 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Timely Updating with Intermittent Energy and Data for Multiple Sources over Erasure Channels
Sep 15, 2021
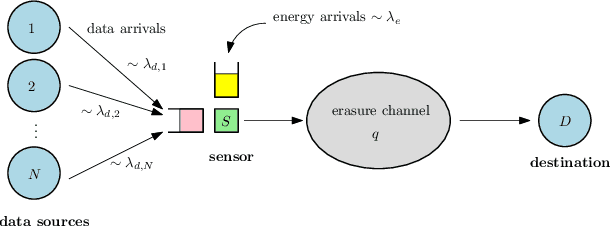
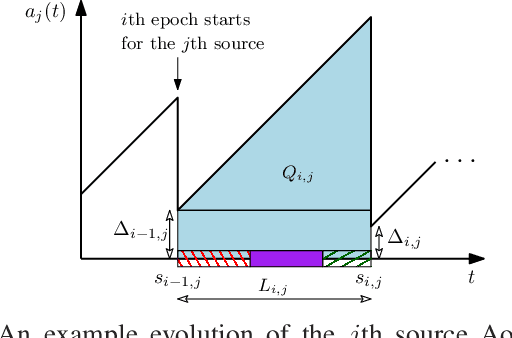
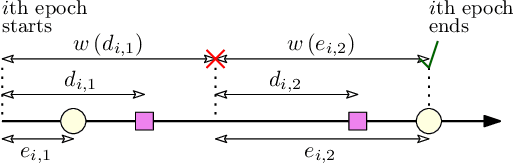
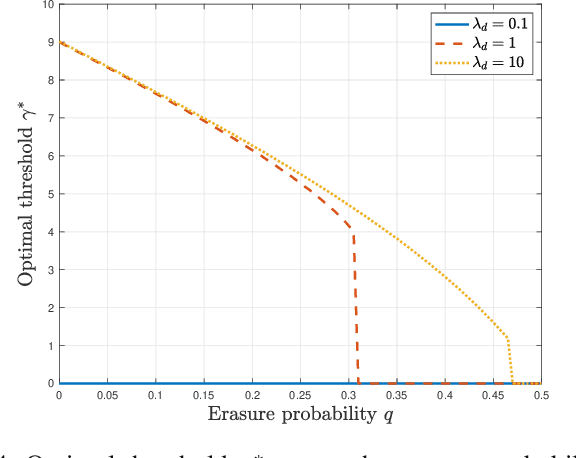
A status updating system is considered in which multiple data sources generate packets to be delivered to a destination through a shared energy harvesting sensor. Only one source's data, when available, can be transmitted by the sensor at a time, subject to energy availability. Transmissions are prune to erasures, and each successful transmission constitutes a status update for its corresponding source at the destination. The goal is to schedule source transmissions such that the collective long-term average age-of-information (AoI) is minimized. AoI is defined as the time elapsed since the latest successfully-received data has been generated at its source. To solve this problem, the case with a single source is first considered, with a focus on threshold waiting policies, in which the sensor attempts transmission only if the time until both energy and data are available grows above a certain threshold. The distribution of the AoI is fully characterized under such a policy. This is then used to analyze the performance of the multiple sources case under maximum-age-first scheduling, in which the sensor's resources are dedicated to the source with the maximum AoI at any given time. The achievable collective long-term average AoI is derived in closed-form. Multiple numerical evaluations are demonstrated to show how the optimal threshold value behaves as a function of the system parameters, and showcase the benefits of a threshold-based waiting policy with intermittent energy and data arrivals.
Self-Supervised Domain Adaptation for Visual Navigation with Global Map Consistency
Oct 14, 2021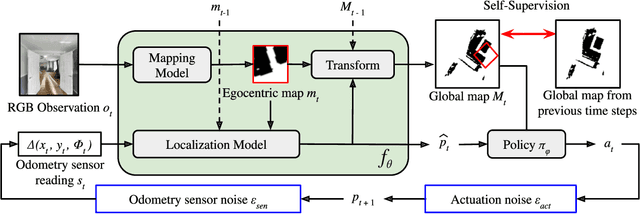
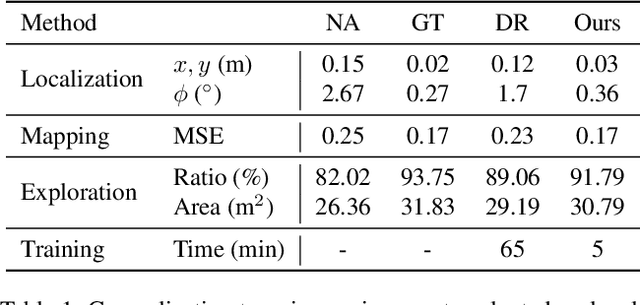
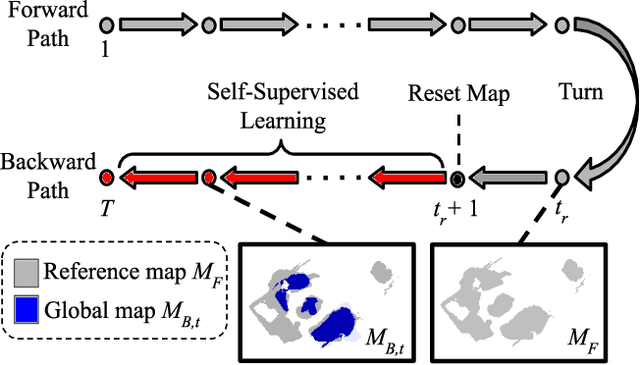
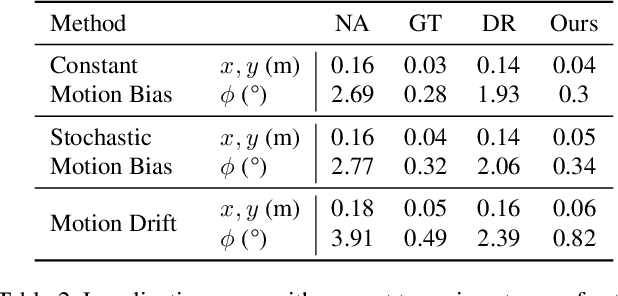
We propose a light-weight, self-supervised adaptation for a visual navigation agent to generalize to unseen environment. Given an embodied agent trained in a noiseless environment, our objective is to transfer the agent to a noisy environment where actuation and odometry sensor noise is present. Our method encourages the agent to maximize the consistency between the global maps generated at different time steps in a round-trip trajectory. The proposed task is completely self-supervised, not requiring any supervision from ground-truth pose data or explicit noise model. In addition, optimization of the task objective is extremely light-weight, as training terminates within a few minutes on a commodity GPU. Our experiments show that the proposed task helps the agent to successfully transfer to new, noisy environments. The transferred agent exhibits improved localization and mapping accuracy, further leading to enhanced performance in downstream visual navigation tasks. Moreover, we demonstrate test-time adaptation with our self-supervised task to show its potential applicability in real-world deployment.
Improving the Segmentation of Pediatric Low-Grade Gliomas through Multitask Learning
Nov 29, 2021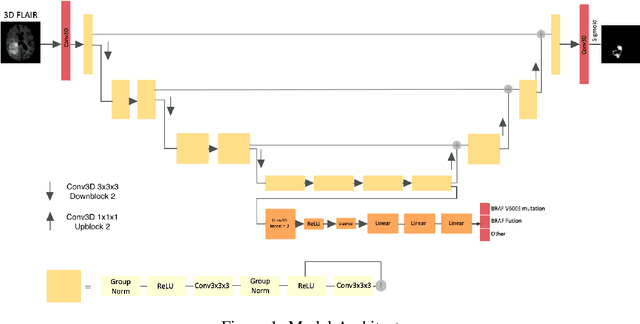
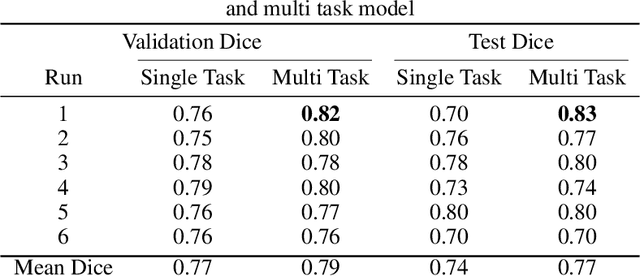
Brain tumor segmentation is a critical task for tumor volumetric analyses and AI algorithms. However, it is a time-consuming process and requires neuroradiology expertise. While there has been extensive research focused on optimizing brain tumor segmentation in the adult population, studies on AI guided pediatric tumor segmentation are scarce. Furthermore, MRI signal characteristics of pediatric and adult brain tumors differ, necessitating the development of segmentation algorithms specifically designed for pediatric brain tumors. We developed a segmentation model trained on magnetic resonance imaging (MRI) of pediatric patients with low-grade gliomas (pLGGs) from The Hospital for Sick Children (Toronto, Ontario, Canada). The proposed model utilizes deep Multitask Learning (dMTL) by adding tumor's genetic alteration classifier as an auxiliary task to the main network, ultimately improving the accuracy of the segmentation results.
Transcoded Video Restoration by Temporal Spatial Auxiliary Network
Dec 15, 2021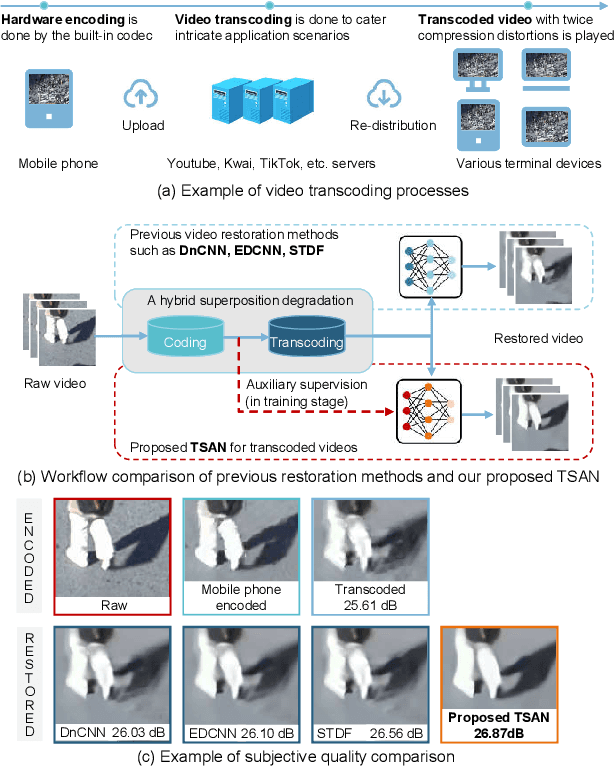
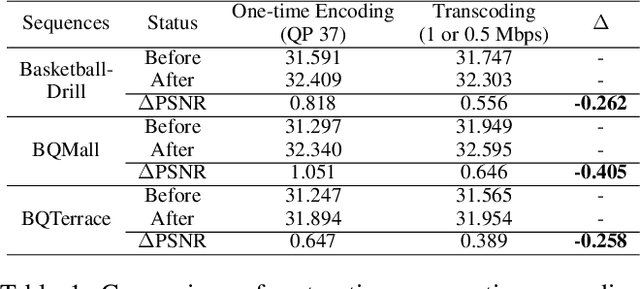
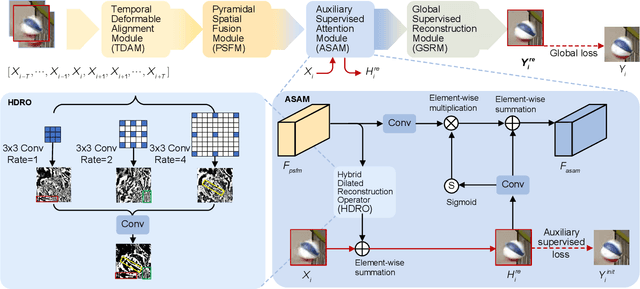

In most video platforms, such as Youtube, and TikTok, the played videos usually have undergone multiple video encodings such as hardware encoding by recording devices, software encoding by video editing apps, and single/multiple video transcoding by video application servers. Previous works in compressed video restoration typically assume the compression artifacts are caused by one-time encoding. Thus, the derived solution usually does not work very well in practice. In this paper, we propose a new method, temporal spatial auxiliary network (TSAN), for transcoded video restoration. Our method considers the unique traits between video encoding and transcoding, and we consider the initial shallow encoded videos as the intermediate labels to assist the network to conduct self-supervised attention training. In addition, we employ adjacent multi-frame information and propose the temporal deformable alignment and pyramidal spatial fusion for transcoded video restoration. The experimental results demonstrate that the performance of the proposed method is superior to that of the previous techniques. The code is available at https://github.com/icecherylXuli/TSAN.
EEG functional connectivity and deep learning for automatic diagnosis of brain disorders: Alzheimer's disease and schizophrenia
Oct 07, 2021
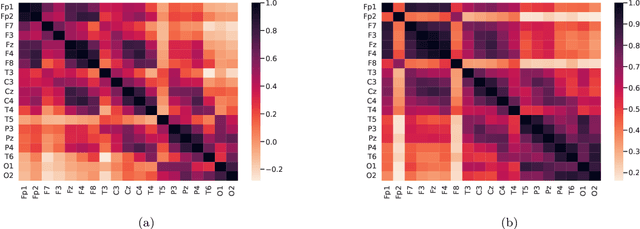
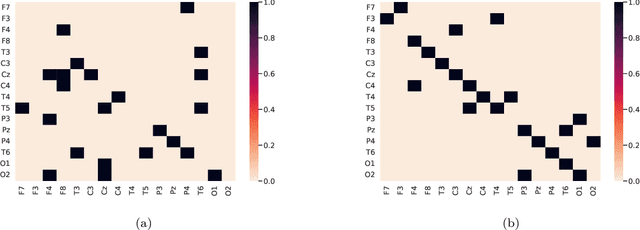
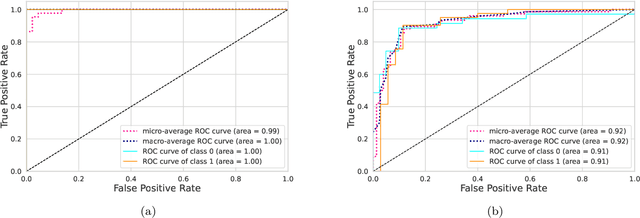
Mental disorders are among the leading causes of disability worldwide. The first step in treating these conditions is to obtain an accurate diagnosis, but the absence of established clinical tests makes this task challenging. Machine learning algorithms can provide a possible solution to this problem, as we describe in this work. We present a method for the automatic diagnosis of mental disorders based on the matrix of connections obtained from EEG time series and deep learning. We show that our approach can classify patients with Alzheimer's disease and schizophrenia with a high level of accuracy. The comparison with the traditional cases, that use raw EEG time series, shows that our method provides the highest precision. Therefore, the application of deep neural networks on data from brain connections is a very promising method to the diagnosis of neurological disorders.
Distribution Shift in Airline Customer Behavior during COVID-19
Nov 29, 2021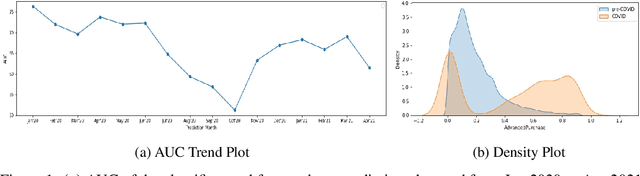

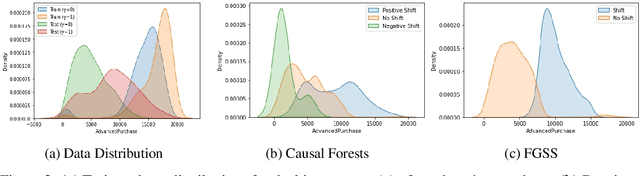
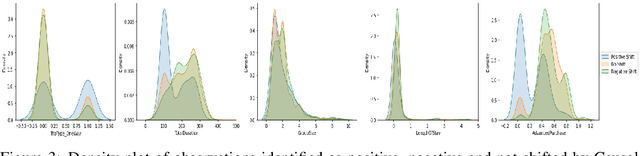
Traditional AI approaches in customized (personalized) contextual pricing applications assume that the data distribution at the time of online pricing is similar to that observed during training. However, this assumption may be violated in practice because of the dynamic nature of customer buying patterns, particularly due to unanticipated system shocks such as COVID-19. We study the changes in customer behavior for a major airline during the COVID-19 pandemic by framing it as a covariate shift and concept drift detection problem. We identify which customers changed their travel and purchase behavior and the attributes affecting that change using (i) Fast Generalized Subset Scanning and (ii) Causal Forests. In our experiments with simulated and real-world data, we present how these two techniques can be used through qualitative analysis.
A Variational Inference Approach to Inverse Problems with Gamma Hyperpriors
Nov 26, 2021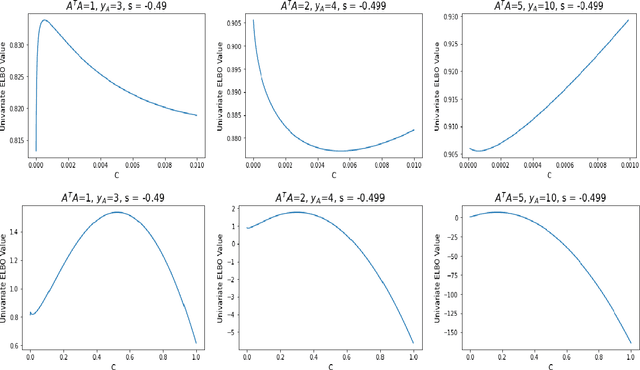

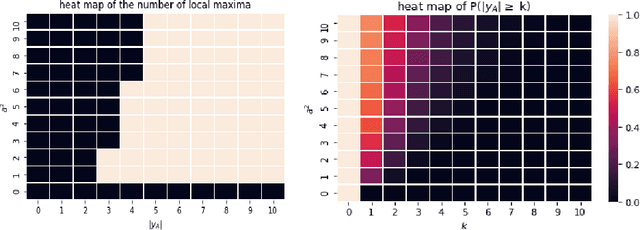
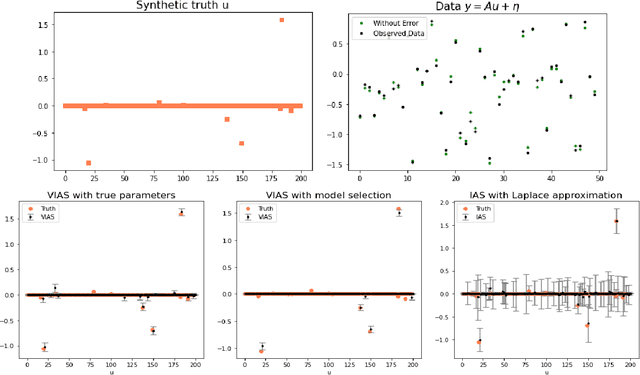
Hierarchical models with gamma hyperpriors provide a flexible, sparse-promoting framework to bridge $L^1$ and $L^2$ regularizations in Bayesian formulations to inverse problems. Despite the Bayesian motivation for these models, existing methodologies are limited to \textit{maximum a posteriori} estimation. The potential to perform uncertainty quantification has not yet been realized. This paper introduces a variational iterative alternating scheme for hierarchical inverse problems with gamma hyperpriors. The proposed variational inference approach yields accurate reconstruction, provides meaningful uncertainty quantification, and is easy to implement. In addition, it lends itself naturally to conduct model selection for the choice of hyperparameters. We illustrate the performance of our methodology in several computed examples, including a deconvolution problem and sparse identification of dynamical systems from time series data.
Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research
Dec 03, 2021
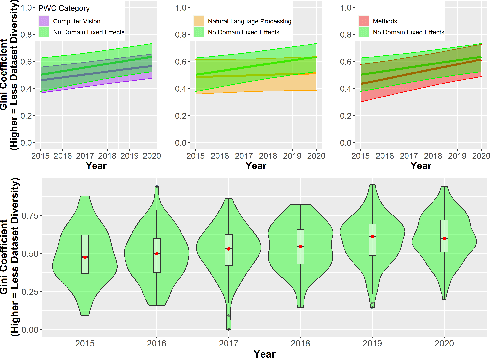
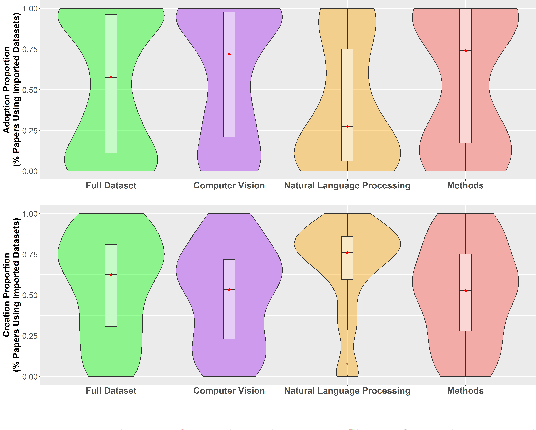
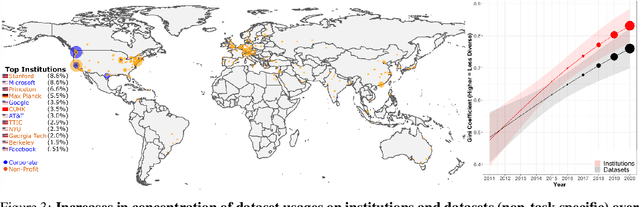
Benchmark datasets play a central role in the organization of machine learning research. They coordinate researchers around shared research problems and serve as a measure of progress towards shared goals. Despite the foundational role of benchmarking practices in this field, relatively little attention has been paid to the dynamics of benchmark dataset use and reuse, within or across machine learning subcommunities. In this paper, we dig into these dynamics. We study how dataset usage patterns differ across machine learning subcommunities and across time from 2015-2020. We find increasing concentration on fewer and fewer datasets within task communities, significant adoption of datasets from other tasks, and concentration across the field on datasets that have been introduced by researchers situated within a small number of elite institutions. Our results have implications for scientific evaluation, AI ethics, and equity/access within the field.
Multi-concept adversarial attacks
Oct 19, 2021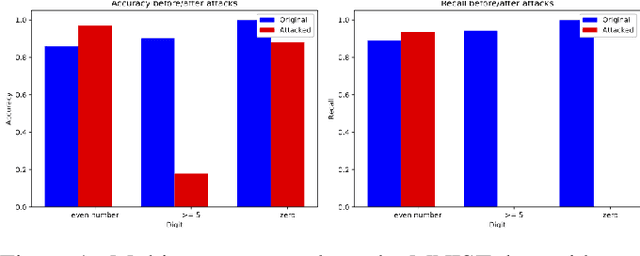
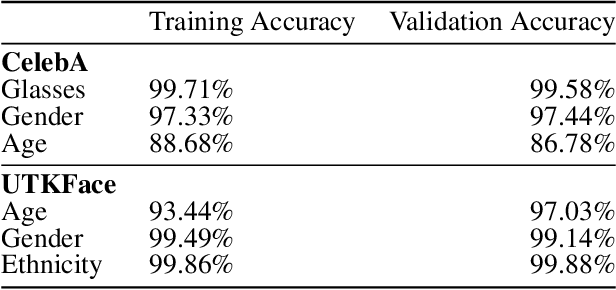

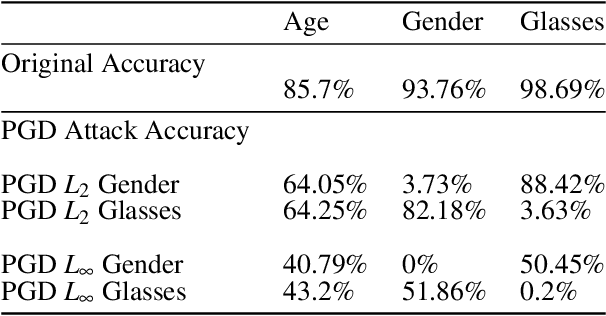
As machine learning (ML) techniques are being increasingly used in many applications, their vulnerability to adversarial attacks becomes well-known. Test time attacks, usually launched by adding adversarial noise to test instances, have been shown effective against the deployed ML models. In practice, one test input may be leveraged by different ML models. Test time attacks targeting a single ML model often neglect their impact on other ML models. In this work, we empirically demonstrate that naively attacking the classifier learning one concept may negatively impact classifiers trained to learn other concepts. For example, for the online image classification scenario, when the Gender classifier is under attack, the (wearing) Glasses classifier is simultaneously attacked with the accuracy dropped from 98.69 to 88.42. This raises an interesting question: is it possible to attack one set of classifiers without impacting the other set that uses the same test instance? Answers to the above research question have interesting implications for protecting privacy against ML model misuse. Attacking ML models that pose unnecessary risks of privacy invasion can be an important tool for protecting individuals from harmful privacy exploitation. In this paper, we address the above research question by developing novel attack techniques that can simultaneously attack one set of ML models while preserving the accuracy of the other. In the case of linear classifiers, we provide a theoretical framework for finding an optimal solution to generate such adversarial examples. Using this theoretical framework, we develop a multi-concept attack strategy in the context of deep learning. Our results demonstrate that our techniques can successfully attack the target classes while protecting the protected classes in many different settings, which is not possible with the existing test-time attack-single strategies.
SPTS: Single-Point Text Spotting
Dec 15, 2021
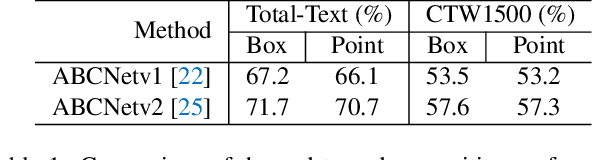

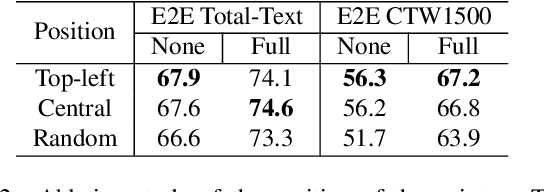
Almost all scene text spotting (detection and recognition) methods rely on costly box annotation (e.g., text-line box, word-level box, and character-level box). For the first time, we demonstrate that training scene text spotting models can be achieved with an extremely low-cost annotation of a single-point for each instance. We propose an end-to-end scene text spotting method that tackles scene text spotting as a sequence prediction task, like language modeling. Given an image as input, we formulate the desired detection and recognition results as a sequence of discrete tokens and use an auto-regressive transformer to predict the sequence. We achieve promising results on several horizontal, multi-oriented, and arbitrarily shaped scene text benchmarks. Most significantly, we show that the performance is not very sensitive to the positions of the point annotation, meaning that it can be much easier to be annotated and automatically generated than the bounding box that requires precise positions. We believe that such a pioneer attempt indicates a significant opportunity for scene text spotting applications of a much larger scale than previously possible.