 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Speech Emotion Representations in the Quaternion Domain
Apr 05, 2022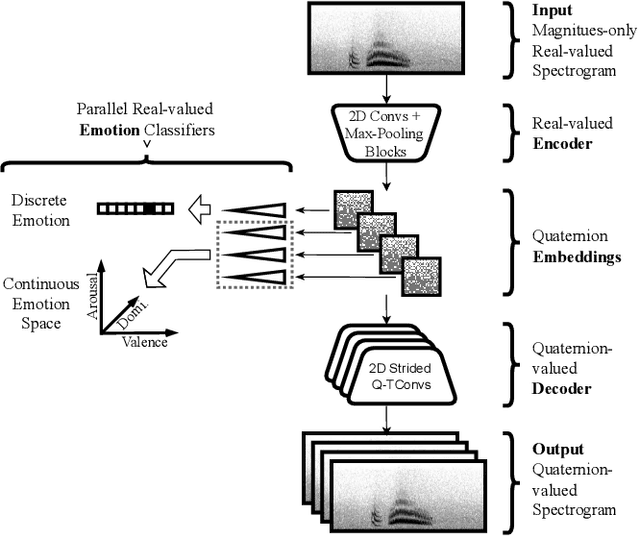
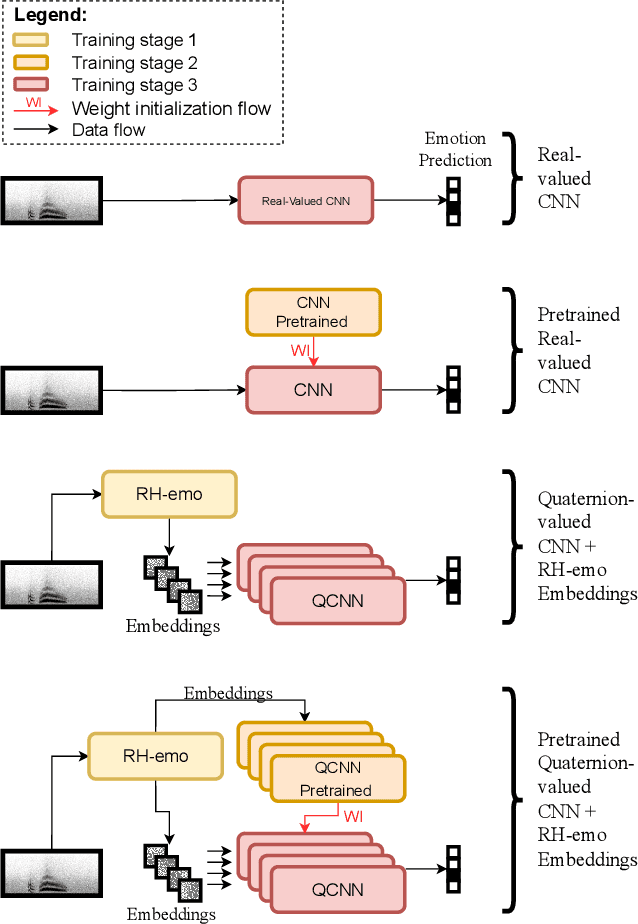
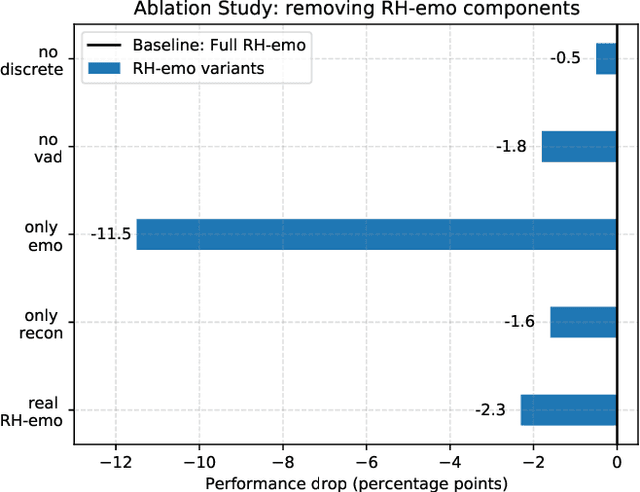
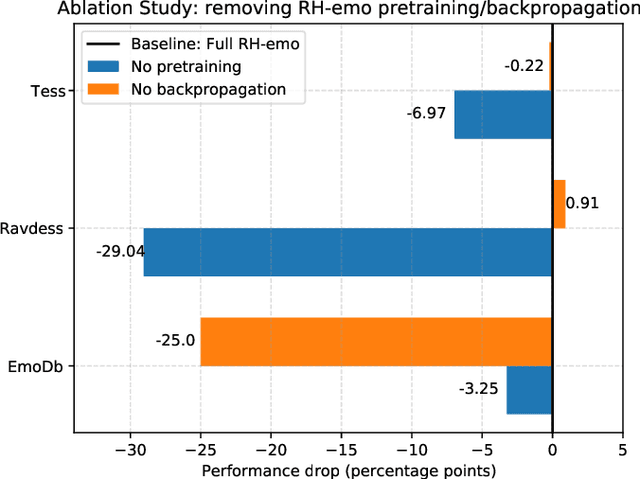
The modeling of human emotion expression in speech signals is an important, yet challenging task. The high resource demand of speech emotion recognition models, combined with the the general scarcity of emotion-labelled data are obstacles to the development and application of effective solutions in this field. In this paper, we present an approach to jointly circumvent these difficulties. Our method, named RH-emo, is a novel semi-supervised architecture aimed at extracting quaternion embeddings from real-valued monoaural spectrograms, enabling the use of quaternion-valued networks for speech emotion recognition tasks. RH-emo is a hybrid real/quaternion autoencoder network that consists of a real-valued encoder in parallel to a real-valued emotion classifier and a quaternion-valued decoder. On the one hand, the classifier permits to optimize each latent axis of the embeddings for the classification of a specific emotion-related characteristic: valence, arousal, dominance and overall emotion. On the other hand, the quaternion reconstruction enables the latent dimension to develop intra-channel correlations that are required for an effective representation as a quaternion entity. We test our approach on speech emotion recognition tasks using four popular datasets: Iemocap, Ravdess, EmoDb and Tess, comparing the performance of three well-established real-valued CNN architectures (AlexNet, ResNet-50, VGG) and their quaternion-valued equivalent fed with the embeddings created with RH-emo. We obtain a consistent improvement in the test accuracy for all datasets, while drastically reducing the resources' demand of models. Moreover, we performed additional experiments and ablation studies that confirm the effectiveness of our approach. The RH-emo repository is available at: https://github.com/ispamm/rhemo.
L3DAS22 Challenge: Learning 3D Audio Sources in a Real Office Environment
Feb 21, 2022
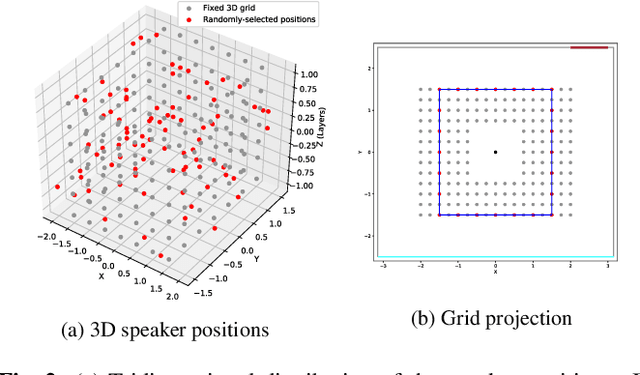
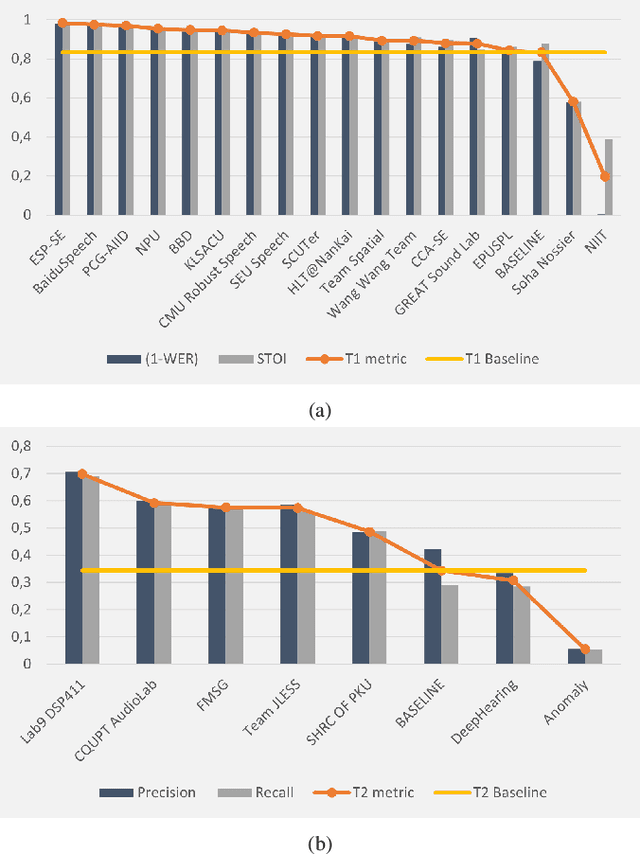
The L3DAS22 Challenge is aimed at encouraging the development of machine learning strategies for 3D speech enhancement and 3D sound localization and detection in office-like environments. This challenge improves and extends the tasks of the L3DAS21 edition. We generated a new dataset, which maintains the same general characteristics of L3DAS21 datasets, but with an extended number of data points and adding constrains that improve the baseline model's efficiency and overcome the major difficulties encountered by the participants of the previous challenge. We updated the baseline model of Task 1, using the architecture that ranked first in the previous challenge edition. We wrote a new supporting API, improving its clarity and ease-of-use. In the end, we present and discuss the results submitted by all participants. L3DAS22 Challenge website: www.l3das.com/icassp2022.
L3DAS21 Challenge: Machine Learning for 3D Audio Signal Processing
Apr 29, 2021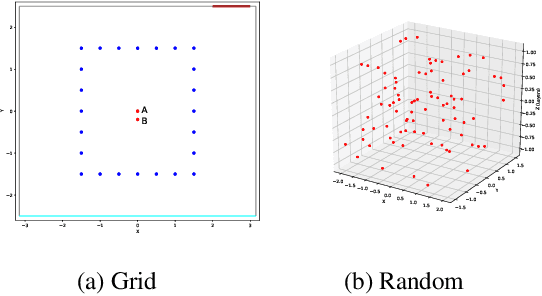
The L3DAS21 Challenge is aimed at encouraging and fostering collaborative research on machine learning for 3D audio signal processing, with particular focus on 3D speech enhancement (SE) and 3D sound localization and detection (SELD). Alongside with the challenge, we release the L3DAS21 dataset, a 65 hours 3D audio corpus, accompanied with a Python API that facilitates the data usage and results submission stage. Usually, machine learning approaches to 3D audio tasks are based on single-perspective Ambisonics recordings or on arrays of single-capsule microphones. We propose, instead, a novel multichannel audio configuration based multiple-source and multiple-perspective Ambisonics recordings, performed with an array of two first-order Ambisonics microphones. To the best of our knowledge, it is the first time that a dual-mic Ambisonics configuration is used for these tasks. We provide baseline models and results for both tasks, obtained with state-of-the-art architectures: FaSNet for SE and SELDNet for SELD. This report is aimed at providing all needed information to participate in the L3DAS21 Challenge, illustrating the details of the L3DAS21 dataset, the challenge tasks and the baseline models.
Blissful Ignorance: Anti-Transfer Learning for Task Invariance
Jun 11, 2020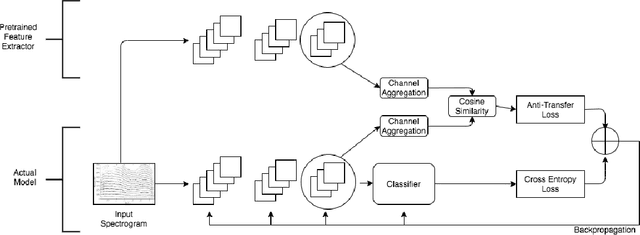

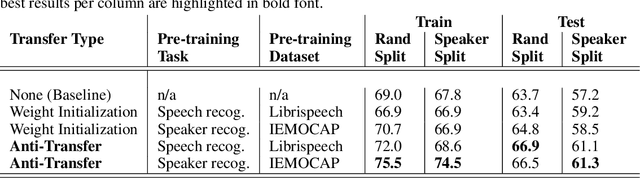
We introduce the novel concept of anti-transfer learning for neural networks. While standard transfer learning assumes that the representations learned in one task will be useful for another task, anti-transfer learning avoids learning representations that have been learned for a different task, which is not relevant and potentially misleading for the new task and should be ignored. Examples of such tasks are style vs content recognition or pitch vs timbre from audio. By penalizing similarity between the second network and the previously learned features, co-incidental correlations between the target and the unrelated task can be avoided, yielding more reliable representations and better performance on the target task. We implemented anti-transfer learning with different similarity metrics and aggregation functions. We evaluate the approach in the audio domain with different tasks and setups, using four datasets in total. The results show that anti-transfer learning consistently improves accuracy in all test cases, proving that it can push the network to learn more representative features for the task at hand.
Multi-Time-Scale Convolution for Emotion Recognition from Speech Audio Signals
Mar 06, 2020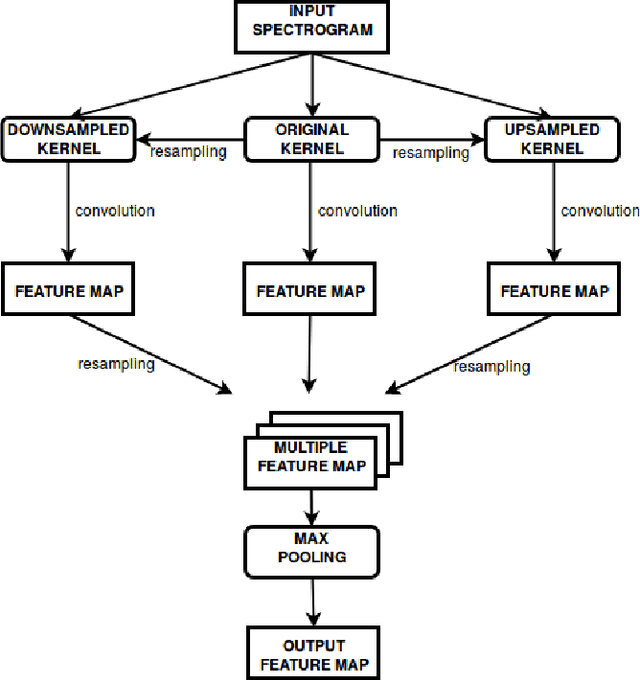
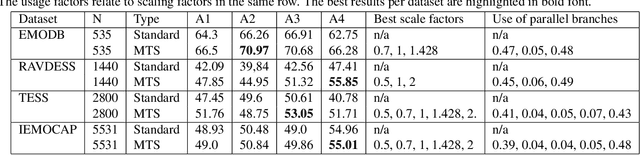
Robustness against temporal variations is important for emotion recognition from speech audio, since emotion is ex-pressed through complex spectral patterns that can exhibit significant local dilation and compression on the time axis depending on speaker and context. To address this and potentially other tasks, we introduce the multi-time-scale (MTS) method to create flexibility towards temporal variations when analyzing time-frequency representations of audio data. MTS extends convolutional neural networks with convolution kernels that are scaled and re-sampled along the time axis, to increase temporal flexibility without increasing the number of trainable parameters compared to standard convolutional layers. We evaluate MTS and standard convolutional layers in different architectures for emotion recognition from speech audio, using 4 datasets of different sizes. The results show that the use of MTS layers consistently improves the generalization of networks of different capacity and depth, compared to standard convolution, especially on smaller datasets