 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SPAMs: Structured Implicit Parametric Models
Jan 20, 2022
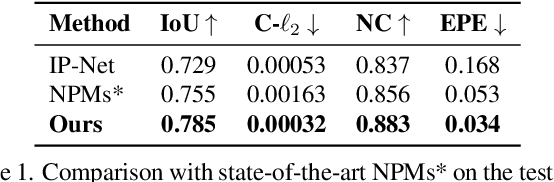
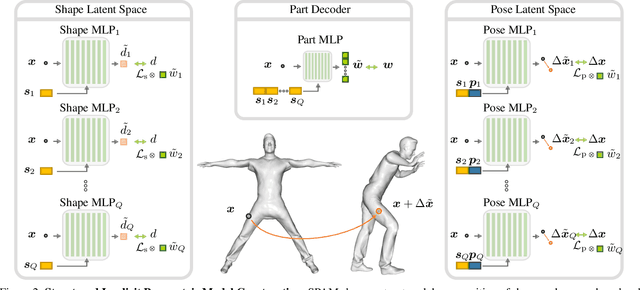
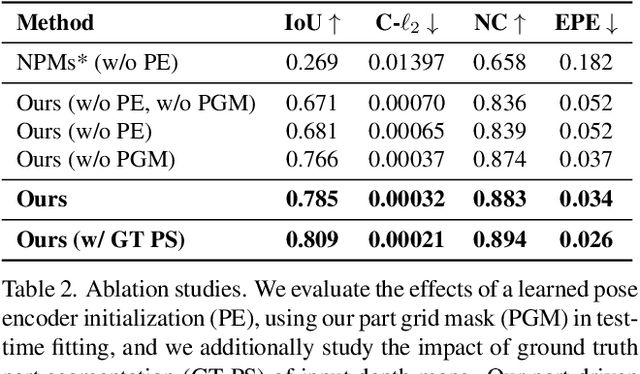

Parametric 3D models have formed a fundamental role in modeling deformable objects, such as human bodies, faces, and hands; however, the construction of such parametric models requires significant manual intervention and domain expertise. Recently, neural implicit 3D representations have shown great expressibility in capturing 3D shape geometry. We observe that deformable object motion is often semantically structured, and thus propose to learn Structured-implicit PArametric Models (SPAMs) as a deformable object representation that structurally decomposes non-rigid object motion into part-based disentangled representations of shape and pose, with each being represented by deep implicit functions. This enables a structured characterization of object movement, with part decomposition characterizing a lower-dimensional space in which we can establish coarse motion correspondence. In particular, we can leverage the part decompositions at test time to fit to new depth sequences of unobserved shapes, by establishing part correspondences between the input observation and our learned part spaces; this guides a robust joint optimization between the shape and pose of all parts, even under dramatic motion sequences. Experiments demonstrate that our part-aware shape and pose understanding lead to state-of-the-art performance in reconstruction and tracking of depth sequences of complex deforming object motion. We plan to release models to the public at https://pablopalafox.github.io/spams.
Importance of Preprocessing in Histopathology Image Classification Using Deep Convolutional Neural Network
Jan 24, 2022
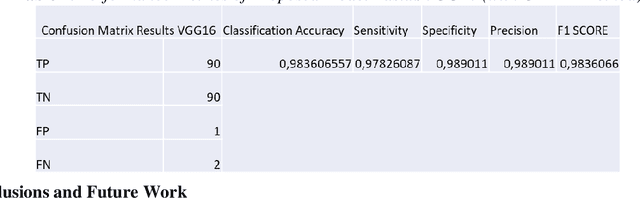
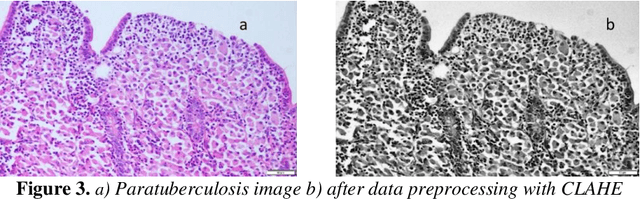
The aim of this study is to propose an alternative and hybrid solution method for diagnosing the disease from histopathology images taken from animals with paratuberculosis and intact intestine. In detail, the hybrid method is based on using both image processing and deep learning for better results. Reliable disease detection from histo-pathology images is known as an open problem in medical image processing and alternative solutions need to be developed. In this context, 520 histopathology images were collected in a joint study with Burdur Mehmet Akif Ersoy University, Faculty of Veterinary Medicine, and Department of Pathology. Manually detecting and interpreting these images requires expertise and a lot of processing time. For this reason, veterinarians, especially newly recruited physicians, have a great need for imaging and computer vision systems in the development of detection and treatment methods for this disease. The proposed solution method in this study is to use the CLAHE method and image processing together. After this preprocessing, the diagnosis is made by classifying a convolutional neural network sup-ported by the VGG-16 architecture. This method uses completely original dataset images. Two types of systems were applied for the evaluation parameters. While the F1 Score was 93% in the method classified without data preprocessing, it was 98% in the method that was preprocessed with the CLAHE method.
EcoFlow: Efficient Convolutional Dataflows for Low-Power Neural Network Accelerators
Feb 04, 2022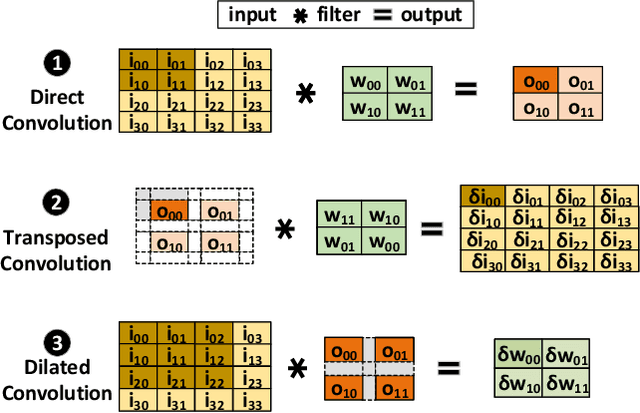

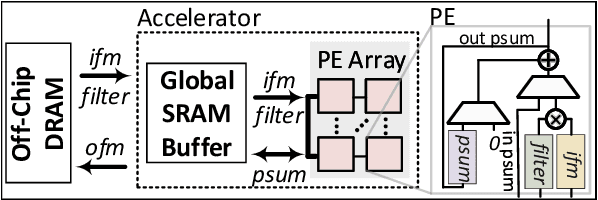
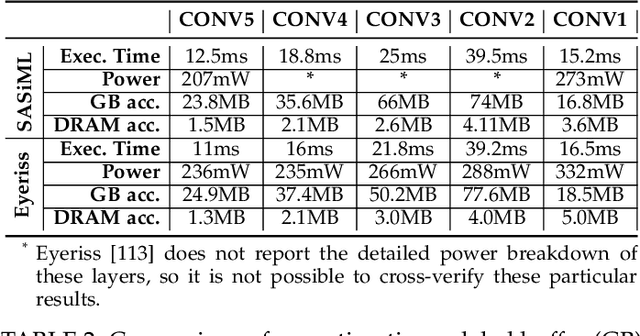
Dilated and transposed convolutions are widely used in modern convolutional neural networks (CNNs). These kernels are used extensively during CNN training and inference of applications such as image segmentation and high-resolution image generation. Although these kernels have grown in popularity, they stress current compute systems due to their high memory intensity, exascale compute demands, and large energy consumption. We find that commonly-used low-power CNN inference accelerators based on spatial architectures are not optimized for both of these convolutional kernels. Dilated and transposed convolutions introduce significant zero padding when mapped to the underlying spatial architecture, significantly degrading performance and energy efficiency. Existing approaches that address this issue require significant design changes to the otherwise simple, efficient, and well-adopted architectures used to compute direct convolutions. To address this challenge, we propose EcoFlow, a new set of dataflows and mapping algorithms for dilated and transposed convolutions. These algorithms are tailored to execute efficiently on existing low-cost, small-scale spatial architectures and requires minimal changes to the network-on-chip of existing accelerators. EcoFlow eliminates zero padding through careful dataflow orchestration and data mapping tailored to the spatial architecture. EcoFlow enables flexible and high-performance transpose and dilated convolutions on architectures that are otherwise optimized for CNN inference. We evaluate the efficiency of EcoFlow on CNN training workloads and Generative Adversarial Network (GAN) training workloads. Experiments in our new cycle-accurate simulator show that EcoFlow 1) reduces end-to-end CNN training time between 7-85%, and 2) improves end-to-end GAN training performance between 29-42%, compared to state-of-the-art CNN inference accelerators.
Pre-Trained Neural Language Models for Automatic Mobile App User Feedback Answer Generation
Feb 04, 2022Studies show that developers' answers to the mobile app users' feedbacks on app stores can increase the apps' star rating. To help app developers generate answers that are related to the users' issues, recent studies develop models to generate the answers automatically. Aims: The app response generation models use deep neural networks and require training data. Pre-Trained neural language Models (PTM) used in Natural Language Processing (NLP) take advantage of the information they learned from a large corpora in an unsupervised manner, and can reduce the amount of required training data. In this paper, we evaluate PTMs to generate replies to the mobile app user feedbacks. Method: We train a Transformer model from scratch and fine-tune two PTMs to evaluate the generated responses, which are compared to RRGEN, a current app response model. We also evaluate the models with different portions of the training data. Results: The results on a large dataset evaluated by automatic metrics show that PTMs obtain lower scores than the baselines. However, our human evaluation confirms that PTMs can generate more relevant and meaningful responses to the posted feedbacks. Moreover, the performance of PTMs has less drop compared to other models when the amount of training data is reduced to 1/3. Conclusion: PTMs are useful in generating responses to app reviews and are more robust models to the amount of training data provided. However, the prediction time is 19X than RRGEN. This study can provide new avenues for research in adapting the PTMs for analyzing mobile app user feedbacks. Index Terms-mobile app user feedback analysis, neural pre-trained language models, automatic answer generation
Object Detection in Thermal Spectrum for Advanced Driver-Assistance Systems (ADAS)
Sep 20, 2021


Object detection in thermal infrared spectrum provides more reliable data source in low-lighting conditions and different weather conditions, as it is useful both in-cabin and outside for pedestrian, animal, and vehicular detection as well as for detecting street-signs & lighting poles. This paper is about exploring and adapting state-of-the-art object detection and classifier framework on thermal vision with seven distinct classes for advanced driver-assistance systems (ADAS). The trained network variants on public datasets are validated on test data with three different test approaches which include test-time with no augmentation, test-time augmentation, and test-time with model ensembling. Additionally, the efficacy of trained networks is tested on locally gathered novel test-data captured with an uncooled LWIR prototype thermal camera in challenging weather and environmental scenarios. The performance analysis of trained models is investigated by computing precision, recall, and mean average precision scores (mAP). Furthermore, the trained model architecture is optimized using TensorRT inference accelerator and deployed on resource-constrained edge hardware Nvidia Jetson Nano to explicitly reduce the inference time on GPU as well as edge devices for further real-time onboard installations.
Time-series Change Point Detection with Self-Supervised Contrastive Predictive Coding
Dec 01, 2020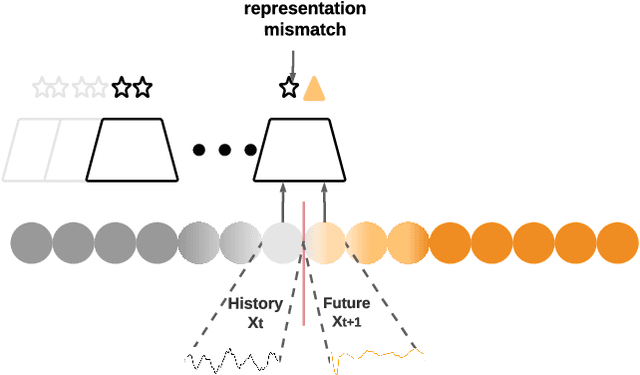
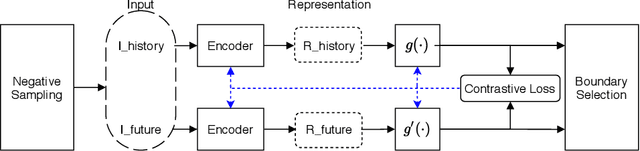
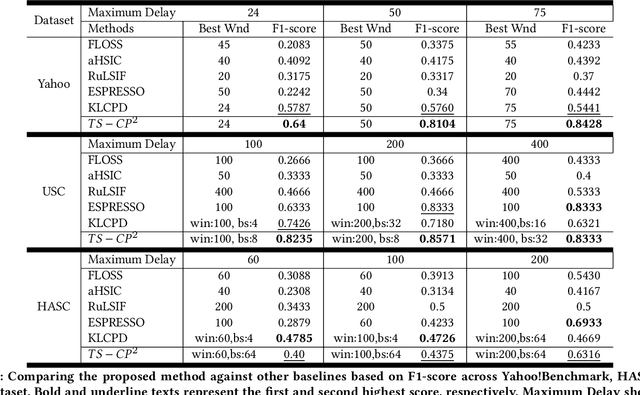
Change Point Detection techniques aim to capture changes in trends and sequences in time-series data to describe the underlying behaviour of the system. Detecting changes and anomalies in the web services, the trend of applications usage can provide valuable insight towards the system, however, many existing approaches are done in a supervised manner, requiring well-labelled data. As the amount of data produced and captured by sensors are growing rapidly, it is getting harder and even impossible to annotate the data. Therefore, coming up with a self-supervised solution is a necessity these days. In this work, we propose TSCP2 a novel self-supervised technique for temporal change point detection, based on representation learning with Temporal Convolutional Network (TCN). To the best of our knowledge, our proposed method is the first method which employs Contrastive Learning for prediction with the aim change point detection. Through extensive evaluations, we demonstrate that our method outperforms multiple state-of-the-art change point detection and anomaly detection baselines, including those adopting either unsupervised or semi-supervised approach. TSCP2 is shown to improve both non-Deep learning- and Deep learning-based methods by 0.28 and 0.12 in terms of average F1-score across three datasets.
Neural Architecture Searching for Facial Attributes-based Depression Recognition
Jan 24, 2022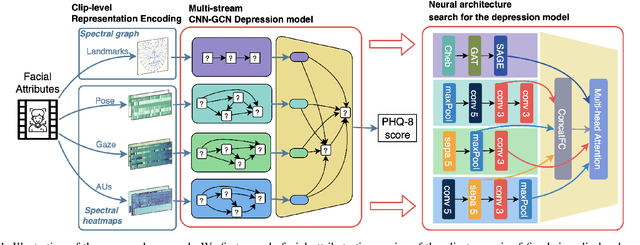
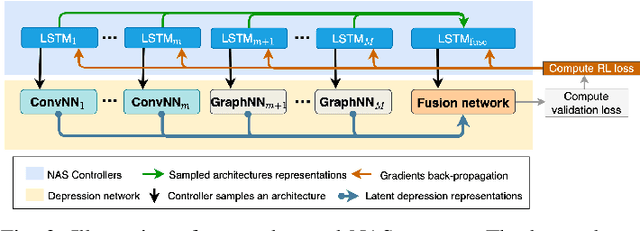
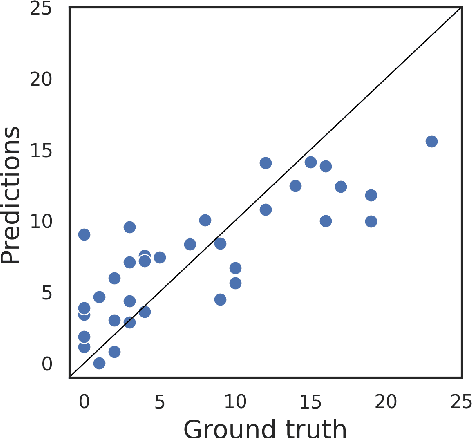
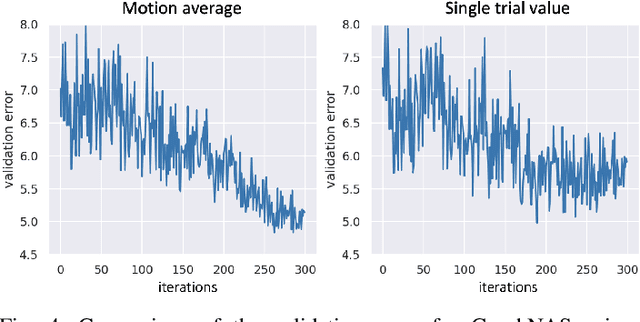
Recent studies show that depression can be partially reflected from human facial attributes. Since facial attributes have various data structure and carry different information, existing approaches fail to specifically consider the optimal way to extract depression-related features from each of them, as well as investigates the best fusion strategy. In this paper, we propose to extend Neural Architecture Search (NAS) technique for designing an optimal model for multiple facial attributes-based depression recognition, which can be efficiently and robustly implemented in a small dataset. Our approach first conducts a warmer up step to the feature extractor of each facial attribute, aiming to largely reduce the search space and providing customized architecture, where each feature extractor can be either a Convolution Neural Networks (CNN) or Graph Neural Networks (GNN). Then, we conduct an end-to-end architecture search for all feature extractors and the fusion network, allowing the complementary depression cues to be optimally combined with less redundancy. The experimental results on AVEC 2016 dataset show that the model explored by our approach achieves breakthrough performance with 27\% and 30\% RMSE and MAE improvements over the existing state-of-the-art. In light of these findings, this paper provides solid evidences and a strong baseline for applying NAS to time-series data-based mental health analysis.
Implicit Deep Adaptive Design: Policy-Based Experimental Design without Likelihoods
Nov 03, 2021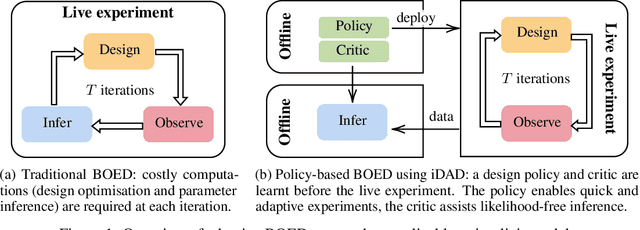
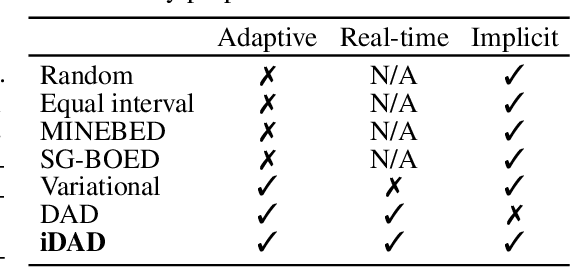
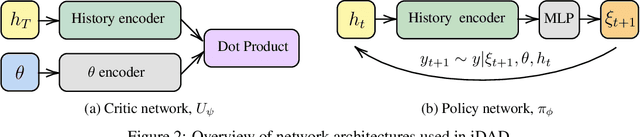
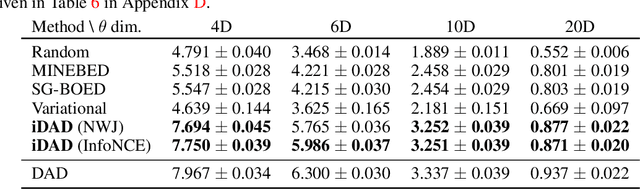
We introduce implicit Deep Adaptive Design (iDAD), a new method for performing adaptive experiments in real-time with implicit models. iDAD amortizes the cost of Bayesian optimal experimental design (BOED) by learning a design policy network upfront, which can then be deployed quickly at the time of the experiment. The iDAD network can be trained on any model which simulates differentiable samples, unlike previous design policy work that requires a closed form likelihood and conditionally independent experiments. At deployment, iDAD allows design decisions to be made in milliseconds, in contrast to traditional BOED approaches that require heavy computation during the experiment itself. We illustrate the applicability of iDAD on a number of experiments, and show that it provides a fast and effective mechanism for performing adaptive design with implicit models.
Autonomous, Mobile Manipulation in a Wall-building Scenario: Team LARICS at MBZIRC 2020
Jan 28, 2022

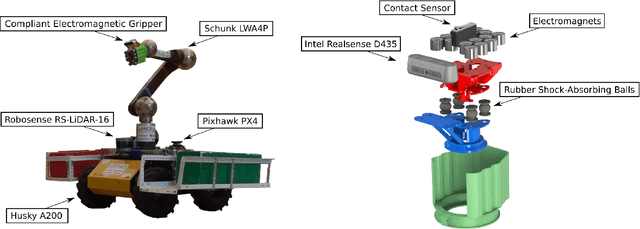
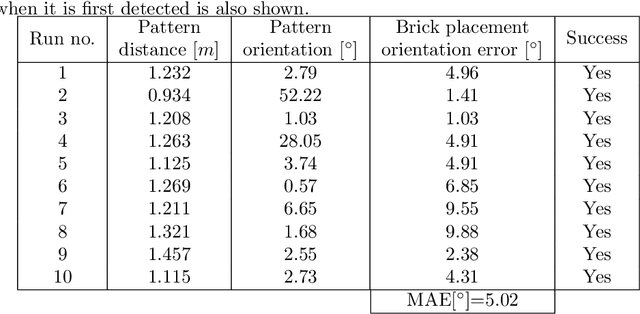
In this paper we present our hardware design and control approaches for a mobile manipulation platform used in Challenge 2 of the MBZIRC 2020 competition. In this challenge, a team of UAVs and a single UGV collaborate in an autonomous, wall-building scenario, motivated by construction automation and large-scale robotic 3D printing. The robots must be able, autonomously, to detect, manipulate, and transport bricks in an unstructured, outdoor environment. Our control approach is based on a state machine that dictates which controllers are active at each stage of the Challenge. In the first stage our UGV uses visual servoing and local controllers to approach the target object without considering its orientation. The second stage consists of detecting the object's global pose using OpenCV-based processing of RGB-D image and point-cloud data, and calculating an alignment goal within a global map. The map is built with Google Cartographer and is based on onboard LIDAR, IMU, and GPS data. Motion control in the second stage is realized using the ROS Move Base package with Time-Elastic Band trajectory optimization. Visual servo algorithms guide the vehicle in local object-approach movement and the arm in manipulating bricks. To ensure a stable grasp of the brick's magnetic patch, we developed a passively-compliant, electromagnetic gripper with tactile feedback. Our fully-autonomous UGV performed well in Challenge 2 and in post-competition evaluations of its brick pick-and-place algorithms.
Analysis of North Indian Classical Ragas Using Tonnetz
Oct 31, 2021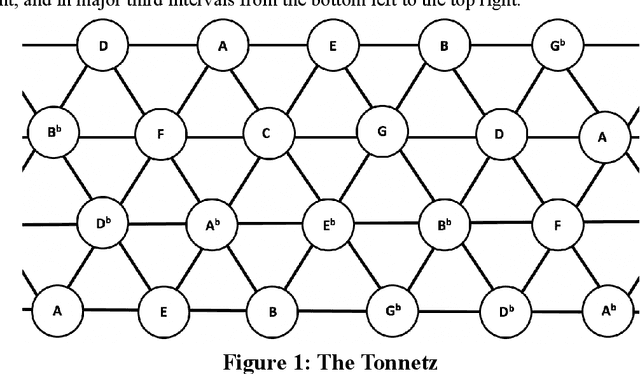
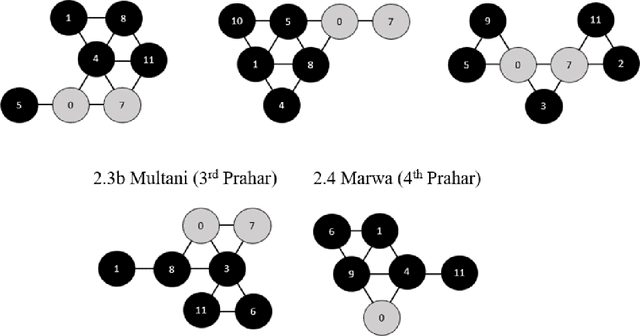
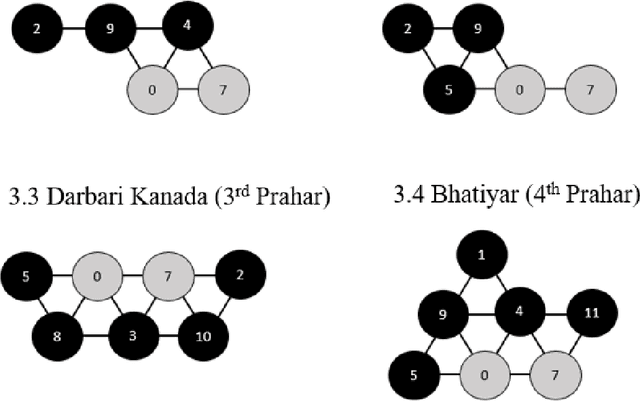
In North Indian Classical music, each raga has been traditionally associated with a performance time, which supposedly maximizes its aesthetic and emotional effects on the listener. The objective of this work was to investigate the structural basis, if any, for the association of ragas with different times of the 24-hour span. The tonnetz framework has been used to analyze the pitch sets of 65 North Indian Classical ragas, and structural similarities have been observed between ragas associated with (1) times of transition between day and night, i.e., dawn and dusk, and (2) times between these transitions. These findings could provide some insight into the scientific basis of the age-old raga-time relation, and their effects on the perception of the listener.