 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Attribute Bias Mitigation via Representation Learning
Sep 03, 2025Real world images frequently exhibit multiple overlapping biases, including textures, watermarks, gendered makeup, scene object pairings, etc. These biases collectively impair the performance of modern vision models, undermining both their robustness and fairness. Addressing these biases individually proves inadequate, as mitigating one bias often permits or intensifies others. We tackle this multi bias problem with Generalized Multi Bias Mitigation (GMBM), a lean two stage framework that needs group labels only while training and minimizes bias at test time. First, Adaptive Bias Integrated Learning (ABIL) deliberately identifies the influence of known shortcuts by training encoders for each attribute and integrating them with the main backbone, compelling the classifier to explicitly recognize these biases. Then Gradient Suppression Fine Tuning prunes those very bias directions from the backbone's gradients, leaving a single compact network that ignores all the shortcuts it just learned to recognize. Moreover we find that existing bias metrics break under subgroup imbalance and train test distribution shifts, so we introduce Scaled Bias Amplification (SBA): a test time measure that disentangles model induced bias amplification from distributional differences. We validate GMBM on FB CMNIST, CelebA, and COCO, where we boost worst group accuracy, halve multi attribute bias amplification, and set a new low in SBA even as bias complexity and distribution shifts intensify, making GMBM the first practical, end to end multibias solution for visual recognition. Project page: http://visdomlab.github.io/GMBM/
Strategic Base Representation Learning via Feature Augmentations for Few-Shot Class Incremental Learning
Jan 16, 2025Few-shot class incremental learning implies the model to learn new classes while retaining knowledge of previously learned classes with a small number of training instances. Existing frameworks typically freeze the parameters of the previously learned classes during the incorporation of new classes. However, this approach often results in suboptimal class separation of previously learned classes, leading to overlap between old and new classes. Consequently, the performance of old classes degrades on new classes. To address these challenges, we propose a novel feature augmentation driven contrastive learning framework designed to enhance the separation of previously learned classes to accommodate new classes. Our approach involves augmenting feature vectors and assigning proxy labels to these vectors. This strategy expands the feature space, ensuring seamless integration of new classes within the expanded space. Additionally, we employ a self-supervised contrastive loss to improve the separation between previous classes. We validate our framework through experiments on three FSCIL benchmark datasets: CIFAR100, miniImageNet, and CUB200. The results demonstrate that our Feature Augmentation driven Contrastive Learning framework significantly outperforms other approaches, achieving state-of-the-art performance.
Label Calibration in Source Free Domain Adaptation
Jan 13, 2025



Source-free domain adaptation (SFDA) utilizes a pre-trained source model with unlabeled target data. Self-supervised SFDA techniques generate pseudolabels from the pre-trained source model, but these pseudolabels often contain noise due to domain discrepancies between the source and target domains. Traditional self-supervised SFDA techniques rely on deterministic model predictions using the softmax function, leading to unreliable pseudolabels. In this work, we propose to introduce predictive uncertainty and softmax calibration for pseudolabel refinement using evidential deep learning. The Dirichlet prior is placed over the output of the target network to capture uncertainty using evidence with a single forward pass. Furthermore, softmax calibration solves the translation invariance problem to assist in learning with noisy labels. We incorporate a combination of evidential deep learning loss and information maximization loss with calibrated softmax in both prior and non-prior target knowledge SFDA settings. Extensive experimental analysis shows that our method outperforms other state-of-the-art methods on benchmark datasets.
CosFairNet:A Parameter-Space based Approach for Bias Free Learning
Oct 19, 2024Deep neural networks trained on biased data often inadvertently learn unintended inference rules, particularly when labels are strongly correlated with biased features. Existing bias mitigation methods typically involve either a) predefining bias types and enforcing them as prior knowledge or b) reweighting training samples to emphasize bias-conflicting samples over bias-aligned samples. However, both strategies address bias indirectly in the feature or sample space, with no control over learned weights, making it difficult to control the bias propagation across different layers. Based on this observation, we introduce a novel approach to address bias directly in the model's parameter space, preventing its propagation across layers. Our method involves training two models: a bias model for biased features and a debias model for unbiased details, guided by the bias model. We enforce dissimilarity in the debias model's later layers and similarity in its initial layers with the bias model, ensuring it learns unbiased low-level features without adopting biased high-level abstractions. By incorporating this explicit constraint during training, our approach shows enhanced classification accuracy and debiasing effectiveness across various synthetic and real-world datasets of different sizes. Moreover, the proposed method demonstrates robustness across different bias types and percentages of biased samples in the training data. The code is available at: https://visdomlab.github.io/CosFairNet/
Towards Robust Few-shot Class Incremental Learning in Audio Classification using Contrastive Representation
Jul 27, 2024



In machine learning applications, gradual data ingress is common, especially in audio processing where incremental learning is vital for real-time analytics. Few-shot class-incremental learning addresses challenges arising from limited incoming data. Existing methods often integrate additional trainable components or rely on a fixed embedding extractor post-training on base sessions to mitigate concerns related to catastrophic forgetting and the dangers of model overfitting. However, using cross-entropy loss alone during base session training is suboptimal for audio data. To address this, we propose incorporating supervised contrastive learning to refine the representation space, enhancing discriminative power and leading to better generalization since it facilitates seamless integration of incremental classes, upon arrival. Experimental results on NSynth and LibriSpeech datasets with 100 classes, as well as ESC dataset with 50 and 10 classes, demonstrate state-of-the-art performance.
Gradient Based Activations for Accurate Bias-Free Learning
Feb 17, 2022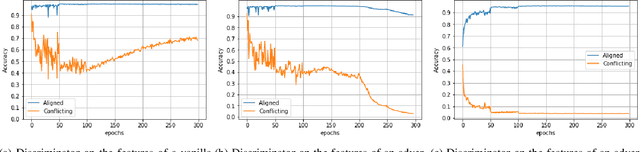

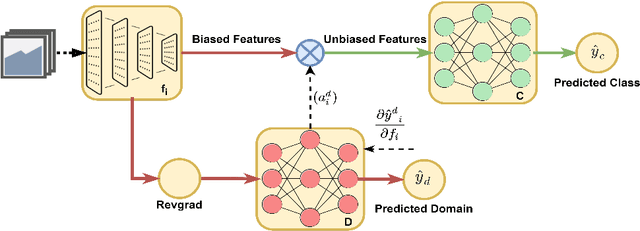

Bias mitigation in machine learning models is imperative, yet challenging. While several approaches have been proposed, one view towards mitigating bias is through adversarial learning. A discriminator is used to identify the bias attributes such as gender, age or race in question. This discriminator is used adversarially to ensure that it cannot distinguish the bias attributes. The main drawback in such a model is that it directly introduces a trade-off with accuracy as the features that the discriminator deems to be sensitive for discrimination of bias could be correlated with classification. In this work we solve the problem. We show that a biased discriminator can actually be used to improve this bias-accuracy tradeoff. Specifically, this is achieved by using a feature masking approach using the discriminator's gradients. We ensure that the features favoured for the bias discrimination are de-emphasized and the unbiased features are enhanced during classification. We show that this simple approach works well to reduce bias as well as improve accuracy significantly. We evaluate the proposed model on standard benchmarks. We improve the accuracy of the adversarial methods while maintaining or even improving the unbiasness and also outperform several other recent methods.
Exploring Dropout Discriminator for Domain Adaptation
Jul 09, 2021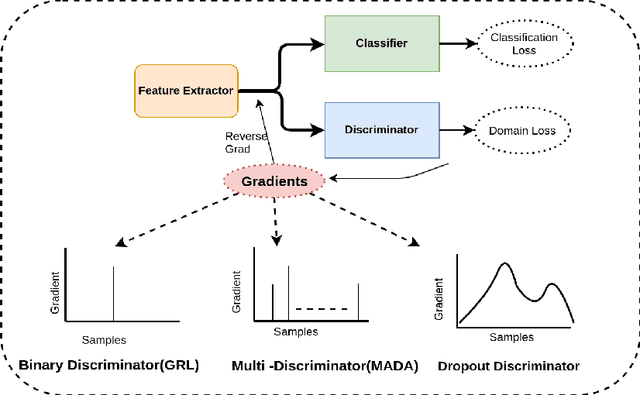
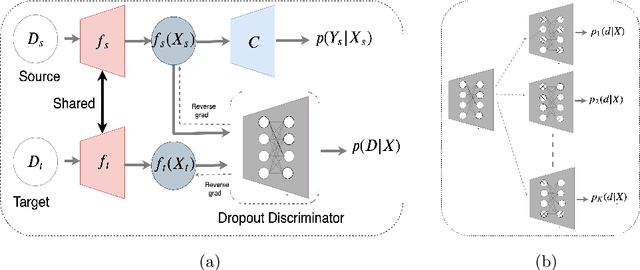
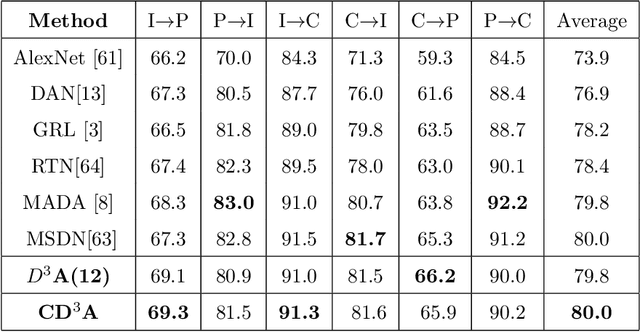
Adaptation of a classifier to new domains is one of the challenging problems in machine learning. This has been addressed using many deep and non-deep learning based methods. Among the methodologies used, that of adversarial learning is widely applied to solve many deep learning problems along with domain adaptation. These methods are based on a discriminator that ensures source and target distributions are close. However, here we suggest that rather than using a point estimate obtaining by a single discriminator, it would be useful if a distribution based on ensembles of discriminators could be used to bridge this gap. This could be achieved using multiple classifiers or using traditional ensemble methods. In contrast, we suggest that a Monte Carlo dropout based ensemble discriminator could suffice to obtain the distribution based discriminator. Specifically, we propose a curriculum based dropout discriminator that gradually increases the variance of the sample based distribution and the corresponding reverse gradients are used to align the source and target feature representations. An ensemble of discriminators helps the model to learn the data distribution efficiently. It also provides a better gradient estimates to train the feature extractor. The detailed results and thorough ablation analysis show that our model outperforms state-of-the-art results.
Sensor-invariant Fingerprint ROI Segmentation Using Recurrent Adversarial Learning
Jul 03, 2021
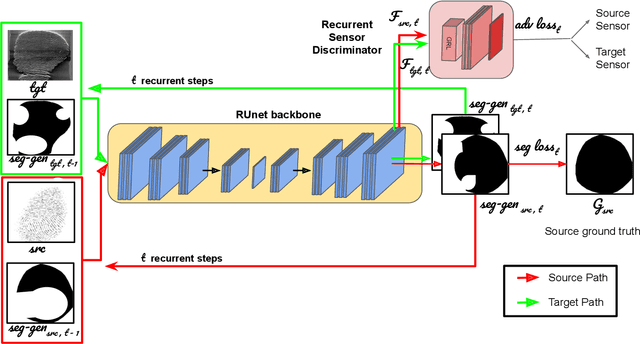

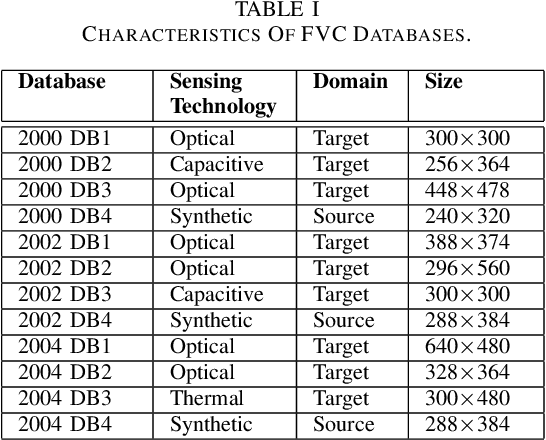
A fingerprint region of interest (roi) segmentation algorithm is designed to separate the foreground fingerprint from the background noise. All the learning based state-of-the-art fingerprint roi segmentation algorithms proposed in the literature are benchmarked on scenarios when both training and testing databases consist of fingerprint images acquired from the same sensors. However, when testing is conducted on a different sensor, the segmentation performance obtained is often unsatisfactory. As a result, every time a new fingerprint sensor is used for testing, the fingerprint roi segmentation model needs to be re-trained with the fingerprint image acquired from the new sensor and its corresponding manually marked ROI. Manually marking fingerprint ROI is expensive because firstly, it is time consuming and more importantly, requires domain expertise. In order to save the human effort in generating annotations required by state-of-the-art, we propose a fingerprint roi segmentation model which aligns the features of fingerprint images derived from the unseen sensor such that they are similar to the ones obtained from the fingerprints whose ground truth roi masks are available for training. Specifically, we propose a recurrent adversarial learning based feature alignment network that helps the fingerprint roi segmentation model to learn sensor-invariant features. Consequently, sensor-invariant features learnt by the proposed roi segmentation model help it to achieve improved segmentation performance on fingerprints acquired from the new sensor. Experiments on publicly available FVC databases demonstrate the efficacy of the proposed work.
* IJCNN 2021 (Accepted)
Data Uncertainty Guided Noise-aware Preprocessing Of Fingerprints
Jul 02, 2021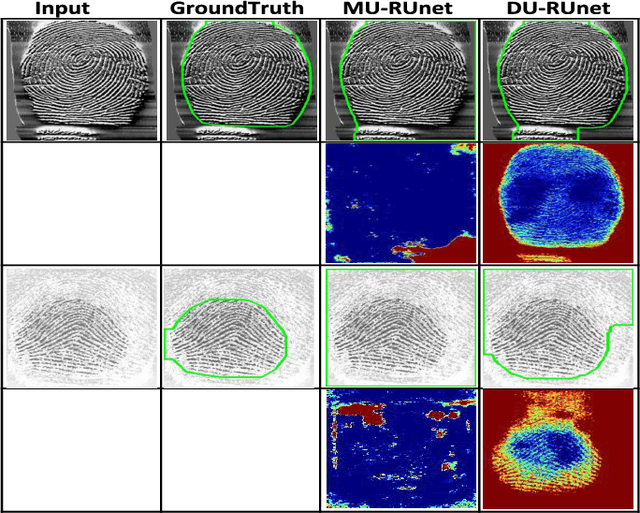
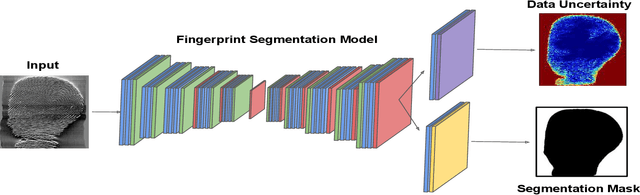
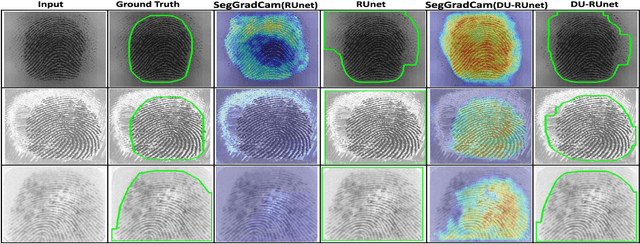

The effectiveness of fingerprint-based authentication systems on good quality fingerprints is established long back. However, the performance of standard fingerprint matching systems on noisy and poor quality fingerprints is far from satisfactory. Towards this, we propose a data uncertainty-based framework which enables the state-of-the-art fingerprint preprocessing models to quantify noise present in the input image and identify fingerprint regions with background noise and poor ridge clarity. Quantification of noise helps the model two folds: firstly, it makes the objective function adaptive to the noise in a particular input fingerprint and consequently, helps to achieve robust performance on noisy and distorted fingerprint regions. Secondly, it provides a noise variance map which indicates noisy pixels in the input fingerprint image. The predicted noise variance map enables the end-users to understand erroneous predictions due to noise present in the input image. Extensive experimental evaluation on 13 publicly available fingerprint databases, across different architectural choices and two fingerprint processing tasks demonstrate effectiveness of the proposed framework.
Collaborative Learning to Generate Audio-Video Jointly
Apr 01, 2021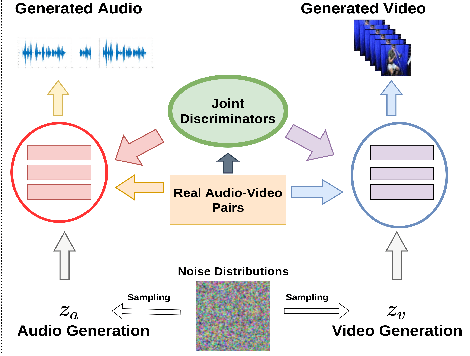

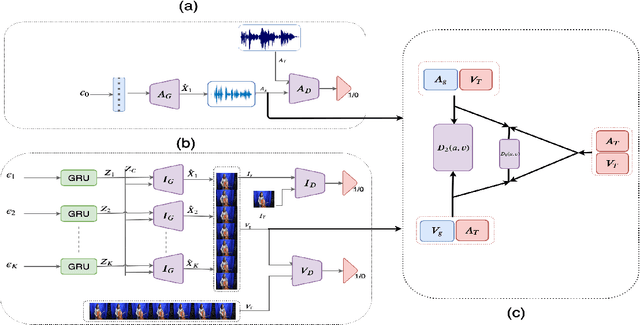

There have been a number of techniques that have demonstrated the generation of multimedia data for one modality at a time using GANs, such as the ability to generate images, videos, and audio. However, so far, the task of multi-modal generation of data, specifically for audio and videos both, has not been sufficiently well-explored. Towards this, we propose a method that demonstrates that we are able to generate naturalistic samples of video and audio data by the joint correlated generation of audio and video modalities. The proposed method uses multiple discriminators to ensure that the audio, video, and the joint output are also indistinguishable from real-world samples. We present a dataset for this task and show that we are able to generate realistic samples. This method is validated using various standard metrics such as Inception Score, Frechet Inception Distance (FID) and through human evaluation.