 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Domain-adaptive Hash for Networks
Aug 20, 2021
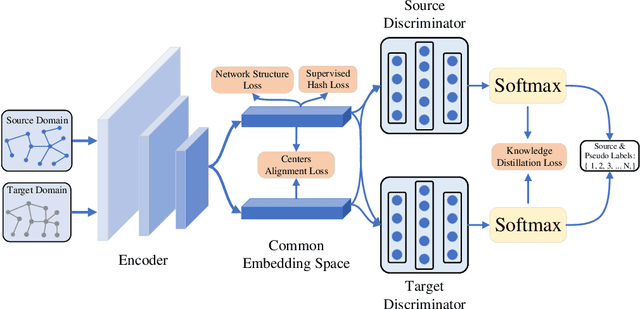
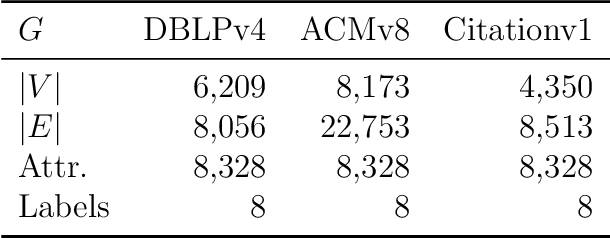
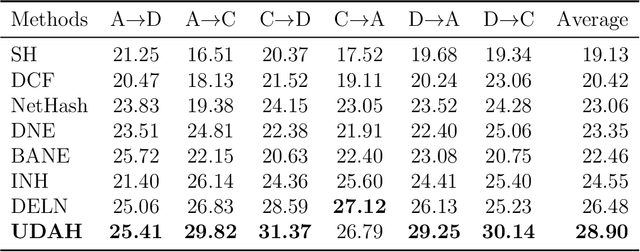
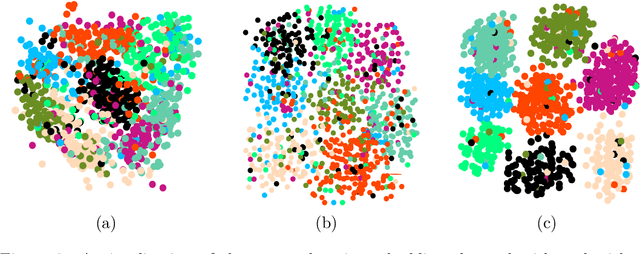
Abundant real-world data can be naturally represented by large-scale networks, which demands efficient and effective learning algorithms. At the same time, labels may only be available for some networks, which demands these algorithms to be able to adapt to unlabeled networks. Domain-adaptive hash learning has enjoyed considerable success in the computer vision community in many practical tasks due to its lower cost in both retrieval time and storage footprint. However, it has not been applied to multiple-domain networks. In this work, we bridge this gap by developing an unsupervised domain-adaptive hash learning method for networks, dubbed UDAH. Specifically, we develop four {task-specific yet correlated} components: (1) network structure preservation via a hard groupwise contrastive loss, (2) relaxation-free supervised hashing, (3) cross-domain intersected discriminators, and (4) semantic center alignment. We conduct a wide range of experiments to evaluate the effectiveness and efficiency of our method on a range of tasks including link prediction, node classification, and neighbor recommendation. Our evaluation results demonstrate that our model achieves better performance than the state-of-the-art conventional discrete embedding methods over all the tasks.
Deep Identification of Nonlinear Systems in Koopman Form
Oct 06, 2021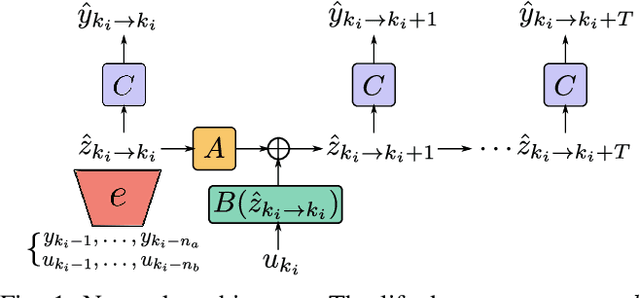
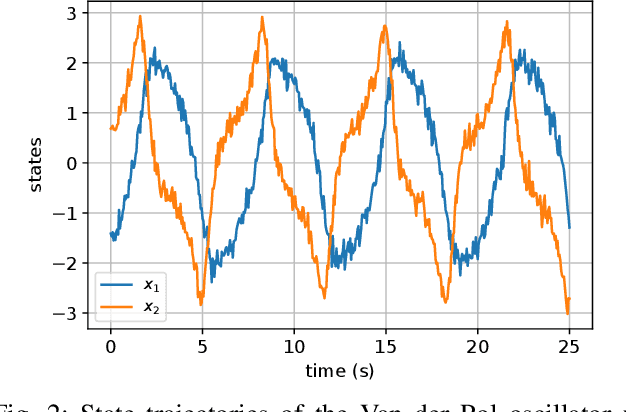
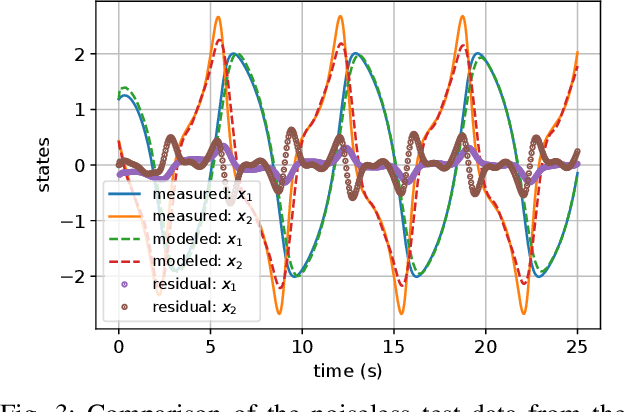
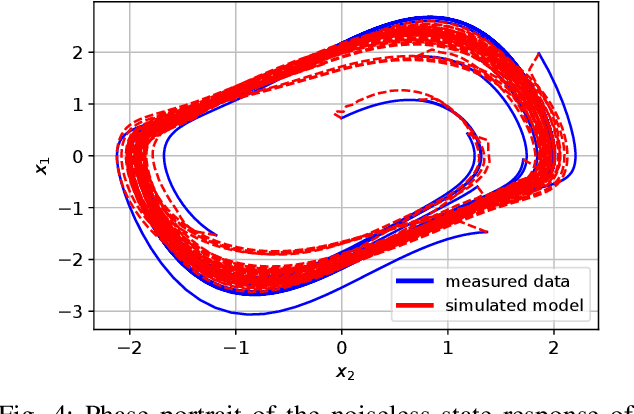
The present paper treats the identification of nonlinear dynamical systems using Koopman-based deep state-space encoders. Through this method, the usual drawback of needing to choose a dictionary of lifting functions a priori is circumvented. The encoder represents the lifting function to the space where the dynamics are linearly propagated using the Koopman operator. An input-affine formulation is considered for the lifted model structure and we address both full and partial state availability. The approach is implemented using the the deepSI toolbox in Python. To lower the computational need of the simulation error-based training, the data is split into subsections where multi-step prediction errors are calculated independently. This formulation allows for efficient batch optimization of the network parameters and, at the same time, excellent long term prediction capabilities of the obtained models. The performance of the approach is illustrated by nonlinear benchmark examples.
C-OPH: Improving the Accuracy of One Permutation Hashing (OPH) with Circulant Permutations
Nov 18, 2021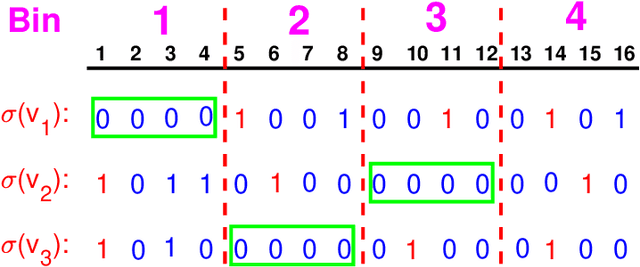
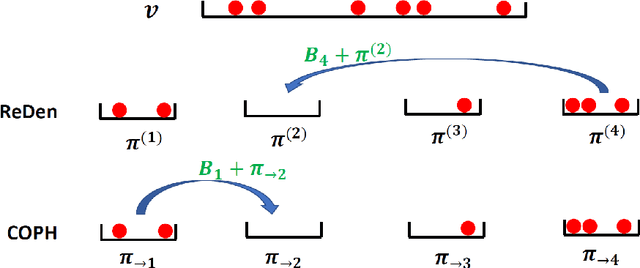
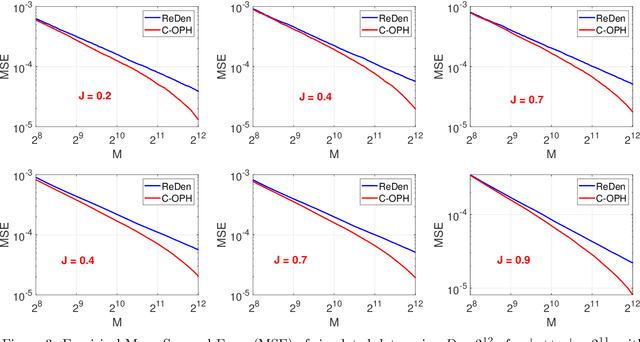
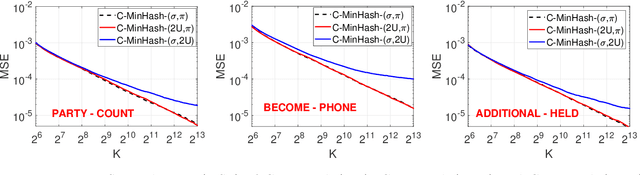
Minwise hashing (MinHash) is a classical method for efficiently estimating the Jaccrad similarity in massive binary (0/1) data. To generate $K$ hash values for each data vector, the standard theory of MinHash requires $K$ independent permutations. Interestingly, the recent work on "circulant MinHash" (C-MinHash) has shown that merely two permutations are needed. The first permutation breaks the structure of the data and the second permutation is re-used $K$ time in a circulant manner. Surprisingly, the estimation accuracy of C-MinHash is proved to be strictly smaller than that of the original MinHash. The more recent work further demonstrates that practically only one permutation is needed. Note that C-MinHash is different from the well-known work on "One Permutation Hashing (OPH)" published in NIPS'12. OPH and its variants using different "densification" schemes are popular alternatives to the standard MinHash. The densification step is necessary in order to deal with empty bins which exist in One Permutation Hashing. In this paper, we propose to incorporate the essential ideas of C-MinHash to improve the accuracy of One Permutation Hashing. Basically, we develop a new densification method for OPH, which achieves the smallest estimation variance compared to all existing densification schemes for OPH. Our proposed method is named C-OPH (Circulant OPH). After the initial permutation (which breaks the existing structure of the data), C-OPH only needs a "shorter" permutation of length $D/K$ (instead of $D$), where $D$ is the original data dimension and $K$ is the total number of bins in OPH. This short permutation is re-used in $K$ bins in a circulant shifting manner. It can be shown that the estimation variance of the Jaccard similarity is strictly smaller than that of the existing (densified) OPH methods.
Structure Information is the Key: Self-Attention RoI Feature Extractor in 3D Object Detection
Nov 01, 2021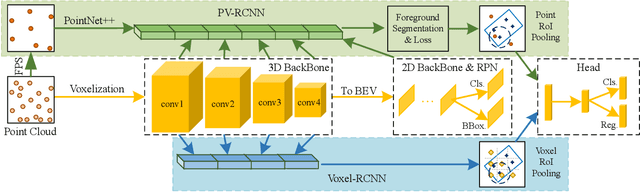
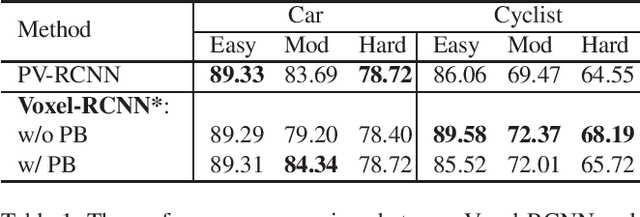

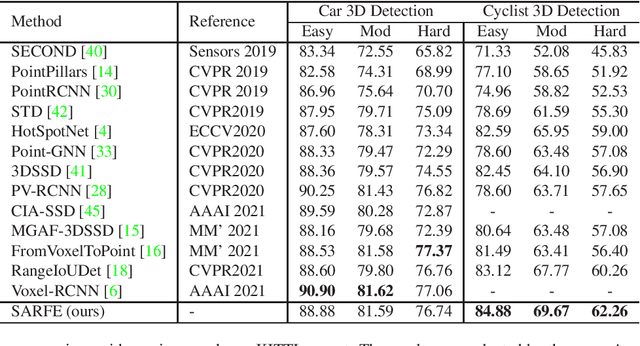
Unlike 2D object detection where all RoI features come from grid pixels, the RoI feature extraction of 3D point cloud object detection is more diverse. In this paper, we first compare and analyze the differences in structure and performance between the two state-of-the-art models PV-RCNN and Voxel-RCNN. Then, we find that the performance gap between the two models does not come from point information, but structural information. The voxel features contain more structural information because they do quantization instead of downsampling to point cloud so that they can contain basically the complete information of the whole point cloud. The stronger structural information in voxel features makes the detector have higher performance in our experiments even if the voxel features don't have accurate location information. Then, we propose that structural information is the key to 3D object detection. Based on the above conclusion, we propose a Self-Attention RoI Feature Extractor (SARFE) to enhance structural information of the feature extracted from 3D proposals. SARFE is a plug-and-play module that can be easily used on existing 3D detectors. Our SARFE is evaluated on both KITTI dataset and Waymo Open dataset. With the newly introduced SARFE, we improve the performance of the state-of-the-art 3D detectors by a large margin in cyclist on KITTI dataset while keeping real-time capability.
A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis
Nov 01, 2021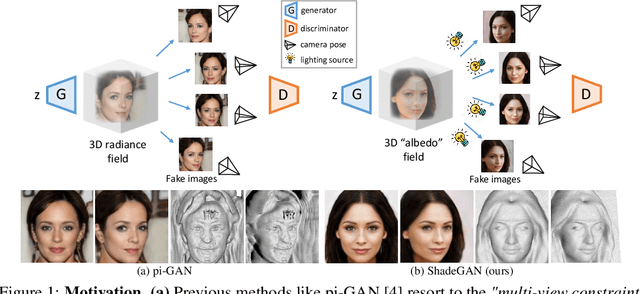
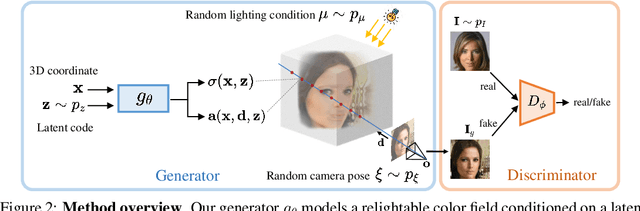
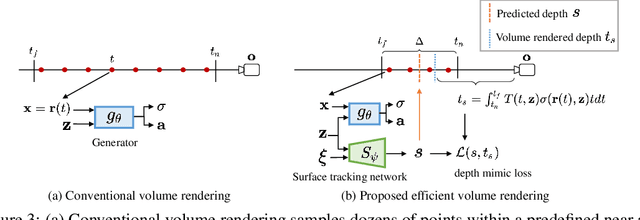

The advancement of generative radiance fields has pushed the boundary of 3D-aware image synthesis. Motivated by the observation that a 3D object should look realistic from multiple viewpoints, these methods introduce a multi-view constraint as regularization to learn valid 3D radiance fields from 2D images. Despite the progress, they often fall short of capturing accurate 3D shapes due to the shape-color ambiguity, limiting their applicability in downstream tasks. In this work, we address this ambiguity by proposing a novel shading-guided generative implicit model that is able to learn a starkly improved shape representation. Our key insight is that an accurate 3D shape should also yield a realistic rendering under different lighting conditions. This multi-lighting constraint is realized by modeling illumination explicitly and performing shading with various lighting conditions. Gradients are derived by feeding the synthesized images to a discriminator. To compensate for the additional computational burden of calculating surface normals, we further devise an efficient volume rendering strategy via surface tracking, reducing the training and inference time by 24% and 48%, respectively. Our experiments on multiple datasets show that the proposed approach achieves photorealistic 3D-aware image synthesis while capturing accurate underlying 3D shapes. We demonstrate improved performance of our approach on 3D shape reconstruction against existing methods, and show its applicability on image relighting. Our code will be released at https://github.com/XingangPan/ShadeGAN.
A Short Study on Compressing Decoder-Based Language Models
Oct 16, 2021
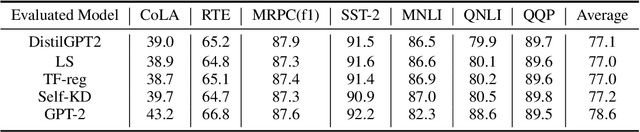

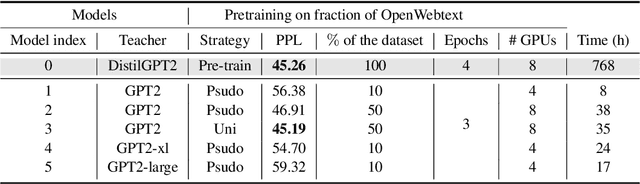
Pre-trained Language Models (PLMs) have been successful for a wide range of natural language processing (NLP) tasks. The state-of-the-art of PLMs, however, are extremely large to be used on edge devices. As a result, the topic of model compression has attracted increasing attention in the NLP community. Most of the existing works focus on compressing encoder-based models (tiny-BERT, distilBERT, distilRoBERTa, etc), however, to the best of our knowledge, the compression of decoder-based models (such as GPT-2) has not been investigated much. Our paper aims to fill this gap. Specifically, we explore two directions: 1) we employ current state-of-the-art knowledge distillation techniques to improve fine-tuning of DistilGPT-2. 2) we pre-train a compressed GPT-2 model using layer truncation and compare it against the distillation-based method (DistilGPT2). The training time of our compressed model is significantly less than DistilGPT-2, but it can achieve better performance when fine-tuned on downstream tasks. We also demonstrate the impact of data cleaning on model performance.
Exploring Non-Autoregressive End-To-End Neural Modeling For English Mispronunciation Detection And Diagnosis
Nov 01, 2021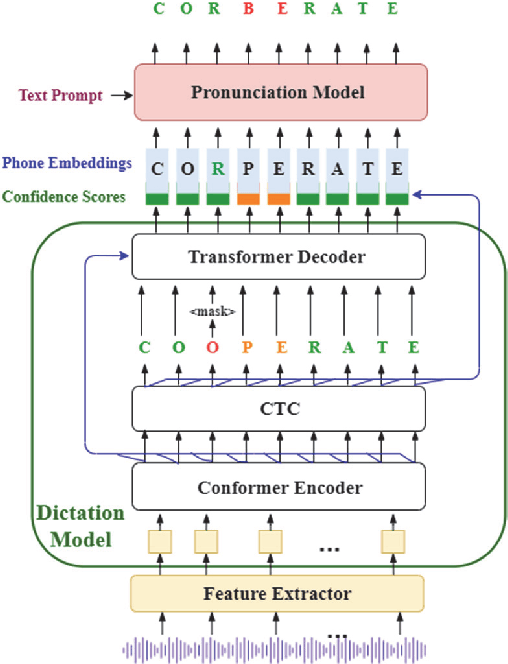
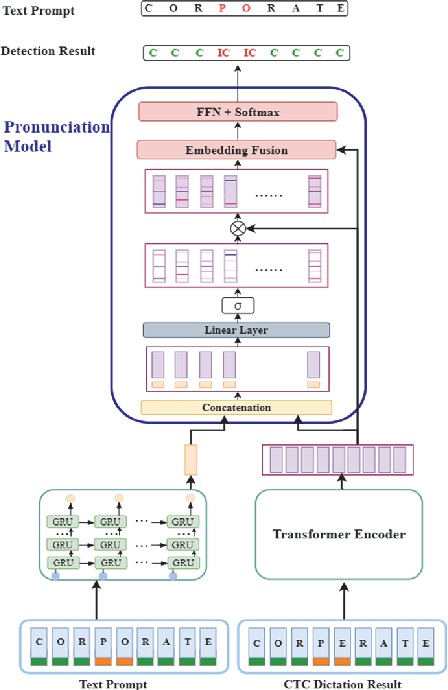
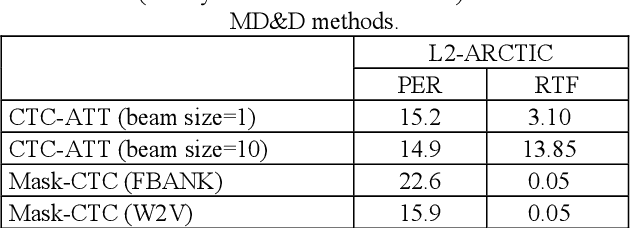
End-to-end (E2E) neural modeling has emerged as one predominant school of thought to develop computer-assisted language training (CAPT) systems, showing competitive performance to conventional pronunciation-scoring based methods. However, current E2E neural methods for CAPT are faced with at least two pivotal challenges. On one hand, most of the E2E methods operate in an autoregressive manner with left-to-right beam search to dictate the pronunciations of an L2 learners. This however leads to very slow inference speed, which inevitably hinders their practical use. On the other hand, E2E neural methods are normally data greedy and meanwhile an insufficient amount of nonnative training data would often reduce their efficacy on mispronunciation detection and diagnosis (MD&D). In response, we put forward a novel MD&D method that leverages non-autoregressive (NAR) E2E neural modeling to dramatically speed up the inference time while maintaining performance in line with the conventional E2E neural methods. In addition, we design and develop a pronunciation modeling network stacked on top of the NAR E2E models of our method to further boost the effectiveness of MD&D. Empirical experiments conducted on the L2-ARCTIC English dataset seems to validate the feasibility of our method, in comparison to some top-of-the-line E2E models and an iconic pronunciation-scoring based method built on a DNN-HMM acoustic model.
A Proximal Algorithm for Sampling from Non-smooth Potentials
Oct 09, 2021
Markov chain Monte Carlo (MCMC) is an effective and dominant method to sample from high-dimensional complex distributions. Yet, most existing MCMC methods are only applicable to settings with smooth potentials (log-densities). In this work, we examine sampling problems with non-smooth potentials. We propose a novel MCMC algorithm for sampling from non-smooth potentials. We provide a non-asymptotical analysis of our algorithm and establish a polynomial-time complexity $\tilde {\cal O}(d\varepsilon^{-1})$ to obtain $\varepsilon$ total variation distance to the target density, better than all existing results under the same assumptions. Our method is based on the proximal bundle method and an alternating sampling framework. This framework requires the so-called restricted Gaussian oracle, which can be viewed as a sampling counterpart of the proximal mapping in convex optimization. One key contribution of this work is a fast algorithm that realizes the restricted Gaussian oracle for any convex non-smooth potential with bounded Lipschitz constant.
Proceedings Third Workshop on Formal Methods for Autonomous Systems
Oct 22, 2021Autonomous systems are highly complex and present unique challenges for the application of formal methods. Autonomous systems act without human intervention, and are often embedded in a robotic system, so that they can interact with the real world. As such, they exhibit the properties of safety-critical, cyber-physical, hybrid, and real-time systems. This EPTCS volume contains the proceedings for the third workshop on Formal Methods for Autonomous Systems (FMAS 2021), which was held virtually on the 21st and 22nd of October 2021. Like the previous workshop, FMAS 2021 was an online, stand-alone event, as an adaptation to the ongoing COVID-19 restrictions. Despite the challenges this brought, we were determined to build on the success of the previous two FMAS workshops. The goal of FMAS is to bring together leading researchers who are tackling the unique challenges of autonomous systems using formal methods, to present recent and ongoing work. We are interested in the use of formal methods to specify, model, or verify autonomous and/or robotic systems; in whole or in part. We are also interested in successful industrial applications and potential future directions for this emerging application of formal methods.
Sequential Decision-Making for Active Object Detection from Hand
Oct 21, 2021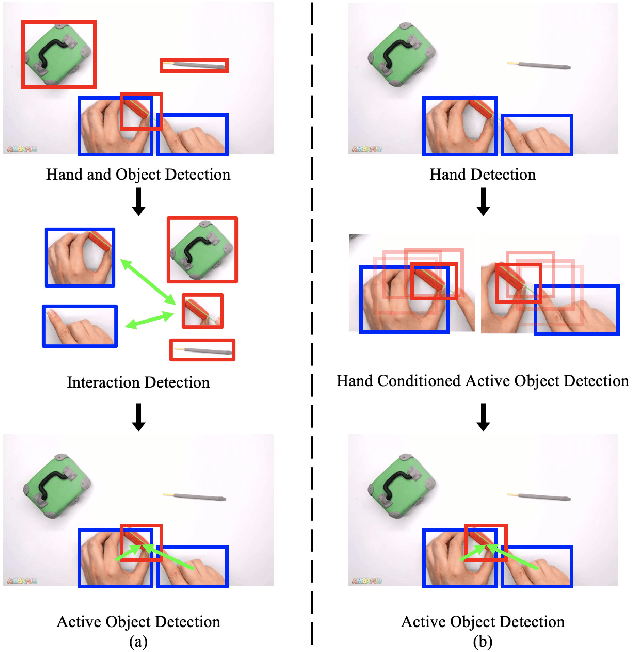

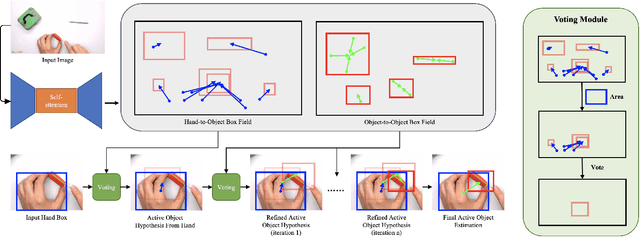

A key component of understanding hand-object interactions is the ability to identify the active object -- the object that is being manipulated by the human hand -- despite the occlusion induced by hand-object interactions. Based on the observation that hand appearance is a strong indicator of the location and size of the active object, we set up our active object detection method as a sequential decision-making process that is conditioned on the location and appearance of the hands. The key innovation of our approach is the design of the active object detection policy that uses an internal representation called the Relational Box Field, which allows for every pixel to regress an improved location of an active object bounding box, essentially giving every pixel the ability to vote for a better bounding box location. The policy is trained using a hybrid imitation learning and reinforcement learning approach, and at test time, the policy is used repeatedly to refine the bounding box location of the active object. We perform experiments on two large-scale datasets: 100DOH and MECCANO, improving AP50 performance by 8% and 30%, respectively, over the state of the art.