 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs One Layer Enough? Understanding Inference Dynamics in Tabular Foundation Models
May 07, 2026Transformer-based tabular foundation models (TFMs) dominate small to medium tabular predictive benchmark tasks, yet their inference mechanisms remain largely unexplored. We present the first large-scale mechanistic study of layerwise dynamics in 6 state-of-the-art tabular in-context learning models. We explore how predictions emerge across depth, identify distinct stages of inference and reveal latent-space dynamics that differ from those of language models. Our findings indicate substantial depthwise redundancy across multiple models, suggesting iterative refinement with overlapping computations during inference stages. Guided by these insights, we design a proof-of-concept, looped single-layer model that uses only 20% of the original model's parameters while achieving comparable performance. The code is available at https://github.com/amirbalef/is_one_layer_enough.
Best Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025



Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
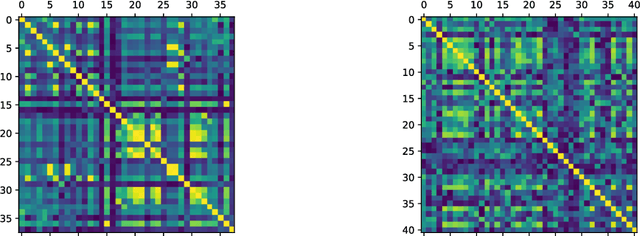
Towards Understanding Layer Contributions in Tabular In-Context Learning Models
Nov 19, 2025Despite the architectural similarities between tabular in-context learning (ICL) models and large language models (LLMs), little is known about how individual layers contribute to tabular prediction. In this paper, we investigate how the latent spaces evolve across layers in tabular ICL models, identify potential redundant layers, and compare these dynamics with those observed in LLMs. We analyze TabPFN and TabICL through the "layers as painters" perspective, finding that only subsets of layers share a common representational language, suggesting structural redundancy and offering opportunities for model compression and improved interpretability.
carps: A Framework for Comparing N Hyperparameter Optimizers on M Benchmarks
Jun 06, 2025



Hyperparameter Optimization (HPO) is crucial to develop well-performing machine learning models. In order to ease prototyping and benchmarking of HPO methods, we propose carps, a benchmark framework for Comprehensive Automated Research Performance Studies allowing to evaluate N optimizers on M benchmark tasks. In this first release of carps, we focus on the four most important types of HPO task types: blackbox, multi-fidelity, multi-objective and multi-fidelity-multi-objective. With 3 336 tasks from 5 community benchmark collections and 28 variants of 9 optimizer families, we offer the biggest go-to library to date to evaluate and compare HPO methods. The carps framework relies on a purpose-built, lightweight interface, gluing together optimizers and benchmark tasks. It also features an analysis pipeline, facilitating the evaluation of optimizers on benchmarks. However, navigating a huge number of tasks while developing and comparing methods can be computationally infeasible. To address this, we obtain a subset of representative tasks by minimizing the star discrepancy of the subset, in the space spanned by the full set. As a result, we propose an initial subset of 10 to 30 diverse tasks for each task type, and include functionality to re-compute subsets as more benchmarks become available, enabling efficient evaluations. We also establish a first set of baseline results on these tasks as a measure for future comparisons. With carps (https://www.github.com/automl/CARP-S), we make an important step in the standardization of HPO evaluation.
Put CASH on Bandits: A Max K-Armed Problem for Automated Machine Learning
May 08, 2025



The Combined Algorithm Selection and Hyperparameter optimization (CASH) is a challenging resource allocation problem in the field of AutoML. We propose MaxUCB, a max $k$-armed bandit method to trade off exploring different model classes and conducting hyperparameter optimization. MaxUCB is specifically designed for the light-tailed and bounded reward distributions arising in this setting and, thus, provides an efficient alternative compared to classic max $k$-armed bandit methods assuming heavy-tailed reward distributions. We theoretically and empirically evaluate our method on four standard AutoML benchmarks, demonstrating superior performance over prior approaches.
Position Paper: Rethinking Empirical Research in Machine Learning: Addressing Epistemic and Methodological Challenges of Experimentation
May 03, 2024We warn against a common but incomplete understanding of empirical research in machine learning (ML) that leads to non-replicable results, makes findings unreliable, and threatens to undermine progress in the field. To overcome this alarming situation, we call for more awareness of the plurality of ways of gaining knowledge experimentally but also of some epistemic limitations. In particular, we argue most current empirical ML research is fashioned as confirmatory research while it should rather be considered exploratory.
Can Fairness be Automated? Guidelines and Opportunities for Fairness-aware AutoML
Mar 15, 2023


The field of automated machine learning (AutoML) introduces techniques that automate parts of the development of machine learning (ML) systems, accelerating the process and reducing barriers for novices. However, decisions derived from ML models can reproduce, amplify, or even introduce unfairness in our societies, causing harm to (groups of) individuals. In response, researchers have started to propose AutoML systems that jointly optimize fairness and predictive performance to mitigate fairness-related harm. However, fairness is a complex and inherently interdisciplinary subject, and solely posing it as an optimization problem can have adverse side effects. With this work, we aim to raise awareness among developers of AutoML systems about such limitations of fairness-aware AutoML, while also calling attention to the potential of AutoML as a tool for fairness research. We present a comprehensive overview of different ways in which fairness-related harm can arise and the ensuing implications for the design of fairness-aware AutoML. We conclude that while fairness cannot be automated, fairness-aware AutoML can play an important role in the toolbox of an ML practitioner. We highlight several open technical challenges for future work in this direction. Additionally, we advocate for the creation of more user-centered assistive systems designed to tackle challenges encountered in fairness work.
Mind the Gap: Measuring Generalization Performance Across Multiple Objectives
Dec 08, 2022



Modern machine learning models are often constructed taking into account multiple objectives, e.g., to minimize inference time while also maximizing accuracy. Multi-objective hyperparameter optimization (MHPO) algorithms return such candidate models and the approximation of the Pareto front is used to assess their performance. However, when estimating generalization performance of an approximation of a Pareto front found on a validation set by computing the performance of the individual models on the test set, models might no longer be Pareto-optimal. This makes it unclear how to measure performance. To resolve this, we provide a novel evaluation protocol that allows measuring the generalization performance of MHPO methods and to study its capabilities for comparing two optimization experiments.
Meta-Learning a Real-Time Tabular AutoML Method For Small Data
Jul 05, 2022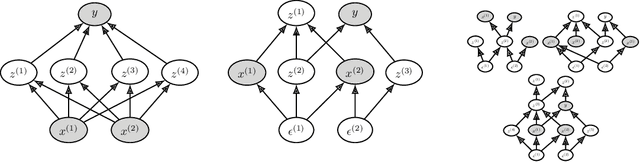

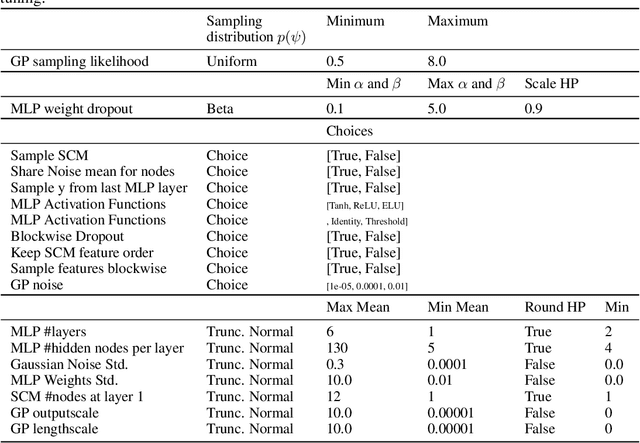
We present TabPFN, an AutoML method that is competitive with the state of the art on small tabular datasets while being over 1,000$\times$ faster. Our method is very simple: it is fully entailed in the weights of a single neural network, and a single forward pass directly yields predictions for a new dataset. Our AutoML method is meta-learned using the Transformer-based Prior-Data Fitted Network (PFN) architecture and approximates Bayesian inference with a prior that is based on assumptions of simplicity and causal structures. The prior contains a large space of structural causal models and Bayesian neural networks with a bias for small architectures and thus low complexity. Furthermore, we extend the PFN approach to differentiably calibrate the prior's hyperparameters on real data. By doing so, we separate our abstract prior assumptions from their heuristic calibration on real data. Afterwards, the calibrated hyperparameters are fixed and TabPFN can be applied to any new tabular dataset at the push of a button. Finally, on 30 datasets from the OpenML-CC18 suite we show that our method outperforms boosted trees and performs on par with complex state-of-the-art AutoML systems with predictions produced in less than a second. We provide all our code and our final trained TabPFN in the supplementary materials.
SMAC3: A Versatile Bayesian Optimization Package for Hyperparameter Optimization
Sep 20, 2021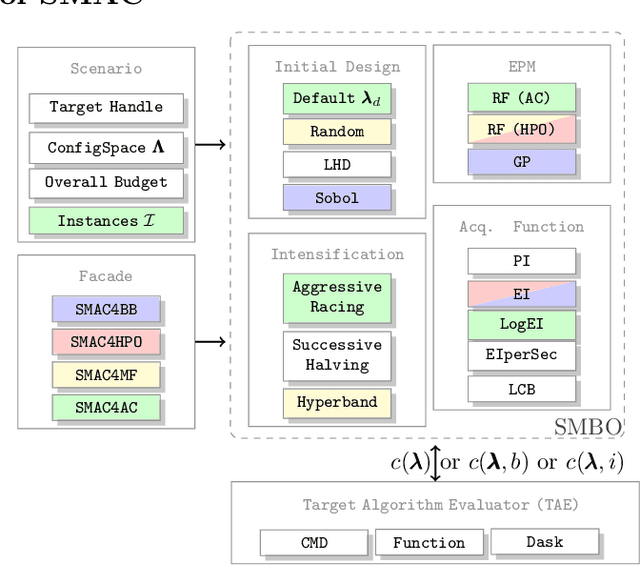
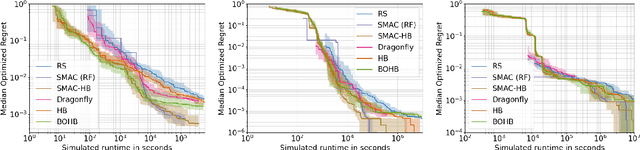
Algorithm parameters, in particular hyperparameters of machine learning algorithms, can substantially impact their performance. To support users in determining well-performing hyperparameter configurations for their algorithms, datasets and applications at hand, SMAC3 offers a robust and flexible framework for Bayesian Optimization, which can improve performance within a few evaluations. It offers several facades and pre-sets for typical use cases, such as optimizing hyperparameters, solving low dimensional continuous (artificial) global optimization problems and configuring algorithms to perform well across multiple problem instances. The SMAC3 package is available under a permissive BSD-license at https://github.com/automl/SMAC3.