 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Guided Semantic Bootstrapping for Interpretable Text Classification with Tsetlin Machines
Apr 14, 2026Pretrained language models (PLMs) like BERT provide strong semantic representations but are costly and opaque, while symbolic models such as the Tsetlin Machine (TM) offer transparency but lack semantic generalization. We propose a semantic bootstrapping framework that transfers LLM knowledge into symbolic form, combining interpretability with semantic capacity. Given a class label, an LLM generates sub-intents that guide synthetic data creation through a three-stage curriculum (seed, core, enriched), expanding semantic diversity. A Non-Negated TM (NTM) learns from these examples to extract high-confidence literals as interpretable semantic cues. Injecting these cues into real data enables a TM to align clause logic with LLM-inferred semantics. Our method requires no embeddings or runtime LLM calls, yet equips symbolic models with pretrained semantic priors. Across multiple text classification tasks, it improves interpretability and accuracy over vanilla TM, achieving performance comparable to BERT while remaining fully symbolic and efficient.
Pruning Literals for Highly Efficient Explainability at Word Level
Nov 07, 2024



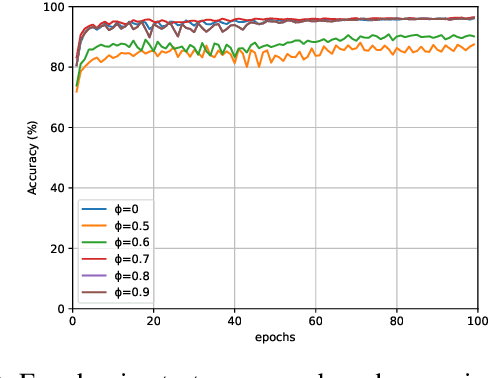
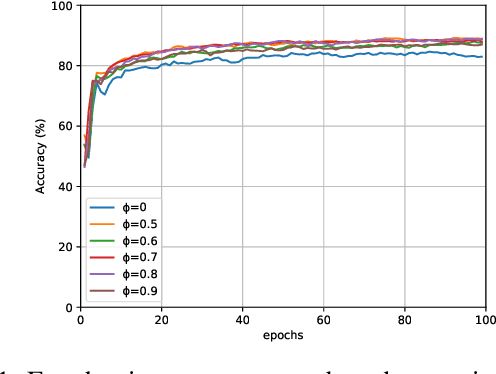
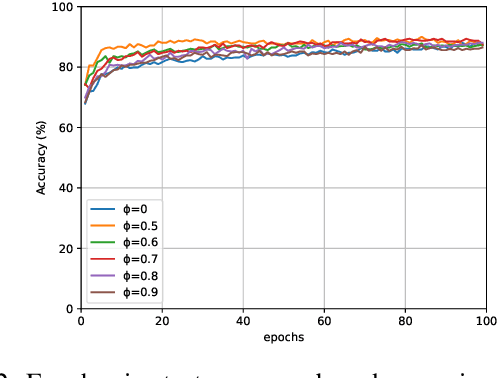
Designing an explainable model becomes crucial now for Natural Language Processing(NLP) since most of the state-of-the-art machine learning models provide a limited explanation for the prediction. In the spectrum of an explainable model, Tsetlin Machine(TM) is promising because of its capability of providing word-level explanation using proposition logic. However, concern rises over the elaborated combination of literals (propositional logic) in the clause that makes the model difficult for humans to comprehend, despite having a transparent learning process. In this paper, we design a post-hoc pruning of clauses that eliminate the randomly placed literals in the clause thereby making the model more efficiently interpretable than the vanilla TM. Experiments on the publicly available YELP-HAT Dataset demonstrate that the proposed pruned TM's attention map aligns more with the human attention map than the vanilla TM's attention map. In addition, the pairwise similarity measure also surpasses the attention map-based neural network models. In terms of accuracy, the proposed pruning method does not degrade the accuracy significantly but rather enhances the performance up to 4% to 9% in some test data.
* 8 pages, 3 figures
Distributed Word Representation in Tsetlin Machine
Apr 14, 2021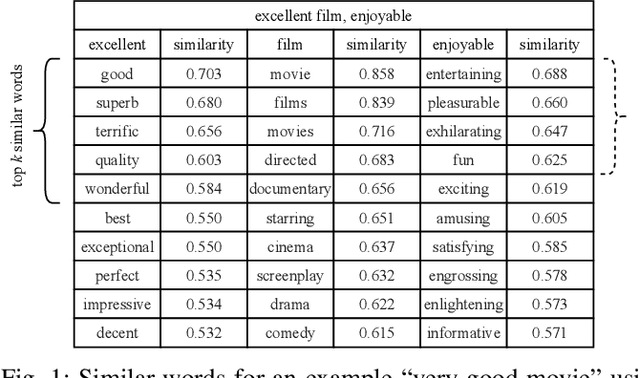
Tsetlin Machine (TM) is an interpretable pattern recognition algorithm based on propositional logic. The algorithm has demonstrated competitive performance in many Natural Language Processing (NLP) tasks, including sentiment analysis, text classification, and Word Sense Disambiguation (WSD). To obtain human-level interpretability, legacy TM employs Boolean input features such as bag-of-words (BOW). However, the BOW representation makes it difficult to use any pre-trained information, for instance, word2vec and GloVe word representations. This restriction has constrained the performance of TM compared to deep neural networks (DNNs) in NLP. To reduce the performance gap, in this paper, we propose a novel way of using pre-trained word representations for TM. The approach significantly enhances the TM performance and maintains interpretability at the same time. We achieve this by extracting semantically related words from pre-trained word representations as input features to the TM. Our experiments show that the accuracy of the proposed approach is significantly higher than the previous BOW-based TM, reaching the level of DNN-based models.