 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning words in groups: fusion algebras, tensor ranks and grokking
Sep 08, 2025In this work, we demonstrate that a simple two-layer neural network with standard activation functions can learn an arbitrary word operation in any finite group, provided sufficient width is available and exhibits grokking while doing so. To explain the mechanism by which this is achieved, we reframe the problem as that of learning a particular $3$-tensor, which we show is typically of low rank. A key insight is that low-rank implementations of this tensor can be obtained by decomposing it along triplets of basic self-conjugate representations of the group and leveraging the fusion structure to rule out many components. Focusing on a phenomenologically similar but more tractable surrogate model, we show that the network is able to find such low-rank implementations (or approximations thereof), thereby using limited width to approximate the word-tensor in a generalizable way. In the case of the simple multiplication word, we further elucidate the form of these low-rank implementations, showing that the network effectively implements efficient matrix multiplication in the sense of Strassen. Our work also sheds light on the mechanism by which a network reaches such a solution under gradient descent.
You Better Look Twice: a new perspective for designing accurate detectors with reduced computations
Aug 03, 2021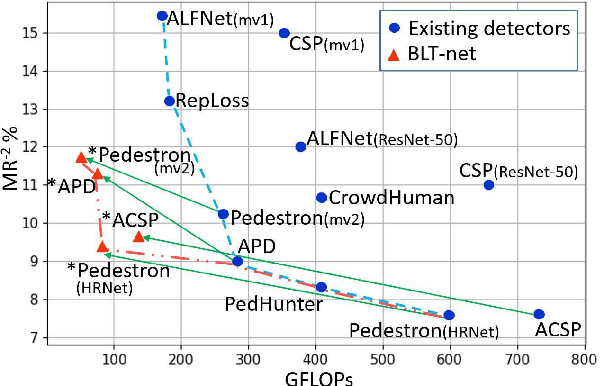
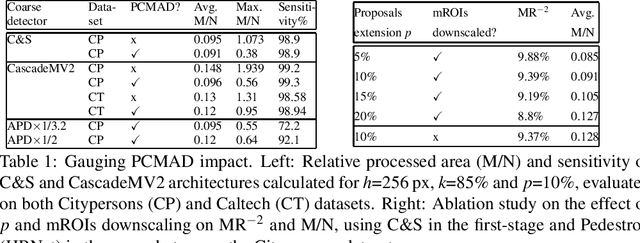
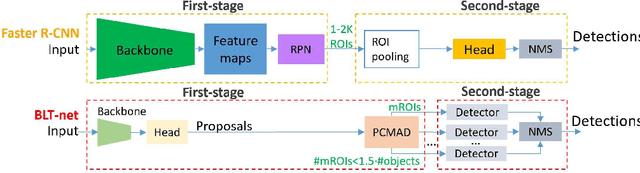
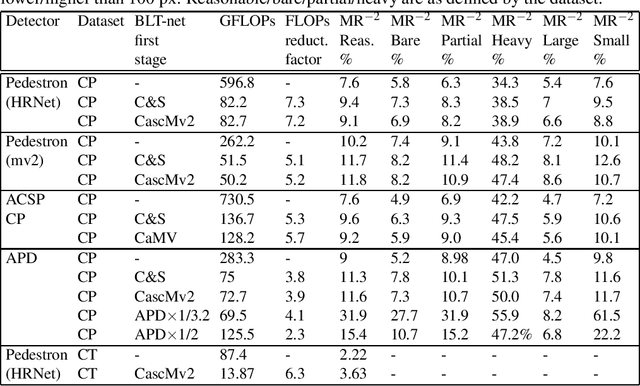
General object detectors use powerful backbones that uniformly extract features from images for enabling detection of a vast amount of object types. However, utilization of such backbones in object detection applications developed for specific object types can unnecessarily over-process an extensive amount of background. In addition, they are agnostic to object scales, thus redundantly process all image regions at the same resolution. In this work we introduce BLT-net, a new low-computation two-stage object detection architecture designed to process images with a significant amount of background and objects of variate scales. BLT-net reduces computations by separating objects from background using a very lite first-stage. BLT-net then efficiently merges obtained proposals to further decrease processed background and then dynamically reduces their resolution to minimize computations. Resulting image proposals are then processed in the second-stage by a highly accurate model. We demonstrate our architecture on the pedestrian detection problem, where objects are of different sizes, images are of high resolution and object detection is required to run in real-time. We show that our design reduces computations by a factor of x4-x7 on the Citypersons and Caltech datasets with respect to leading pedestrian detectors, on account of a small accuracy degradation. This method can be applied on other object detection applications in scenes with a considerable amount of background and variate object sizes to reduce computations.