 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prompt-Based Multi-Modal Image Segmentation
Dec 18, 2021
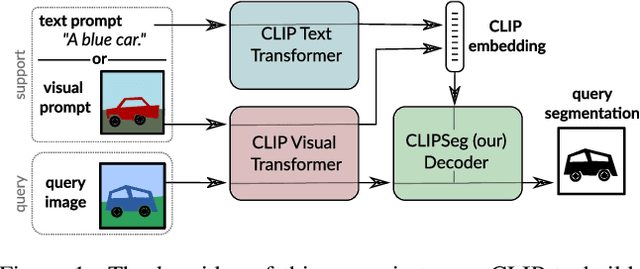

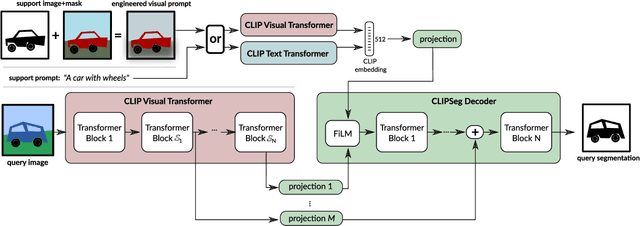

Image segmentation is usually addressed by training a model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system that can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text or an image. This approach enables us to create a unified model (trained once) for three common segmentation tasks, which come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation. We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense prediction. After training on an extended version of the PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on an additional image expressing the query. Different variants of the latter image-based prompts are analyzed in detail. This novel hybrid input allows for dynamic adaptation not only to the three segmentation tasks mentioned above, but to any binary segmentation task where a text or image query can be formulated. Finally, we find our system to adapt well to generalized queries involving affordances or properties. Source code: https://eckerlab.org/code/clipseg
DIRECT: A Differential Dynamic Programming Based Framework for Trajectory Generation
Sep 10, 2021
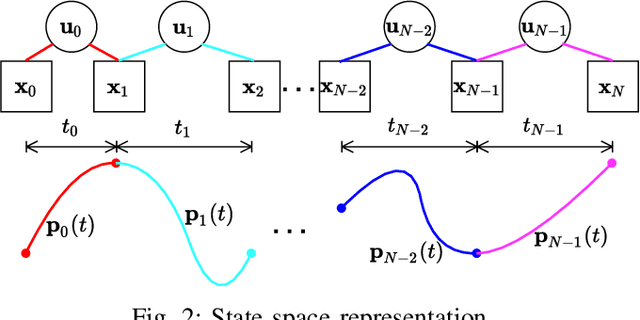
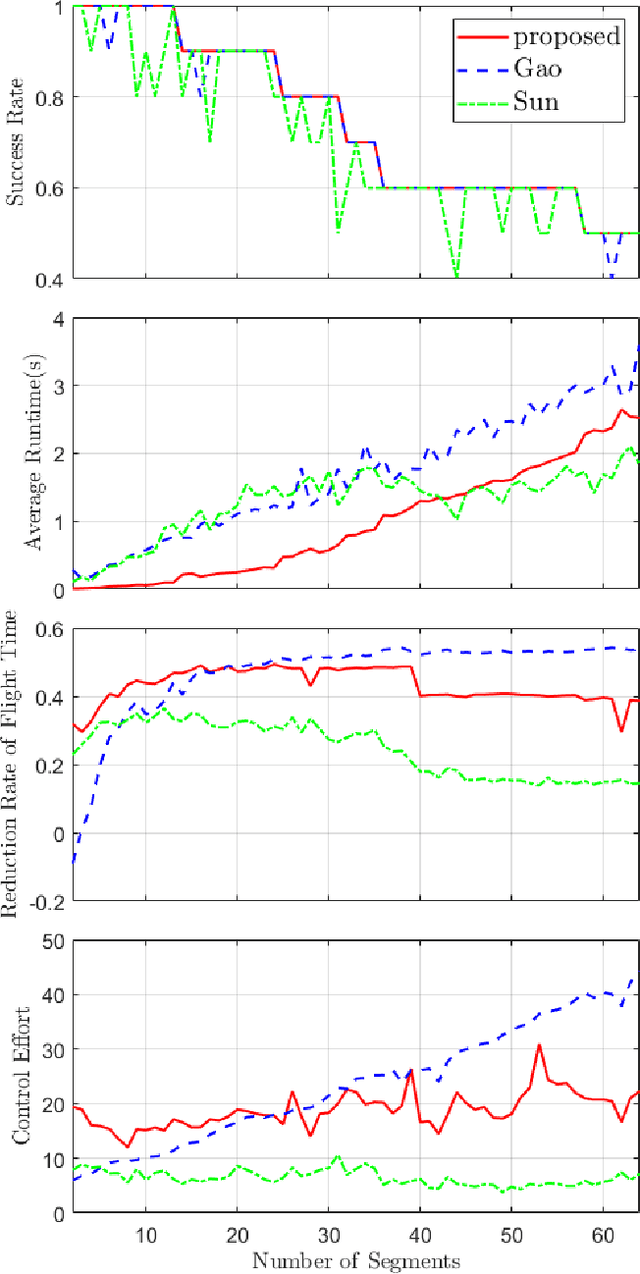
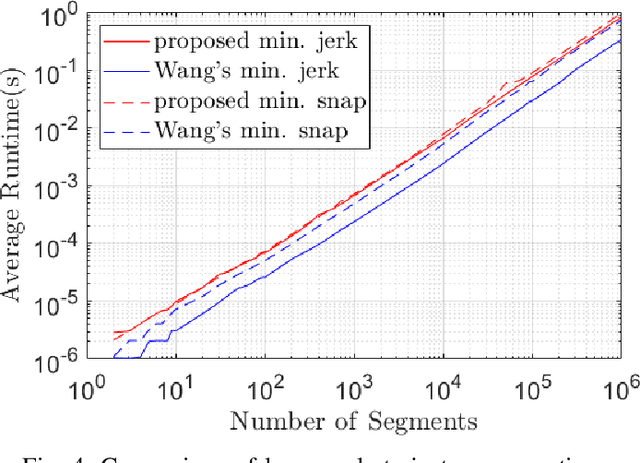
This paper introduces a differential dynamic programming (DDP) based framework for polynomial trajectory generation for differentially flat systems. In particular, instead of using a linear equation with increasing size to represent multiple polynomial segments as in literature, we take a new perspective from state-space representation such that the linear equation reduces to a finite horizon control system with a fixed state dimension and the required continuity conditions for consecutive polynomials are automatically satisfied. Consequently, the constrained trajectory generation problem (both with and without time optimization) can be converted to a discrete-time finite-horizon optimal control problem with inequality constraints, which can be approached by a recently developed interior-point DDP (IPDDP) algorithm. Furthermore, for unconstrained trajectory generation with preallocated time, we show that this problem is indeed a linear-quadratic tracking (LQT) problem (DDP algorithm with exact one iteration). All these algorithms enjoy linear complexity with respect to the number of segments. Both numerical comparisons with state-of-the-art methods and physical experiments are presented to verify and validate the effectiveness of our theoretical findings. The implementation code will be open-sourced,
An Autonomous Self-Incremental Learning Approach for Detection of Cyber Attacks on Unmanned Aerial Vehicles (UAVs)
Dec 18, 2021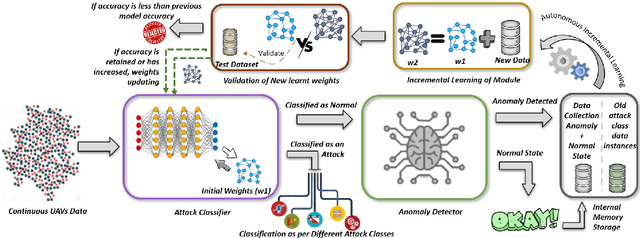
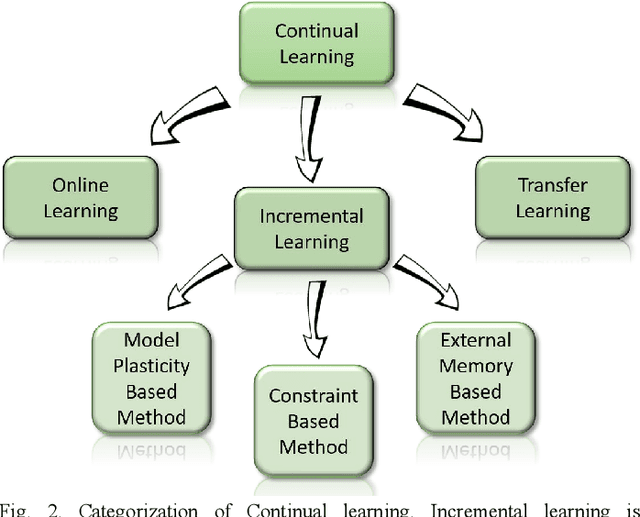
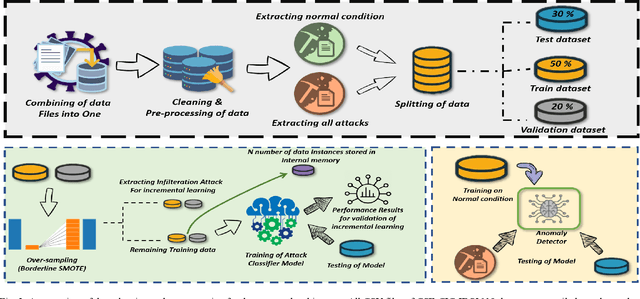
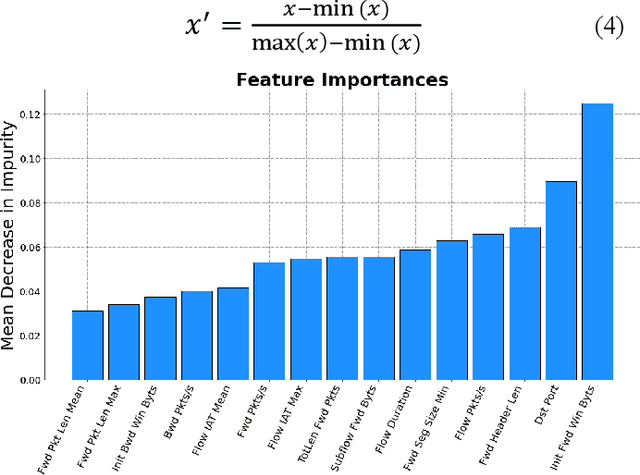
As the technological advancement and capabilities of automated systems have increased drastically, the usage of unmanned aerial vehicles for performing human-dependent tasks without human indulgence has also spiked. Since unmanned aerial vehicles are heavily dependent on Information and Communication Technology, they are highly prone to cyber-attacks. With time more advanced and new attacks are being developed and employed. However, the current Intrusion detection system lacks detection and classification of new and unknown attacks. Therefore, for having an autonomous and reliable operation of unmanned aerial vehicles, more robust and automated cyber detection and protection schemes are needed. To address this, we have proposed an autonomous self-incremental learning architecture, capable of detecting known and unknown cyber-attacks on its own without any human interference. In our approach, we have combined signature-based detection along with anomaly detection in such a way that the signature-based detector autonomously updates its attack classes with the help of an anomaly detector. To achieve this, we have implemented an incremental learning approach, updating our model to incorporate new classes without forgetting the old ones. To validate the applicability and effectiveness of our proposed architecture, we have implemented it in a trial scenario and then compared it with the traditional offline learning approach. Moreover, our anomaly-based detector has achieved a 100% detection rate for attacks.
Co-training Transformer with Videos and Images Improves Action Recognition
Dec 14, 2021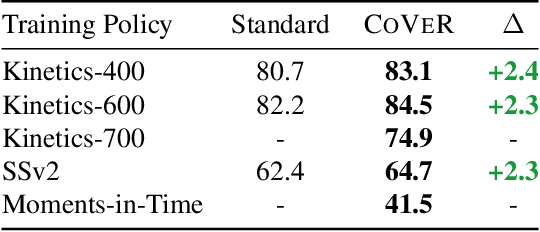
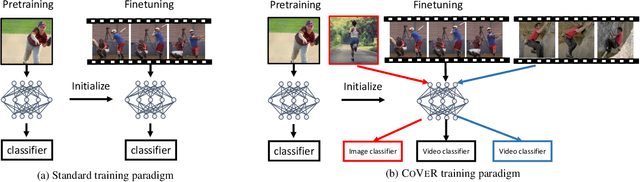

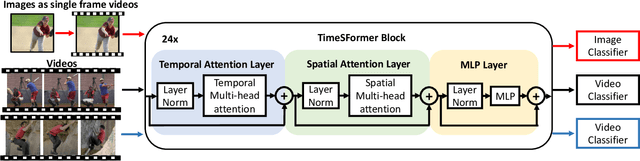
In learning action recognition, models are typically pre-trained on object recognition with images, such as ImageNet, and later fine-tuned on target action recognition with videos. This approach has achieved good empirical performance especially with recent transformer-based video architectures. While recently many works aim to design more advanced transformer architectures for action recognition, less effort has been made on how to train video transformers. In this work, we explore several training paradigms and present two findings. First, video transformers benefit from joint training on diverse video datasets and label spaces (e.g., Kinetics is appearance-focused while SomethingSomething is motion-focused). Second, by further co-training with images (as single-frame videos), the video transformers learn even better video representations. We term this approach as Co-training Videos and Images for Action Recognition (CoVeR). In particular, when pretrained on ImageNet-21K based on the TimeSFormer architecture, CoVeR improves Kinetics-400 Top-1 Accuracy by 2.4%, Kinetics-600 by 2.3%, and SomethingSomething-v2 by 2.3%. When pretrained on larger-scale image datasets following previous state-of-the-art, CoVeR achieves best results on Kinetics-400 (87.2%), Kinetics-600 (87.9%), Kinetics-700 (79.8%), SomethingSomething-v2 (70.9%), and Moments-in-Time (46.1%), with a simple spatio-temporal video transformer.
Constant Time Graph Neural Networks
Jan 23, 2019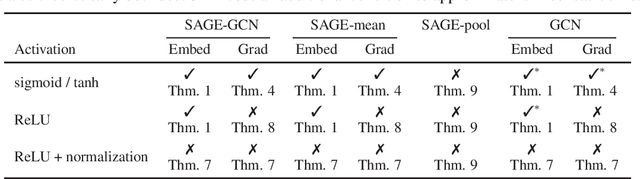
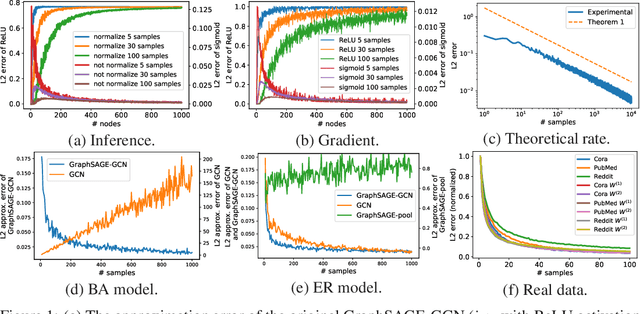
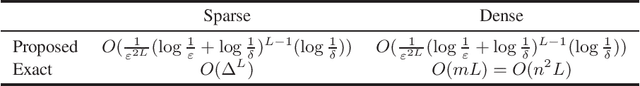
Recent advancements in graph neural networks (GNN) have led to state-of-the-art performance in various applications including chemo-informatics, question answering systems, and recommendation systems, to name a few. However, making these methods scalable to huge graphs such as web-mining remains a challenge. In particular, the existing methods for accelerating GNN are either not theoretically guaranteed in terms of approximation error or require at least linear time computation cost. In this paper, we propose a constant time approximation algorithm for the inference and training of GNN that theoretically guarantees arbitrary precision with arbitrary probability. The key advantage of the proposed algorithm is that the complexity is completely independent of the number of nodes, edges, and neighbors of the input. To the best of our knowledge, this is the first constant time approximation algorithm for GNN with theoretical guarantee. Through experiments using synthetic and real-world datasets, we evaluate our proposed approximation algorithm and show that the algorithm can successfully approximate GNN in constant time.
Which images to label for few-shot medical landmark detection?
Dec 09, 2021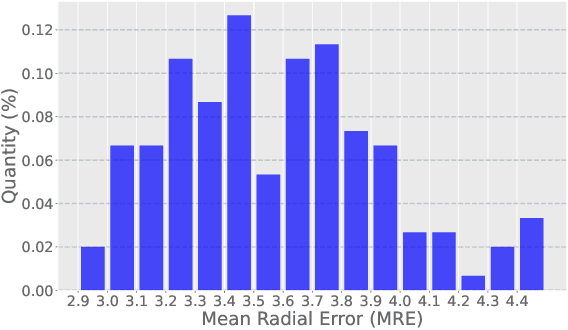

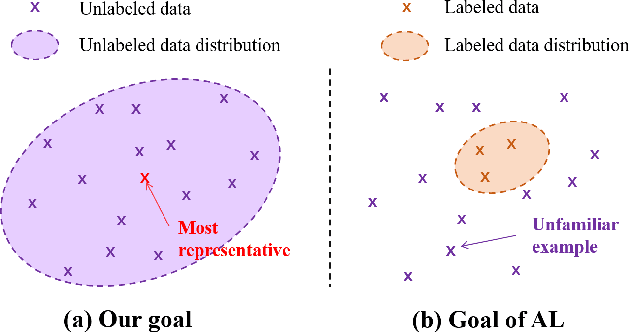
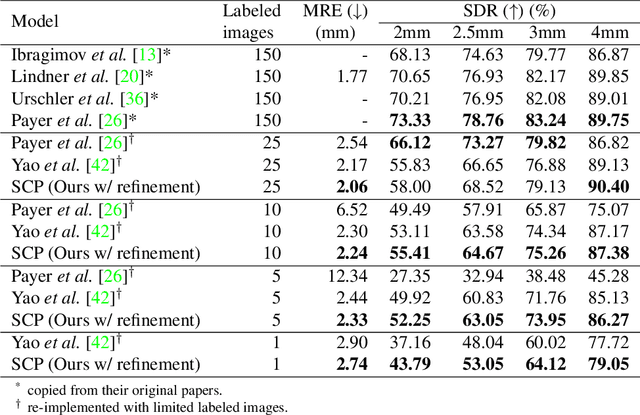
The success of deep learning methods relies on the availability of well-labeled large-scale datasets. However, for medical images, annotating such abundant training data often requires experienced radiologists and consumes their limited time. Few-shot learning is developed to alleviate this burden, which achieves competitive performances with only several labeled data. However, a crucial yet previously overlooked problem in few-shot learning is about the selection of template images for annotation before learning, which affects the final performance. We herein propose a novel Sample Choosing Policy (SCP) to select "the most worthy" images for annotation, in the context of few-shot medical landmark detection. SCP consists of three parts: 1) Self-supervised training for building a pre-trained deep model to extract features from radiological images, 2) Key Point Proposal for localizing informative patches, and 3) Representative Score Estimation for searching the most representative samples or templates. The advantage of SCP is demonstrated by various experiments on three widely-used public datasets. For one-shot medical landmark detection, its use reduces the mean radial errors on Cephalometric and HandXray datasets by 14.2% (from 3.595mm to 3.083mm) and 35.5% (4.114mm to 2.653mm), respectively.
Online Adaptation of Neural Network Models by Modified Extended Kalman Filter for Customizable and Transferable Driving Behavior Prediction
Dec 09, 2021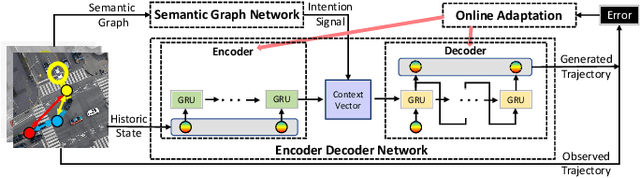
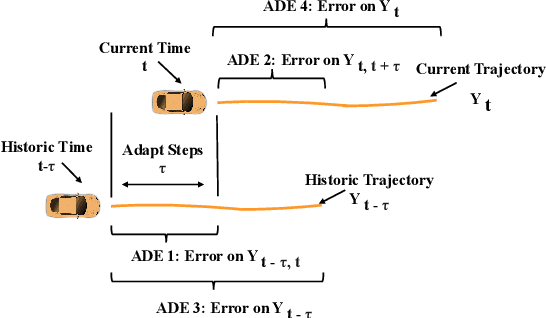
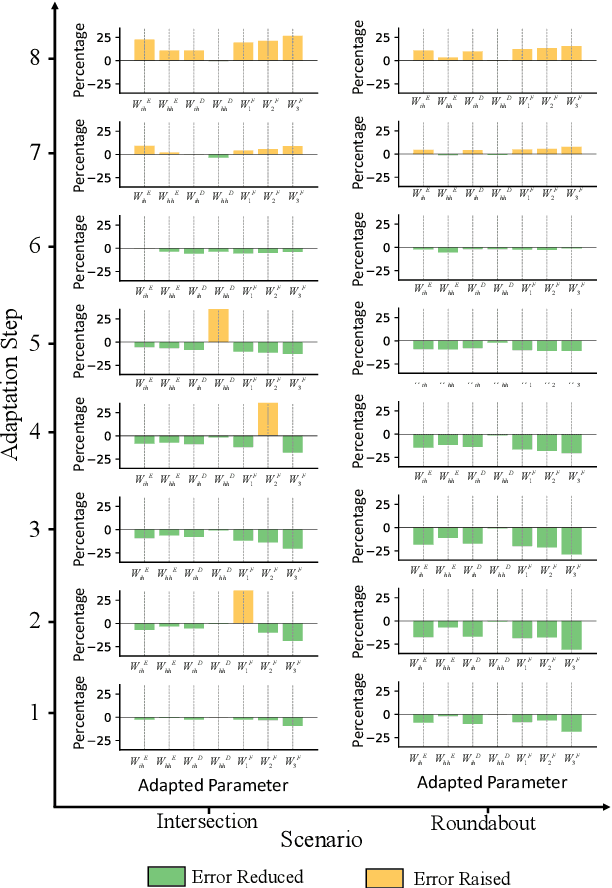
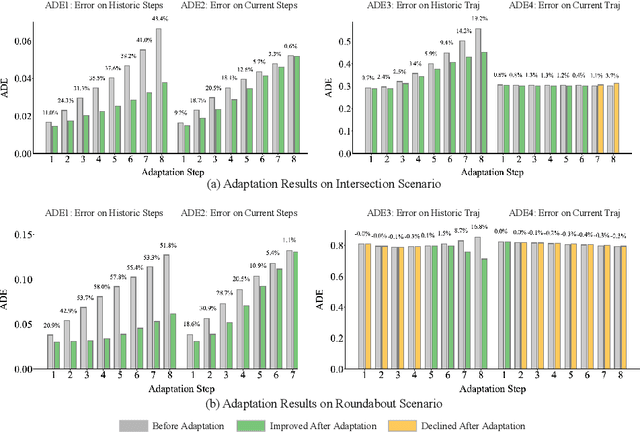
High fidelity behavior prediction of human drivers is crucial for efficient and safe deployment of autonomous vehicles, which is challenging due to the stochasticity, heterogeneity, and time-varying nature of human behaviors. On one hand, the trained prediction model can only capture the motion pattern in an average sense, while the nuances among individuals can hardly be reflected. On the other hand, the prediction model trained on the training set may not generalize to the testing set which may be in a different scenario or data distribution, resulting in low transferability and generalizability. In this paper, we applied a $\tau$-step modified Extended Kalman Filter parameter adaptation algorithm (MEKF$_\lambda$) to the driving behavior prediction task, which has not been studied before in literature. With the feedback of the observed trajectory, the algorithm is applied to neural-network-based models to improve the performance of driving behavior predictions across different human subjects and scenarios. A new set of metrics is proposed for systematic evaluation of online adaptation performance in reducing the prediction error for different individuals and scenarios. Empirical studies on the best layer in the model and steps of observation to adapt are also provided.
Training Verifiers to Solve Math Word Problems
Nov 18, 2021
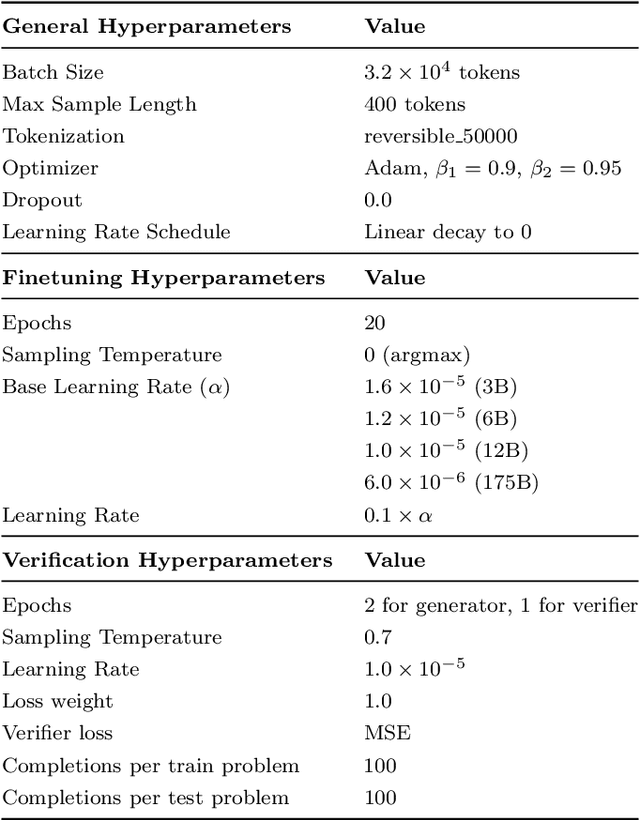
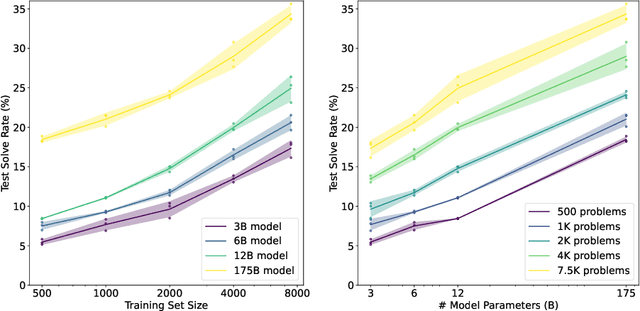
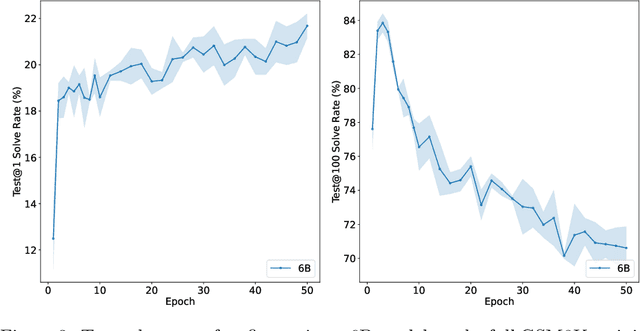
State-of-the-art language models can match human performance on many tasks, but they still struggle to robustly perform multi-step mathematical reasoning. To diagnose the failures of current models and support research, we introduce GSM8K, a dataset of 8.5K high quality linguistically diverse grade school math word problems. We find that even the largest transformer models fail to achieve high test performance, despite the conceptual simplicity of this problem distribution. To increase performance, we propose training verifiers to judge the correctness of model completions. At test time, we generate many candidate solutions and select the one ranked highest by the verifier. We demonstrate that verification significantly improves performance on GSM8K, and we provide strong empirical evidence that verification scales more effectively with increased data than a finetuning baseline.
MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images
Aug 14, 2020We introduce a method to convert stereo 360{\deg} (omnidirectional stereo) imagery into a layered, multi-sphere image representation for six degree-of-freedom (6DoF) rendering. Stereo 360{\deg} imagery can be captured from multi-camera systems for virtual reality (VR), but lacks motion parallax and correct-in-all-directions disparity cues. Together, these can quickly lead to VR sickness when viewing content. One solution is to try and generate a format suitable for 6DoF rendering, such as by estimating depth. However, this raises questions as to how to handle disoccluded regions in dynamic scenes. Our approach is to simultaneously learn depth and disocclusions via a multi-sphere image representation, which can be rendered with correct 6DoF disparity and motion parallax in VR. This significantly improves comfort for the viewer, and can be inferred and rendered in real time on modern GPU hardware. Together, these move towards making VR video a more comfortable immersive medium.
Joint 3D Object Detection and Tracking Using Spatio-Temporal Representation of Camera Image and LiDAR Point Clouds
Dec 14, 2021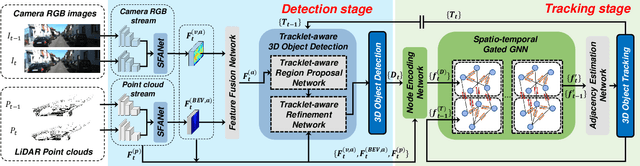

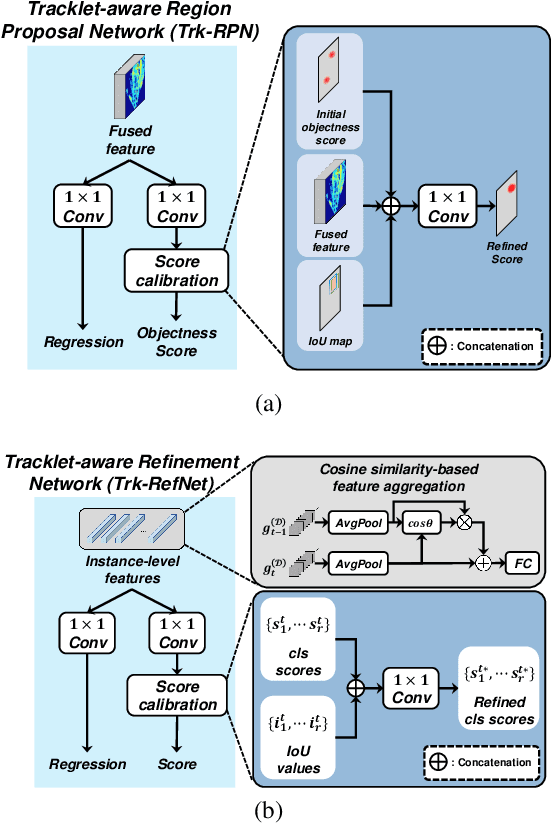

In this paper, we propose a new joint object detection and tracking (JoDT) framework for 3D object detection and tracking based on camera and LiDAR sensors. The proposed method, referred to as 3D DetecTrack, enables the detector and tracker to cooperate to generate a spatio-temporal representation of the camera and LiDAR data, with which 3D object detection and tracking are then performed. The detector constructs the spatio-temporal features via the weighted temporal aggregation of the spatial features obtained by the camera and LiDAR fusion. Then, the detector reconfigures the initial detection results using information from the tracklets maintained up to the previous time step. Based on the spatio-temporal features generated by the detector, the tracker associates the detected objects with previously tracked objects using a graph neural network (GNN). We devise a fully-connected GNN facilitated by a combination of rule-based edge pruning and attention-based edge gating, which exploits both spatial and temporal object contexts to improve tracking performance. The experiments conducted on both KITTI and nuScenes benchmarks demonstrate that the proposed 3D DetecTrack achieves significant improvements in both detection and tracking performances over baseline methods and achieves state-of-the-art performance among existing methods through collaboration between the detector and tracker.