 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
T$^{\star}$-Lite: A Fast Time-Risk Optimal Motion Planning Algorithm for Multi-Speed Autonomous Vehicles
Aug 29, 2020
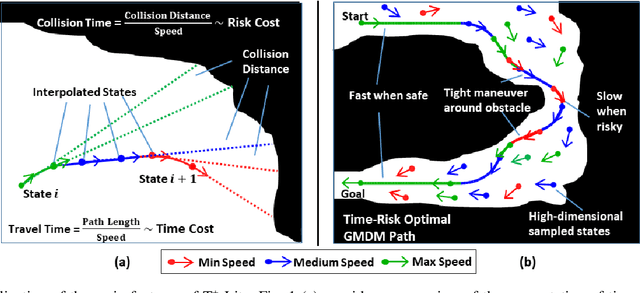
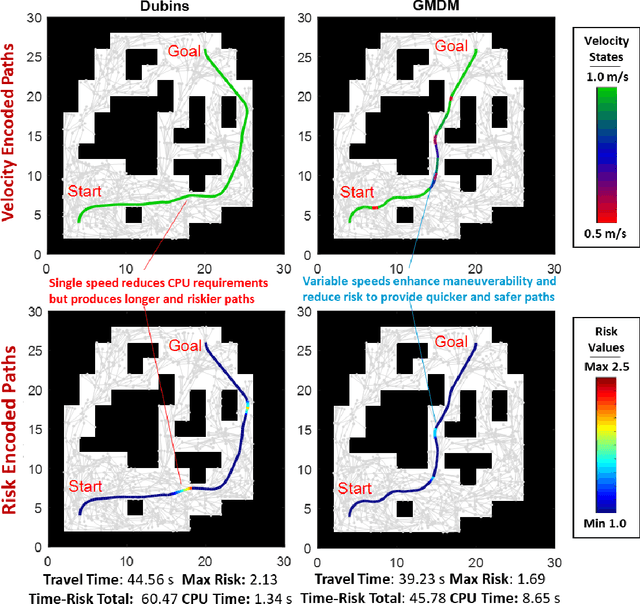
In this paper, we develop a new algorithm, called T$^{\star}$-Lite, that enables fast time-risk optimal motion planning for variable-speed autonomous vehicles. The T$^{\star}$-Lite algorithm is a significantly faster version of the previously developed T$^{\star}$ algorithm. T$^{\star}$-Lite uses the novel time-risk cost function of T$^{\star}$; however, instead of a grid-based approach, it uses an asymptotically optimal sampling-based motion planner. Furthermore, it utilizes the recently developed Generalized Multi-speed Dubins Motion-model (GMDM) for sample-to-sample kinodynamic motion planning. The sample-based approach and GMDM significantly reduce the computational burden of T$^{\star}$ while providing reasonable solution quality. The sample points are drawn from a four-dimensional configuration space consisting of two position coordinates plus vehicle heading and speed. Specifically, T$^{\star}$-Lite enables the motion planner to select the vehicle speed and direction based on its proximity to the obstacle to generate faster and safer paths. In this paper, T$^{\star}$-Lite is developed using the RRT$^{\star}$ motion planner, but adaptation to other motion planners is straightforward and depends on the needs of the planner
Multi-Task Meta-Learning Modification with Stochastic Approximation
Oct 25, 2021



Meta-learning methods aim to build learning algorithms capable of quickly adapting to new tasks in low-data regime. One of the main benchmarks of such an algorithms is a few-shot learning problem. In this paper we investigate the modification of standard meta-learning pipeline that takes a multi-task approach during training. The proposed method simultaneously utilizes information from several meta-training tasks in a common loss function. The impact of each of these tasks in the loss function is controlled by the corresponding weight. Proper optimization of these weights can have a big influence on training of the entire model and might improve the quality on test time tasks. In this work we propose and investigate the use of methods from the family of simultaneous perturbation stochastic approximation (SPSA) approaches for meta-train tasks weights optimization. We have also compared the proposed algorithms with gradient-based methods and found that stochastic approximation demonstrates the largest quality boost in test time. Proposed multi-task modification can be applied to almost all methods that use meta-learning pipeline. In this paper we study applications of this modification on Prototypical Networks and Model-Agnostic Meta-Learning algorithms on CIFAR-FS, FC100, tieredImageNet and miniImageNet few-shot learning benchmarks. During these experiments, multi-task modification has demonstrated improvement over original methods. The proposed SPSA-Tracking algorithm shows the largest accuracy boost. Our code is available online.
CertainNet: Sampling-free Uncertainty Estimation for Object Detection
Oct 04, 2021
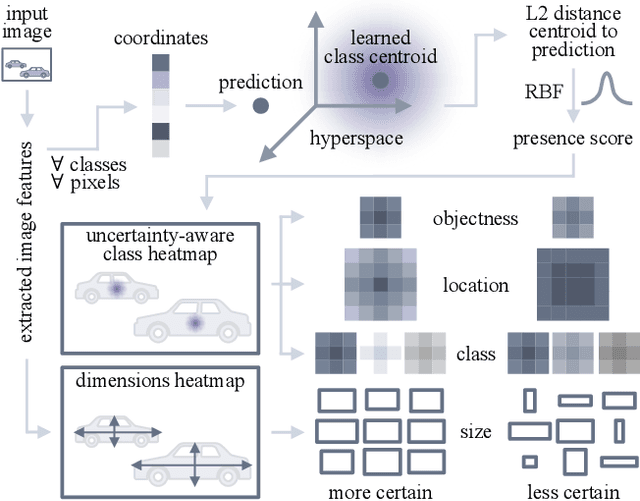
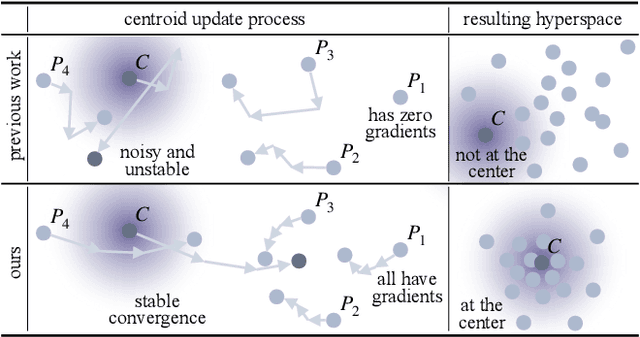
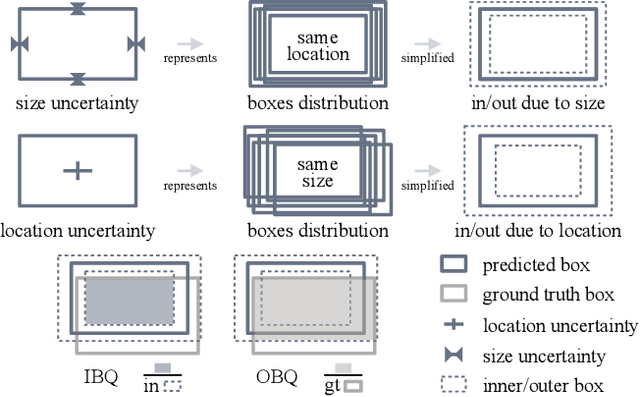
Estimating the uncertainty of a neural network plays a fundamental role in safety-critical settings. In perception for autonomous driving, measuring the uncertainty means providing additional calibrated information to downstream tasks, such as path planning, that can use it towards safe navigation. In this work, we propose a novel sampling-free uncertainty estimation method for object detection. We call it CertainNet, and it is the first to provide separate uncertainties for each output signal: objectness, class, location and size. To achieve this, we propose an uncertainty-aware heatmap, and exploit the neighboring bounding boxes provided by the detector at inference time. We evaluate the detection performance and the quality of the different uncertainty estimates separately, also with challenging out-of-domain samples: BDD100K and nuImages with models trained on KITTI. Additionally, we propose a new metric to evaluate location and size uncertainties. When transferring to unseen datasets, CertainNet generalizes substantially better than previous methods and an ensemble, while being real-time and providing high quality and comprehensive uncertainty estimates.
Improved Topic modeling in Twitter through Community Pooling
Dec 20, 2021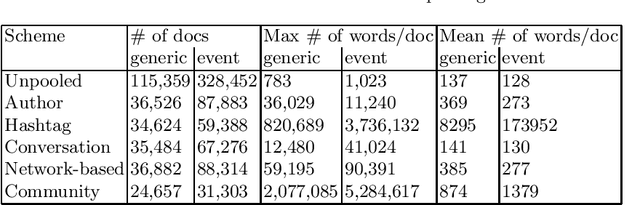
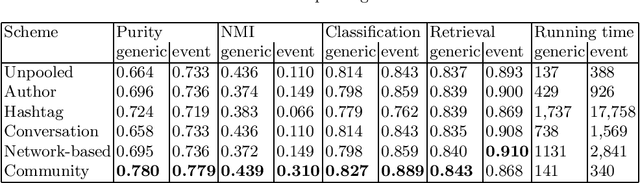
Social networks play a fundamental role in propagation of information and news. Characterizing the content of the messages becomes vital for different tasks, like breaking news detection, personalized message recommendation, fake users detection, information flow characterization and others. However, Twitter posts are short and often less coherent than other text documents, which makes it challenging to apply text mining algorithms to these datasets efficiently. Tweet-pooling (aggregating tweets into longer documents) has been shown to improve automatic topic decomposition, but the performance achieved in this task varies depending on the pooling method. In this paper, we propose a new pooling scheme for topic modeling in Twitter, which groups tweets whose authors belong to the same community (group of users who mainly interact with each other but not with other groups) on a user interaction graph. We present a complete evaluation of this methodology, state of the art schemes and previous pooling models in terms of the cluster quality, document retrieval tasks performance and supervised machine learning classification score. Results show that our Community polling method outperformed other methods on the majority of metrics in two heterogeneous datasets, while also reducing the running time. This is useful when dealing with big amounts of noisy and short user-generated social media texts. Overall, our findings contribute to an improved methodology for identifying the latent topics in a Twitter dataset, without the need of modifying the basic machinery of a topic decomposition model.
Deep Measurement Updates for Bayes Filters
Dec 01, 2021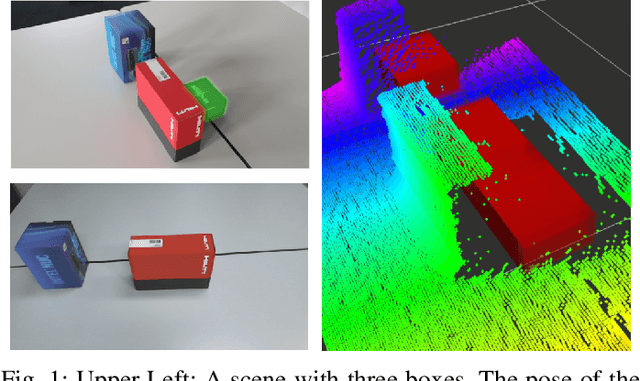
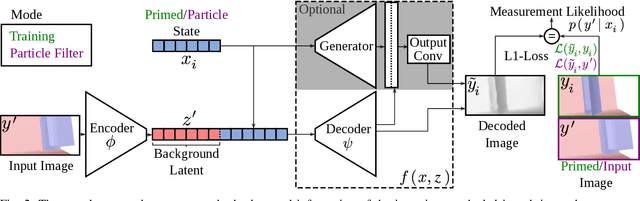
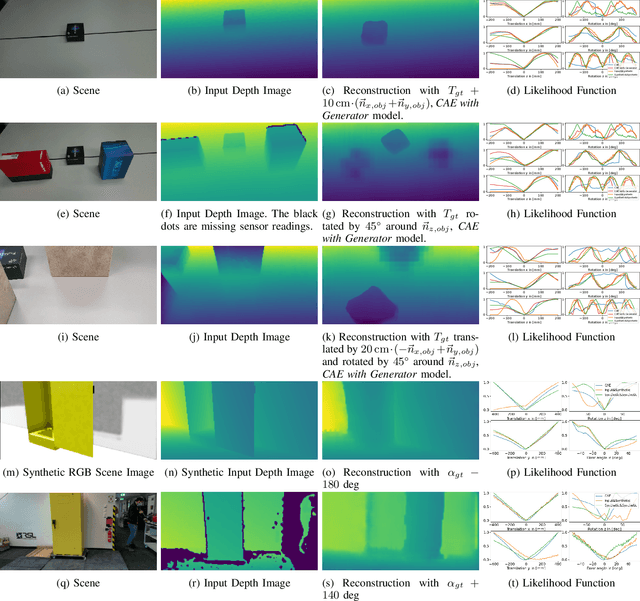

Measurement update rules for Bayes filters often contain hand-crafted heuristics to compute observation probabilities for high-dimensional sensor data, like images. In this work, we propose the novel approach Deep Measurement Update (DMU) as a general update rule for a wide range of systems. DMU has a conditional encoder-decoder neural network structure to process depth images as raw inputs. Even though the network is trained only on synthetic data, the model shows good performance at evaluation time on real-world data. With our proposed training scheme primed data training , we demonstrate how the DMU models can be trained efficiently to be sensitive to condition variables without having to rely on a stochastic information bottleneck. We validate the proposed methods in multiple scenarios of increasing complexity, beginning with the pose estimation of a single object to the joint estimation of the pose and the internal state of an articulated system. Moreover, we provide a benchmark against Articulated Signed Distance Functions(A-SDF) on the RBO dataset as a baseline comparison for articulation state estimation.
Fast and deep neuromorphic learning with time-to-first-spike coding
Dec 24, 2019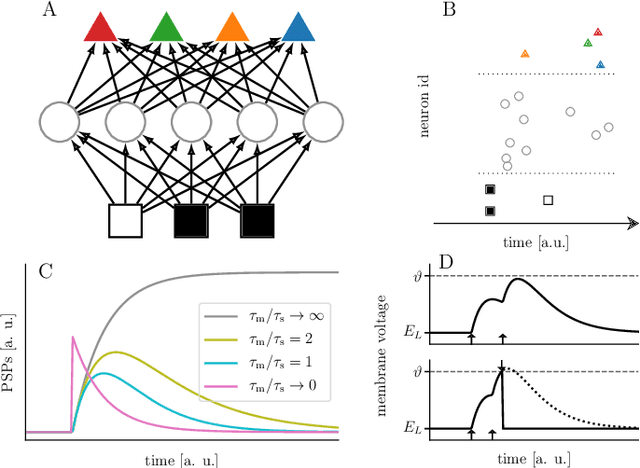
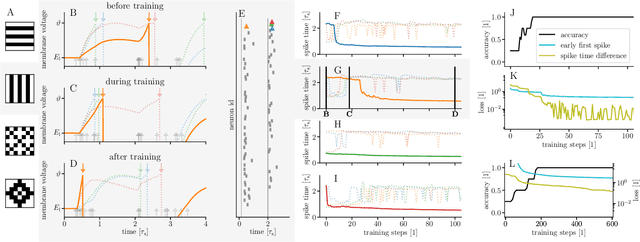
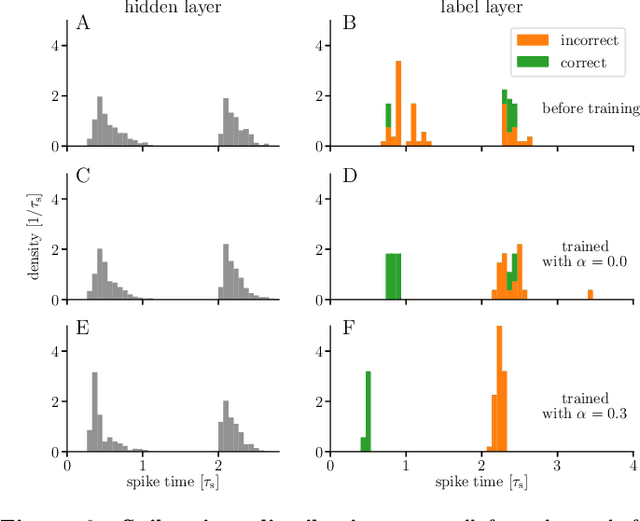
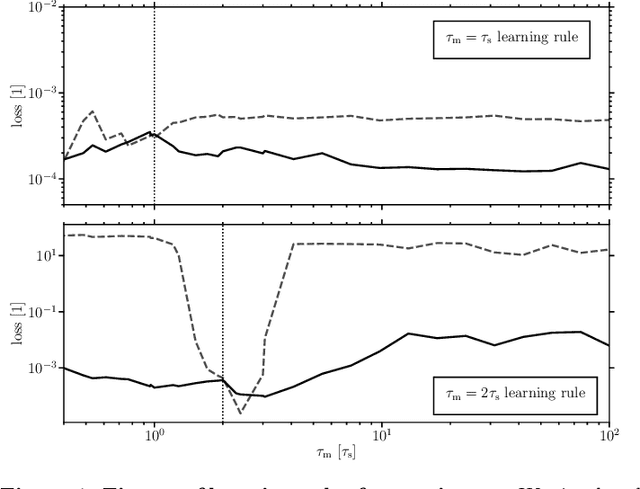
For a biological agent operating under environmental pressure, energy consumption and reaction times are of critical importance. Similarly, engineered systems also strive for short time-to-solution and low energy-to-solution characteristics. At the level of neuronal implementation, this implies achieving the desired results with as few and as early spikes as possible. In the time-to-first-spike coding framework, both of these goals are inherently emerging features of learning. Here, we describe a rigorous derivation of error-backpropagation-based learning for hierarchical networks of leaky integrate-and-fire neurons. We explicitly address two issues that are relevant for both biological plausibility and applicability to neuromorphic substrates by incorporating dynamics with finite time constants and by optimizing the backward pass with respect to substrate variability. This narrows the gap between previous models of first-spike-time learning and biological neuronal dynamics, thereby also enabling fast and energy-efficient inference on analog neuromorphic devices that inherit these dynamics from their biological archetypes, which we demonstrate on two generations of the BrainScaleS analog neuromorphic architecture.
Unsupervised Domain Adaptation for Semantic Image Segmentation: a Comprehensive Survey
Dec 06, 2021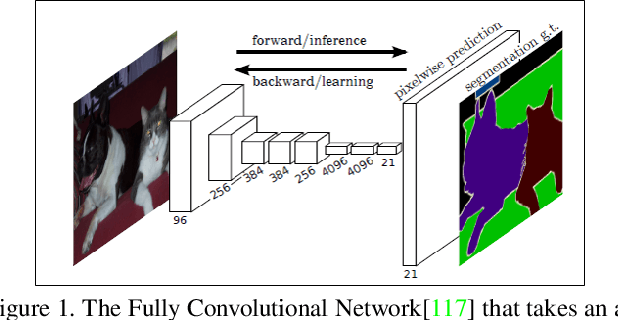
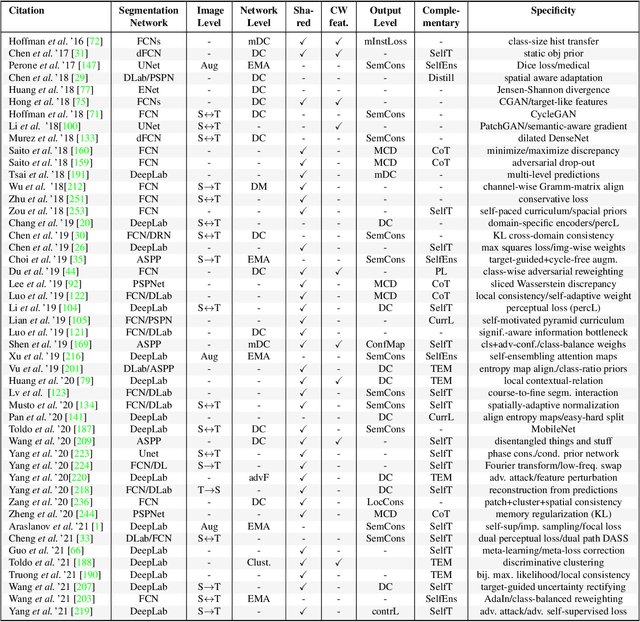
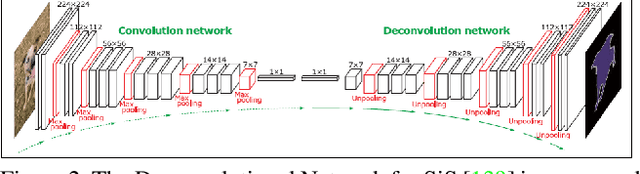
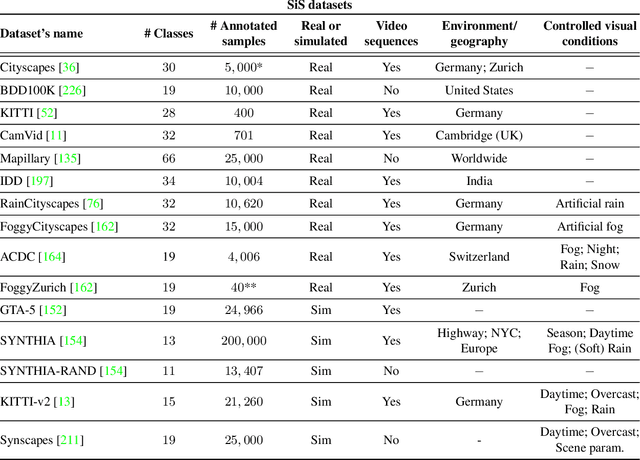
Semantic segmentation plays a fundamental role in a broad variety of computer vision applications, providing key information for the global understanding of an image. Yet, the state-of-the-art models rely on large amount of annotated samples, which are more expensive to obtain than in tasks such as image classification. Since unlabelled data is instead significantly cheaper to obtain, it is not surprising that Unsupervised Domain Adaptation reached a broad success within the semantic segmentation community. This survey is an effort to summarize five years of this incredibly rapidly growing field, which embraces the importance of semantic segmentation itself and a critical need of adapting segmentation models to new environments. We present the most important semantic segmentation methods; we provide a comprehensive survey on domain adaptation techniques for semantic segmentation; we unveil newer trends such as multi-domain learning, domain generalization, test-time adaptation or source-free domain adaptation; we conclude this survey by describing datasets and benchmarks most widely used in semantic segmentation research. We hope that this survey will provide researchers across academia and industry with a comprehensive reference guide and will help them in fostering new research directions in the field.
Multi-Modal Model Predictive Control through Batch Non-Holonomic Trajectory Optimization: Application to Highway Driving
Sep 21, 2021
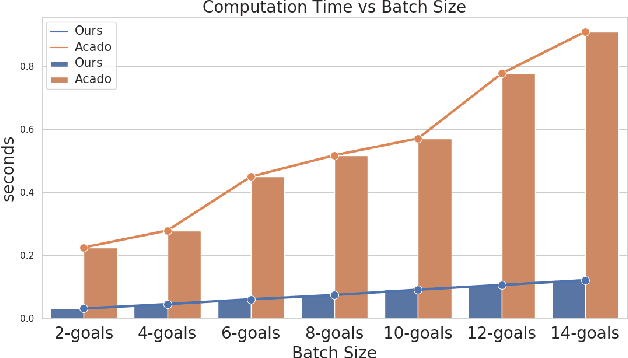
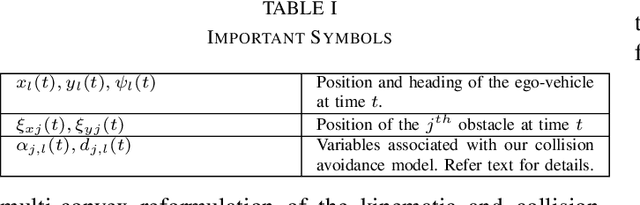

Standard Model Predictive Control (MPC) or trajectory optimization approaches perform only a local search to solve a complex non-convex optimization problem. As a result, they cannot capture the multi-modal characteristic of human driving. A global optimizer can be a potential solution but is computationally intractable in a real-time setting. In this paper, we present a real-time MPC capable of searching over different driving modalities. Our basic idea is simple: we run several goal-directed parallel trajectory optimizations and score the resulting trajectories based on user-defined meta cost functions. This allows us to perform a global search over several locally optimal motion plans. Although conceptually straightforward, realizing this idea in real-time with existing optimizers is highly challenging from technical and computational standpoints. With this motivation, we present a novel batch non-holonomic trajectory optimization whose underlying matrix algebra is easily parallelizable across problem instances and reduces to computing large batch matrix-vector products. This structure, in turn, is achieved by deriving a linearization-free multi-convex reformulation of the non-holonomic kinematics and collision avoidance constraints. We extensively validate our approach using both synthetic and real data sets (NGSIM) of traffic scenarios. We highlight how our algorithm automatically takes lane-change and overtaking decisions based on the defined meta cost function. Our batch optimizer achieves trajectories with lower meta cost, up to 6x faster than competing baselines.
Monaural source separation: From anechoic to reverberant environments
Nov 15, 2021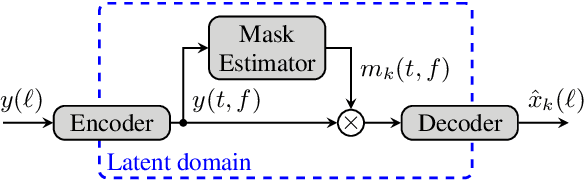
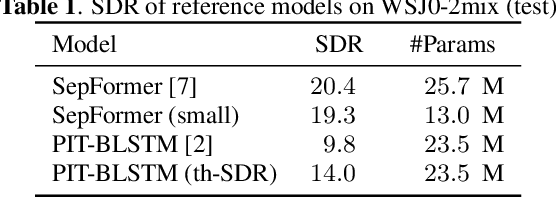
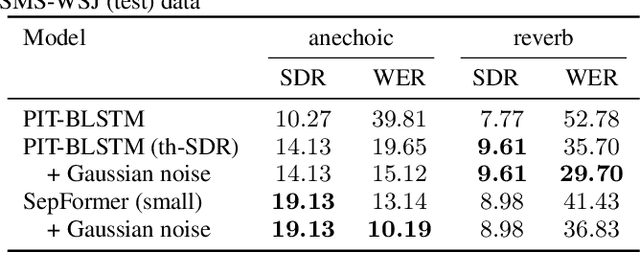
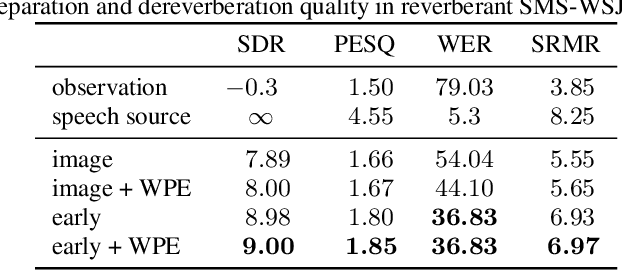
Impressive progress in neural network-based single-channel speech source separation has been made in recent years. But those improvements have been mostly reported on anechoic data, a situation that is hardly met in practice. Taking the SepFormer as a starting point, which achieves state-of-the-art performance on anechoic mixtures, we gradually modify it to optimize its performance on reverberant mixtures. Although this leads to a word error rate improvement by 8 percentage points compared to the standard SepFormer implementation, the system ends up with only marginally better performance than our improved PIT-BLSTM separation system, that is optimized with rather straightforward means. This is surprising and at the same time sobering, challenging the practical usefulness of many improvements reported in recent years for monaural source separation on nonreverberant data.
Curvature-guided dynamic scale networks for Multi-view Stereo
Dec 11, 2021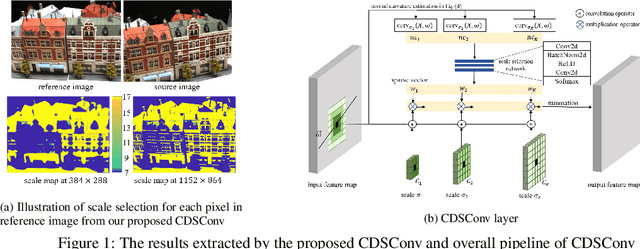
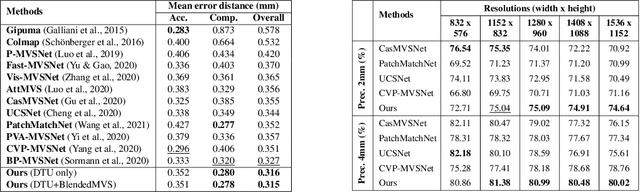
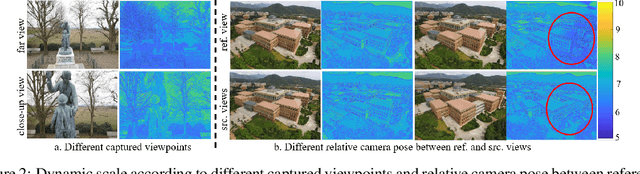
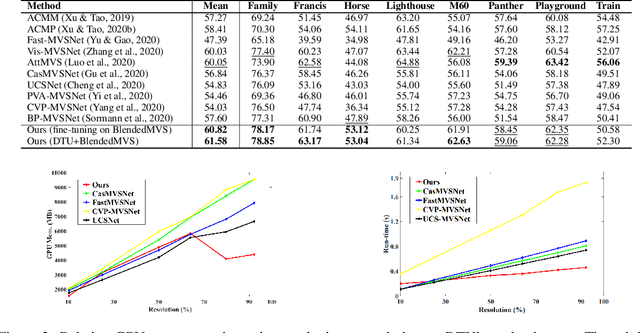
Multi-view stereo (MVS) is a crucial task for precise 3D reconstruction. Most recent studies tried to improve the performance of matching cost volume in MVS by designing aggregated 3D cost volumes and their regularization. This paper focuses on learning a robust feature extraction network to enhance the performance of matching costs without heavy computation in the other steps. In particular, we present a dynamic scale feature extraction network, namely, CDSFNet. It is composed of multiple novel convolution layers, each of which can select a proper patch scale for each pixel guided by the normal curvature of the image surface. As a result, CDFSNet can estimate the optimal patch scales to learn discriminative features for accurate matching computation between reference and source images. By combining the robust extracted features with an appropriate cost formulation strategy, our resulting MVS architecture can estimate depth maps more precisely. Extensive experiments showed that the proposed method outperforms other state-of-the-art methods on complex outdoor scenes. It significantly improves the completeness of reconstructed models. As a result, the method can process higher resolution inputs within faster run-time and lower memory than other MVS methods. Our source code is available at url{https://github.com/TruongKhang/cds-mvsnet}.