 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Task Learning for Scalable and Dense Multi-Layer Bayesian Map Inference
Jun 28, 2021
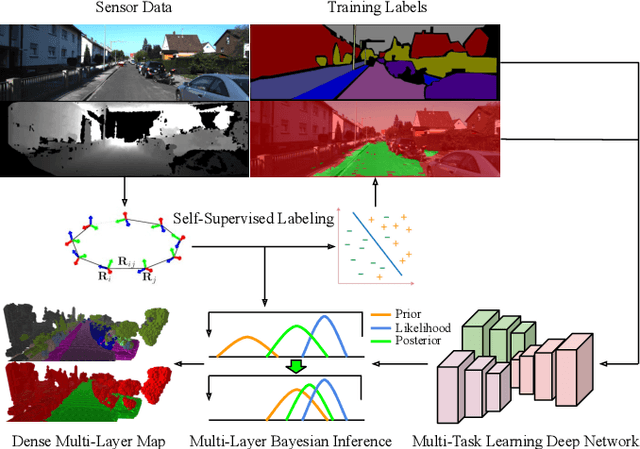
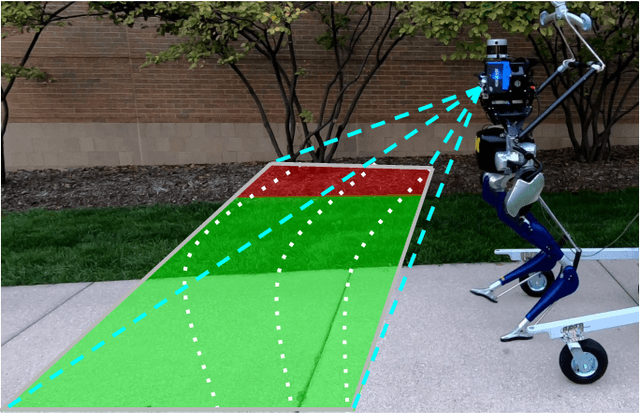


This paper presents a novel and flexible multi-task multi-layer Bayesian mapping framework with readily extendable attribute layers. The proposed framework goes beyond modern metric-semantic maps to provide even richer environmental information for robots in a single mapping formalism while exploiting existing inter-layer correlations. It removes the need for a robot to access and process information from many separate maps when performing a complex task and benefits from the correlation between map layers, advancing the way robots interact with their environments. To this end, we design a multi-task deep neural network with attention mechanisms as our front-end to provide multiple observations for multiple map layers simultaneously. Our back-end runs a scalable closed-form Bayesian inference with only logarithmic time complexity. We apply the framework to build a dense robotic map including metric-semantic occupancy and traversability layers. Traversability ground truth labels are automatically generated from exteroceptive sensory data in a self-supervised manner. We present extensive experimental results on publicly available data sets and data collected by a 3D bipedal robot platform on the University of Michigan North Campus and show reliable mapping performance in different environments. Finally, we also discuss how the current framework can be extended to incorporate more information such as friction, signal strength, temperature, and physical quantity concentration using Gaussian map layers. The software for reproducing the presented results or running on customized data is made publicly available.
Measuring and Increasing Context Usage in Context-Aware Machine Translation
Jun 02, 2021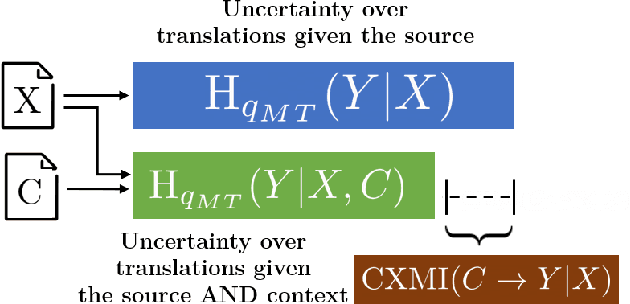

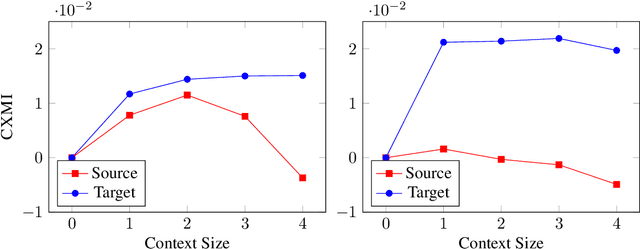
Recent work in neural machine translation has demonstrated both the necessity and feasibility of using inter-sentential context -- context from sentences other than those currently being translated. However, while many current methods present model architectures that theoretically can use this extra context, it is often not clear how much they do actually utilize it at translation time. In this paper, we introduce a new metric, conditional cross-mutual information, to quantify the usage of context by these models. Using this metric, we measure how much document-level machine translation systems use particular varieties of context. We find that target context is referenced more than source context, and that conditioning on a longer context has a diminishing effect on results. We then introduce a new, simple training method, context-aware word dropout, to increase the usage of context by context-aware models. Experiments show that our method increases context usage and that this reflects on the translation quality according to metrics such as BLEU and COMET, as well as performance on anaphoric pronoun resolution and lexical cohesion contrastive datasets.
Lossless compression with state space models using bits back coding
Mar 19, 2021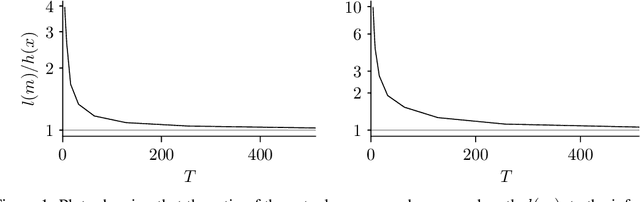
We generalize the 'bits back with ANS' method to time-series models with a latent Markov structure. This family of models includes hidden Markov models (HMMs), linear Gaussian state space models (LGSSMs) and many more. We provide experimental evidence that our method is effective for small scale models, and discuss its applicability to larger scale settings such as video compression.
John praised Mary because he? Implicit Causality Bias and Its Interaction with Explicit Cues in LMs
Jun 02, 2021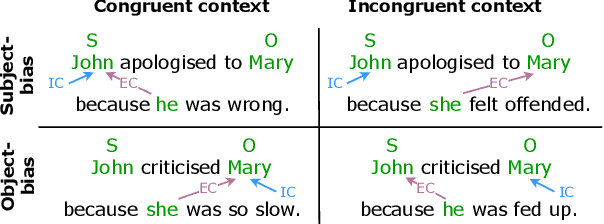
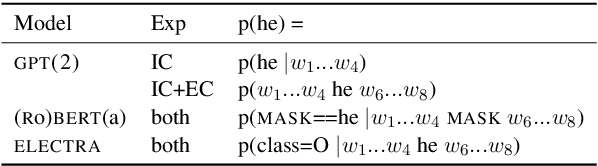
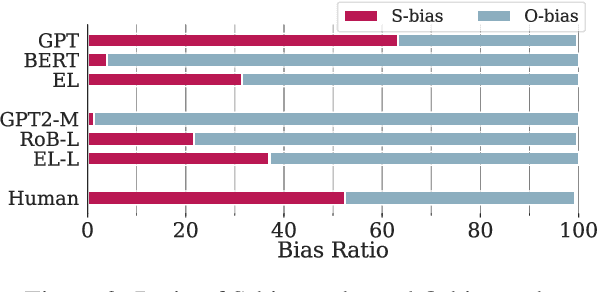
Some interpersonal verbs can implicitly attribute causality to either their subject or their object and are therefore said to carry an implicit causality (IC) bias. Through this bias, causal links can be inferred from a narrative, aiding language comprehension. We investigate whether pre-trained language models (PLMs) encode IC bias and use it at inference time. We find that to be the case, albeit to different degrees, for three distinct PLM architectures. However, causes do not always need to be implicit -- when a cause is explicitly stated in a subordinate clause, an incongruent IC bias associated with the verb in the main clause leads to a delay in human processing. We hypothesize that the temporary challenge humans face in integrating the two contradicting signals, one from the lexical semantics of the verb, one from the sentence-level semantics, would be reflected in higher error rates for models on tasks dependent on causal links. The results of our study lend support to this hypothesis, suggesting that PLMs tend to prioritize lexical patterns over higher-order signals.
A Raspberry Pi based Traumatic Brain Injury Detection System for Single-Channel Electroencephalogram
Jan 23, 2021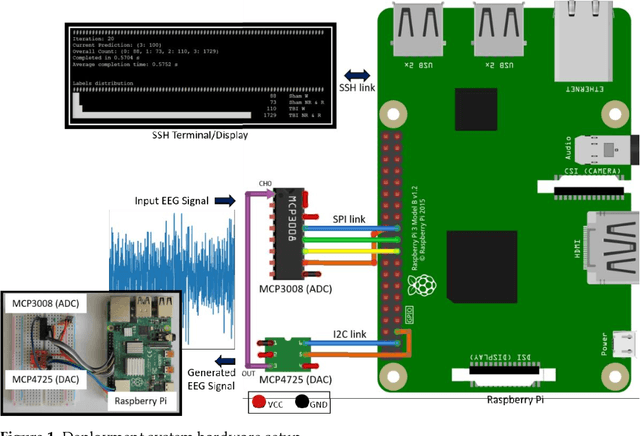
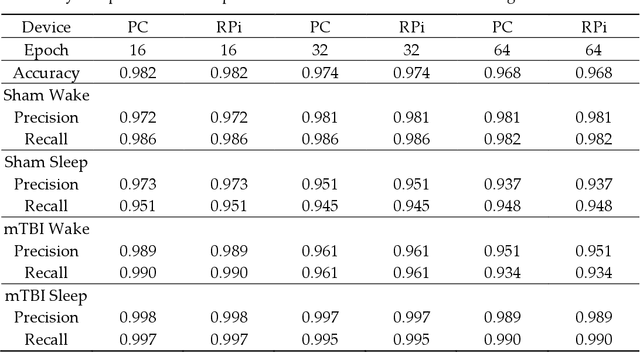
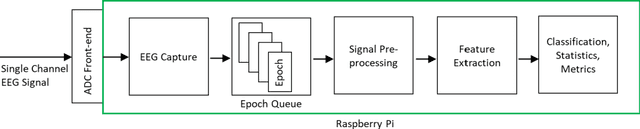
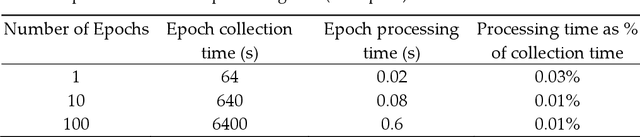
Traumatic Brain Injury (TBI) is a common cause of death and disability. However, existing tools for TBI diagnosis are either subjective or require extensive clinical setup and expertise. The increasing affordability and reduction in size of relatively high-performance computing systems combined with promising results from TBI related machine learning research make it possible to create compact and portable systems for early detection of TBI. This work describes a Raspberry Pi based portable, real-time data acquisition, and automated processing system that uses machine learning to efficiently identify TBI and automatically score sleep stages from a single-channel Electroen-cephalogram (EEG) signal. We discuss the design, implementation, and verification of the system that can digitize EEG signal using an Analog to Digital Converter (ADC) and perform real-time signal classification to detect the presence of mild TBI (mTBI). We utilize Convolutional Neural Networks (CNN) and XGBoost based predictive models to evaluate the performance and demonstrate the versatility of the system to operate with multiple types of predictive models. We achieve a peak classification accuracy of more than 90% with a classification time of less than 1 s across 16 s - 64 s epochs for TBI vs control conditions. This work can enable development of systems suitable for field use without requiring specialized medical equipment for early TBI detection applications and TBI research. Further, this work opens avenues to implement connected, real-time TBI related health and wellness monitoring systems.
Toward Robotic Weed Control: Detection of Nutsedge Weed in Bermudagrass Turf Using Inaccurate and Insufficient Training Data
Jun 16, 2021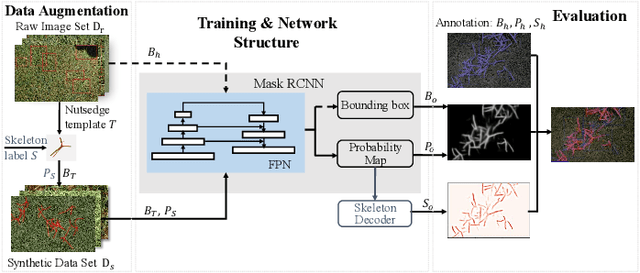
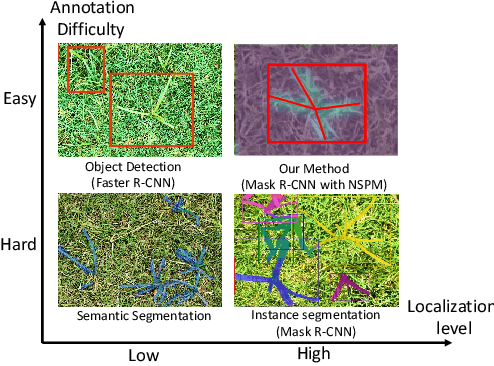
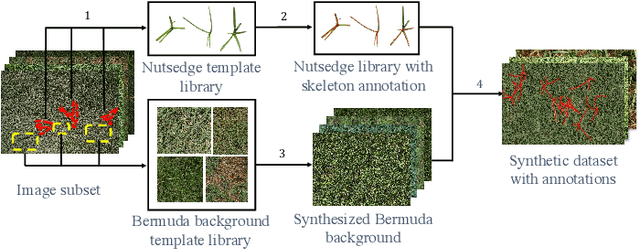

To enable robotic weed control, we develop algorithms to detect nutsedge weed from bermudagrass turf. Due to the similarity between the weed and the background turf, manual data labeling is expensive and error-prone. Consequently, directly applying deep learning methods for object detection cannot generate satisfactory results. Building on an instance detection approach (i.e. Mask R-CNN), we combine synthetic data with raw data to train the network. We propose an algorithm to generate high fidelity synthetic data, adopting different levels of annotations to reduce labeling cost. Moreover, we construct a nutsedge skeleton-based probabilistic map (NSPM) as the neural network input to reduce the reliance on pixel-wise precise labeling. We also modify loss function from cross entropy to Kullback-Leibler divergence which accommodates uncertainty in the labeling process. We implement the proposed algorithm and compare it with both Faster R-CNN and Mask R-CNN. The results show that our design can effectively overcome the impact of imprecise and insufficient training sample issues and significantly outperform the Faster R-CNN counterpart with a false negative rate of only 0.4%. In particular, our approach also reduces labeling time by 95% while achieving better performance if comparing with the original Mask R-CNN approach.
Real-time CPU-based large-scale 3D mesh reconstruction
Jan 16, 2018
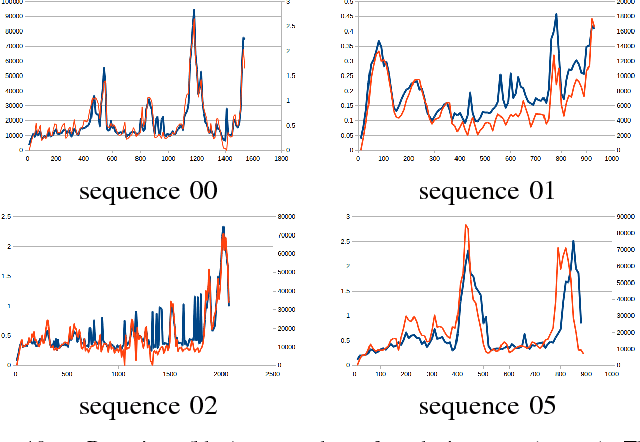
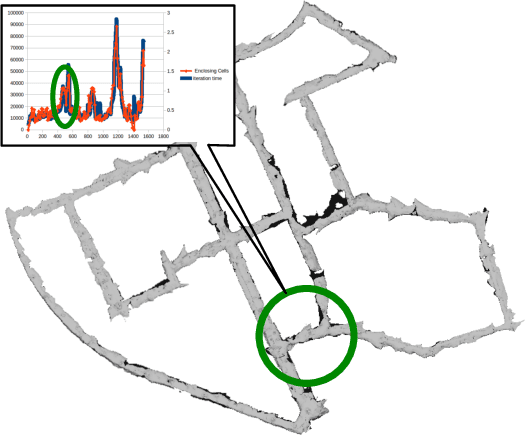
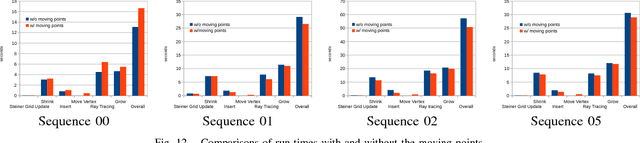
In Robotics, especially in this era of autonomous driving, mapping is one key ability of a robot to be able to navigate through an environment, localize on it and analyze its traversability. To allow for real-time execution on constrained hardware, the map usually estimated by feature-based or semi-dense SLAM algorithms is a sparse point cloud; a richer and more complete representation of the environment is desirable. Existing dense mapping algorithms require extensive use of GPU computing and they hardly scale to large environments; incremental algorithms from sparse points still represent an effective solution when light computational effort is needed and big sequences have to be processed in real-time. In this paper we improved and extended the state of the art incremental manifold mesh algorithm proposed in [1] and extended in [2]. While these algorithms do not achieve real-time and they embed points from SLAM or Structure from Motion only when their position is fixed, in this paper we propose the first incremental algorithm able to reconstruct a manifold mesh in real-time through single core CPU processing which is also able to modify the mesh according to 3D points updates from the underlying SLAM algorithm. We tested our algorithm against two state of the art incremental mesh mapping systems on the KITTI dataset, and we showed that, while accuracy is comparable, our approach is able to reach real-time performances thanks to an order of magnitude speed-up.
A Comparative Analysis of Forecasting Financial Time Series Using ARIMA, LSTM, and BiLSTM
Nov 21, 2019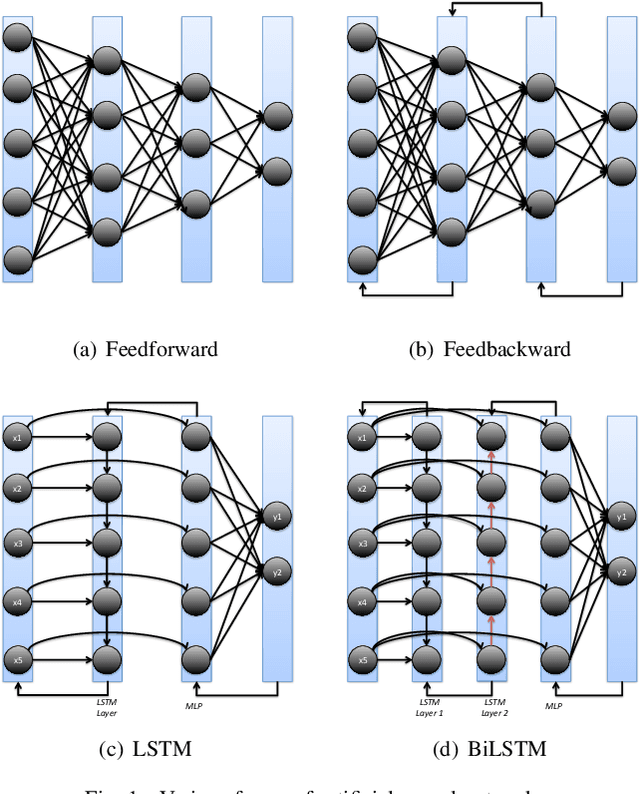
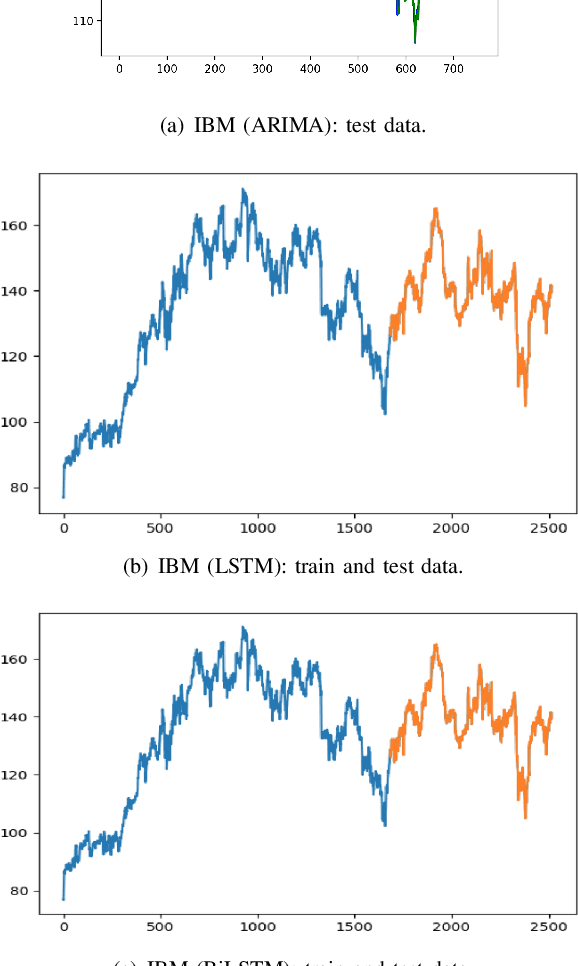
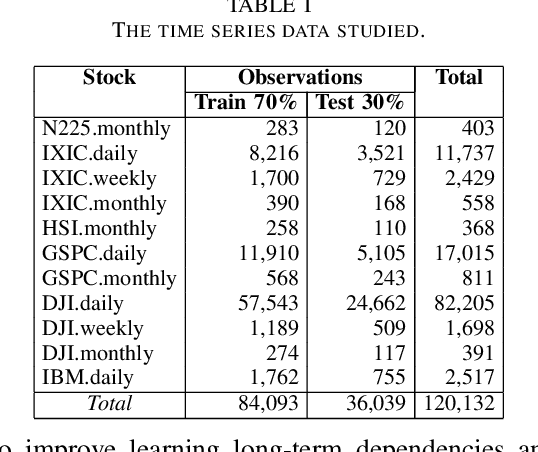
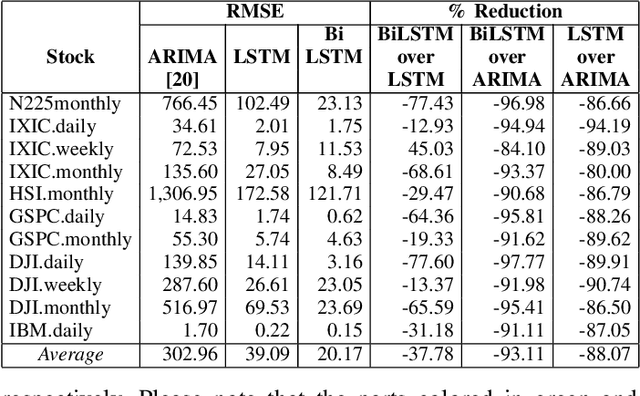
Machine and deep learning-based algorithms are the emerging approaches in addressing prediction problems in time series. These techniques have been shown to produce more accurate results than conventional regression-based modeling. It has been reported that artificial Recurrent Neural Networks (RNN) with memory, such as Long Short-Term Memory (LSTM), are superior compared to Autoregressive Integrated Moving Average (ARIMA) with a large margin. The LSTM-based models incorporate additional "gates" for the purpose of memorizing longer sequences of input data. The major question is that whether the gates incorporated in the LSTM architecture already offers a good prediction and whether additional training of data would be necessary to further improve the prediction. Bidirectional LSTMs (BiLSTMs) enable additional training by traversing the input data twice (i.e., 1) left-to-right, and 2) right-to-left). The research question of interest is then whether BiLSTM, with additional training capability, outperforms regular unidirectional LSTM. This paper reports a behavioral analysis and comparison of BiLSTM and LSTM models. The objective is to explore to what extend additional layers of training of data would be beneficial to tune the involved parameters. The results show that additional training of data and thus BiLSTM-based modeling offers better predictions than regular LSTM-based models. More specifically, it was observed that BiLSTM models provide better predictions compared to ARIMA and LSTM models. It was also observed that BiLSTM models reach the equilibrium much slower than LSTM-based models.
A Simple Discrete-Time Survival Model for Neural Networks
May 03, 2018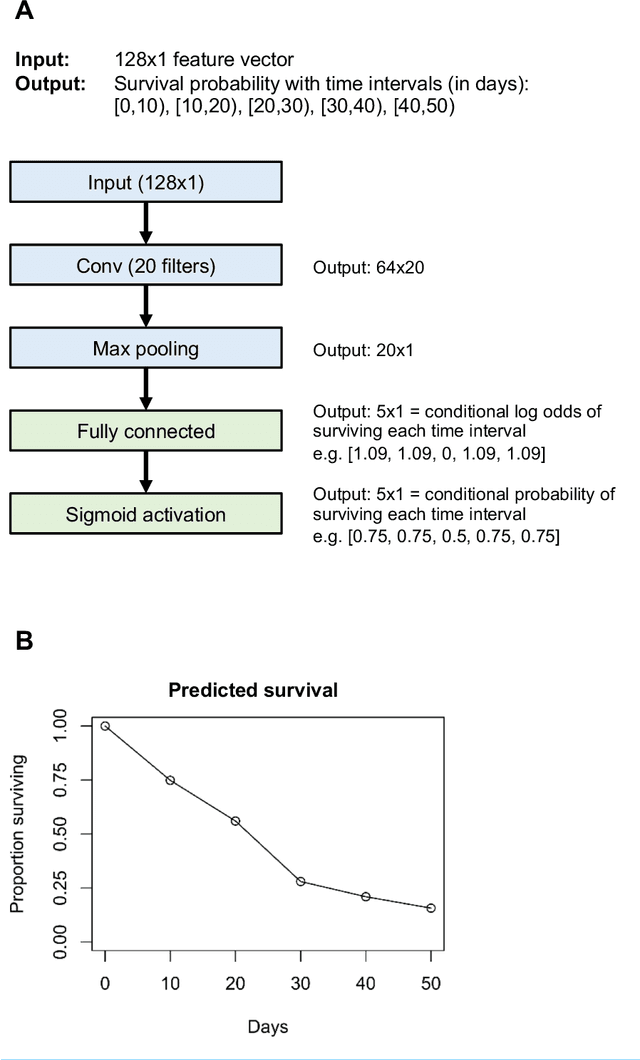
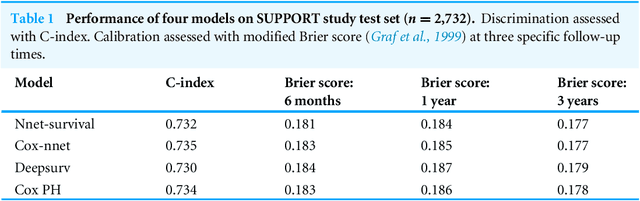
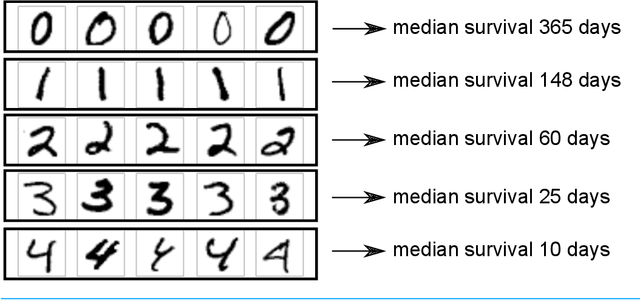
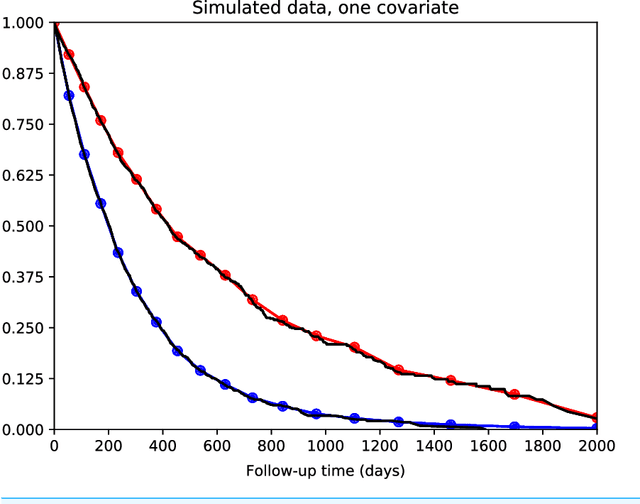
There is currently great interest in applying neural networks to prediction tasks in medicine. It is important for predictive models to be able to use survival data, where each patient has a known follow-up time and event/censoring indicator. This avoids information loss when training the model and enables generation of predicted survival curves. In this paper, we describe a discrete-time survival model that is designed to be used with neural networks. The model is trained with the maximum likelihood method using minibatch stochastic gradient descent (SGD). The use of SGD enables rapid training speed. The model is flexible, so that the baseline hazard rate and the effect of the input data can vary with follow-up time. It has been implemented in the Keras deep learning framework, and source code for the model and several examples is available online. We demonstrated the high performance of the model by using it as part of a convolutional neural network to predict survival for over 10,000 patients with metastatic cancer, using the full text of 1,137,317 provider notes. The model's C-index on the validation set was 0.71, which was superior to a linear baseline model (C-index 0.69).
A machine learning pipeline for aiding school identification from child trafficking images
Jun 09, 2021
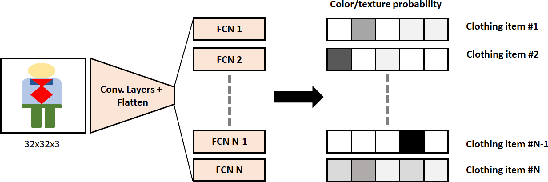
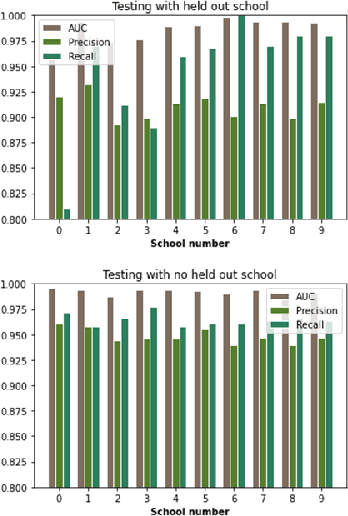
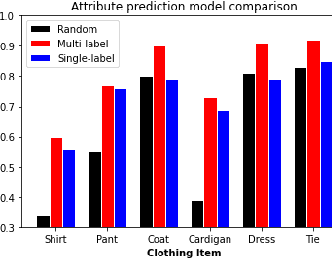
Child trafficking in a serious problem around the world. Every year there are more than 4 million victims of child trafficking around the world, many of them for the purposes of child sexual exploitation. In collaboration with UK Police and a non-profit focused on child abuse prevention, Global Emancipation Network, we developed a proof-of-concept machine learning pipeline to aid the identification of children from intercepted images. In this work, we focus on images that contain children wearing school uniforms to identify the school of origin. In the absence of a machine learning pipeline, this hugely time consuming and labor intensive task is manually conducted by law enforcement personnel. Thus, by automating aspects of the school identification process, we hope to significantly impact the speed of this portion of child identification. Our proposed pipeline consists of two machine learning models: i) to identify whether an image of a child contains a school uniform in it, and ii) identification of attributes of different school uniform items (such as color/texture of shirts, sweaters, blazers etc.). We describe the data collection, labeling, model development and validation process, along with strategies for efficient searching of schools using the model predictions.