 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling the Lane-Change Reactions to Merging Vehicles for Highway On-Ramp Simulations
Apr 15, 2024
Enhancing simulation environments to replicate real-world driver behavior is essential for developing Autonomous Vehicle technology. While some previous works have studied the yielding reaction of lag vehicles in response to a merging car at highway on-ramps, the possible lane-change reaction of the lag car has not been widely studied. In this work we aim to improve the simulation of the highway merge scenario by including the lane-change reaction in addition to yielding behavior of main-lane lag vehicles, and we evaluate two different models for their ability to capture this reactive lane-change behavior. To tune the payoff functions of these models, a novel naturalistic dataset was collected on U.S. highways that provided several hours of merge-specific data to learn the lane change behavior of U.S. drivers. To make sure that we are collecting a representative set of different U.S. highway geometries in our data, we surveyed 50,000 U.S. highway on-ramps and then selected eight representative sites. The data were collected using roadside-mounted lidar sensors to capture various merge driver interactions. The models were demonstrated to be configurable for both keep-straight and lane-change behavior. The models were finally integrated into a high-fidelity simulation environment and confirmed to have adequate computation time efficiency for use in large-scale simulations to support autonomous vehicle development.
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Apr 15, 2024In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
Exponentially Weighted Moving Models
Apr 11, 2024An exponentially weighted moving model (EWMM) for a vector time series fits a new data model each time period, based on an exponentially fading loss function on past observed data. The well known and widely used exponentially weighted moving average (EWMA) is a special case that estimates the mean using a square loss function. For quadratic loss functions EWMMs can be fit using a simple recursion that updates the parameters of a quadratic function. For other loss functions, the entire past history must be stored, and the fitting problem grows in size as time increases. We propose a general method for computing an approximation of EWMM, which requires storing only a window of a fixed number of past samples, and uses an additional quadratic term to approximate the loss associated with the data before the window. This approximate EWMM relies on convex optimization, and solves problems that do not grow with time. We compare the estimates produced by our approximation with the estimates from the exact EWMM method.
VideoSAGE: Video Summarization with Graph Representation Learning
Apr 14, 2024We propose a graph-based representation learning framework for video summarization. First, we convert an input video to a graph where nodes correspond to each of the video frames. Then, we impose sparsity on the graph by connecting only those pairs of nodes that are within a specified temporal distance. We then formulate the video summarization task as a binary node classification problem, precisely classifying video frames whether they should belong to the output summary video. A graph constructed this way aims to capture long-range interactions among video frames, and the sparsity ensures the model trains without hitting the memory and compute bottleneck. Experiments on two datasets(SumMe and TVSum) demonstrate the effectiveness of the proposed nimble model compared to existing state-of-the-art summarization approaches while being one order of magnitude more efficient in compute time and memory
Empowering Federated Learning with Implicit Gossiping: Mitigating Connection Unreliability Amidst Unknown and Arbitrary Dynamics
Apr 15, 2024Federated learning is a popular distributed learning approach for training a machine learning model without disclosing raw data. It consists of a parameter server and a possibly large collection of clients (e.g., in cross-device federated learning) that may operate in congested and changing environments. In this paper, we study federated learning in the presence of stochastic and dynamic communication failures wherein the uplink between the parameter server and client $i$ is on with unknown probability $p_i^t$ in round $t$. Furthermore, we allow the dynamics of $p_i^t$ to be arbitrary. We first demonstrate that when the $p_i^t$'s vary across clients, the most widely adopted federated learning algorithm, Federated Average (FedAvg), experiences significant bias. To address this observation, we propose Federated Postponed Broadcast (FedPBC), a simple variant of FedAvg. FedPBC differs from FedAvg in that the parameter server postpones broadcasting the global model till the end of each round. Despite uplink failures, we show that FedPBC converges to a stationary point of the original non-convex objective. On the technical front, postponing the global model broadcasts enables implicit gossiping among the clients with active links in round $t$. Despite the time-varying nature of $p_i^t$, we can bound the perturbation of the global model dynamics using techniques to control gossip-type information mixing errors. Extensive experiments have been conducted on real-world datasets over diversified unreliable uplink patterns to corroborate our analysis.
PD-L1 Classification of Weakly-Labeled Whole Slide Images of Breast Cancer
Apr 15, 2024Specific and effective breast cancer therapy relies on the accurate quantification of PD-L1 positivity in tumors, which appears in the form of brown stainings in high resolution whole slide images (WSIs). However, the retrieval and extensive labeling of PD-L1 stained WSIs is a time-consuming and challenging task for pathologists, resulting in low reproducibility, especially for borderline images. This study aims to develop and compare models able to classify PD-L1 positivity of breast cancer samples based on WSI analysis, relying only on WSI-level labels. The task consists of two phases: identifying regions of interest (ROI) and classifying tumors as PD-L1 positive or negative. For the latter, two model categories were developed, with different feature extraction methodologies. The first encodes images based on the colour distance from a base color. The second uses a convolutional autoencoder to obtain embeddings of WSI tiles, and aggregates them into a WSI-level embedding. For both model types, features are fed into downstream ML classifiers. Two datasets from different clinical centers were used in two different training configurations: (1) training on one dataset and testing on the other; (2) combining the datasets. We also tested the performance with or without human preprocessing to remove brown artefacts Colour distance based models achieve the best performances on testing configuration (1) with artefact removal, while autoencoder-based models are superior in the remaining cases, which are prone to greater data variability.
Items or Relations -- what do Artificial Neural Networks learn?
Apr 15, 2024What has an Artificial Neural Network (ANN) learned after being successfully trained to solve a task - the set of training items or the relations between them? This question is difficult to answer for modern applied ANNs because of their enormous size and complexity. Therefore, here we consider a low-dimensional network and a simple task, i.e., the network has to reproduce a set of training items identically. We construct the family of solutions analytically and use standard learning algorithms to obtain numerical solutions. These numerical solutions differ depending on the optimization algorithm and the weight initialization and are shown to be particular members of the family of analytical solutions. In this simple setting, we observe that the general structure of the network weights represents the training set's symmetry group, i.e., the relations between training items. As a consequence, linear networks generalize, i.e., reproduce items that were not part of the training set but are consistent with the symmetry of the training set. In contrast, non-linear networks tend to learn individual training items and show associative memory. At the same time, their ability to generalize is limited. A higher degree of generalization is obtained for networks whose activation function contains a linear regime, such as tanh. Our results suggest ANN's ability to generalize - instead of learning items - could be improved by generating a sufficiently big set of elementary operations to represent relations and strongly depends on the applied non-linearity.
Design and Fabrication of String-driven Origami Robots
Apr 14, 2024Origami designs and structures have been widely used in many fields, such as morphing structures, robotics, and metamaterials. However, the design and fabrication of origami structures rely on human experiences and skills, which are both time and labor-consuming. In this paper, we present a rapid design and fabrication method for string-driven origami structures and robots. We developed an origami design software to generate desired crease patterns based on analytical models and Evolution Strategies (ES). Additionally, the software can automatically produce 3D models of origami designs. We then used a dual-material 3D printer to fabricate those wrapping-based origami structures with the required mechanical properties. We utilized Twisted String Actuators (TSAs) to fold the target 3D structures from flat plates. To demonstrate the capability of these techniques, we built and tested an origami crawling robot and an origami robotic arm using 3D-printed origami structures driven by TSAs.
SMITIN: Self-Monitored Inference-Time INtervention for Generative Music Transformers
Apr 02, 2024We introduce Self-Monitored Inference-Time INtervention (SMITIN), an approach for controlling an autoregressive generative music transformer using classifier probes. These simple logistic regression probes are trained on the output of each attention head in the transformer using a small dataset of audio examples both exhibiting and missing a specific musical trait (e.g., the presence/absence of drums, or real/synthetic music). We then steer the attention heads in the probe direction, ensuring the generative model output captures the desired musical trait. Additionally, we monitor the probe output to avoid adding an excessive amount of intervention into the autoregressive generation, which could lead to temporally incoherent music. We validate our results objectively and subjectively for both audio continuation and text-to-music applications, demonstrating the ability to add controls to large generative models for which retraining or even fine-tuning is impractical for most musicians. Audio samples of the proposed intervention approach are available on our demo page http://tinyurl.com/smitin .
Video-Based Human Pose Regression via Decoupled Space-Time Aggregation
Apr 01, 2024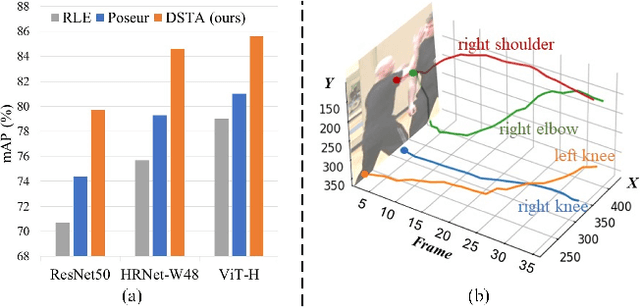

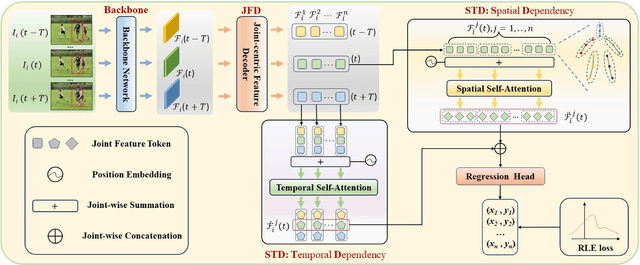
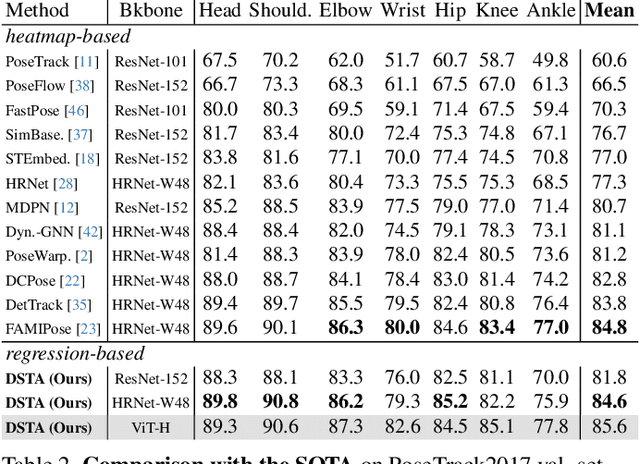
By leveraging temporal dependency in video sequences, multi-frame human pose estimation algorithms have demonstrated remarkable results in complicated situations, such as occlusion, motion blur, and video defocus. These algorithms are predominantly based on heatmaps, resulting in high computation and storage requirements per frame, which limits their flexibility and real-time application in video scenarios, particularly on edge devices. In this paper, we develop an efficient and effective video-based human pose regression method, which bypasses intermediate representations such as heatmaps and instead directly maps the input to the output joint coordinates. Despite the inherent spatial correlation among adjacent joints of the human pose, the temporal trajectory of each individual joint exhibits relative independence. In light of this, we propose a novel Decoupled Space-Time Aggregation network (DSTA) to separately capture the spatial contexts between adjacent joints and the temporal cues of each individual joint, thereby avoiding the conflation of spatiotemporal dimensions. Concretely, DSTA learns a dedicated feature token for each joint to facilitate the modeling of their spatiotemporal dependencies. With the proposed joint-wise local-awareness attention mechanism, our method is capable of efficiently and flexibly utilizing the spatial dependency of adjacent joints and the temporal dependency of each joint itself. Extensive experiments demonstrate the superiority of our method. Compared to previous regression-based single-frame human pose estimation methods, DSTA significantly enhances performance, achieving an 8.9 mAP improvement on PoseTrack2017. Furthermore, our approach either surpasses or is on par with the state-of-the-art heatmap-based multi-frame human pose estimation methods. Project page: https://github.com/zgspose/DSTA.