 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDehallu3D: Hallucination-Mitigated 3D Generation from Single Image via Cyclic View Consistency Refinement
Mar 02, 2026Large 3D reconstruction models have revolutionized the 3D content generation field, enabling broad applications in virtual reality and gaming. Just like other large models, large 3D reconstruction models suffer from hallucinations as well, introducing structural outliers (e.g., odd holes or protrusions) that deviate from the input data. However, unlike other large models, hallucinations in large 3D reconstruction models remain severely underexplored, leading to malformed 3D-printed objects or insufficient immersion in virtual scenes. Such hallucinations majorly originate from that existing methods reconstruct 3D content from sparsely generated multi-view images which suffer from large viewpoint gaps and discontinuities. To mitigate hallucinations by eliminating the outliers, we propose Dehallu3D for 3D mesh generation. Our key idea is to design a balanced multi-view continuity constraint to enforce smooth transitions across dense intermediate viewpoints, while avoiding over-smoothing that could erase sharp geometric features. Therefore, Dehallu3D employs a plug-and-play optimization module with two key constraints: (i) adjacent consistency to ensure geometric continuity across views, and (ii) adaptive smoothness to retain fine details.We further propose the Outlier Risk Measure (ORM) metric to quantify geometric fidelity in 3D generation from the perspective of outliers. Extensive experiments show that Dehallu3D achieves high-fidelity 3D generation by effectively preserving structural details while removing hallucinated outliers.
Label Assignment Distillation for Object Detection
Sep 18, 2021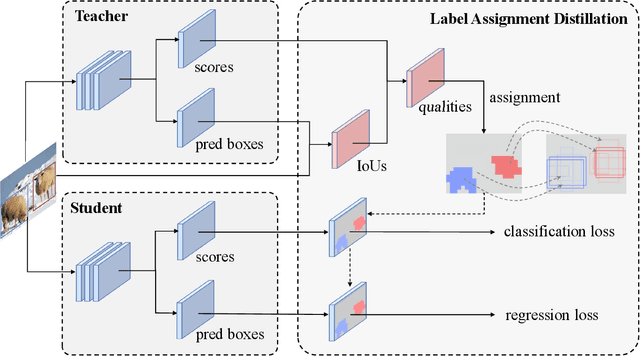
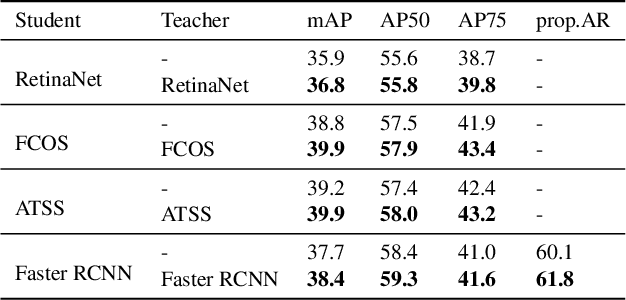
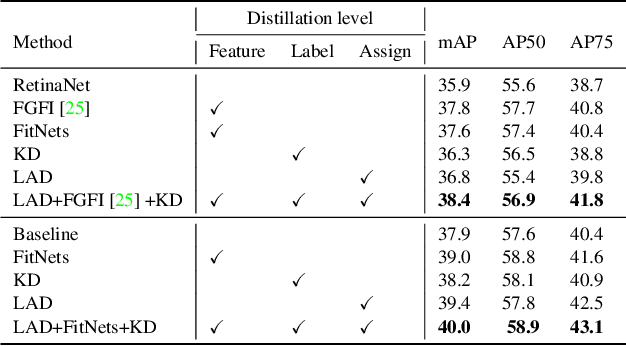

Knowledge distillation methods are proved to be promising in improving the performance of neural networks and no additional computational expenses are required during the inference time. For the sake of boosting the accuracy of object detection, a great number of knowledge distillation methods have been proposed particularly designed for object detection. However, most of these methods only focus on feature-level distillation and label-level distillation, leaving the label assignment step, a unique and paramount procedure for object detection, by the wayside. In this work, we come up with a simple but effective knowledge distillation approach focusing on label assignment in object detection, in which the positive and negative samples of student network are selected in accordance with the predictions of teacher network. Our method shows encouraging results on the MSCOCO2017 benchmark, and can not only be applied to both one-stage detectors and two-stage detectors but also be utilized orthogonally with other knowledge distillation methods.
HLSGD Hierarchical Local SGD With Stale Gradients Featuring
Sep 06, 2020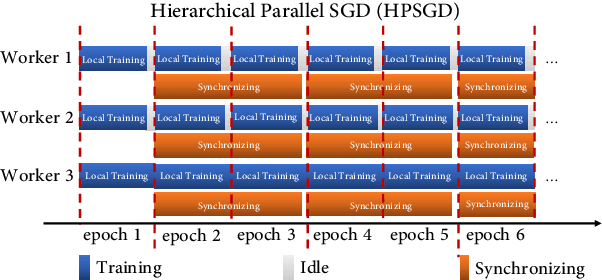
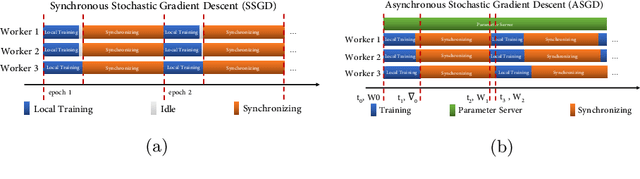
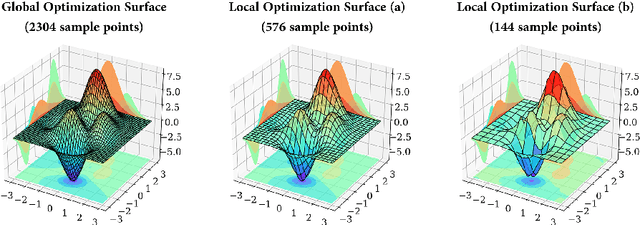
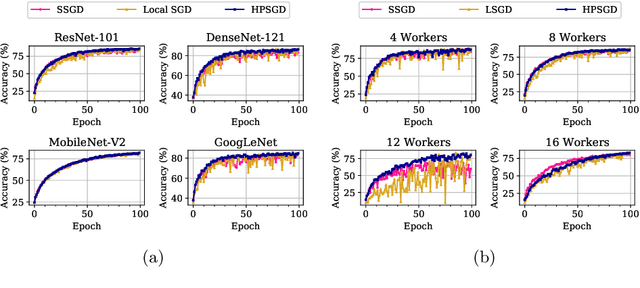
While distributed training significantly speeds up the training process of the deep neural network (DNN), the utilization of the cluster is relatively low due to the time-consuming data synchronizing between workers. To alleviate this problem, a novel Hierarchical Parallel SGD (HPSGD) strategy is proposed based on the observation that the data synchronization phase can be paralleled with the local training phase (i.e., Feed-forward and back-propagation). Furthermore, an improved model updating method is unitized to remedy the introduced stale gradients problem, which commits updates to the replica (i.e., a temporary model that has the same parameters as the global model) and then merges the average changes to the global model. Extensive experiments are conducted to demonstrate that the proposed HPSGD approach substantially boosts the distributed DNN training, reduces the disturbance of the stale gradients and achieves better accuracy in given fixed wall-time.