 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Real Use Case of Semi-Supervised Learning for Mammogram Classification in a Local Clinic of Costa Rica
Jul 24, 2021
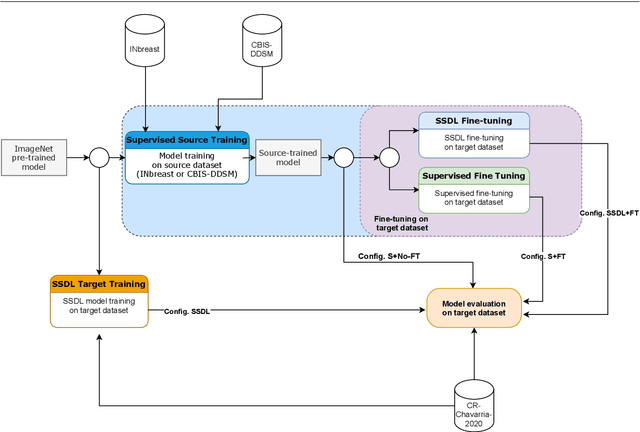
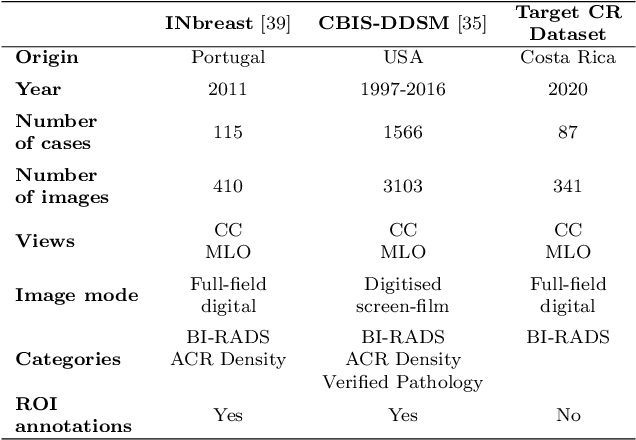
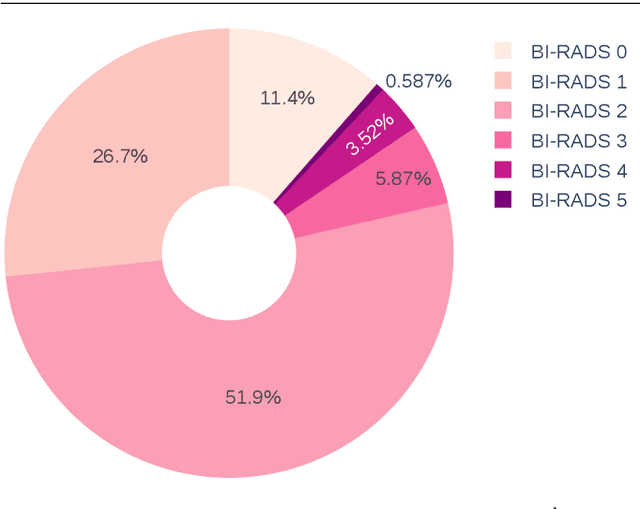
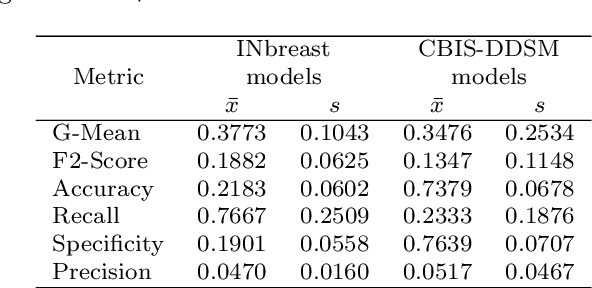
The implementation of deep learning based computer aided diagnosis systems for the classification of mammogram images can help in improving the accuracy, reliability, and cost of diagnosing patients. However, training a deep learning model requires a considerable amount of labeled images, which can be expensive to obtain as time and effort from clinical practitioners is required. A number of publicly available datasets have been built with data from different hospitals and clinics. However, using models trained on these datasets for later work on images sampled from a different hospital or clinic might result in lower performance. This is due to the distribution mismatch of the datasets, which include different patient populations and image acquisition protocols. The scarcity of labeled data can also bring a challenge towards the application of transfer learning with models trained using these source datasets. In this work, a real world scenario is evaluated where a novel target dataset sampled from a private Costa Rican clinic is used, with few labels and heavily imbalanced data. The use of two popular and publicly available datasets (INbreast and CBIS-DDSM) as source data, to train and test the models on the novel target dataset, is evaluated. The use of the semi-supervised deep learning approach known as MixMatch, to leverage the usage of unlabeled data from the target dataset, is proposed and evaluated. In the tests, the performance of models is extensively measured, using different metrics to assess the performance of a classifier under heavy data imbalance conditions. It is shown that the use of semi-supervised deep learning combined with fine-tuning can provide a meaningful advantage when using scarce labeled observations. We make available the novel dataset for the benefit of the community.
Scaling up Mean Field Games with Online Mirror Descent
Feb 28, 2021
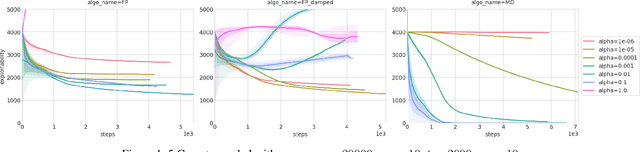

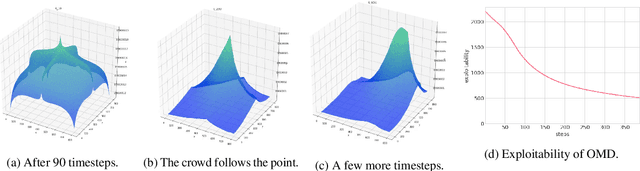
We address scaling up equilibrium computation in Mean Field Games (MFGs) using Online Mirror Descent (OMD). We show that continuous-time OMD provably converges to a Nash equilibrium under a natural and well-motivated set of monotonicity assumptions. This theoretical result nicely extends to multi-population games and to settings involving common noise. A thorough experimental investigation on various single and multi-population MFGs shows that OMD outperforms traditional algorithms such as Fictitious Play (FP). We empirically show that OMD scales up and converges significantly faster than FP by solving, for the first time to our knowledge, examples of MFGs with hundreds of billions states. This study establishes the state-of-the-art for learning in large-scale multi-agent and multi-population games.
AMV : Algorithm Metadata Vocabulary
Jun 01, 2021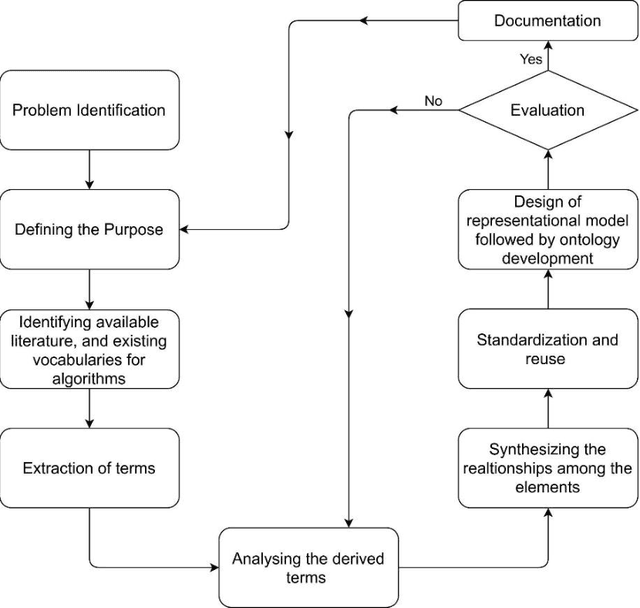
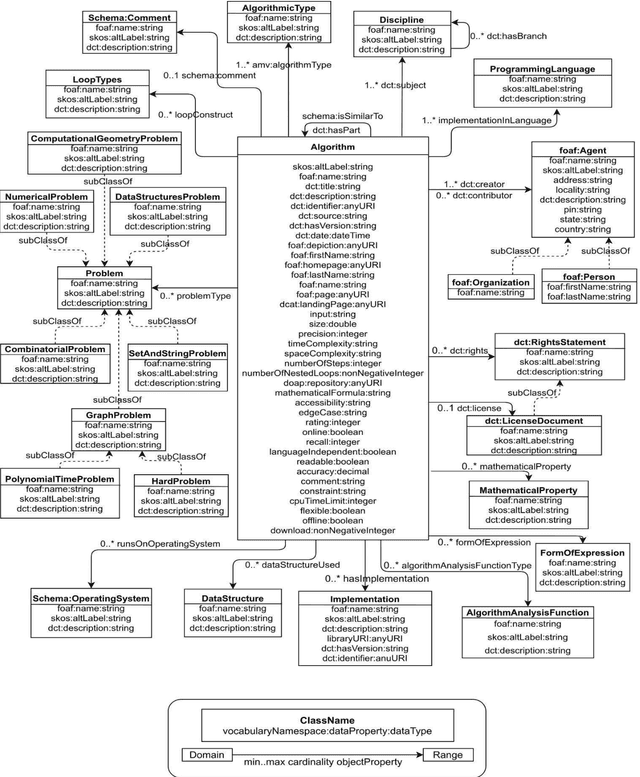
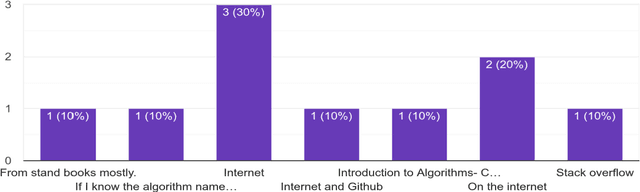
Metadata vocabularies are used in various domains of study. It provides an in-depth description of the resources. In this work, we develop Algorithm Metadata Vocabulary (AMV), a vocabulary for capturing and storing the metadata about the algorithms (a procedure or a set of rules that is followed step-by-step to solve a problem, especially by a computer). The snag faced by the researchers in the current time is the failure of getting relevant results when searching for algorithms in any search engine. AMV is represented as a semantic model and produced OWL file, which can be directly used by anyone interested to create and publish algorithm metadata as a knowledge graph, or to provide metadata service through SPARQL endpoint. To design the vocabulary, we propose a well-defined methodology, which considers real issues faced by the algorithm users and the practitioners. The evaluation shows a promising result.
An Adaptive Framework for Learning Unsupervised Depth Completion
Jun 06, 2021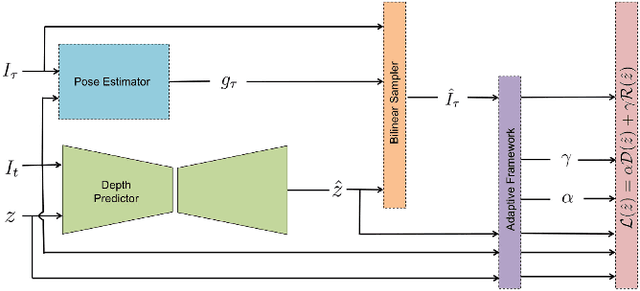
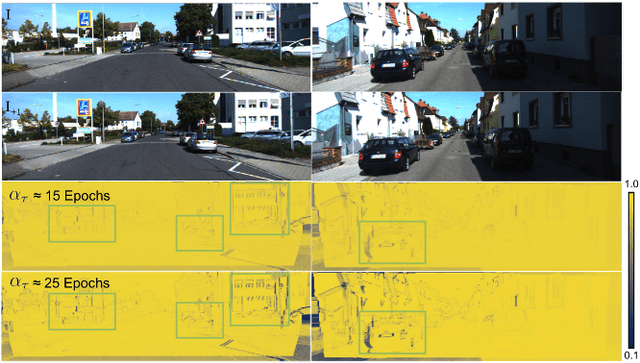

We present a method to infer a dense depth map from a color image and associated sparse depth measurements. Our main contribution lies in the design of an annealing process for determining co-visibility (occlusions, disocclusions) and the degree of regularization to impose on the model. We show that regularization and co-visibility are related via the fitness (residual) of model to data and both can be unified into a single framework to improve the learning process. Our method is an adaptive weighting scheme that guides optimization by measuring the residual at each pixel location over each training step for (i) estimating a soft visibility mask and (ii) determining the amount of regularization. We demonstrate the effectiveness our method by applying it to several recent unsupervised depth completion methods and improving their performance on public benchmark datasets, without incurring additional trainable parameters or increase in inference time. Code available at: https://github.com/alexklwong/adaframe-depth-completion.
Noised Consistency Training for Text Summarization
May 28, 2021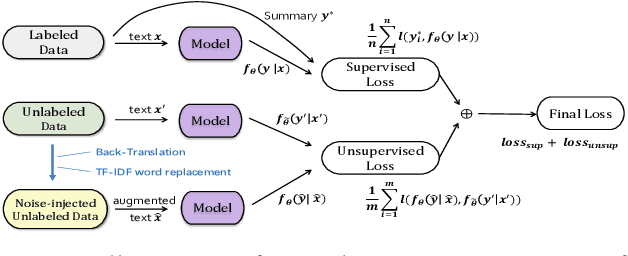
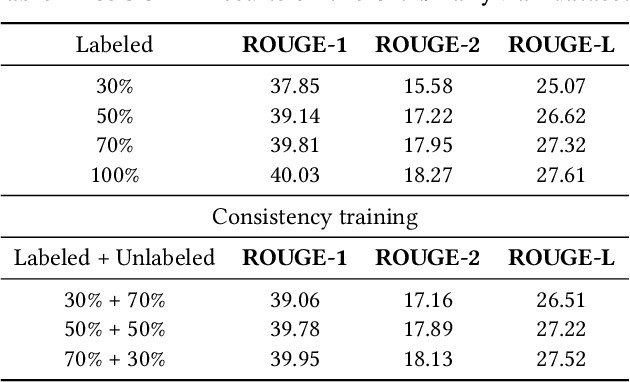
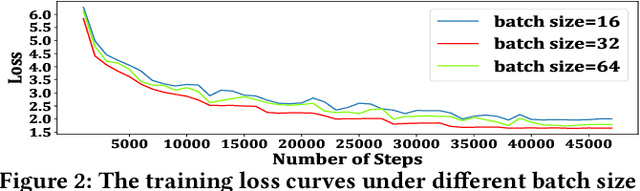
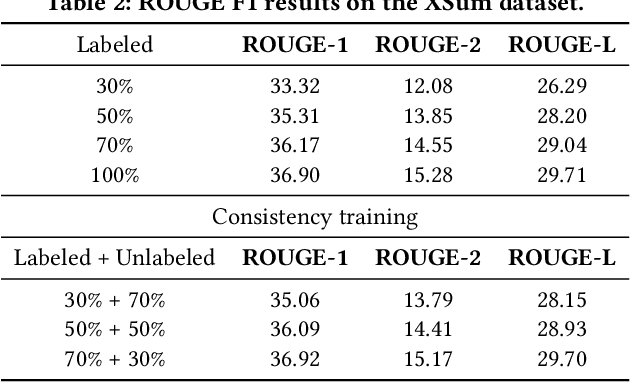
Neural abstractive summarization methods often require large quantities of labeled training data. However, labeling large amounts of summarization data is often prohibitive due to time, financial, and expertise constraints, which has limited the usefulness of summarization systems to practical applications. In this paper, we argue that this limitation can be overcome by a semi-supervised approach: consistency training which is to leverage large amounts of unlabeled data to improve the performance of supervised learning over a small corpus. The consistency regularization semi-supervised learning can regularize model predictions to be invariant to small noise applied to input articles. By adding noised unlabeled corpus to help regularize consistency training, this framework obtains comparative performance without using the full dataset. In particular, we have verified that leveraging large amounts of unlabeled data decently improves the performance of supervised learning over an insufficient labeled dataset.
Revelio: ML-Generated Debugging Queries for Distributed Systems
Jun 28, 2021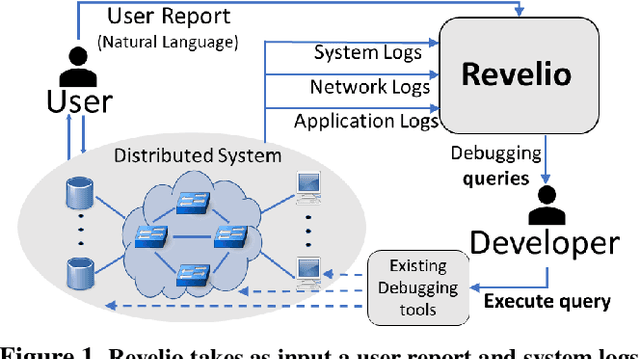
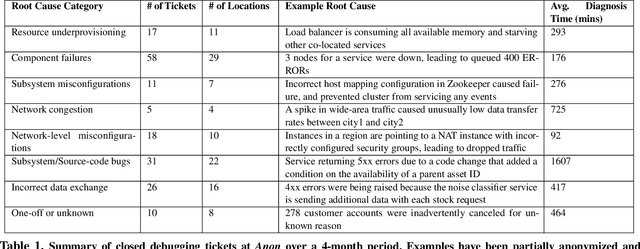
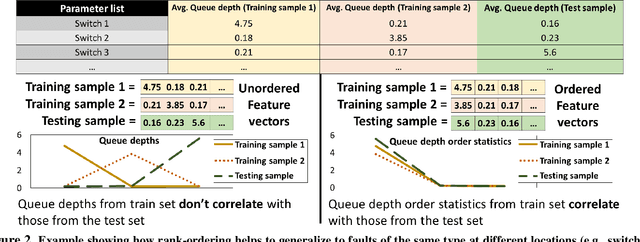

A major difficulty in debugging distributed systems lies in manually determining which of the many available debugging tools to use and how to query its logs. Our own study of a production debugging workflow confirms the magnitude of this burden. This paper explores whether a machine-learning model can assist developers in distributed systems debugging. We present Revelio, a debugging assistant which takes user reports and system logs as input, and outputs debugging queries that developers can use to find a bug's root cause. The key challenges lie in (1) combining inputs of different types (e.g., natural language reports and quantitative logs) and (2) generalizing to unseen faults. Revelio addresses these by employing deep neural networks to uniformly embed diverse input sources and potential queries into a high-dimensional vector space. In addition, it exploits observations from production systems to factorize query generation into two computationally and statistically simpler learning tasks. To evaluate Revelio, we built a testbed with multiple distributed applications and debugging tools. By injecting faults and training on logs and reports from 800 Mechanical Turkers, we show that Revelio includes the most helpful query in its predicted list of top-3 relevant queries 96% of the time. Our developer study confirms the utility of Revelio.
DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision
Jun 05, 2021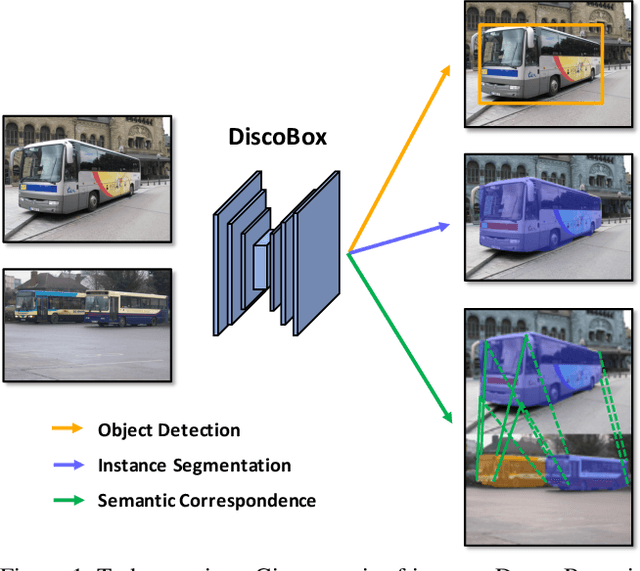
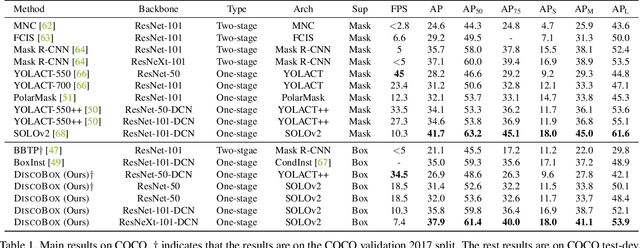
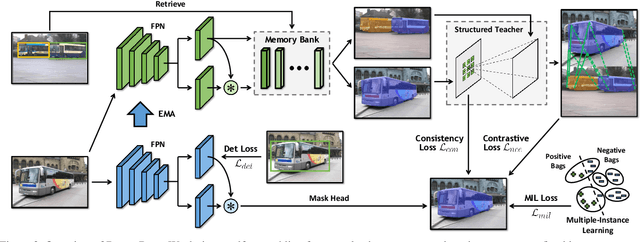
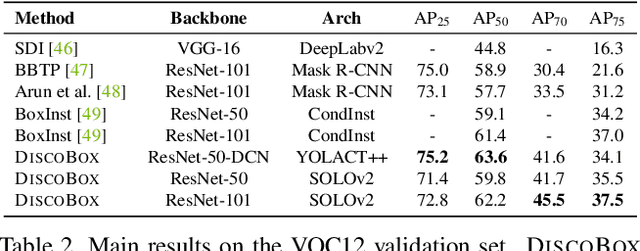
We introduce DiscoBox, a novel framework that jointly learns instance segmentation and semantic correspondence using bounding box supervision. Specifically, we propose a self-ensembling framework where instance segmentation and semantic correspondence are jointly guided by a structured teacher in addition to the bounding box supervision. The teacher is a structured energy model incorporating a pairwise potential and a cross-image potential to model the pairwise pixel relationships both within and across the boxes. Minimizing the teacher energy simultaneously yields refined object masks and dense correspondences between intra-class objects, which are taken as pseudo-labels to supervise the task network and provide positive/negative correspondence pairs for dense constrastive learning. We show a symbiotic relationship where the two tasks mutually benefit from each other. Our best model achieves 37.9% AP on COCO instance segmentation, surpassing prior weakly supervised methods and is competitive to supervised methods. We also obtain state of the art weakly supervised results on PASCAL VOC12 and PF-PASCAL with real-time inference.
DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation
Apr 03, 2019


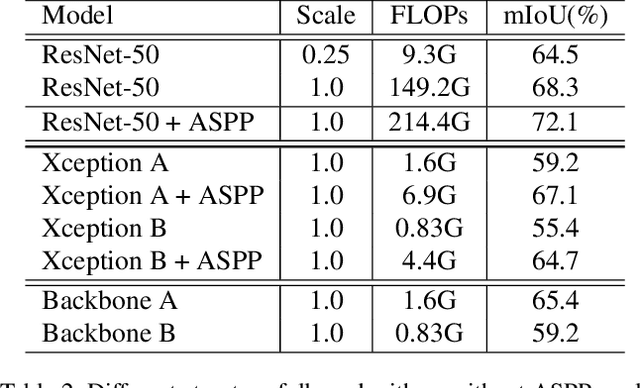
This paper introduces an extremely efficient CNN architecture named DFANet for semantic segmentation under resource constraints. Our proposed network starts from a single lightweight backbone and aggregates discriminative features through sub-network and sub-stage cascade respectively. Based on the multi-scale feature propagation, DFANet substantially reduces the number of parameters, but still obtains sufficient receptive field and enhances the model learning ability, which strikes a balance between the speed and segmentation performance. Experiments on Cityscapes and CamVid datasets demonstrate the superior performance of DFANet with 8$\times$ less FLOPs and 2$\times$ faster than the existing state-of-the-art real-time semantic segmentation methods while providing comparable accuracy. Specifically, it achieves 70.3\% Mean IOU on the Cityscapes test dataset with only 1.7 GFLOPs and a speed of 160 FPS on one NVIDIA Titan X card, and 71.3\% Mean IOU with 3.4 GFLOPs while inferring on a higher resolution image.
Data-driven Prediction of General Hamiltonian Dynamics via Learning Exactly-Symplectic Maps
Mar 09, 2021
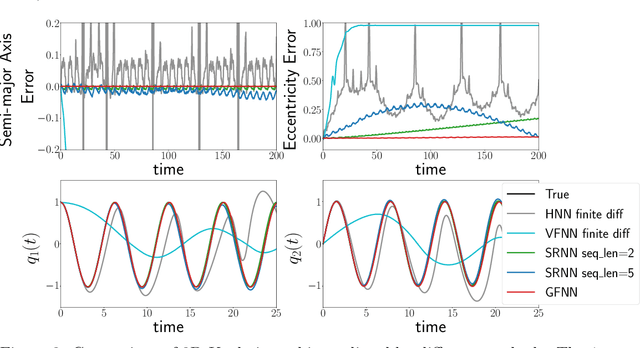
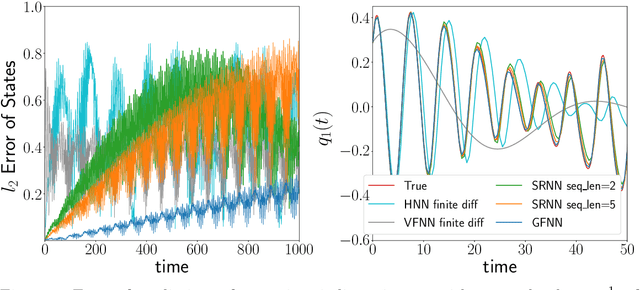
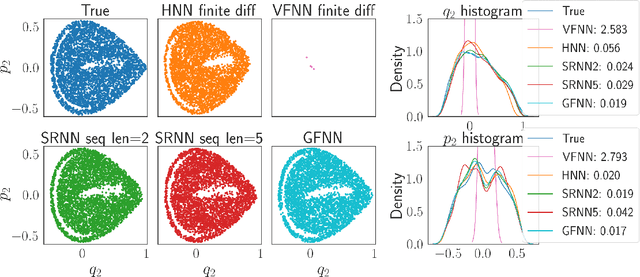
We consider the learning and prediction of nonlinear time series generated by a latent symplectic map. A special case is (not necessarily separable) Hamiltonian systems, whose solution flows give such symplectic maps. For this special case, both generic approaches based on learning the vector field of the latent ODE and specialized approaches based on learning the Hamiltonian that generates the vector field exist. Our method, however, is different as it does not rely on the vector field nor assume its existence; instead, it directly learns the symplectic evolution map in discrete time. Moreover, we do so by representing the symplectic map via a generating function, which we approximate by a neural network (hence the name GFNN). This way, our approximation of the evolution map is always \emph{exactly} symplectic. This additional geometric structure allows the local prediction error at each step to accumulate in a controlled fashion, and we will prove, under reasonable assumptions, that the global prediction error grows at most \emph{linearly} with long prediction time, which significantly improves an otherwise exponential growth. In addition, as a map-based and thus purely data-driven method, GFNN avoids two additional sources of inaccuracies common in vector-field based approaches, namely the error in approximating the vector field by finite difference of the data, and the error in numerical integration of the vector field for making predictions. Numerical experiments further demonstrate our claims.
3D U-Net for segmentation of COVID-19 associated pulmonary infiltrates using transfer learning: State-of-the-art results on affordable hardware
Jan 25, 2021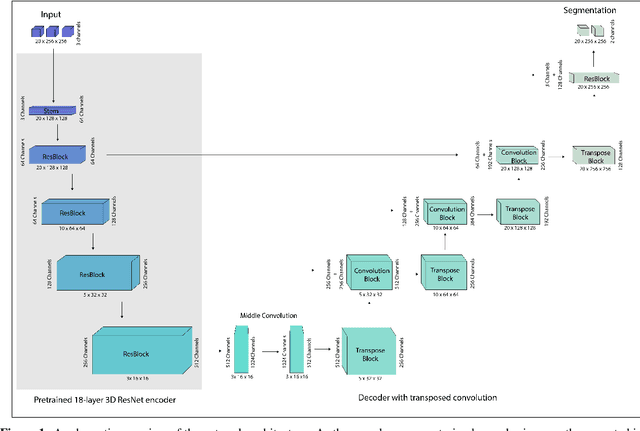
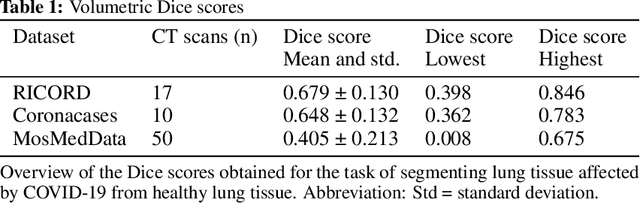
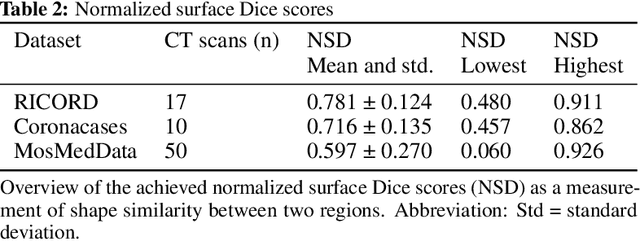
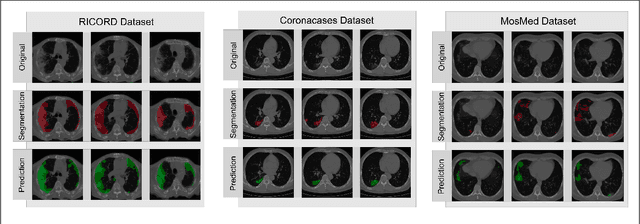
Segmentation of pulmonary infiltrates can help assess severity of COVID-19, but manual segmentation is labor and time-intensive. Using neural networks to segment pulmonary infiltrates would enable automation of this task. However, training a 3D U-Net from computed tomography (CT) data is time- and resource-intensive. In this work, we therefore developed and tested a solution on how transfer learning can be used to train state-of-the-art segmentation models on limited hardware and in shorter time. We use the recently published RSNA International COVID-19 Open Radiology Database (RICORD) to train a fully three-dimensional U-Net architecture using an 18-layer 3D ResNet, pretrained on the Kinetics-400 dataset as encoder. The generalization of the model was then tested on two openly available datasets of patients with COVID-19, who received chest CTs (Corona Cases and MosMed datasets). Our model performed comparable to previously published 3D U-Net architectures, achieving a mean Dice score of 0.679 on the tuning dataset, 0.648 on the Coronacases dataset and 0.405 on the MosMed dataset. Notably, these results were achieved with shorter training time on a single GPU with less memory available than the GPUs used in previous studies.