 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
A Simple Discrete-Time Survival Model for Neural Networks
May 03, 2018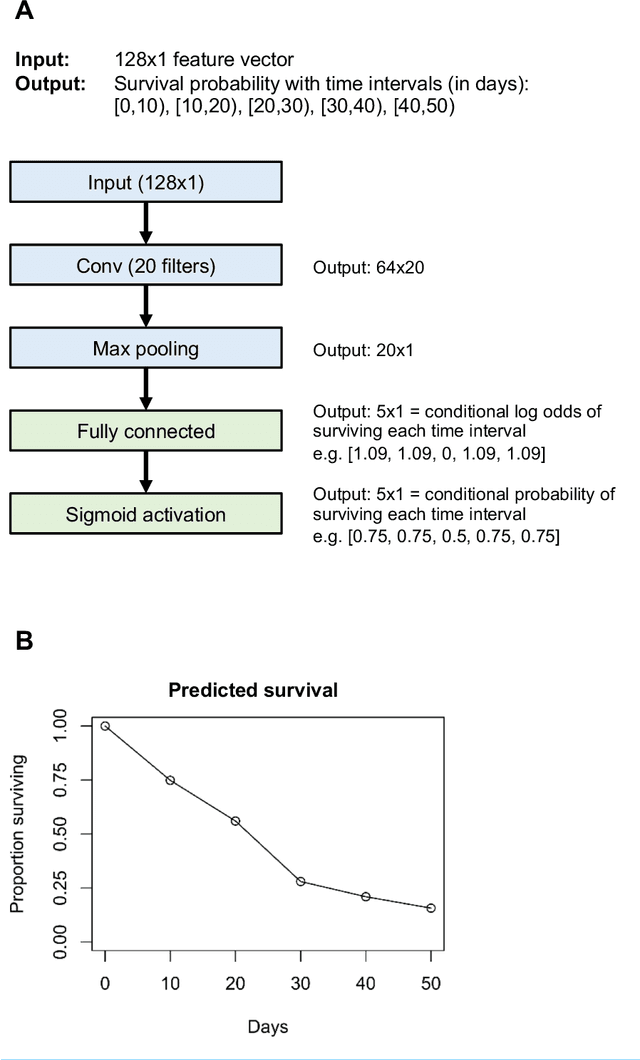
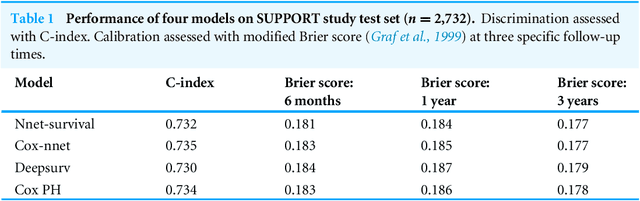
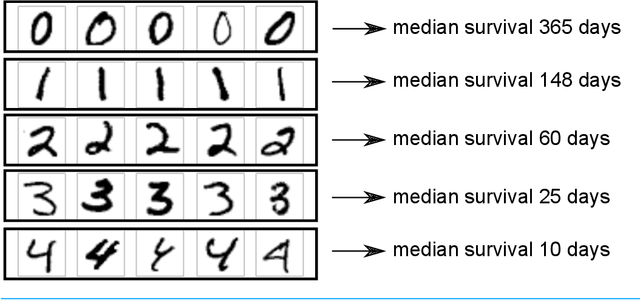
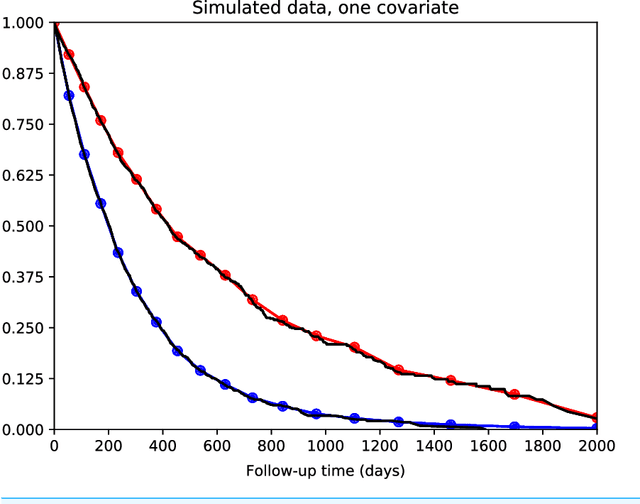
There is currently great interest in applying neural networks to prediction tasks in medicine. It is important for predictive models to be able to use survival data, where each patient has a known follow-up time and event/censoring indicator. This avoids information loss when training the model and enables generation of predicted survival curves. In this paper, we describe a discrete-time survival model that is designed to be used with neural networks. The model is trained with the maximum likelihood method using minibatch stochastic gradient descent (SGD). The use of SGD enables rapid training speed. The model is flexible, so that the baseline hazard rate and the effect of the input data can vary with follow-up time. It has been implemented in the Keras deep learning framework, and source code for the model and several examples is available online. We demonstrated the high performance of the model by using it as part of a convolutional neural network to predict survival for over 10,000 patients with metastatic cancer, using the full text of 1,137,317 provider notes. The model's C-index on the validation set was 0.71, which was superior to a linear baseline model (C-index 0.69).