 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoised Consistency Training for Text Summarization
Paper and Code
May 28, 2021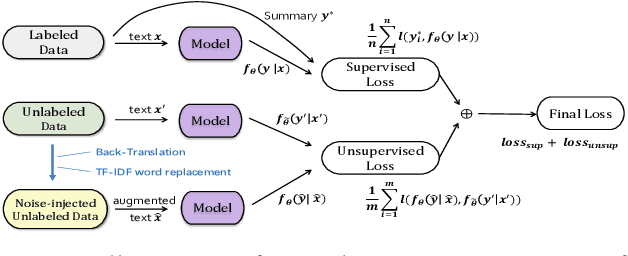
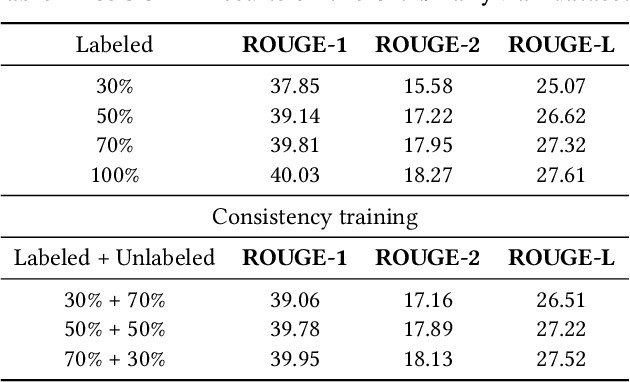
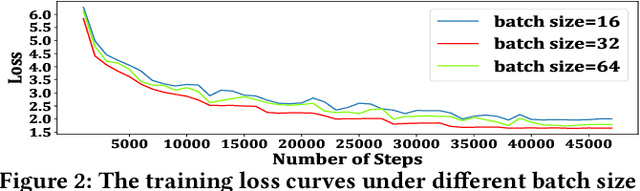
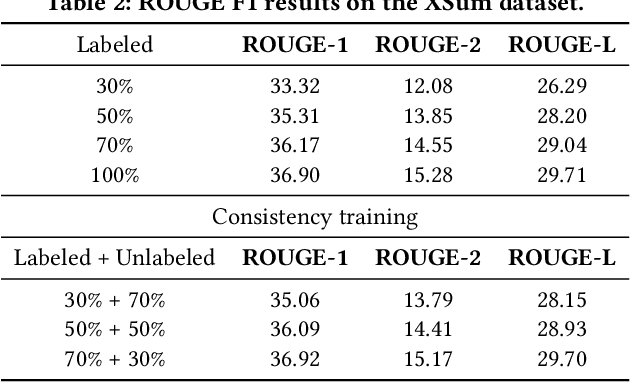
Neural abstractive summarization methods often require large quantities of labeled training data. However, labeling large amounts of summarization data is often prohibitive due to time, financial, and expertise constraints, which has limited the usefulness of summarization systems to practical applications. In this paper, we argue that this limitation can be overcome by a semi-supervised approach: consistency training which is to leverage large amounts of unlabeled data to improve the performance of supervised learning over a small corpus. The consistency regularization semi-supervised learning can regularize model predictions to be invariant to small noise applied to input articles. By adding noised unlabeled corpus to help regularize consistency training, this framework obtains comparative performance without using the full dataset. In particular, we have verified that leveraging large amounts of unlabeled data decently improves the performance of supervised learning over an insufficient labeled dataset.