 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data-Driven Optimization for Police Zone Design
Mar 30, 2021
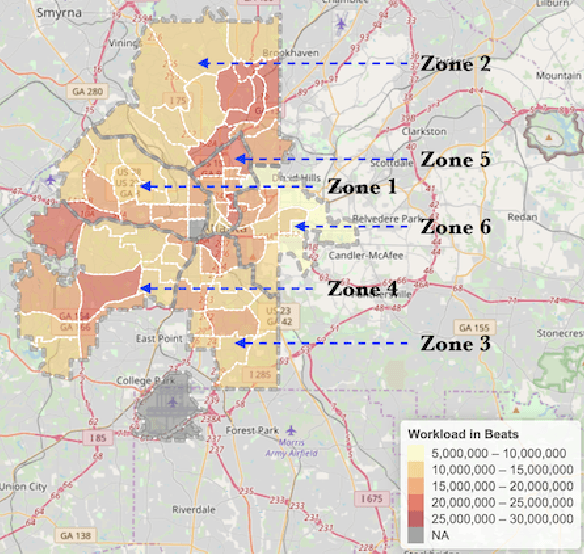

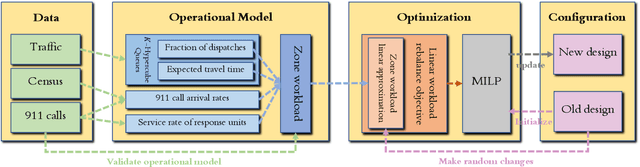

We present a data-driven optimization framework for redesigning police patrol zones in an urban environment. The objectives are to rebalance police workload among geographical areas and to reduce response time to emergency calls. We develop a stochastic model for police emergency response by integrating multiple data sources, including police incidents reports, demographic surveys, and traffic data. Using this stochastic model, we optimize zone redesign plans using mixed-integer linear programming. Our proposed design was implemented by the Atlanta Police Department in March 2019. By analyzing data before and after the zone redesign, we show that the new design has reduced the response time to high priority 911 calls by 5.8\% and the imbalance of police workload among different zones by 43\%.
Multiaccurate Proxies for Downstream Fairness
Jul 09, 2021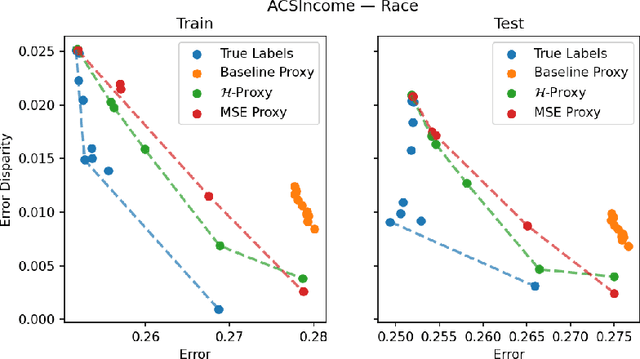
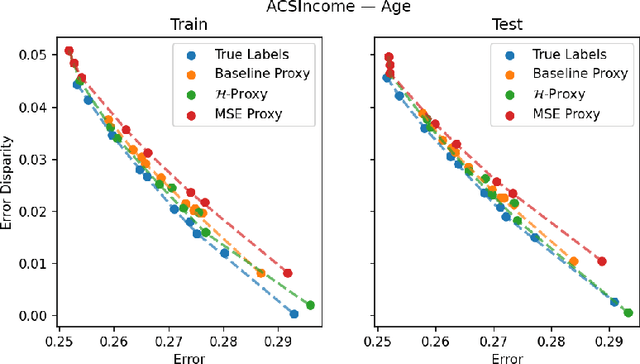
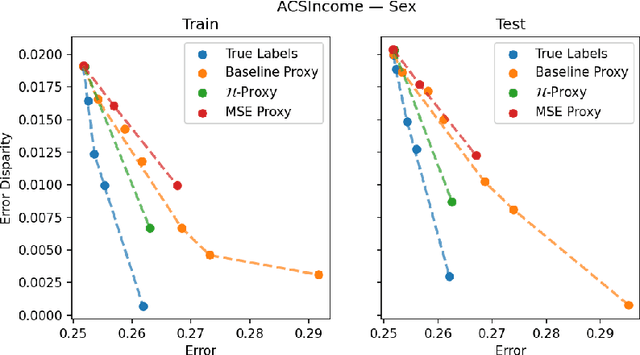
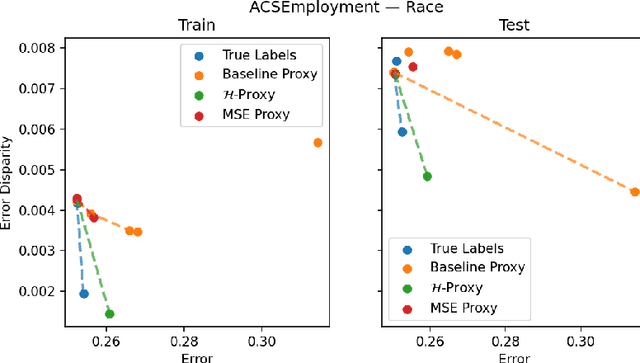
We study the problem of training a model that must obey demographic fairness conditions when the sensitive features are not available at training time -- in other words, how can we train a model to be fair by race when we don't have data about race? We adopt a fairness pipeline perspective, in which an "upstream" learner that does have access to the sensitive features will learn a proxy model for these features from the other attributes. The goal of the proxy is to allow a general "downstream" learner -- with minimal assumptions on their prediction task -- to be able to use the proxy to train a model that is fair with respect to the true sensitive features. We show that obeying multiaccuracy constraints with respect to the downstream model class suffices for this purpose, and provide sample- and oracle efficient-algorithms and generalization bounds for learning such proxies. In general, multiaccuracy can be much easier to satisfy than classification accuracy, and can be satisfied even when the sensitive features are hard to predict.
Enabling Plug-and-Play and Crowdsourcing SLAM in Wireless Communication Systems
Aug 08, 2021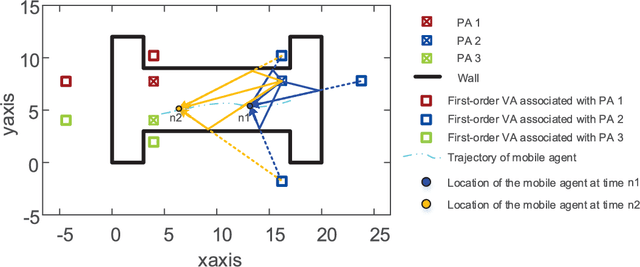
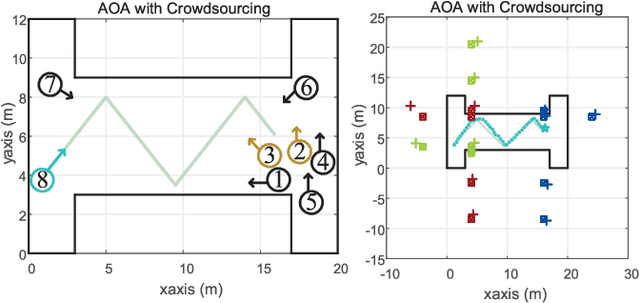
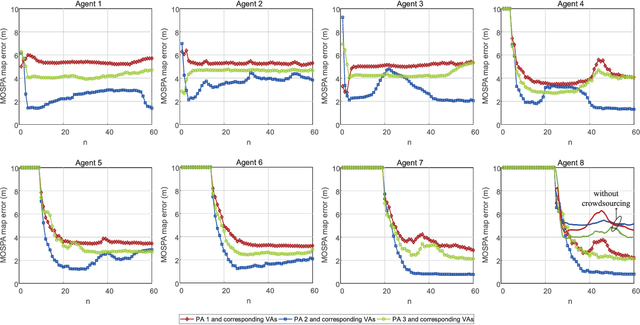
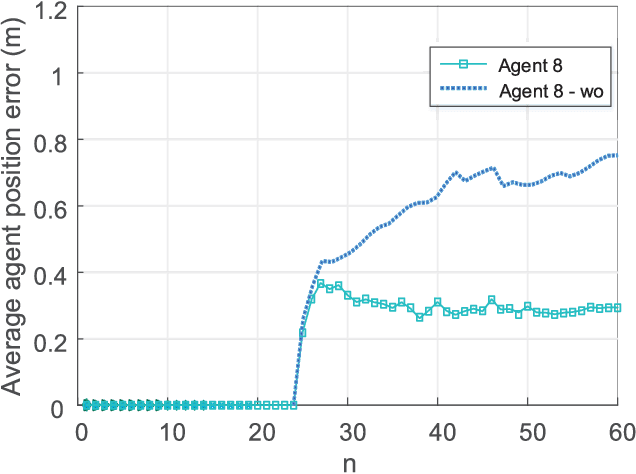
Simultaneous localization and mapping (SLAM) during communication is emerging. This technology promises to provide information on propagation environments and transceivers' location, thus creating several new services and applications for the Internet of Things and environment-aware communication. Using crowdsourcing data collected by multiple agents appears to be much potential for enhancing SLAM performance. However, the measurement uncertainties in practice and biased estimations from multiple agents may result in serious errors. This study develops a robust SLAM method with measurement plug-and-play and crowdsourcing mechanisms to address the above problems. First, we divide measurements into different categories according to their unknown biases and realize a measurement plug-and-play mechanism by extending the classic belief propagation (BP)-based SLAM method. The proposed mechanism can obtain the time-varying agent location, radio features, and corresponding measurement biases (such as clock bias, orientation bias, and received signal strength model parameters), with high accuracy and robustness in challenging scenarios without any prior information on anchors and agents. Next, we establish a probabilistic crowdsourcing-based SLAM mechanism, in which multiple agents cooperate to construct and refine the radio map in a decentralized manner. Our study presents the first BP-based crowdsourcing that resolves the "double count" and "data reliability" problems through the flexible application of probabilistic data association methods. Numerical results reveal that the crowdsourcing mechanism can further improve the accuracy of the mapping result, which, in turn, ensures the decimeter-level localization accuracy of each agent in a challenging propagation environment.
MuCoMiD: A Multitask Convolutional Learning Framework for miRNA-Disease Association Prediction
Aug 08, 2021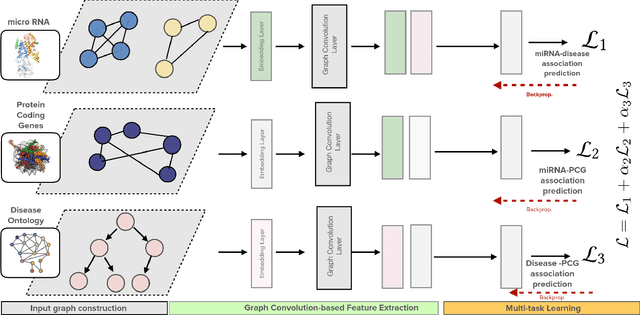


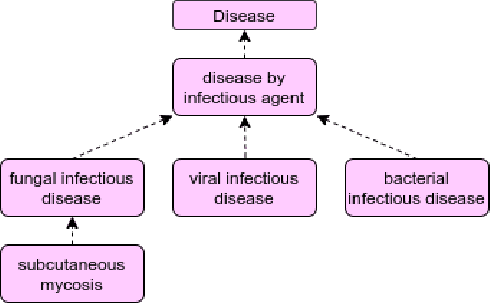
Growing evidence from recent studies implies that microRNA or miRNA could serve as biomarkers in various complex human diseases. Since wet-lab experiments are expensive and time-consuming, computational techniques for miRNA-disease association prediction have attracted a lot of attention in recent years. Data scarcity is one of the major challenges in building reliable machine learning models. Data scarcity combined with the use of pre-calculated hand-crafted input features has led to problems of overfitting and data leakage. We overcome the limitations of existing works by proposing a novel multi-tasking convolution-based approach, which we refer to as MuCoMiD. MuCoMiD allows automatic feature extraction while incorporating knowledge from 4 heterogeneous biological information sources (interactions between miRNA/diseases and protein-coding genes (PCG), miRNA family information, and disease ontology) in a multi-task setting which is a novel perspective and has not been studied before. The use of multi-channel convolutions allows us to extract expressive representations while keeping the model linear and, therefore, simple. To effectively test the generalization capability of our model, we construct large-scale experiments on standard benchmark datasets as well as our proposed larger independent test sets and case studies. MuCoMiD shows an improvement of at least 5% in 5-fold CV evaluation on HMDDv2.0 and HMDDv3.0 datasets and at least 49% on larger independent test sets with unseen miRNA and diseases over state-of-the-art approaches. We share our code for reproducibility and future research at https://git.l3s.uni-hannover.de/dong/cmtt.
You Better Look Twice: a new perspective for designing accurate detectors with reduced computations
Aug 03, 2021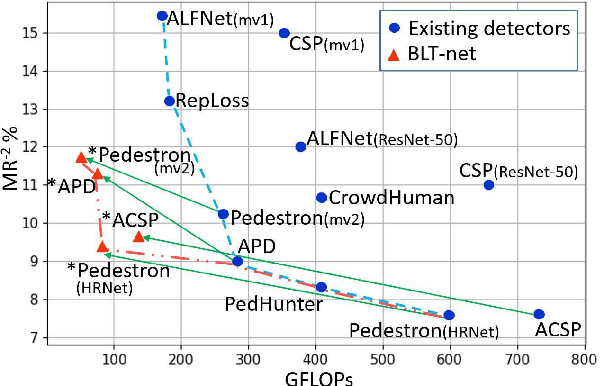
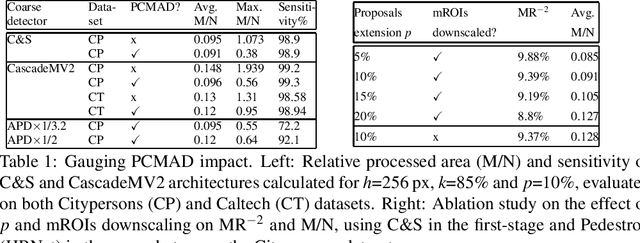
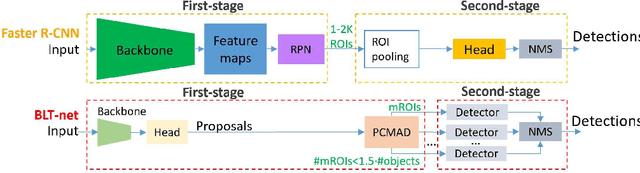
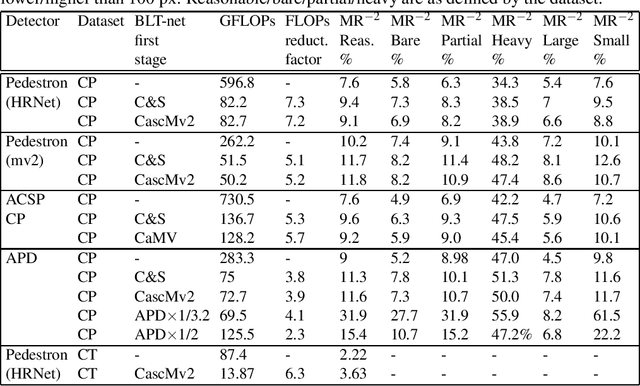
General object detectors use powerful backbones that uniformly extract features from images for enabling detection of a vast amount of object types. However, utilization of such backbones in object detection applications developed for specific object types can unnecessarily over-process an extensive amount of background. In addition, they are agnostic to object scales, thus redundantly process all image regions at the same resolution. In this work we introduce BLT-net, a new low-computation two-stage object detection architecture designed to process images with a significant amount of background and objects of variate scales. BLT-net reduces computations by separating objects from background using a very lite first-stage. BLT-net then efficiently merges obtained proposals to further decrease processed background and then dynamically reduces their resolution to minimize computations. Resulting image proposals are then processed in the second-stage by a highly accurate model. We demonstrate our architecture on the pedestrian detection problem, where objects are of different sizes, images are of high resolution and object detection is required to run in real-time. We show that our design reduces computations by a factor of x4-x7 on the Citypersons and Caltech datasets with respect to leading pedestrian detectors, on account of a small accuracy degradation. This method can be applied on other object detection applications in scenes with a considerable amount of background and variate object sizes to reduce computations.
Revisiting IoT Device Identification
Jul 16, 2021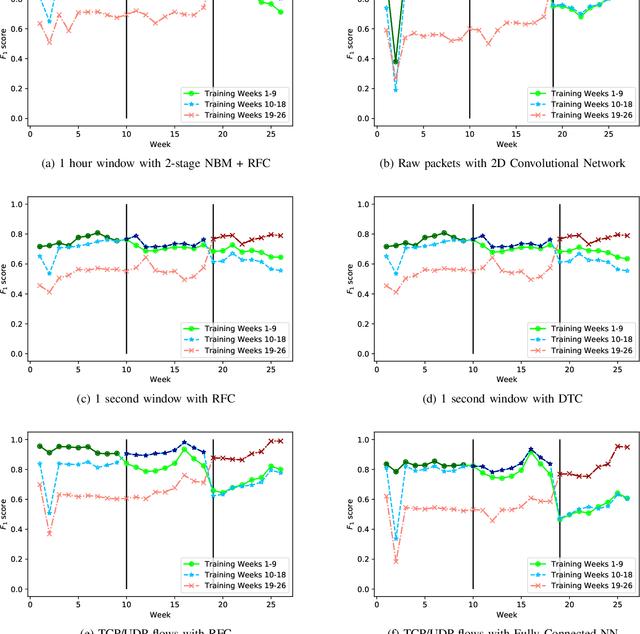
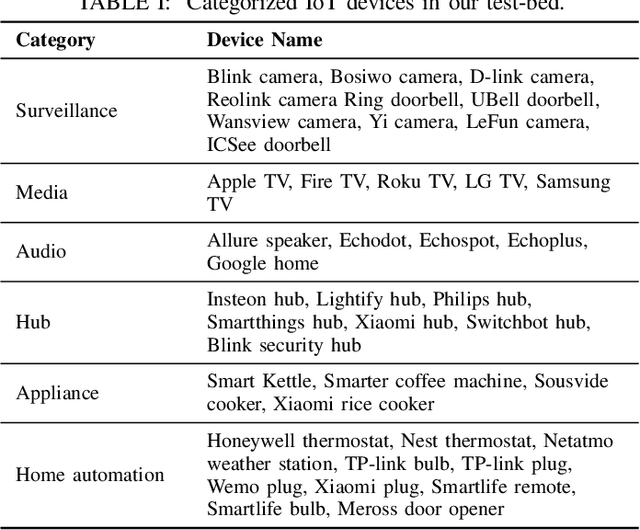
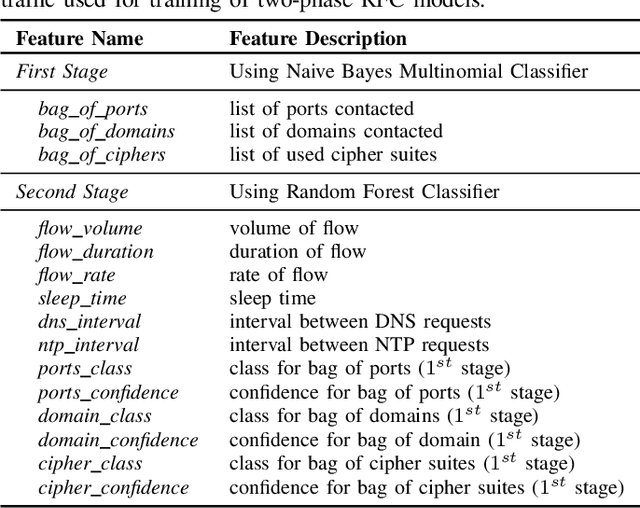

Internet-of-Things (IoT) devices are known to be the source of many security problems, and as such, they would greatly benefit from automated management. This requires robustly identifying devices so that appropriate network security policies can be applied. We address this challenge by exploring how to accurately identify IoT devices based on their network behavior, while leveraging approaches previously proposed by other researchers. We compare the accuracy of four different previously proposed machine learning models (tree-based and neural network-based) for identifying IoT devices. We use packet trace data collected over a period of six months from a large IoT test-bed. We show that, while all models achieve high accuracy when evaluated on the same dataset as they were trained on, their accuracy degrades over time, when evaluated on data collected outside the training set. We show that on average the models' accuracy degrades after a couple of weeks by up to 40 percentage points (on average between 12 and 21 percentage points). We argue that, in order to keep the models' accuracy at a high level, these need to be continuously updated.
Graph-based Detection of Multiuser Impulse Radio Systems
May 23, 2021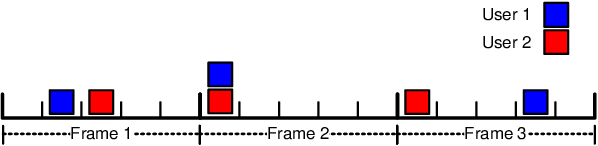
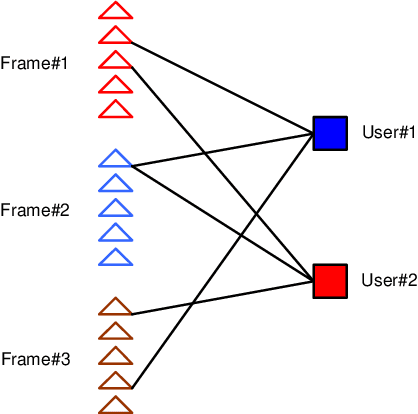
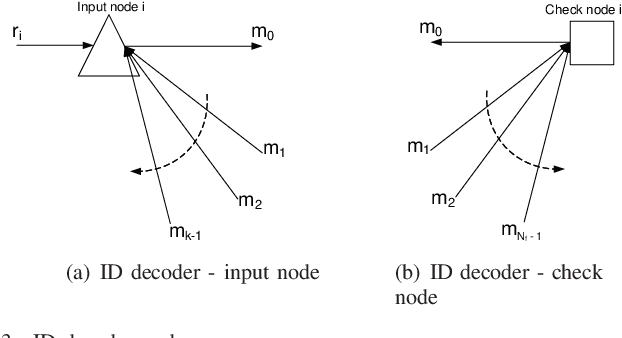
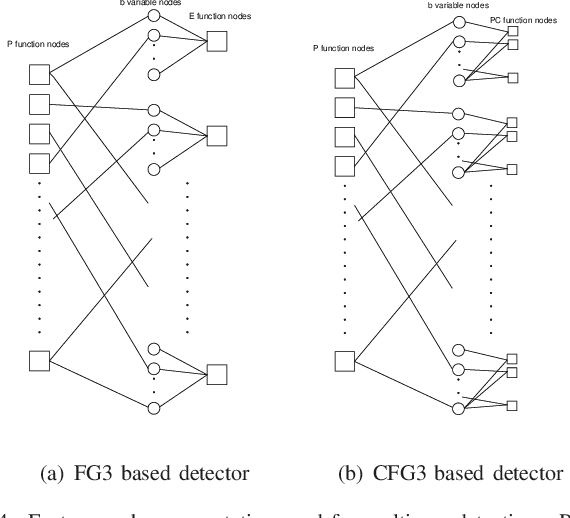
Impulse-Radio (IR) is a wideband modulation technique that can support multiple users by employing random Time-Hopping (TH) combined with repeated transmissions. The latter is aimed at alleviating the impact of collisions. This work employs a graphical model for describing the multiuser system which, in turn, facilitates the inclusion of general coding schemes. Based on factor graph representation of the system, several iterative multiuser detectors are presented. These detectors are applicable for any binary linear coding scheme. The performance of the proposed multiuser detectors is evaluated via simulations revealing large gains with low complexity.
PoolRank: Max/Min Pooling-based Ranking Loss for Listwise Learning & Ranking Balance
Aug 08, 2021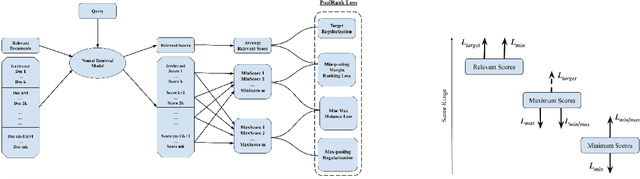
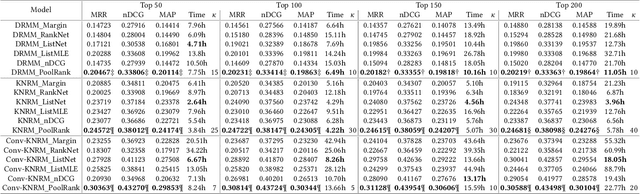
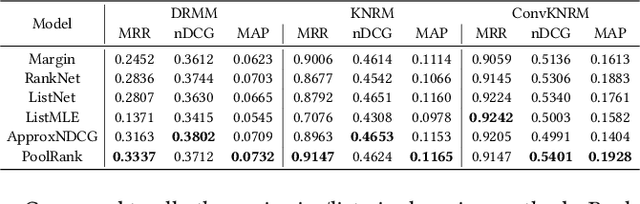
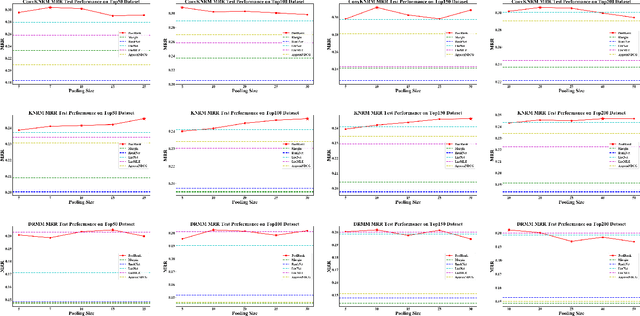
Numerous neural retrieval models have been proposed in recent years. These models learn to compute a ranking score between the given query and document. The majority of existing models are trained in pairwise fashion using human-judged labels directly without further calibration. The traditional pairwise schemes can be time-consuming and require pre-defined positive-negative document pairs for training, potentially leading to learning bias due to document distribution mismatch between training and test conditions. Some popular existing listwise schemes rely on the strong pre-defined probabilistic assumptions and stark difference between relevant and non-relevant documents for the given query, which may limit the model potential due to the low-quality or ambiguous relevance labels. To address these concerns, we turn to a physics-inspired ranking balance scheme and propose PoolRank, a pooling-based listwise learning framework. The proposed scheme has four major advantages: (1) PoolRank extracts training information from the best candidates at the local level based on model performance and relative ranking among abundant document candidates. (2) By combining four pooling-based loss components in a multi-task learning fashion, PoolRank calibrates the ranking balance for the partially relevant and the highly non-relevant documents automatically without costly human inspection. (3) PoolRank can be easily generalized to any neural retrieval model without requiring additional learnable parameters or model structure modifications. (4) Compared to pairwise learning and existing listwise learning schemes, PoolRank yields better ranking performance for all studied retrieval models while retaining efficient convergence rates.
CausCF: Causal Collaborative Filtering for RecommendationEffect Estimation
May 28, 2021
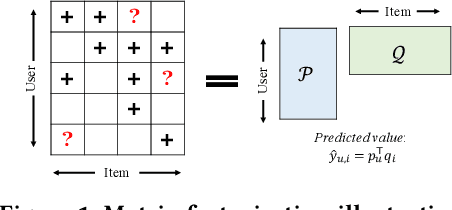
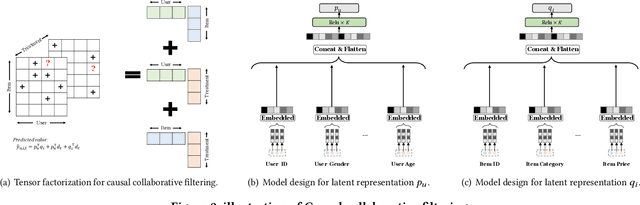
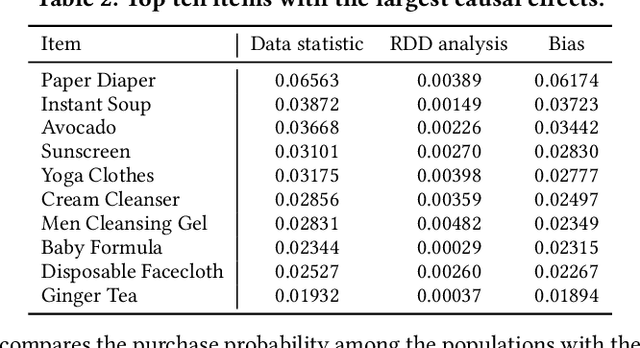
To improve user experience and profits of corporations, modern industrial recommender systems usually aim to select the items that are most likely to be interacted with (e.g., clicks and purchases). However, they overlook the fact that users may purchase the items even without recommendations. To select these effective items, it is essential to estimate the causal effect of recommendations. The real effective items are the ones which can contribute to purchase probability uplift. Nevertheless, it is difficult to obtain the real causal effect since we can only recommend or not recommend an item to a user at one time. Furthermore, previous works usually rely on the randomized controlled trial~(RCT) experiment to evaluate their performance. However, it is usually not practicable in the recommendation scenario due to its unavailable time consuming. To tackle these problems, in this paper, we propose a causal collaborative filtering~(CausCF) method inspired by the widely adopted collaborative filtering~(CF) technique. It is based on the idea that similar users not only have a similar taste on items, but also have similar treatment effect under recommendations. CausCF extends the classical matrix factorization to the tensor factorization with three dimensions -- user, item, and treatment. Furthermore, we also employs regression discontinuity design (RDD) to evaluate the precision of the estimated causal effects from different models. With the testable assumptions, RDD analysis can provide an unbiased causal conclusion without RCT experiments. Through dedicated experiments on both the public datasets and the industrial application, we demonstrate the effectiveness of our proposed CausCF on the causal effect estimation and ranking performance improvement.
KCNet: An Insect-Inspired Single-Hidden-Layer Neural Network with Randomized Binary Weights for Prediction and Classification Tasks
Aug 17, 2021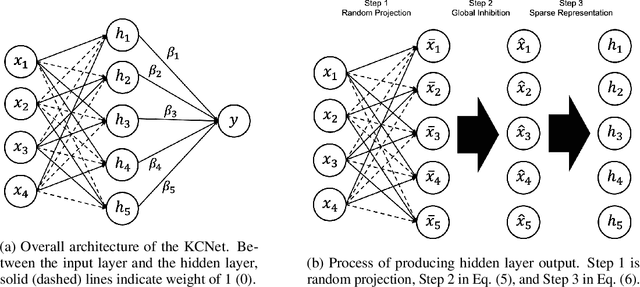
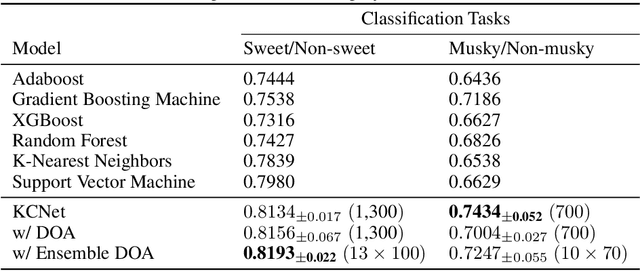
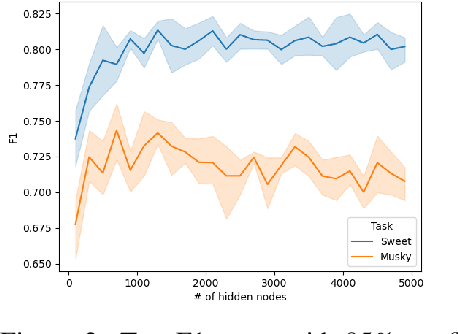
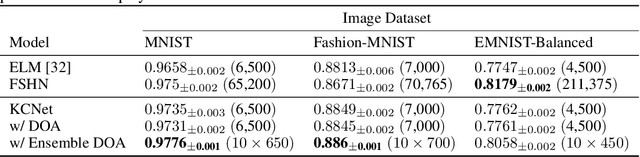
Fruit flies are established model systems for studying olfactory learning as they will readily learn to associate odors with both electric shock or sugar rewards. The mechanisms of the insect brain apparently responsible for odor learning form a relatively shallow neuronal architecture. Olfactory inputs are received by the antennal lobe (AL) of the brain, which produces an encoding of each odor mixture across ~50 sub-units known as glomeruli. Each of these glomeruli then project its component of this feature vector to several of ~2000 so-called Kenyon Cells (KCs) in a region of the brain known as the mushroom body (MB). Fly responses to odors are generated by small downstream neuropils that decode the higher-order representation from the MB. Research has shown that there is no recognizable pattern in the glomeruli--KC connections (and thus the particular higher-order representations); they are akin to fingerprints~-- even isogenic flies have different projections. Leveraging insights from this architecture, we propose KCNet, a single-hidden-layer neural network that contains sparse, randomized, binary weights between the input layer and the hidden layer and analytically learned weights between the hidden layer and the output layer. Furthermore, we also propose a dynamic optimization algorithm that enables the KCNet to increase performance beyond its structural limits by searching a more efficient set of inputs. For odorant-perception tasks that predict perceptual properties of an odorant, we show that KCNet outperforms existing data-driven approaches, such as XGBoost. For image-classification tasks, KCNet achieves reasonable performance on benchmark datasets (MNIST, Fashion-MNIST, and EMNIST) without any data-augmentation methods or convolutional layers and shows particularly fast running time. Thus, neural networks inspired by the insect brain can be both economical and perform well.