 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting COVID-19 Patient Shielding: A Comprehensive Study
Oct 01, 2021
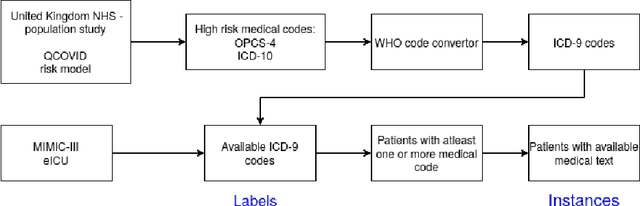
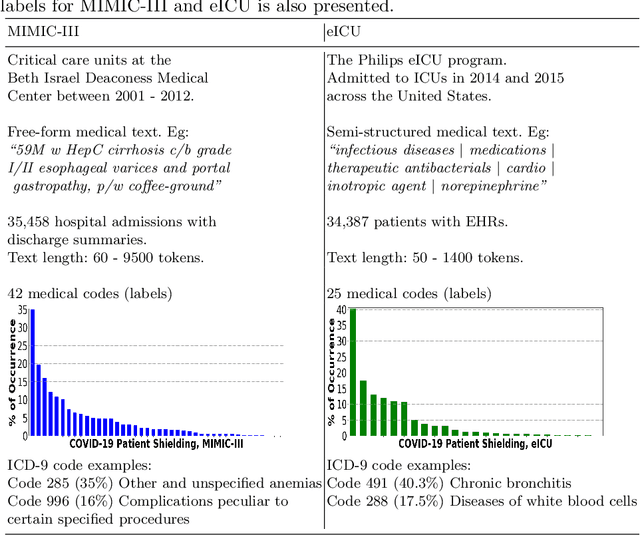
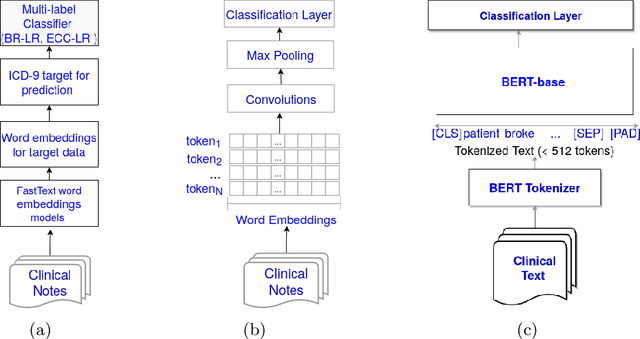

There are many ways machine learning and big data analytics are used in the fight against the COVID-19 pandemic, including predictions, risk management, diagnostics, and prevention. This study focuses on predicting COVID-19 patient shielding -- identifying and protecting patients who are clinically extremely vulnerable from coronavirus. This study focuses on techniques used for the multi-label classification of medical text. Using the information published by the United Kingdom NHS and the World Health Organisation, we present a novel approach to predicting COVID-19 patient shielding as a multi-label classification problem. We use publicly available, de-identified ICU medical text data for our experiments. The labels are derived from the published COVID-19 patient shielding data. We present an extensive comparison across 12 multi-label classifiers from the simple binary relevance to neural networks and the most recent transformers. To the best of our knowledge this is the first comprehensive study, where such a range of multi-label classifiers for medical text are considered. We highlight the benefits of various approaches, and argue that, for the task at hand, both predictive accuracy and processing time are essential.
* Accepted in AJCAI 2021
Computational Paremiology: Charting the temporal, ecological dynamics of proverb use in books, news articles, and tweets
Jul 10, 2021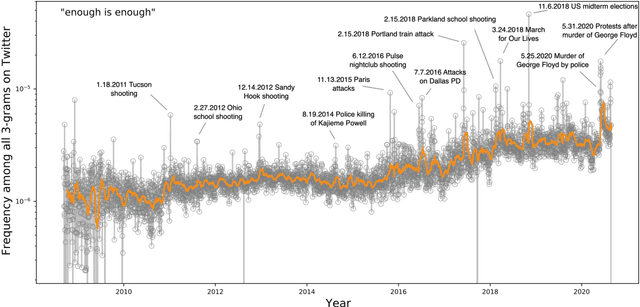
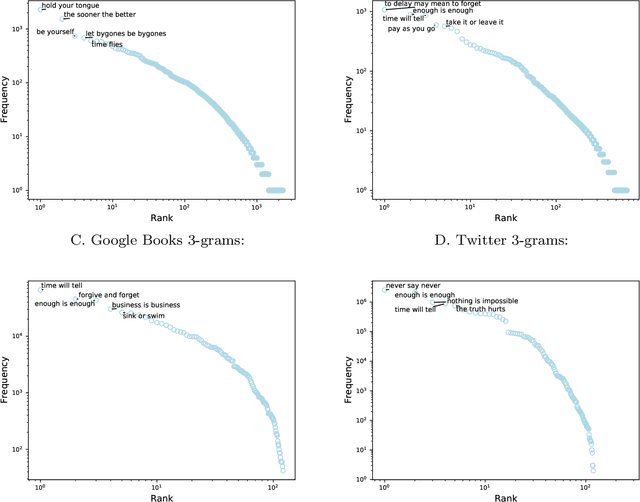
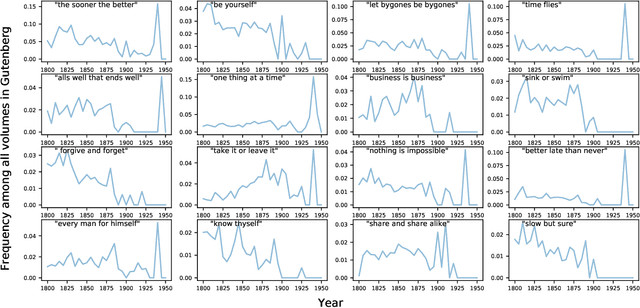
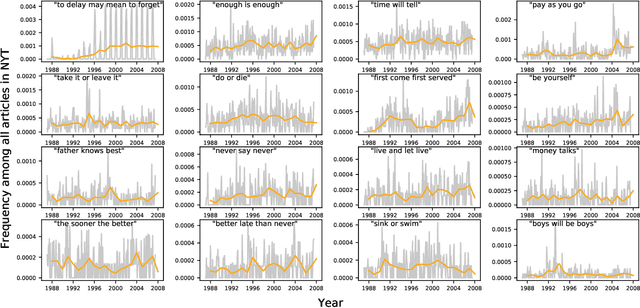
Proverbs are an essential component of language and culture, and though much attention has been paid to their history and currency, there has been comparatively little quantitative work on changes in the frequency with which they are used over time. With wider availability of large corpora reflecting many diverse genres of documents, it is now possible to take a broad and dynamic view of the importance of the proverb. Here, we measure temporal changes in the relevance of proverbs within three corpora, differing in kind, scale, and time frame: Millions of books over centuries; hundreds of millions of news articles over twenty years; and billions of tweets over a decade. We find that proverbs present heavy-tailed frequency-of-usage rank distributions in each venue; exhibit trends reflecting the cultural dynamics of the eras covered; and have evolved into contemporary forms on social media.
Mechanical Chameleons: Evaluating the effects of a social robot's non-verbal behavior on social influence
Sep 02, 2021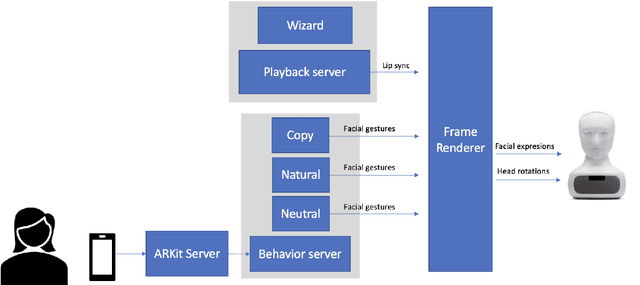

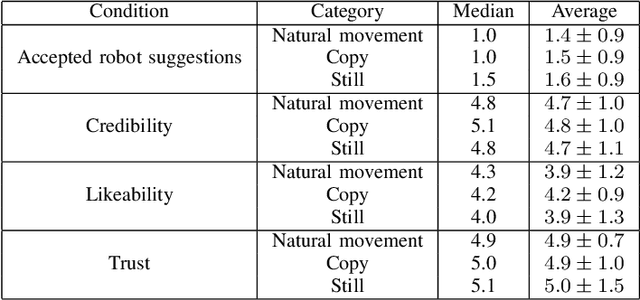
In this paper we present a pilot study which investigates how non-verbal behavior affects social influence in social robots. We also present a modular system which is capable of controlling the non-verbal behavior based on the interlocutor's facial gestures (head movements and facial expressions) in real time, and a study investigating whether three different strategies for facial gestures ("still", "natural movement", i.e. movements recorded from another conversation, and "copy", i.e. mimicking the user with a four second delay) has any affect on social influence and decision making in a "survival task". Our preliminary results show there was no significant difference between the three conditions, but this might be due to among other things a low number of study participants (12).
Label Assignment Distillation for Object Detection
Sep 18, 2021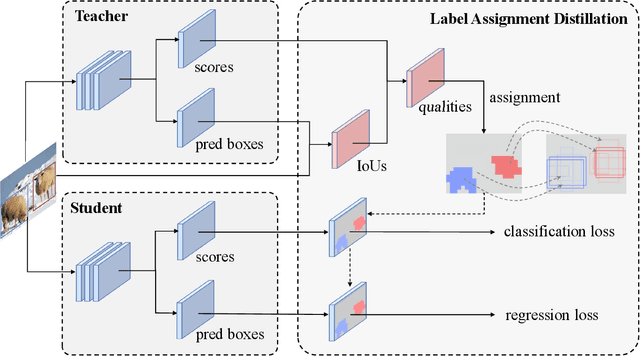
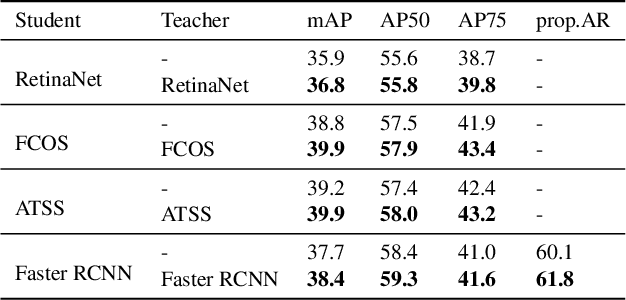
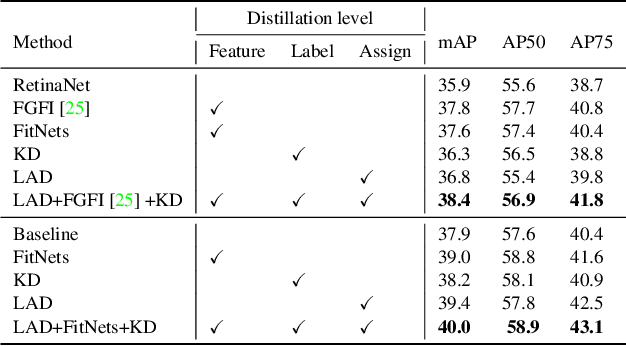

Knowledge distillation methods are proved to be promising in improving the performance of neural networks and no additional computational expenses are required during the inference time. For the sake of boosting the accuracy of object detection, a great number of knowledge distillation methods have been proposed particularly designed for object detection. However, most of these methods only focus on feature-level distillation and label-level distillation, leaving the label assignment step, a unique and paramount procedure for object detection, by the wayside. In this work, we come up with a simple but effective knowledge distillation approach focusing on label assignment in object detection, in which the positive and negative samples of student network are selected in accordance with the predictions of teacher network. Our method shows encouraging results on the MSCOCO2017 benchmark, and can not only be applied to both one-stage detectors and two-stage detectors but also be utilized orthogonally with other knowledge distillation methods.
Asymptotic Performance of Thompson Sampling in the Batched Multi-Armed Bandits
Oct 01, 2021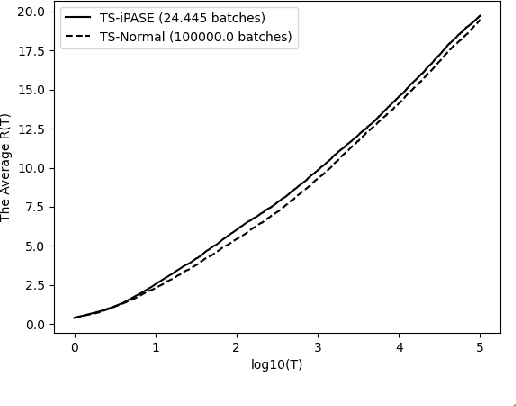
We study the asymptotic performance of the Thompson sampling algorithm in the batched multi-armed bandit setting where the time horizon $T$ is divided into batches, and the agent is not able to observe the rewards of her actions until the end of each batch. We show that in this batched setting, Thompson sampling achieves the same asymptotic performance as in the case where instantaneous feedback is available after each action, provided that the batch sizes increase subexponentially. This result implies that Thompson sampling can maintain its performance even if it receives delayed feedback in $\omega(\log T)$ batches. We further propose an adaptive batching scheme that reduces the number of batches to $\Theta(\log T)$ while maintaining the same performance. Although the batched multi-armed bandit setting has been considered in several recent works, previous results rely on tailored algorithms for the batched setting, which optimize the batch structure and prioritize exploration in the beginning of the experiment to eliminate suboptimal actions. We show that Thompson sampling, on the other hand, is able to achieve a similar asymptotic performance in the batched setting without any modifications.
* This work was presented in 2021 IEEE International Symposium on Information Theory (ISIT)
Meta Internal Learning
Oct 06, 2021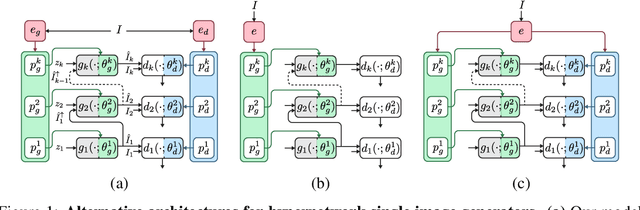
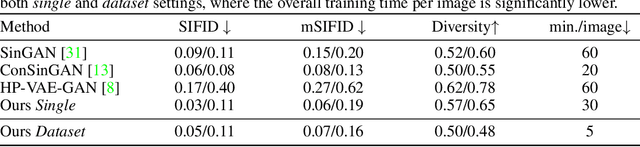


Internal learning for single-image generation is a framework, where a generator is trained to produce novel images based on a single image. Since these models are trained on a single image, they are limited in their scale and application. To overcome these issues, we propose a meta-learning approach that enables training over a collection of images, in order to model the internal statistics of the sample image more effectively. In the presented meta-learning approach, a single-image GAN model is generated given an input image, via a convolutional feedforward hypernetwork $f$. This network is trained over a dataset of images, allowing for feature sharing among different models, and for interpolation in the space of generative models. The generated single-image model contains a hierarchy of multiple generators and discriminators. It is therefore required to train the meta-learner in an adversarial manner, which requires careful design choices that we justify by a theoretical analysis. Our results show that the models obtained are as suitable as single-image GANs for many common image applications, significantly reduce the training time per image without loss in performance, and introduce novel capabilities, such as interpolation and feedforward modeling of novel images.
Pre-training Co-evolutionary Protein Representation via A Pairwise Masked Language Model
Oct 29, 2021

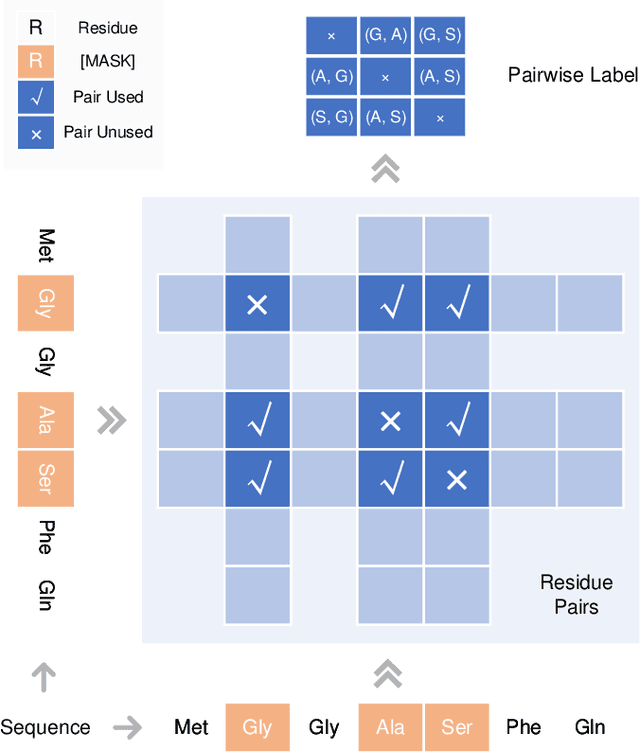

Understanding protein sequences is vital and urgent for biology, healthcare, and medicine. Labeling approaches are expensive yet time-consuming, while the amount of unlabeled data is increasing quite faster than that of the labeled data due to low-cost, high-throughput sequencing methods. In order to extract knowledge from these unlabeled data, representation learning is of significant value for protein-related tasks and has great potential for helping us learn more about protein functions and structures. The key problem in the protein sequence representation learning is to capture the co-evolutionary information reflected by the inter-residue co-variation in the sequences. Instead of leveraging multiple sequence alignment as is usually done, we propose a novel method to capture this information directly by pre-training via a dedicated language model, i.e., Pairwise Masked Language Model (PMLM). In a conventional masked language model, the masked tokens are modeled by conditioning on the unmasked tokens only, but processed independently to each other. However, our proposed PMLM takes the dependency among masked tokens into consideration, i.e., the probability of a token pair is not equal to the product of the probability of the two tokens. By applying this model, the pre-trained encoder is able to generate a better representation for protein sequences. Our result shows that the proposed method can effectively capture the inter-residue correlations and improves the performance of contact prediction by up to 9% compared to the MLM baseline under the same setting. The proposed model also significantly outperforms the MSA baseline by more than 7% on the TAPE contact prediction benchmark when pre-trained on a subset of the sequence database which the MSA is generated from, revealing the potential of the sequence pre-training method to surpass MSA based methods in general.
A-star path planning simulation for UAS Traffic Management (UTM) application
Jul 27, 2021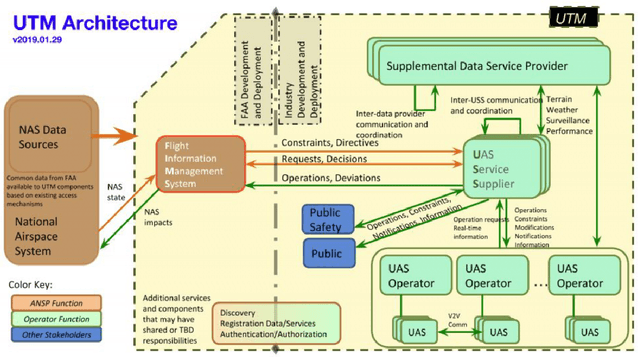
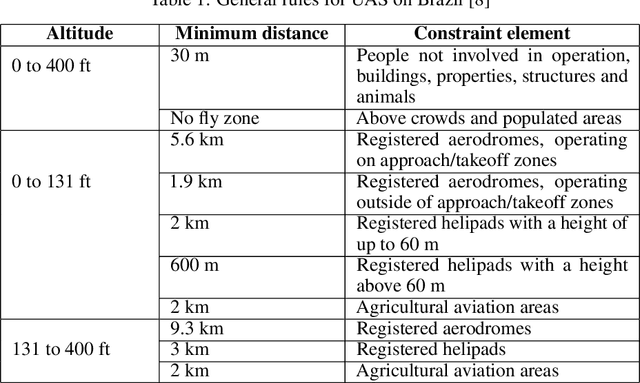
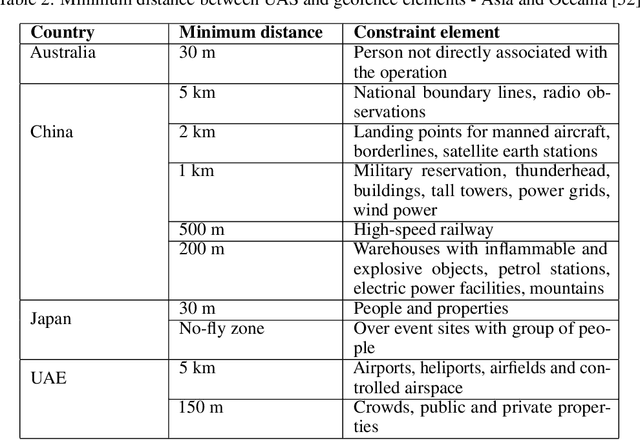
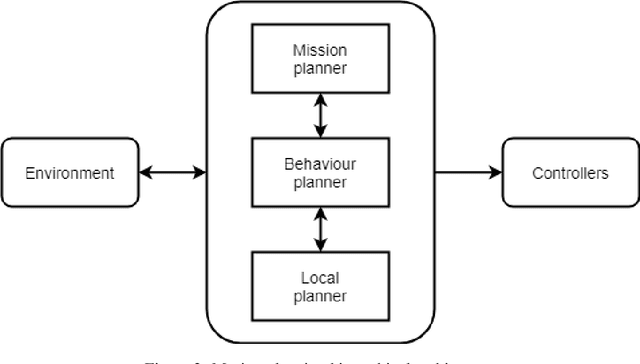
This paper presents a Robot Operating System and Gazebo application to calculate and simulate an optimal route for a drone in an urban environment by developing new ROS packages and executing them along with open-source tools. Firstly, the current regulations about UAS are presented to guide the building of the simulated environment, and multiple path planning algorithms are reviewed to guide the search method selection. After selecting the A-star algorithm, both the 2D and 3D versions of them were implemented in this paper, with both Manhattan and Euclidean distances heuristics. The performance of these algorithms was evaluated considering the distance to be covered by the drone and the execution time of the route planning method, aiming to support algorithm's choice based on the environment in which it will be applied. The algorithm execution time was 3.2 and 17.2 higher when using the Euclidean distance for the 2D and 3D A-star algorithm, respectively. Along with the performance analysis of the algorithm, this paper is also the first step for building a complete UAS Traffic Management (UTM) system simulation using ROS and Gazebo.
HPOBench: A Collection of Reproducible Multi-Fidelity Benchmark Problems for HPO
Sep 14, 2021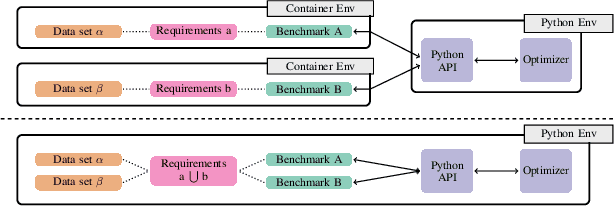
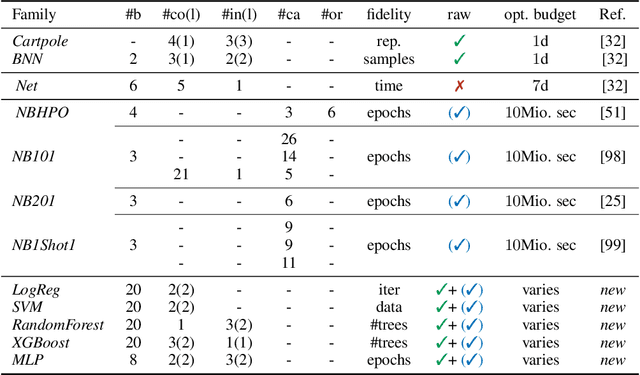

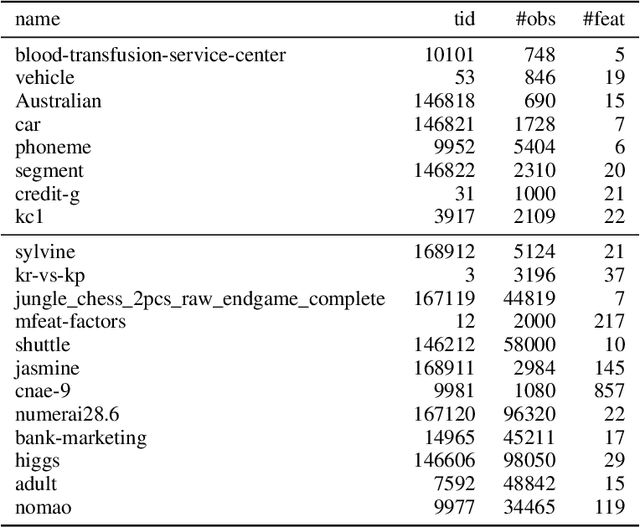
To achieve peak predictive performance, hyperparameter optimization (HPO) is a crucial component of machine learning and its applications. Over the last years,the number of efficient algorithms and tools for HPO grew substantially. At the same time, the community is still lacking realistic, diverse, computationally cheap,and standardized benchmarks. This is especially the case for multi-fidelity HPO methods. To close this gap, we propose HPOBench, which includes 7 existing and 5 new benchmark families, with in total more than 100 multi-fidelity benchmark problems. HPOBench allows to run this extendable set of multi-fidelity HPO benchmarks in a reproducible way by isolating and packaging the individual benchmarks in containers. It also provides surrogate and tabular benchmarks for computationally affordable yet statistically sound evaluations. To demonstrate the broad compatibility of HPOBench and its usefulness, we conduct an exemplary large-scale study evaluating 6 well known multi-fidelity HPO tools.
Generative Adversarial Imitation Learning for End-to-End Autonomous Driving on Urban Environments
Oct 16, 2021
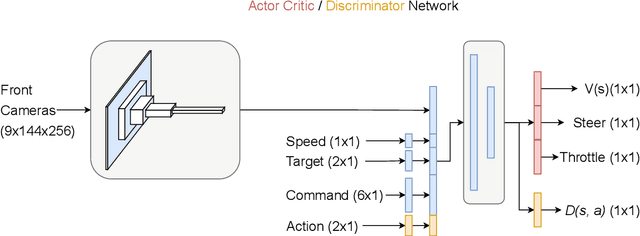

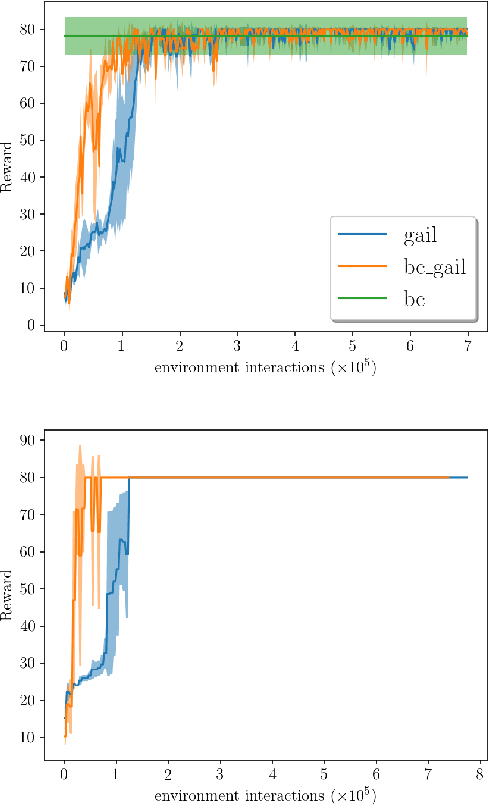
Autonomous driving is a complex task, which has been tackled since the first self-driving car ALVINN in 1989, with a supervised learning approach, or behavioral cloning (BC). In BC, a neural network is trained with state-action pairs that constitute the training set made by an expert, i.e., a human driver. However, this type of imitation learning does not take into account the temporal dependencies that might exist between actions taken in different moments of a navigation trajectory. These type of tasks are better handled by reinforcement learning (RL) algorithms, which need to define a reward function. On the other hand, more recent approaches to imitation learning, such as Generative Adversarial Imitation Learning (GAIL), can train policies without explicitly requiring to define a reward function, allowing an agent to learn by trial and error directly on a training set of expert trajectories. In this work, we propose two variations of GAIL for autonomous navigation of a vehicle in the realistic CARLA simulation environment for urban scenarios. Both of them use the same network architecture, which process high dimensional image input from three frontal cameras, and other nine continuous inputs representing the velocity, the next point from the sparse trajectory and a high-level driving command. We show that both of them are capable of imitating the expert trajectory from start to end after training ends, but the GAIL loss function that is augmented with BC outperforms the former in terms of convergence time and training stability.