 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOusiometrics and Telegnomics: The essence of meaning conforms to a two-dimensional powerful-weak and dangerous-safe framework with diverse corpora presenting a safety bias
Oct 13, 2021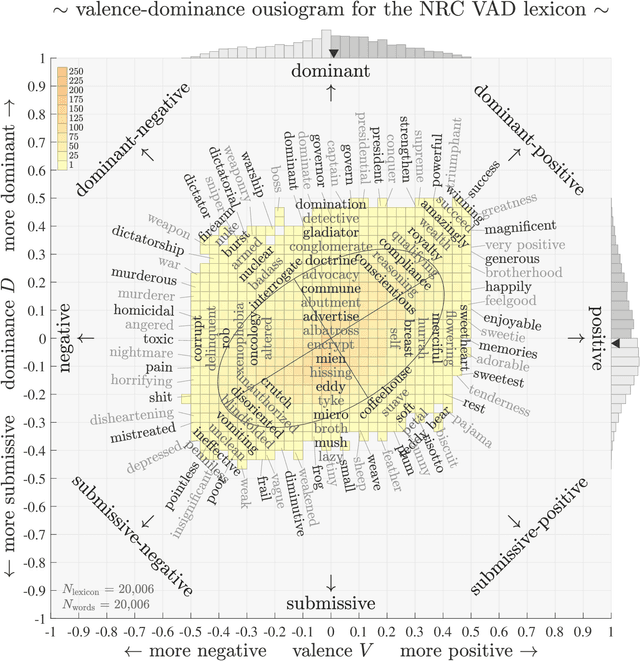
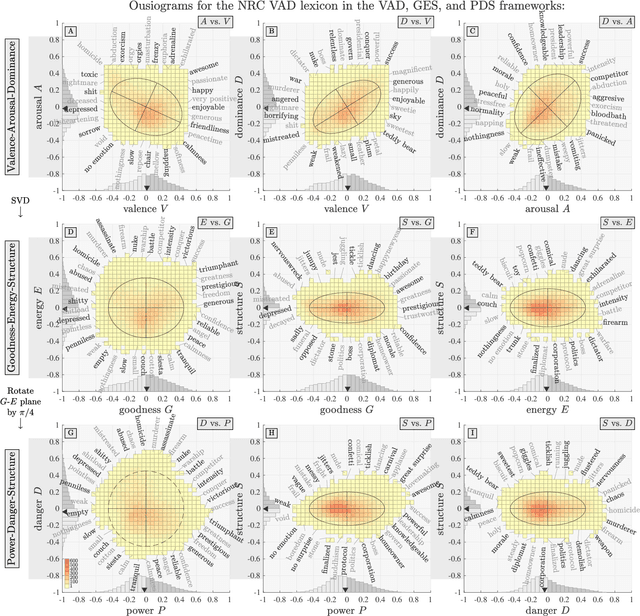
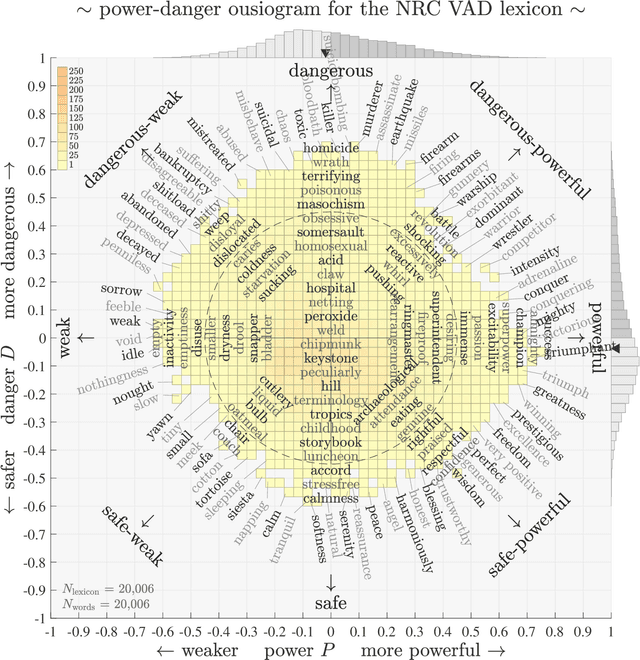
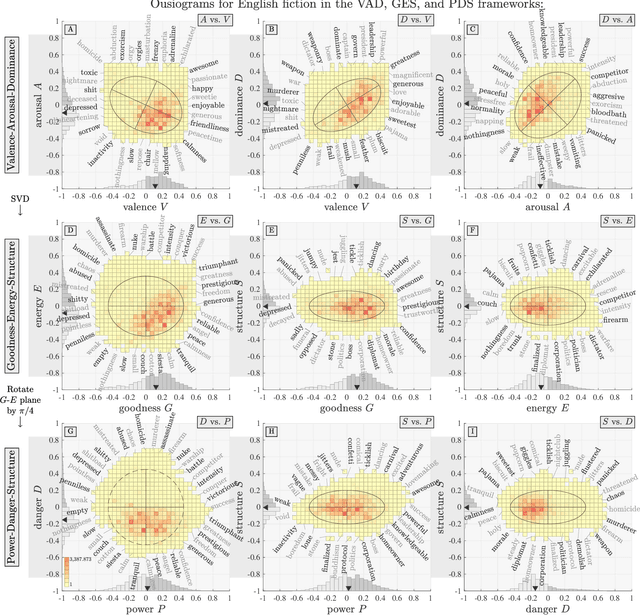
We define `ousiometrics' to be the study of essential meaning in whatever context that meaningful signals are communicated, and `telegnomics' as the study of remotely sensed knowledge. From work emerging through the middle of the 20th century, the essence of meaning has become generally accepted as being well captured by the three orthogonal dimensions of evaluation, potency, and activation (EPA). By re-examining first types and then tokens for the English language, and through the use of automatically annotated histograms -- `ousiograms' -- we find here that: 1. The essence of meaning conveyed by words is instead best described by a compass-like power-danger (PD) framework, and 2. Analysis of a disparate collection of large-scale English language corpora -- literature, news, Wikipedia, talk radio, and social media -- shows that natural language exhibits a systematic bias toward safe, low danger words -- a reinterpretation of the Pollyanna principle's positivity bias for written expression. To help justify our choice of dimension names and to help address the problems with representing observed ousiometric dimensions by bipolar adjective pairs, we introduce and explore `synousionyms' and `antousionyms' -- ousiometric counterparts of synonyms and antonyms. We further show that the PD framework revises the circumplex model of affect as a more general model of state of mind. Finally, we use our findings to construct and test a prototype `ousiometer', a telegnomic instrument that measures ousiometric time series for temporal corpora. We contend that our power-danger ousiometric framework provides a complement for entropy-based measurements, and may be of value for the study of a wide variety of communication across biological and artificial life.
Computational Paremiology: Charting the temporal, ecological dynamics of proverb use in books, news articles, and tweets
Jul 10, 2021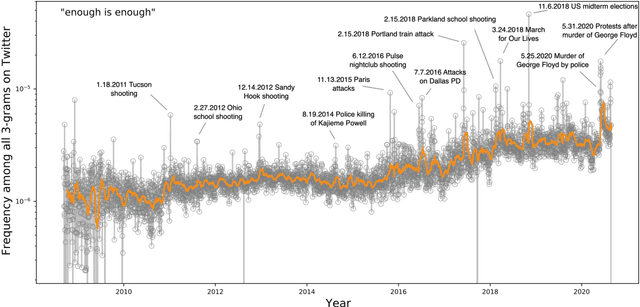
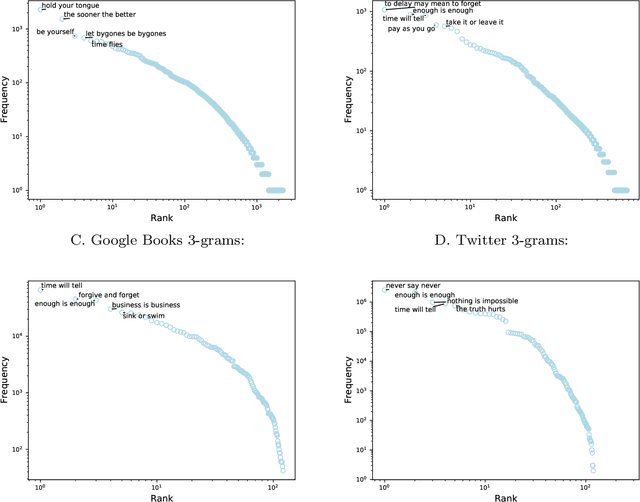
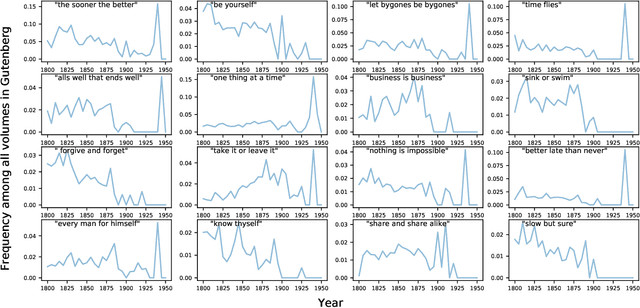
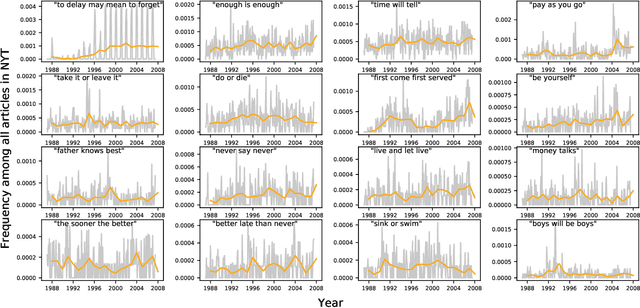
Proverbs are an essential component of language and culture, and though much attention has been paid to their history and currency, there has been comparatively little quantitative work on changes in the frequency with which they are used over time. With wider availability of large corpora reflecting many diverse genres of documents, it is now possible to take a broad and dynamic view of the importance of the proverb. Here, we measure temporal changes in the relevance of proverbs within three corpora, differing in kind, scale, and time frame: Millions of books over centuries; hundreds of millions of news articles over twenty years; and billions of tweets over a decade. We find that proverbs present heavy-tailed frequency-of-usage rank distributions in each venue; exhibit trends reflecting the cultural dynamics of the eras covered; and have evolved into contemporary forms on social media.
Reply to Garcia et al.: Common mistakes in measuring frequency dependent word characteristics
May 28, 2015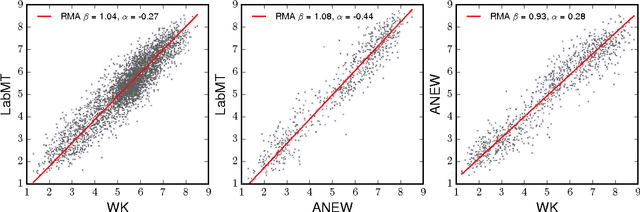
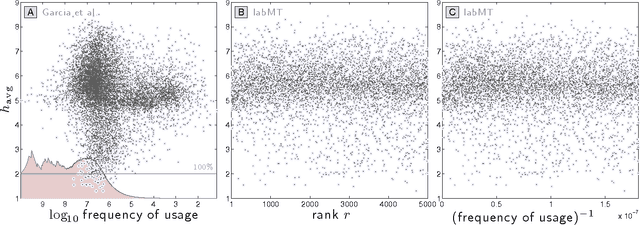
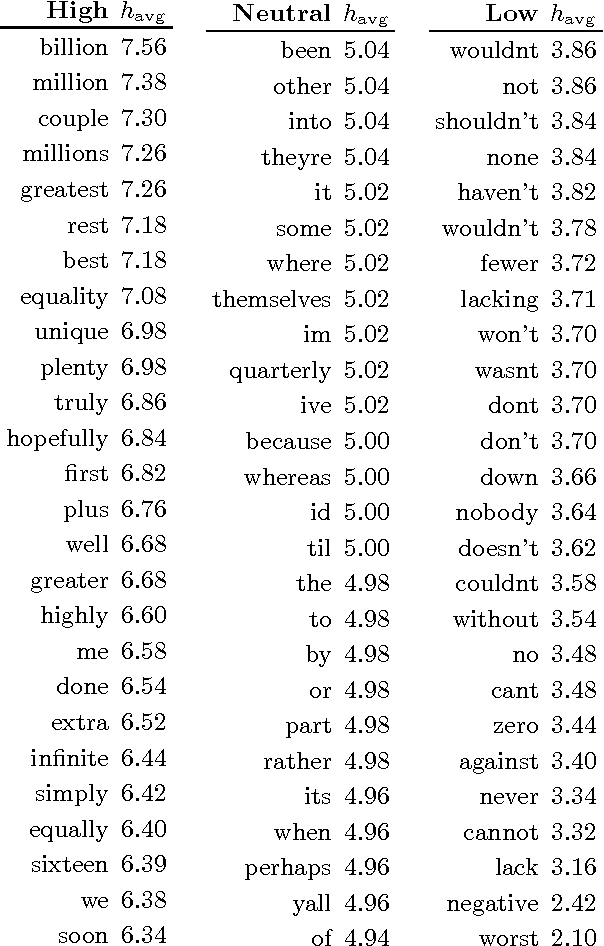
We demonstrate that the concerns expressed by Garcia et al. are misplaced, due to (1) a misreading of our findings in [1]; (2) a widespread failure to examine and present words in support of asserted summary quantities based on word usage frequencies; and (3) a range of misconceptions about word usage frequency, word rank, and expert-constructed word lists. In particular, we show that the English component of our study compares well statistically with two related surveys, that no survey design influence is apparent, and that estimates of measurement error do not explain the positivity biases reported in our work and that of others. We further demonstrate that for the frequency dependence of positivity---of which we explored the nuances in great detail in [1]---Garcia et al. did not perform a reanalysis of our data---they instead carried out an analysis of a different, statistically improper data set and introduced a nonlinearity before performing linear regression.