 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonaural source separation: From anechoic to reverberant environments
Paper and Code
Nov 15, 2021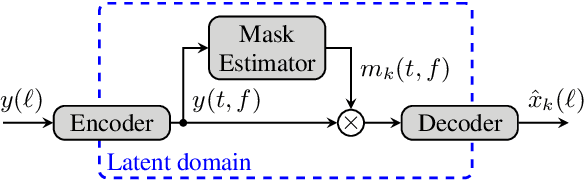
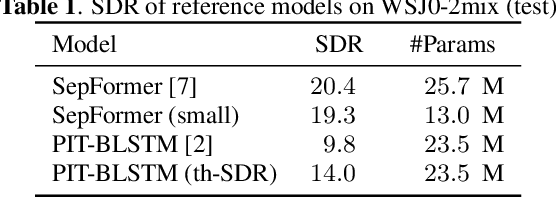
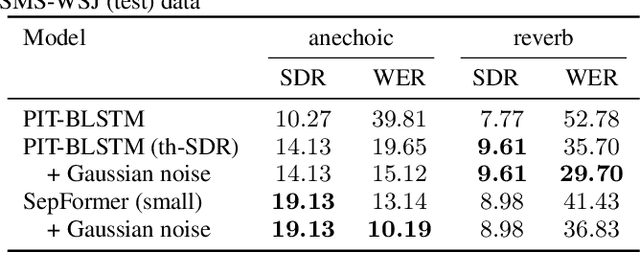
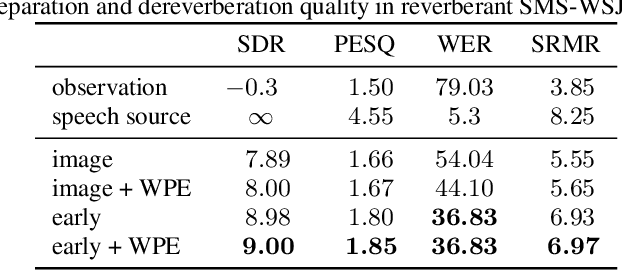
Impressive progress in neural network-based single-channel speech source separation has been made in recent years. But those improvements have been mostly reported on anechoic data, a situation that is hardly met in practice. Taking the SepFormer as a starting point, which achieves state-of-the-art performance on anechoic mixtures, we gradually modify it to optimize its performance on reverberant mixtures. Although this leads to a word error rate improvement by 8 percentage points compared to the standard SepFormer implementation, the system ends up with only marginally better performance than our improved PIT-BLSTM separation system, that is optimized with rather straightforward means. This is surprising and at the same time sobering, challenging the practical usefulness of many improvements reported in recent years for monaural source separation on nonreverberant data.