 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Social Simulations Are a Promising Research Method
Apr 03, 2025Accurate and verifiable large language model (LLM) simulations of human research subjects promise an accessible data source for understanding human behavior and training new AI systems. However, results to date have been limited, and few social scientists have adopted these methods. In this position paper, we argue that the promise of LLM social simulations can be achieved by addressing five tractable challenges. We ground our argument in a literature survey of empirical comparisons between LLMs and human research subjects, commentaries on the topic, and related work. We identify promising directions with prompting, fine-tuning, and complementary methods. We believe that LLM social simulations can already be used for exploratory research, such as pilot experiments for psychology, economics, sociology, and marketing. More widespread use may soon be possible with rapidly advancing LLM capabilities, and researchers should prioritize developing conceptual models and evaluations that can be iteratively deployed and refined at pace with ongoing AI advances.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research
Dec 03, 2021
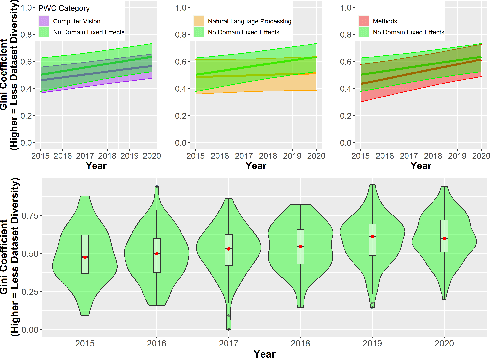
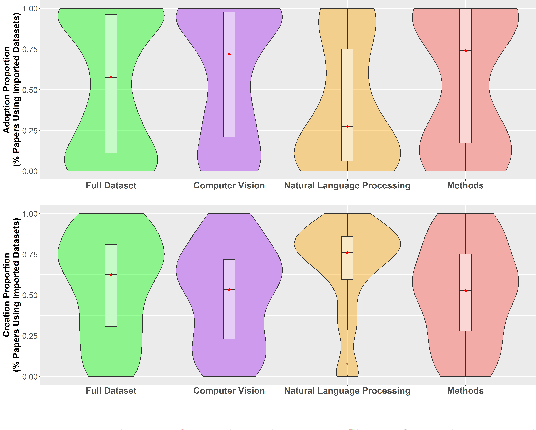
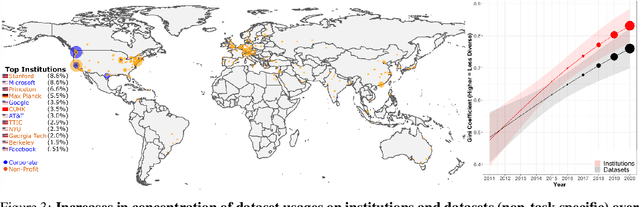
Benchmark datasets play a central role in the organization of machine learning research. They coordinate researchers around shared research problems and serve as a measure of progress towards shared goals. Despite the foundational role of benchmarking practices in this field, relatively little attention has been paid to the dynamics of benchmark dataset use and reuse, within or across machine learning subcommunities. In this paper, we dig into these dynamics. We study how dataset usage patterns differ across machine learning subcommunities and across time from 2015-2020. We find increasing concentration on fewer and fewer datasets within task communities, significant adoption of datasets from other tasks, and concentration across the field on datasets that have been introduced by researchers situated within a small number of elite institutions. Our results have implications for scientific evaluation, AI ethics, and equity/access within the field.
Deep Learning of Potential Outcomes
Oct 09, 2021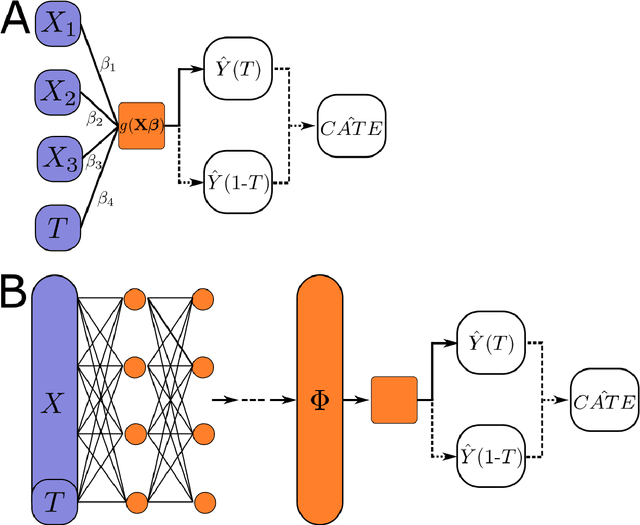
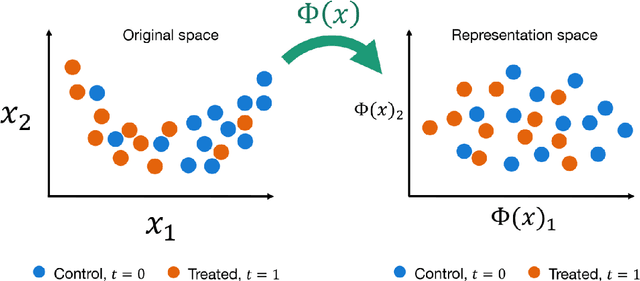
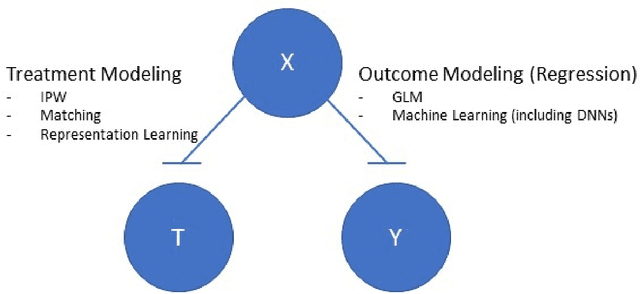
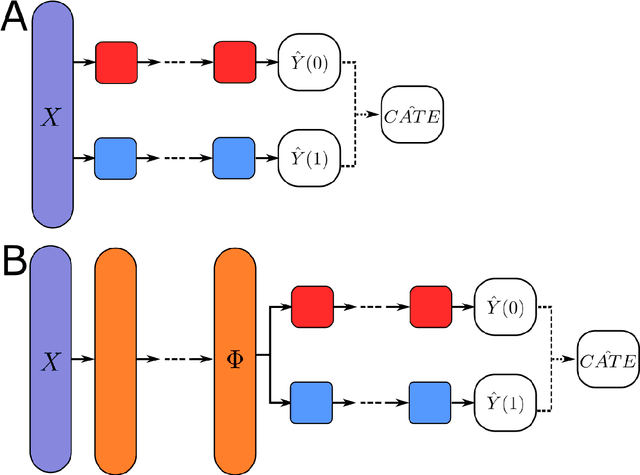
This review systematizes the emerging literature for causal inference using deep neural networks under the potential outcomes framework. It provides an intuitive introduction on how deep learning can be used to estimate/predict heterogeneous treatment effects and extend causal inference to settings where confounding is non-linear, time varying, or encoded in text, networks, and images. To maximize accessibility, we also introduce prerequisite concepts from causal inference and deep learning. The survey differs from other treatments of deep learning and causal inference in its sharp focus on observational causal estimation, its extended exposition of key algorithms, and its detailed tutorials for implementing, training, and selecting among deep estimators in Tensorflow 2 available at github.com/kochbj/Deep-Learning-for-Causal-Inference.
Uncovering Sociological Effect Heterogeneity using Machine Learning
Sep 18, 2019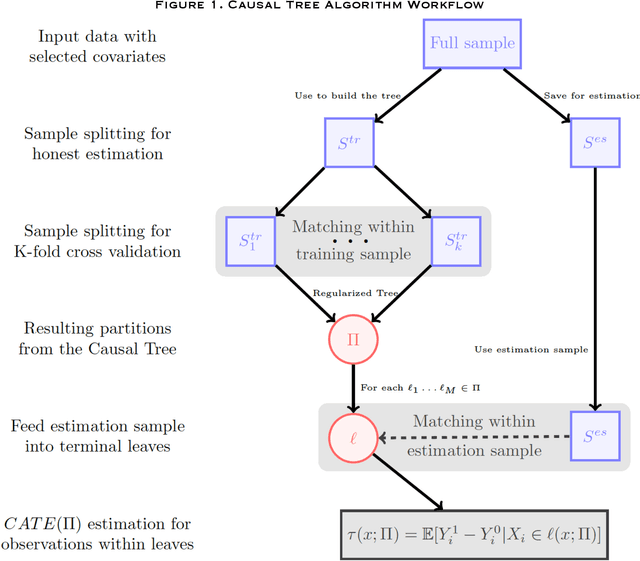
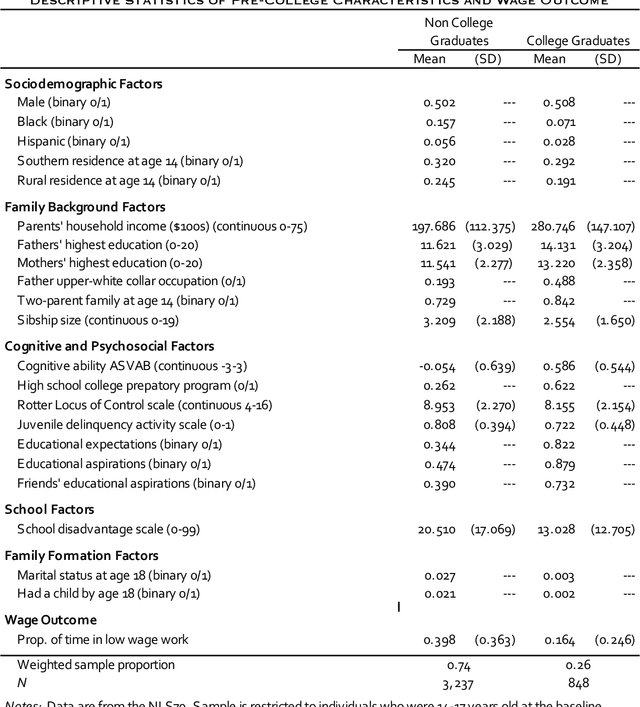
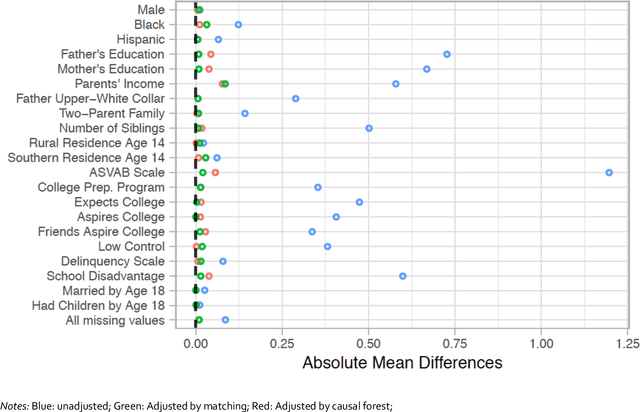
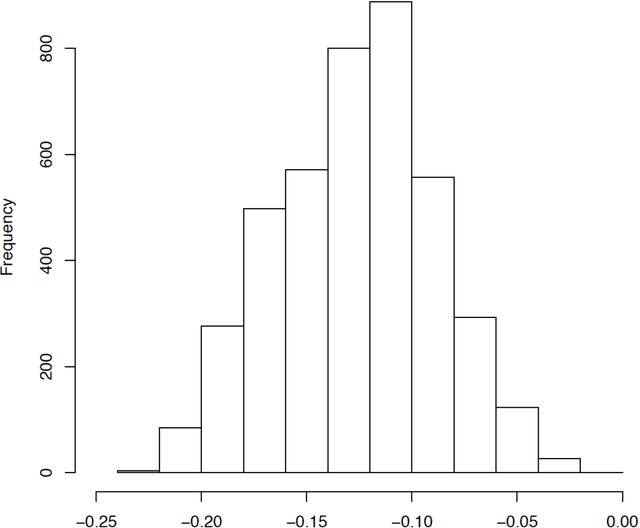
Individuals do not respond uniformly to treatments, events, or interventions. Sociologists routinely partition samples into subgroups to explore how the effects of treatments vary by covariates like race, gender, and socioeconomic status. In so doing, analysts determine the key subpopulations based on theoretical priors. Data-driven discoveries are also routine, yet the analyses by which sociologists typically go about them are problematic and seldom move us beyond our expectations, and biases, to explore new meaningful subgroups. Emerging machine learning methods allow researchers to explore sources of variation that they may not have previously considered, or envisaged. In this paper, we use causal trees to recursively partition the sample and uncover sources of treatment effect heterogeneity. We use honest estimation, splitting the sample into a training sample to grow the tree and an estimation sample to estimate leaf-specific effects. Assessing a central topic in the social inequality literature, college effects on wages, we compare what we learn from conventional approaches for exploring variation in effects to causal trees. Given our use of observational data, we use leaf-specific matching and sensitivity analyses to address confounding and offer interpretations of effects based on observed and unobserved heterogeneity. We encourage researchers to follow similar practices in their work on variation in sociological effects.