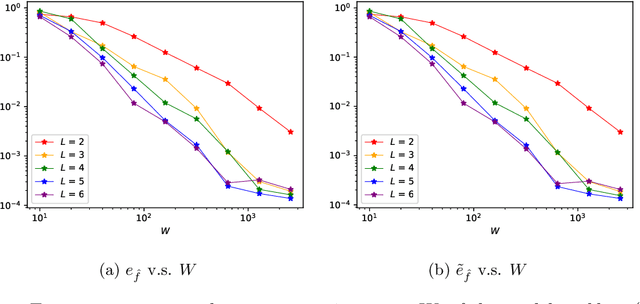
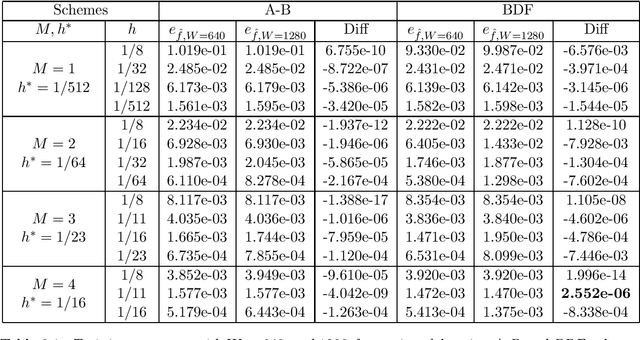
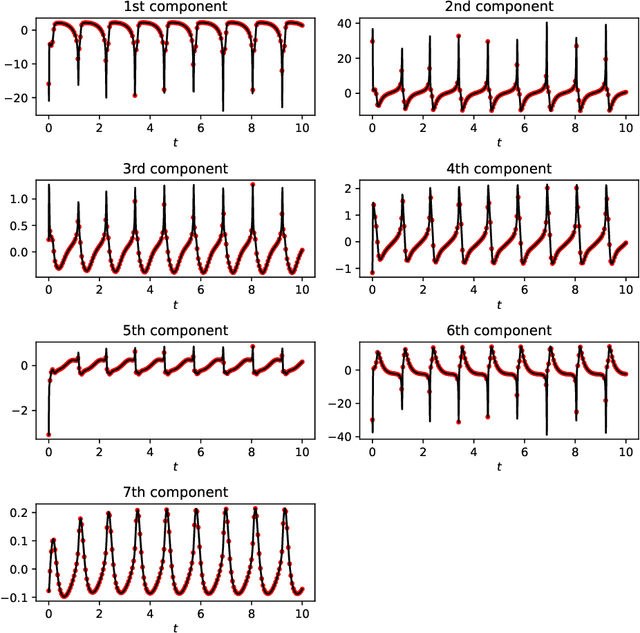
Identifying hidden dynamics from observed data is a significant and challenging task in a wide range of applications. Recently, the combination of linear multistep methods (LMMs) and deep learning has been successfully employed to discover dynamics, whereas a complete convergence analysis of this approach is still under development. In this work, we consider the deep network-based LMMs for the discovery of dynamics. We put forward error estimates for these methods using the approximation property of deep networks. It indicates, for certain families of LMMs, that the $\ell^2$ grid error is bounded by the sum of $O(h^p)$ and the network approximation error, where $h$ is the time step size and $p$ is the local truncation error order. Numerical results of several physically relevant examples are provided to demonstrate our theory.